

Recently, a paper was published on arXiv that provides a new interpretation of the mathematical principles of Transformers. The content is lengthy and contains a lot of knowledge, and I highly recommend reading the original text.
In 2017, the paper “Attention is All You Need” by Vaswani et al. became a significant milestone in the development of neural network architectures. The core contribution of this paper is the self-attention mechanism, which is the innovation that distinguishes Transformers from traditional architectures and plays a crucial role in their outstanding practical performance.
In fact, this innovation has become a key catalyst for advancements in artificial intelligence in fields such as computer vision and natural language processing, and has also played a critical role in the emergence of large language models. Therefore, understanding Transformers, especially the mechanism of self-attention in processing data, is a crucial but largely under-explored area.

Paper link: https://arxiv.org/pdf/2312.10794.pdf
Deep neural networks (DNNs) share a common feature: input data is processed sequentially, layer by layer, forming a time-discrete dynamic system (for specific content, refer to the book “Deep Learning” published by MIT, also known as the “flower book” in China). This perspective has been successfully used to model residual networks as time-continuous dynamic systems, referred to as neural ordinary differential equations (neural ODEs). In neural ordinary differential equations, the input image 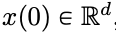 evolves according to a given time-varying velocity field
evolves according to a given time-varying velocity field 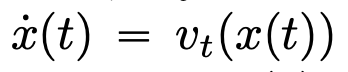 . Therefore, DNNs can be seen as a flow mapping from one
. Therefore, DNNs can be seen as a flow mapping from one 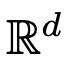 to another
to another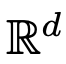 flow mapping
flow mapping . Even under the constraints of classic DNN architectures, the velocity fields
. Even under the constraints of classic DNN architectures, the velocity fields exhibit strong similarities between flow mappings.
exhibit strong similarities between flow mappings.
Specifically, each particle (which can be understood as a token in the context of deep learning) follows the flow of the vector field, which depends on the empirical measure of all particles. In turn, the equations determine the evolution of the empirical measure of the particles, a process that can take a long time and requires continuous attention.
