This article primarily explains the paper “RAT: Retrieval Augmented Thoughts Elicit Context-Aware Reasoning in Long-Horizon Generation”[1]. Currently, there are some relevant introductions available online, but most only discuss the ideas and mainly rely on GPT translations, which can be quite awkward and do not provide a detailed understanding of all principles. Therefore, a detailed description is provided here.
In general, this article combines CoT and RAG to propose RAT. First, multiple steps are generated by CoT, and then RAT is used to correct the information in each step to prevent hallucination issues that may arise during long text generation. My personal understanding is that RAT is more suitable for open-ended and long text generation scenarios. The reason is that its process first provides a preliminary answer through LLM and then corrects it, which is not very friendly for knowledge base-based short answer questions. The fundamental reasons are as follows:
-
Short answer questions often have unique answers, heavily relying on the specific content of the knowledge base, while LLM may lack relevant knowledge, and fine-tuning may not work well on this issue. -
The iterative process increases time consumption. For steps, LLM needs to be accessed times.
Of course, the limitations mentioned above are not issues with RAT; RAT is originally claimed to alleviate hallucinations in long text generation. How to integrate this capability into the question-and-answer scenario is worth learning from and thinking about.
Abstract
This article studies how to iteratively repair CoT under information retrieval to enhance the reasoning and generation capabilities of large language models in long text generation tasks while significantly reducing hallucination phenomena. The authors propose retrieval-augmented thoughts (RAT). The translation is a bit awkward, so here is the original text:
revises each thought step one by one with retrieved information relevant to the task query, the current and the past thought steps, after the initial zero-shot CoT is generated.
In summary, multiple steps are generated using CoT, and then RAG is added to each step to reduce model hallucinations and improve effectiveness. That is: RAG+CoT=RAT.
Experimental results show that applying RAT to GPT-3.5, GPT-4, and CodeLLaMA-7b can enhance performance; on average, code generation ability improved by 13.63%, mathematical reasoning ability improved by 16.96%, creative writing ability improved by 19.2%, and specific task planning ability improved by 42.78%.
Introduction
Currently, the combination of LLM and CoT has achieved good results in many tasks. Scholars point out that LLM’s answers and intermediate reasoning steps may exhibit hallucinations. In zero-shot CoT and long text generation (long-horizon generation), such as code generation, task planning, and mathematical reasoning, this issue becomes increasingly prominent. The factual validity of intermediate thoughts may be crucial when completing these tasks.
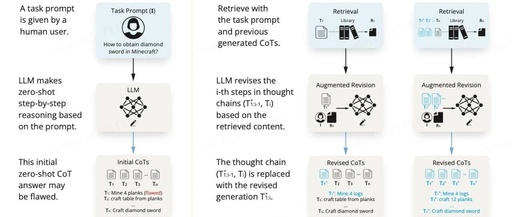
Some techniques are already available to alleviate this problem, such as using retrieved information in RAG to promote more fact-based reasoning. This article explores how to combine RAG with complex long-term reasoning. Before this, we have an intuition that with the help of external knowledge (RAG), we can mitigate hallucinations in the intermediate reasoning process (CoT). The proposed prompting strategy, namely retrieval-augmented thoughts (RAT), is illustrated in Figure 1.
The RAT strategy in this article consists of two key steps.
-
First, the initial zero-shot CoT generated by LLM. Due to model hallucinations, some steps may be incorrect. -
Second, this article designs a step-by-step approach rather than retrieving and correcting the entire CoT at once to generate the final response. LLM generates responses step by step according to CoT (a series of sub-tasks), and only the current thought step will be corrected based on retrieved information, current and past CoT, and task prompts. This strategy can be likened to the human reasoning process: when solving complex long-term problems, we can utilize external knowledge to iteratively adjust our thinking.
