
Recently, while writing articles, I wanted to fill in some gaps left by last year’s RAG (Retrieval-Augmented Generation) and hope to share some tips to help everyone with RAG.
As the old saying goes:
Building a prototype of a large model is easy, but turning it into a product that can actually be put into production is very difficult.
This article is suitable for those who have just built their first LLM (Large Language Model) application in the past month and are starting to consider how to commercialize it. We will introduce 17 techniques to help you avoid repeating mistakes during the RAG development process—after all, falling into the same pit twice is a waste of time! With these tips, you can gradually optimize the technical solutions of large models, improving the effectiveness and stability of RAG in practical applications.
Production Data Is the Cornerstone of LLM Implementation
There is no doubt that LLMs are becoming more powerful, but if we take a closer look, there are actually not many products that completely rely on pure large models.In most cases, large models play only a supporting role.So, what are the key factors for improving RAG performance?It’s still those not-so-glamorous things:
Data quality—data preparation—data processing.
Whether during the application run or while preparing raw data, we need to process, classify, and extract useful information from data to ensure the results move in the right direction.
If we just sit back and wait for increasingly larger models to solve all problems without handling data and processes, that is clearly unrealistic.
Perhaps one day, we can throw all the messy raw data directly to the model and magically get useful results. But even when that day comes, whether this approach is reasonable and applicable from a cost and performance perspective is still questionable.
Before delving into advanced techniques of RAG, let’s briefly review Naive RAG (the simplest RAG system) and expand on that basis. If you are already very familiar with Naive RAG, you can skip this part.
Naive RAG — Brief Review
The core idea of RAG is to stand on the shoulders of giants, leverage existing concepts and technologies, and combine them in appropriate ways.Many technologies actually originate from the search engine field.Our goal is to build a process around LLMs that provides the model with the right data to help it make decisions or summarize information.
The following diagram shows a series of techniques we use when building such a system.
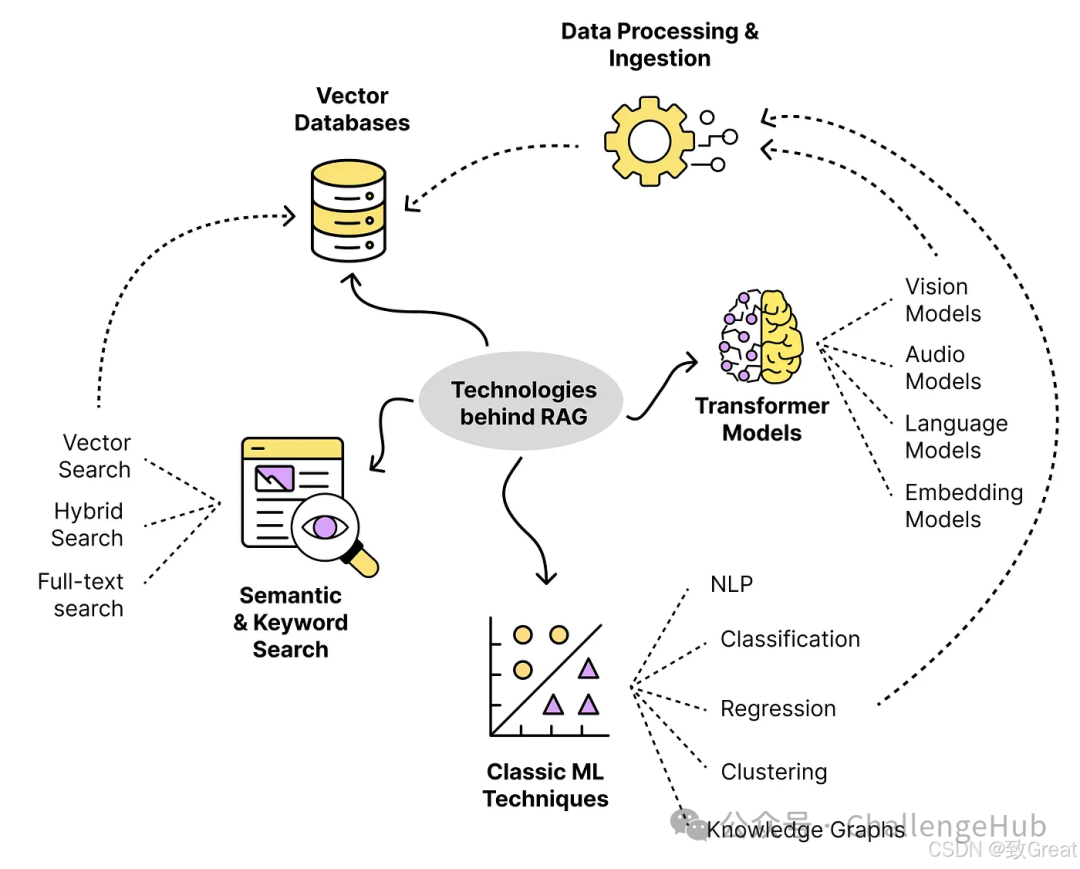
In addition to the Transformer model, we also use many techniques, such as:
-
Semantic search techniques -
Techniques for preparing and processing text data -
Knowledge graphs, smaller classification/regression/NLP models, etc.