The main observation by researchers is that particles tend to cluster together over time. This phenomenon is particularly evident in learning tasks such as unidirectional inference (i.e., predicting the next word in a sequence). The output metric encodes the probability distribution for the next token, allowing for the selection of a few possible results based on clustering outcomes.
The research results indicate that the limiting distribution is actually a point mass, lacking diversity or randomness, but this contradicts actual observed results. This apparent paradox is resolved by the long-lasting variable state of the particles. From Figures 2 and 4, it can be seen that Transformers have two different time scales: in the first phase, all tokens quickly form several clusters, while in the second phase (much slower than the first), through a pairwise merging process of the clusters, all tokens ultimately collapse into a single point.
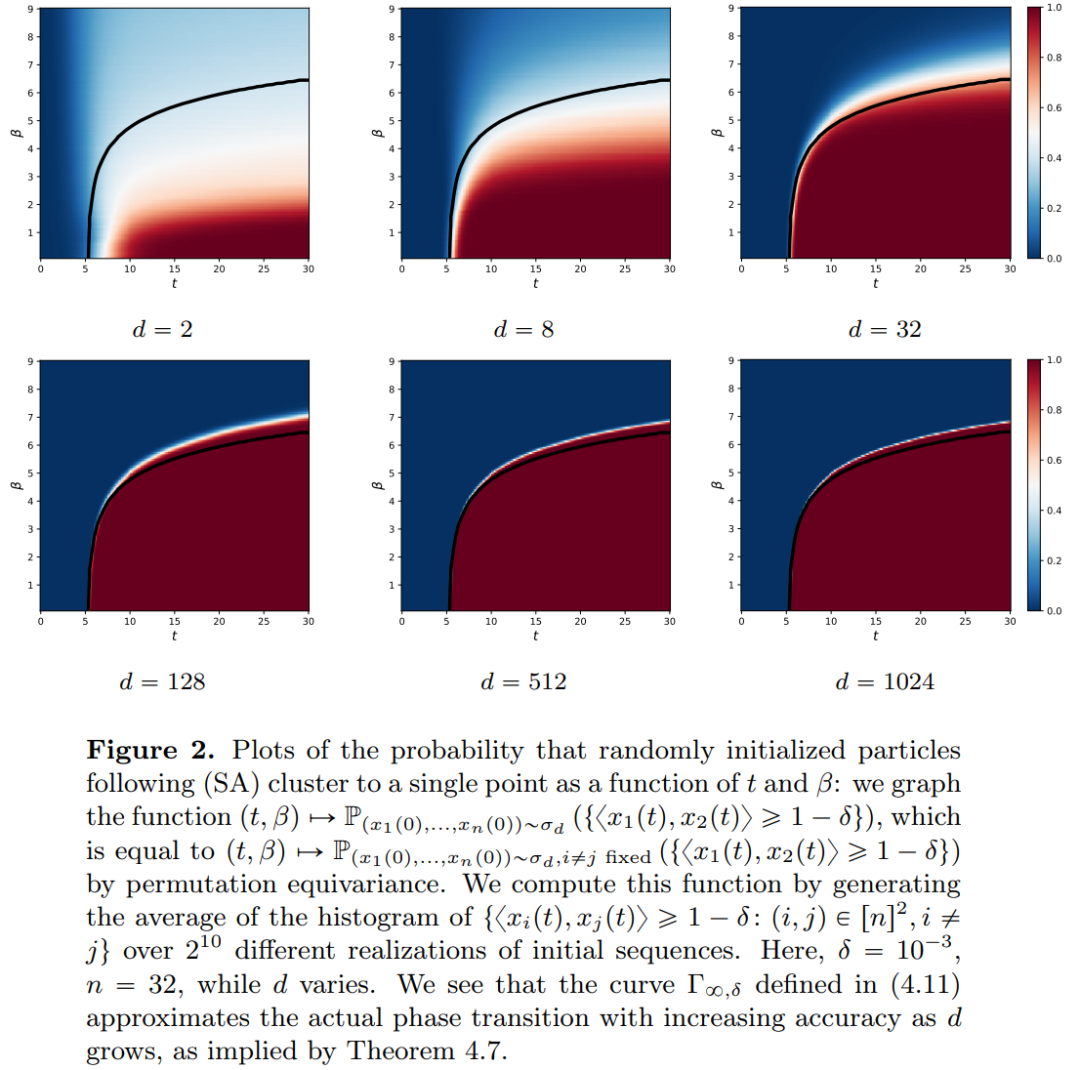
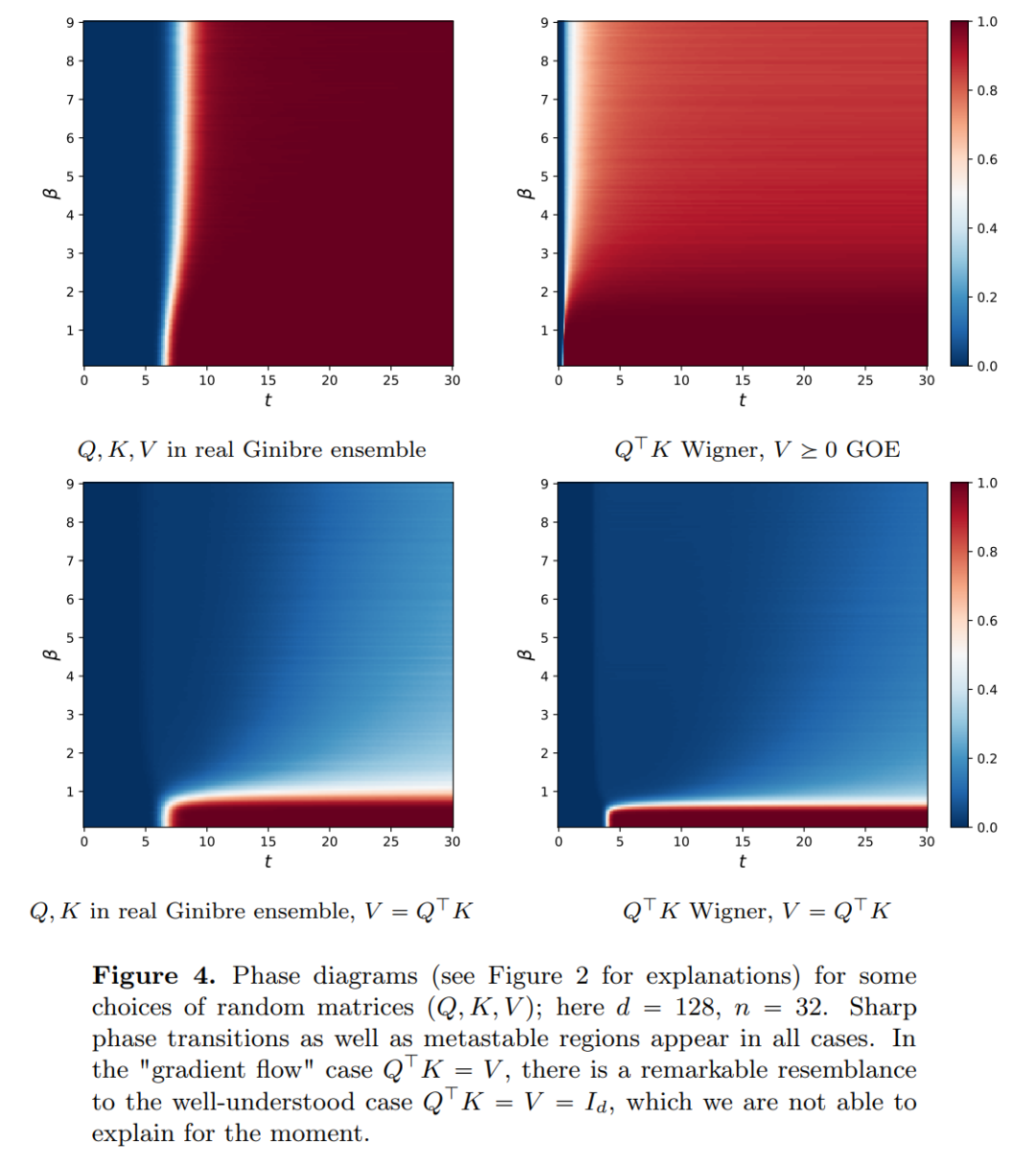
This article has two main objectives. On one hand, it aims to provide a general and easily understandable framework for studying Transformers from a mathematical perspective. In particular, through the structure of these interacting particle systems, researchers can make concrete connections with established themes in mathematics, including nonlinear transport equations, Wasserstein gradient flows, collective behavior models, and optimal configurations of points on spheres. On the other hand, this article describes several promising research directions, with a particular focus on clustering phenomena over long time spans. The main result indicators proposed by the researchers are all new, and they also present what they consider interesting open questions throughout the paper.
The main contributions of this article are divided into three parts.

Part 1: Modeling. This article defines an ideal model of the Transformer architecture, treating the number of layers as a continuous time variable. This abstract approach is not novel and is similar to methods used in classic architectures such as ResNets. The model in this article focuses solely on two key components of the Transformer architecture: the self-attention mechanism and layer normalization. Layer normalization effectively confines