This article evaluates the RAT on a series of challenging long-term tasks, including code generation, mathematical reasoning, embodied task planning, and creative writing. The article uses several LLMs of different scales: GPT-3.5 (Brown et al., 2020), GPT-4 (OpenAI, 2023), CodeLLaMA-7b (Rozière et al., 2023). The results show that using RAT in conjunction with these LLMs has significant advantages compared to traditional CoT prompts and RAG methods. In particular, this article observes new highest performance levels on the selected tasks:
-
Code generation: HumanEval (+20.94%), HumanEval+ (+18.89%), MBPP (+14.83%), MBPP+ (+1.86%) -
Mathematical reasoning problems: GSM8K (+8.36%), GSMHard (+31.37%) -
Minecraft task planning (improved by 2.96 times in executability, improved by +51.94% in rationality) -
Creative writing (improved by +19.19% in human scoring).
This article’s additional ablation studies further confirm the role of the two key components in RAT: using RAG to revise CoT and stepwise revision and generation. This work reveals how LLM can correct its reasoning process in a zero-shot scenario with the aid of external knowledge, just as humans do.
Retrieval-Augmented Thoughts
Our goal is to support long reasoning and generation while utilizing large language models (LLMs) and reduce the occurrence of hallucinations. To achieve satisfactory performance on long-term tasks, two elements facilitate this. However, simply combining the two does not necessarily lead to improvement.
-
What relevant information should be retrieved; -
How to effectively utilize the relevant factual information to correct reasoning steps. To better understand the method in this article and why it can solve these two problems, we first briefly introduce the concepts of RAG and CoT.
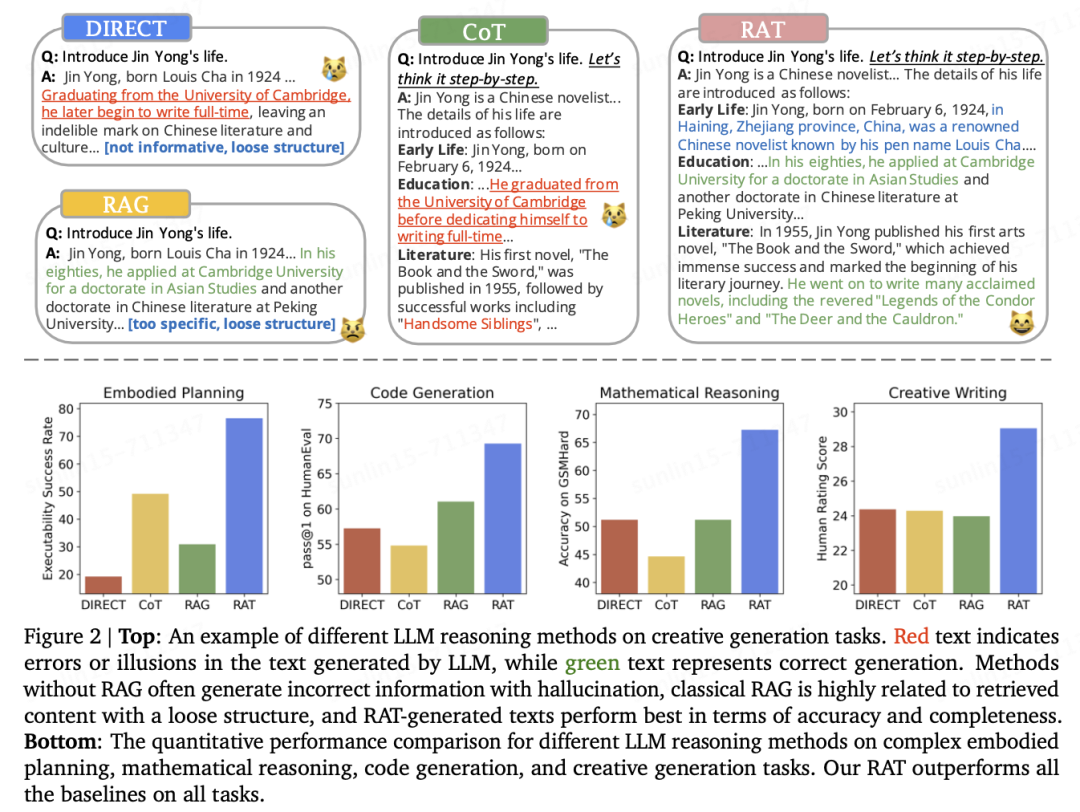
RAG: Aims to address the issue of large language models generating fictitious facts by providing relevant text extracted from credible sources, generally used for question-and-answer (QA) tasks. In simple terms, it first finds content related to the question based on relevance and then concatenates the relevant content with the user question to give to the large model. However, complex reasoning tasks (e.g., those requiring multi-step reasoning) are challenging to translate into effective search queries, which leads to difficulties in finding relevant documents. Traditionally, RAG retrieves all relevant information at once. However, it overlooks the fact that it is difficult to predict which “facts” or information will be needed in subsequent reasoning and generation steps. The task prompts themselves provide almost insufficient clues for this.