All these techniques have been around for years. The vector search library FAISS was released in 2019. Additionally, text vectorization is not a new concept.
RAG is simply about connecting these components to solve specific problems.
For example, Bing Search is combining their traditional “BING” web search with the capabilities of LLMs. This allows their chatbot to answer questions about “real” life data. Here’s an example question:
“What is Google’s stock price today?”
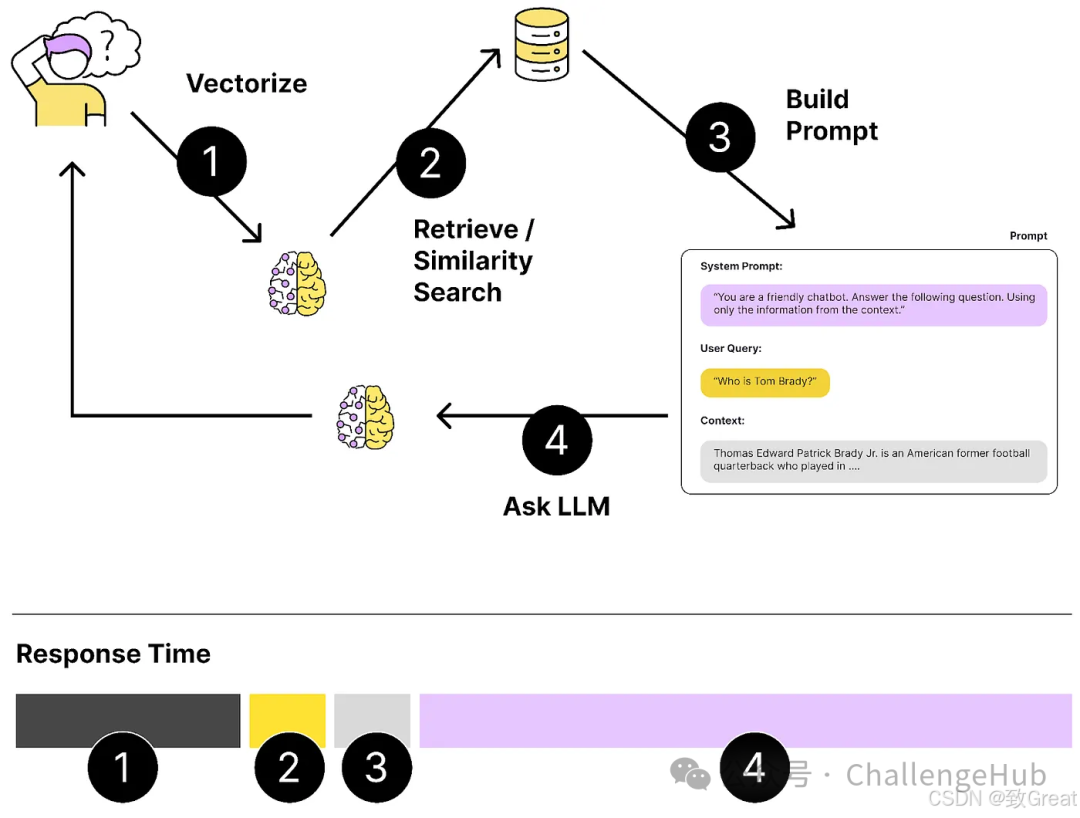
The following diagram illustrates the standard RAG process. When a user asks a question, Naive RAG directly compares the user’s question with any content in our vector library.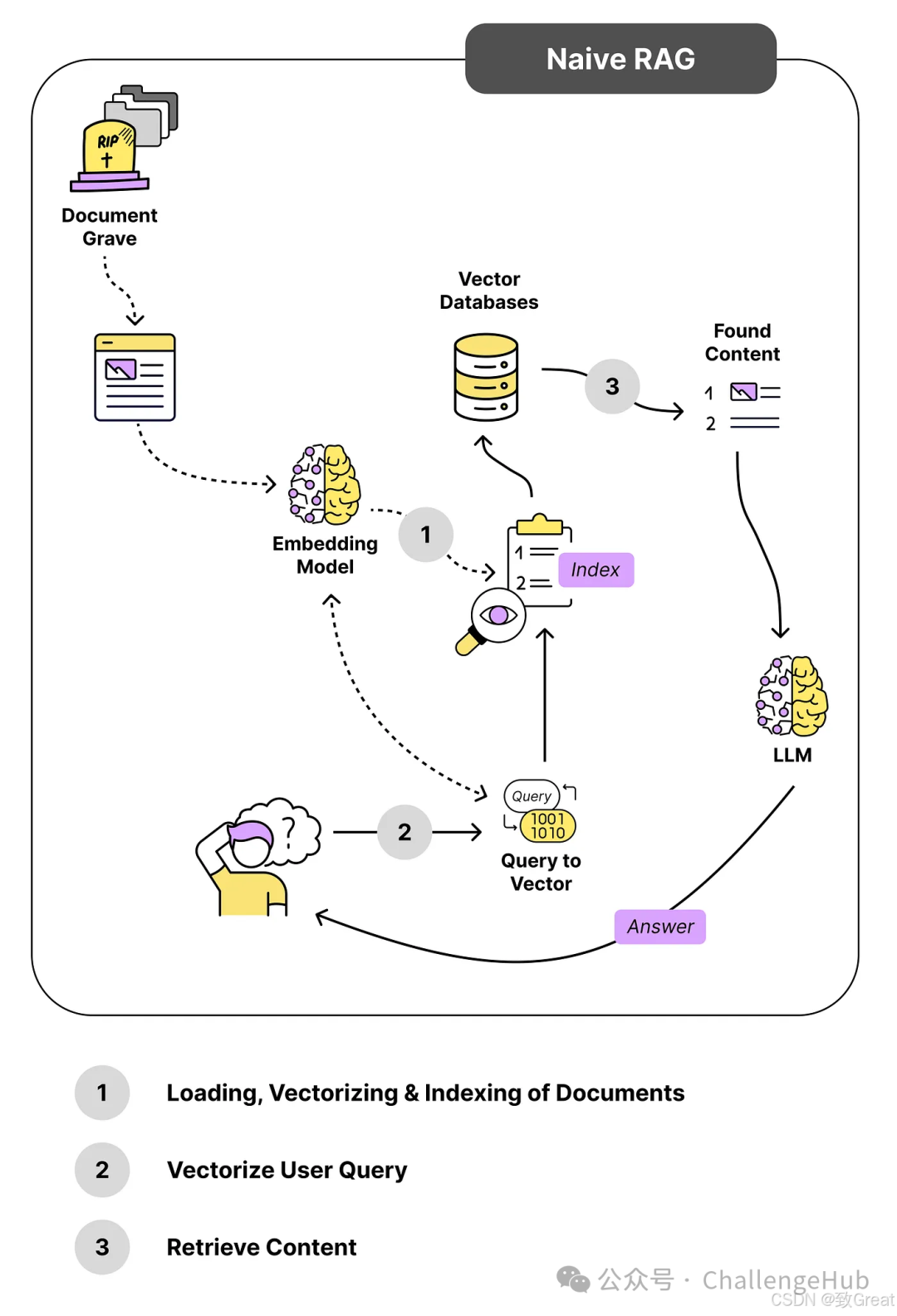
What we care about is finding content similar to the query. Similar content is that which is close to each other in our vector space, and the distance can be measured by calculating cosine similarity.