particles within the unit ball 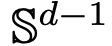 , while the self-attention mechanism achieves nonlinear coupling between particles through empirical measures. In turn, the empirical measures evolve according to continuous partial differential equations. This article also introduces a simpler and more user-friendly alternative model for self-attention, a Wasserstein gradient flow of an energy function, for which there are established research methods for optimal configurations of points on spheres.
, while the self-attention mechanism achieves nonlinear coupling between particles through empirical measures. In turn, the empirical measures evolve according to continuous partial differential equations. This article also introduces a simpler and more user-friendly alternative model for self-attention, a Wasserstein gradient flow of an energy function, for which there are established research methods for optimal configurations of points on spheres.
Part 2: Clustering. In this section, researchers present new mathematical results regarding token clustering over longer time spans. For instance, Theorem 4.1 indicates that a set of n particles randomly initialized on the unit sphere in high-dimensional space will cluster to a point over time. Researchers provide a precise description of the shrinking rate of the particle clusters to supplement this result. Specifically, researchers plot histograms of all pairwise distances between particles, as well as the time points at which all particles are about to complete clustering (see Section 4 of the original text). They also obtain clustering results without assuming a large dimension d (see Section 5 of the original text).
Part 3: Future Outlook. This article primarily poses questions in the form of open problems and confirms them through numerical observations, thus proposing potential routes for future research. Researchers first focus on the case where the dimension d = 2 (see Section 6 of the original text) and introduce connections with Kuramoto oscillators. They then briefly demonstrate how simple and natural modifications to the model can solve problems related to optimization on spheres (see Section 7 of the original text). The following chapters explore interacting particle systems, which may enable further practical applications in adjusting parameters within the Transformer architecture.

Scan the QR code to add the assistant on WeChat
About Us