CoT: Aims to enhance LLM performance in tasks that require complex reasoning steps, such as multi-step mathematical application problems. Specifically, CoT prompts do not directly ask LLM to generate the correct answer, but rather encourage LLM to output intermediate reasoning steps first, which are referred to as “thoughts”. This behavior of LLM can be triggered through prompts, such as the famous “Let’s think step by step” or by executing a few sample examples in similar tasks. However, since there is no direct supervision over the intermediate thoughts, LLM may make mistakes due to a lack of relevant domain knowledge or be biased by fictitious information.
▶RAT = RAG + CoT
Our intuition is that to alleviate the aforementioned issues with CoT prompts and RAG, this article applies RAG to revise each thought step generated by CoT prompts. Specifically, for a task prompt, we first generate multiple thought steps through a zero-shot prompt. In long text generation tasks, these can be intermediate reasoning steps, such as commented pseudocode in code generation or an outline in creative writing.

However, the thoughts in this process may have issues, such as model hallucinations. Therefore, the final responses generated based on these thoughts may be biased, so RAG is used to correct the generated thoughts. Specifically, assuming we have fixed the previous thought steps and are now ready to revise, we first convert the text into a query:
Where ToQuery(·) can be a text encoder or an LLM that transforms the task prompt, current and past thought steps into a query that can be processed by the retrieval system.
We use RAG to retrieve relevant documents and then prepend these documents to the prompt to generate revised thought steps:
Finally, depending on the actual task, the revised thought steps can be directly used as the final model response. For tasks like code generation or creative writing, LLM will be further prompted to generate complete responses (code, articles) from each revised thought step. The formula here may seem confusing at first, but in practice, it is just utilizing prompts.
It is important to note that when revising the th thought step, we do not solely use the current step or the complete thought chain to generate queries for RAG; we ensure that the query is generated from the current thought step and previously revised thought steps, meaning this article adopts causal reasoning to use RAG to revise thought steps.
This allows for correcting errors in the original thought steps by continuously referencing different reference texts and ensures that each reasoning step is supported by the most accurate and relevant information, significantly improving the quality and reliability of the generated output.
Why is this method considered useful? We believe there are two aspects:
-
The most direct way to understand what information will be used in complex reasoning is to “observe” the reasoning steps. The method in this article utilizes all generated thought steps and task prompts to provide more clues for more effective retrieval. -
Some information cannot be retrieved directly, especially information related to the final answer of difficult complex problems. Instead, it is more feasible to retrieve information related to intermediate questions that are easier to hypothesize. Thanks to the combinatorial nature of many reasoning tasks, the iterative retrieval process may also be more effective. -
It is necessary to target and correct potential fictitious information. Using RAG to revise the entire CoT may introduce errors in other already correct steps. Revising each step one by one may be more reliable.
Experiments
Next, the authors conducted a series of experiments to validate the RAT method, focusing on long text generation and reasoning. This article employed four sets of benchmark tests.
-
Code generation: Including HumanEval, HumanEval+, MBPP, and MBPP+. These benchmark tests cover a wide range of programming problems, from simple function implementations to more complex algorithm challenges, providing a robust testing platform for evaluating generative capabilities. The classic pass@k metric was used as the evaluation indicator, where represents the number of samples. -
Mathematical reasoning evaluation: Conducted on GSM8K and GSM-HARD datasets, which contain thousands of multi-step mathematical problems. Accuracy was used as the evaluation metric. -
Creative writing tasks: Evaluating the diversity of RAT, including investigation, summarization, etc., highlighting different aspects of open-ended text generation. Human evaluation was conducted to calculate true_skill scores. -
Embodied planning tasks: Evaluated in the open environment Minecraft. A series of 100 tasks, ranging from simple goals to challenging diamond goals, were assessed via MC-TextWorld. The planning execution success rate was calculated as executability as the evaluation metric. Similar to creative writing tasks, human elo scoring evaluation was also conducted.
Baseline methods. To establish a comprehensive and fair comparative environment, this article incorporated a series of baseline methods. The baselines in this article include the original language model, referred to as DIRECT, and the retrieval-augmented generation (RAG) method with retrieval examples implemented in single-shot (1 time) and multi-shot (5 times) configurations. Additionally, this article examined zero-shot CoT (CoT). For different methods, the same language model was used as the base model.
RAG settings. RAT utilizes the powerful capabilities of retrieval-augmented generation methods, which enhance language model performance by integrating external knowledge sources. Specifically, this article used the codeparrot/github-jupyter dataset as the main search vector database for code generation and mathematical reasoning tasks. For embodied planning tasks in Minecraft, this article used the Minecraft Wiki1 and DigMinecraft2 websites as information sources accessible to LLMs. For open-ended creative writing tasks, this article used Google to search queries on the internet. The OpenAI text-embedding-ada-002 API service was used for all embedding calculations for different methods and base models.
Considering the risk of benchmark contamination (a potential issue that may lead to the codebase containing solutions to the exact problems being evaluated), this article adopted the rigorous preprocessing methods described by Guo et al.
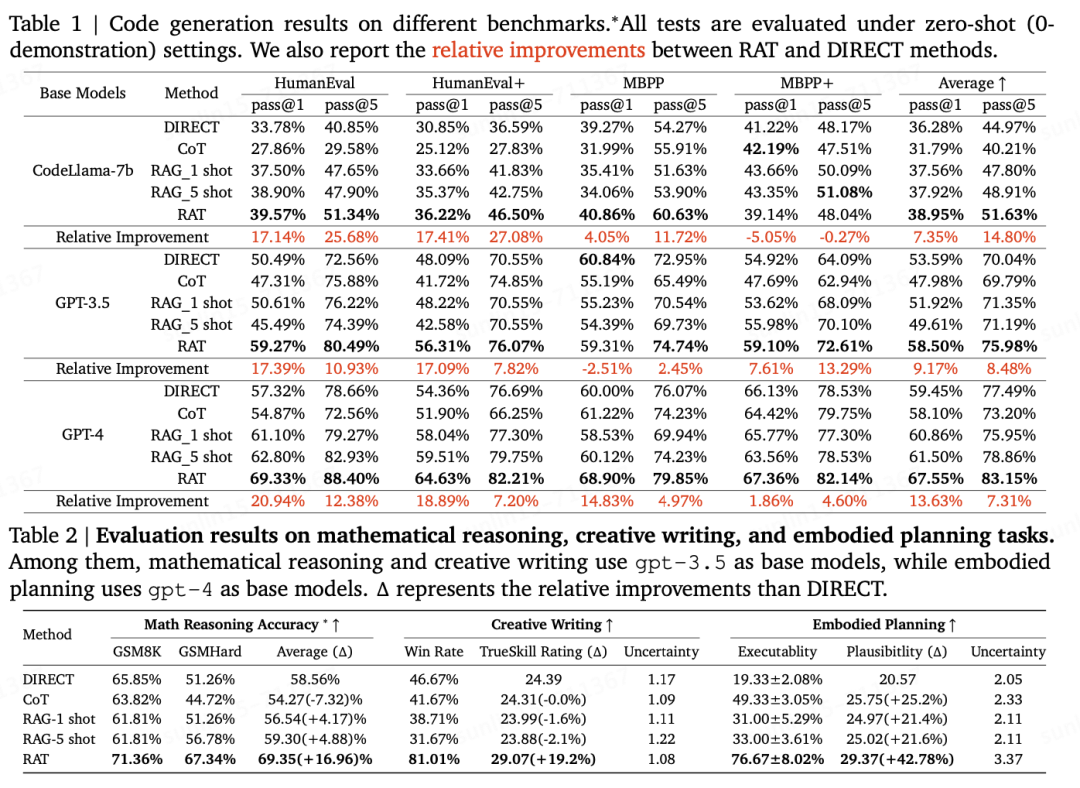
The summary of the experimental results can be stated in one sentence: the four experimental results demonstrate that RAT is impressive, significantly improving the accuracy and efficiency of generating context.
▶Ablation Studies
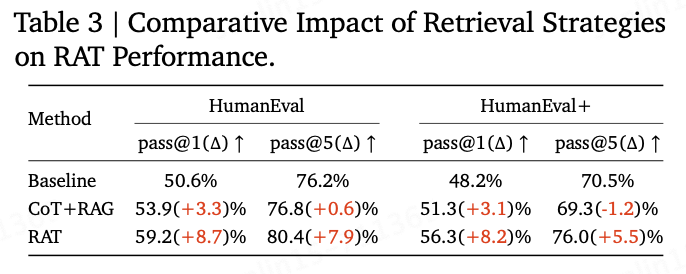
Ablation study of retrieval in RAT. In this ablation study, this article explores the impact of different retrieval strategies on the effectiveness of RAT, focusing on improving the quality of generated output through optimized content retrieval. The experimental results detailed in Table 3 indicate that RAT achieves significant progress through iterative refinement of retrieval queries compared to baseline methods. In contrast, CoT+RAG aims to obtain a broader understanding of content by using the entire reasoning thought output from the language model as queries. However, RAT introduces a more dynamic approach by using the continuously modified reasoning thought parts as queries, allowing for a more focused and relevant information retrieval process. Comparative analysis shows that RAT outperforms the baseline and CoT+RAG methods on the pass@1 and pass@5 metrics of the HumanEval and HumanEval+ benchmarks. Notably, in the HumanEval benchmark, RAT improved pass@1 by 8.7 percentage points compared to the baseline and achieved an impressive gain of 7.9 percentage points in pass@5 in the HumanEval+ benchmark. These improvements highlight the effectiveness of the RAT retrieval strategy, which ensures the retrieval of highly relevant information by iteratively refining subsequent queries based on evolving reasoning thoughts and previous queries. This process not only enhances the relevance of the retrieved information but also significantly improves the quality and accuracy of the final generated output. The results firmly establish the advantages of RAT’s dynamic retrieval method in driving more precise and effective generation processes by leveraging contextual nuances.
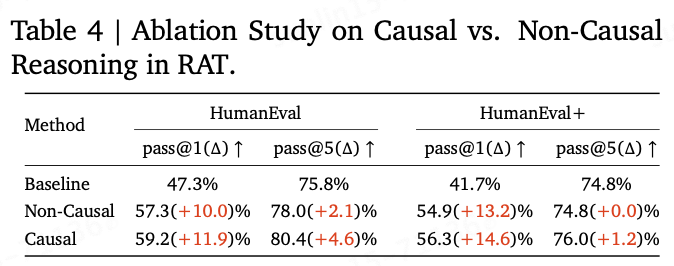
Ablation study of causal reasoning in RAT. In this ablation study, this article systematically examines the impact of causal reasoning and non-causal reasoning methods on the performance of the RAT system, using the reasoning chain as a baseline. The findings of this article reveal a significant improvement in generative capabilities when introducing causal reasoning techniques. Specifically, the causal method, which iteratively conducts reasoning and retrieval, brought significant improvements in both pass@1 and pass@5 metrics on the HumanEval and HumanEval+ benchmarks. For instance, on the HumanEval dataset, the causal method improved pass@1 by 11.9 percentage points compared to the baseline (CoT) and by 4.6 percentage points in pass@5. This method contrasts with the non-causal method, which also surpassed the baseline but directly retrieved all necessary steps using the initial reasoning thoughts to generate the final answer. The superior performance of the causal method emphasizes the value of sequential reasoning and information retrieval in enhancing the accuracy and reliability of generated output. This iterative process may help refine searches and reasoning steps based on continuously updated contexts, allowing for more precise and relevant information retrieval, thereby supporting more accurate final answers. These results firmly establish the effectiveness of causal reasoning in long-term problem-solving tasks.
▶RAT Robustness
The experiments demonstrate that RAT’s capabilities have been validated across various tasks, including code generation, mathematical reasoning, creative writing, and embodied planning. The diversity of these tasks highlights the generalization ability of RAT, proving its robust performance in highly diverse challenges. Moreover, all experimental setups in this article were conducted in a zero-shot manner, without designing specific task prompts for RAT, instead using the simplest prompts possible to express questions or instructions for all methods. This approach ensures RAT’s generalization ability in open-ended scenarios.
The diversity of the evaluation is further enhanced by testing RAT on a range of language models of different capacities. This includes CodeLlama-7b, ChatGPT (gpt-3.5-turbo), and the more advanced GPT-4 (gpt-4) models. Notably, RAT maintains its generalization ability across different scales of language models, showing improvements on benchmarks such as HumanEval for code generation tasks. It is particularly noteworthy that the most significant improvements were observed when using GPT-4, attributed to its superior contextual learning ability from retrieved texts. In MBPP+, RAT based on CodeLlama-7b showed a performance decline. This decline may be due to the limited contextual learning capabilities of smaller language models.
For mathematical reasoning tasks, RAT demonstrated significant relative improvements, achieving an overall average improvement of 18.44% when applied to the GPT-3.5 model. This trend of improvement persisted when using GPT-4, which achieved an astonishing relative improvement of 10.26% from DIRECT to RAT. These findings highlight RAT’s robustness and its ability to effectively enhance language model performance across computational and creative tasks.
Conclusion
This article presents retrieval-augmented thoughts (RAT), which combines chain-of-thought (CoT) prompts with retrieval-augmented generation (RAG) to address challenging long-term reasoning and generation tasks. The key ideas of this article include using RAG to revise the zero-shot thinking chain generated by LLMs as queries and incrementally revising thoughts and generating responses in a causal manner. RAT, as a zero-shot prompting method, has demonstrated significant advantages over ordinary CoT prompts, RAG, and other baseline methods in challenging tasks such as code generation, mathematical reasoning, embodied task planning, and creative writing.
Process Details Exploration
The prompts are divided into three levels (translated directly into Chinese by GPT):
-
Generating initial answers (prompt1): Although CoT claims to be “step-by-step”, it is actually single-round. Therefore, it is necessary to parse out which steps/thoughts are from the single-round answer. A trick is used here to have LLM output different steps by using line breaks. -
Generating search queries (prompt2): The process is to summarize what the current text has written and then retrieve relevant knowledge based on the summary. Prompt2 serves as the input for generating RAG. -
Revising answers based on retrieved context (prompt3): Before prompt3, RAG is performed to obtain relevant content, and then the current answer is revised based on that relevant content.
prompt1 = """
Try to answer this question/instruction using step-by-step thinking and make the answer more structured.
Use `\n\n` to separate the answer into several paragraphs.
Directly respond to the instruction. Do not add extra explanations or introductions unless requested.
"""
prompt2 = """
I want to verify the content accuracy of the given question, especially the last few sentences.
Please summarize the content with the corresponding question.
This summary will be used as a query for the Bing search engine.
The query should be brief but specific enough to ensure Bing can find relevant knowledge or pages.
You can also use search syntax to make the query brief and clear enough for the search engine to find relevant language data.
Try to make the query as relevant as possible to the last few sentences in the content.
**Important**
Directly output the query. Do not add extra explanations or introductions unless requested.
"""
prompt3 = """
I want to revise the answer based on the relevant text learned from the Wikipedia page.
You need to check if the answer is correct.
If you find any errors in the answer, please revise it to make it better.
If you find that some necessary details have been overlooked, please add those details based on the relevant text to make the answer more credible.
If you find the answer is correct and does not need more details, please output the original answer directly.
**Important**
Try to maintain the structure of the revised answer (multiple paragraphs and their subheadings) to make it more structured for understanding.
Separate paragraphs with `\n\n` characters.
Directly output the revised answer. Do not add extra explanations or statements in the revised answer unless requested.
"""
The open-source code CraftJarvis/RAT[2] includes some engineering handling (such as timeout handling, etc.), which will not be elaborated here.
Finally, let’s look at a specific case comparing LLM and RAT, as shown in the figure below. It can be seen that RAT’s results are more comprehensive, and based on the process analysis, it can also better avoid hallucinations.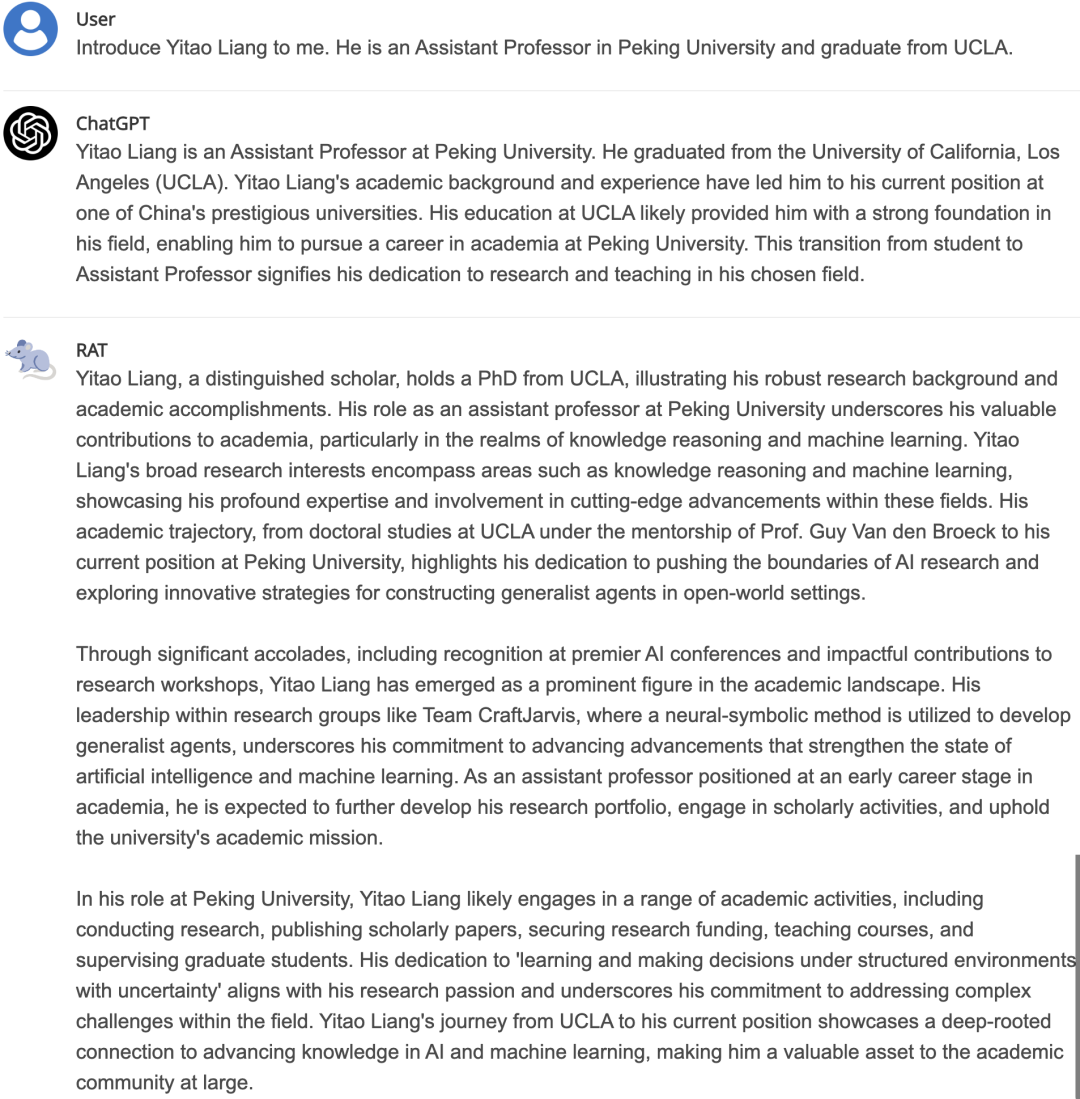
References
“RAT”: https://arxiv.org/abs/2403.05313
[2]CraftJarvis/RAT: https://github.com/CraftJarvis/RAT