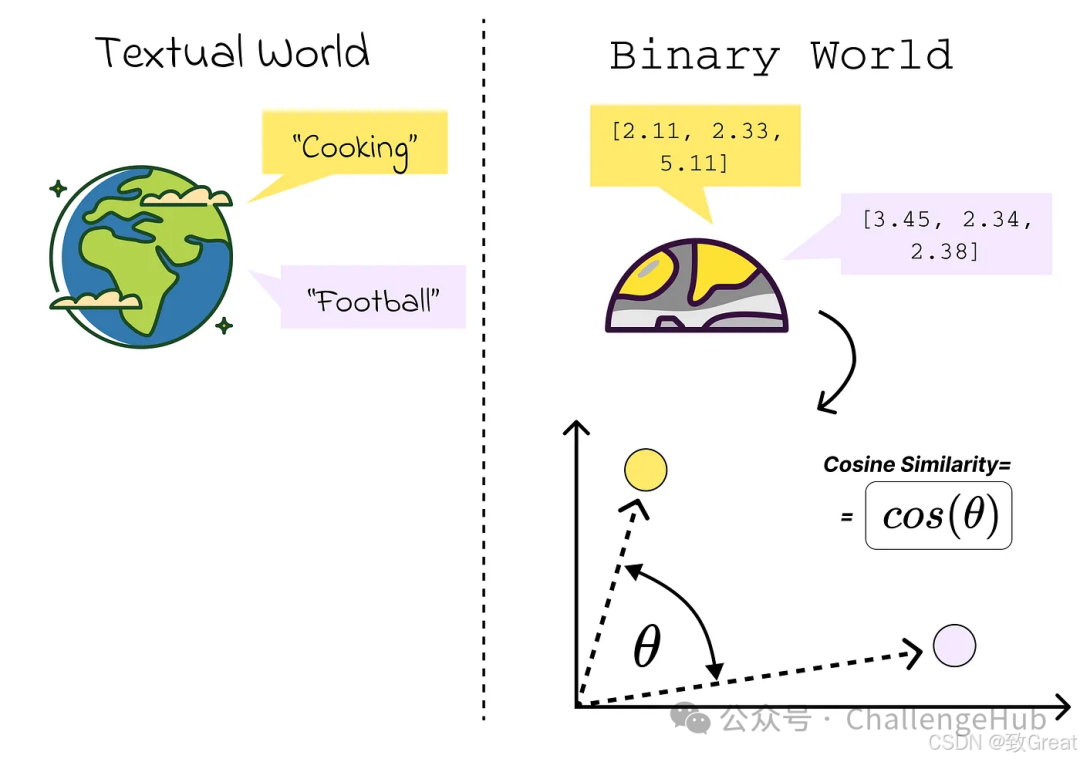 For example, the question:
For example, the question:
Question: “What position did Tom Brady play?”
Assuming our vector database has two main data sources:
-
Tom Brady’s Wikipedia article.
-
An article from a cookbook.
In the example below, the content from Wikipedia should be more relevant and therefore closer to the user’s question.
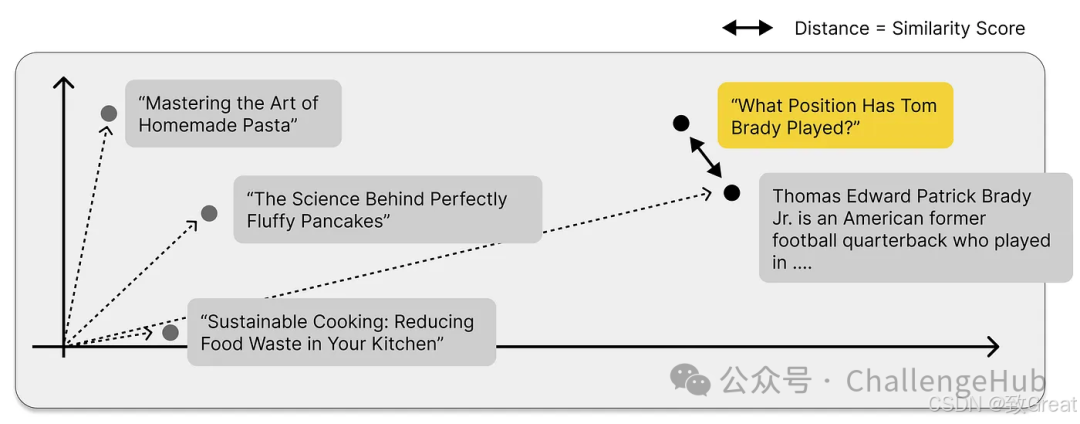
But how similar is “similar” enough?
It’s difficult to set a threshold for similarity scores to clearly distinguish relevant from irrelevant content. You can try it yourself, but you might find this approach impractical.
Found relevant content? Then let’s build prompts!
Now that we have found some content similar to the user’s question, the next step is to package them into a meaningful prompt. Typically, this prompt contains at least three parts:
-
System prompt: Telling the LLM how to answer the question. -
User question: The actual question posed by the user. -
Context: Relevant documents found through similarity search.
A suitable prompt template might look like this: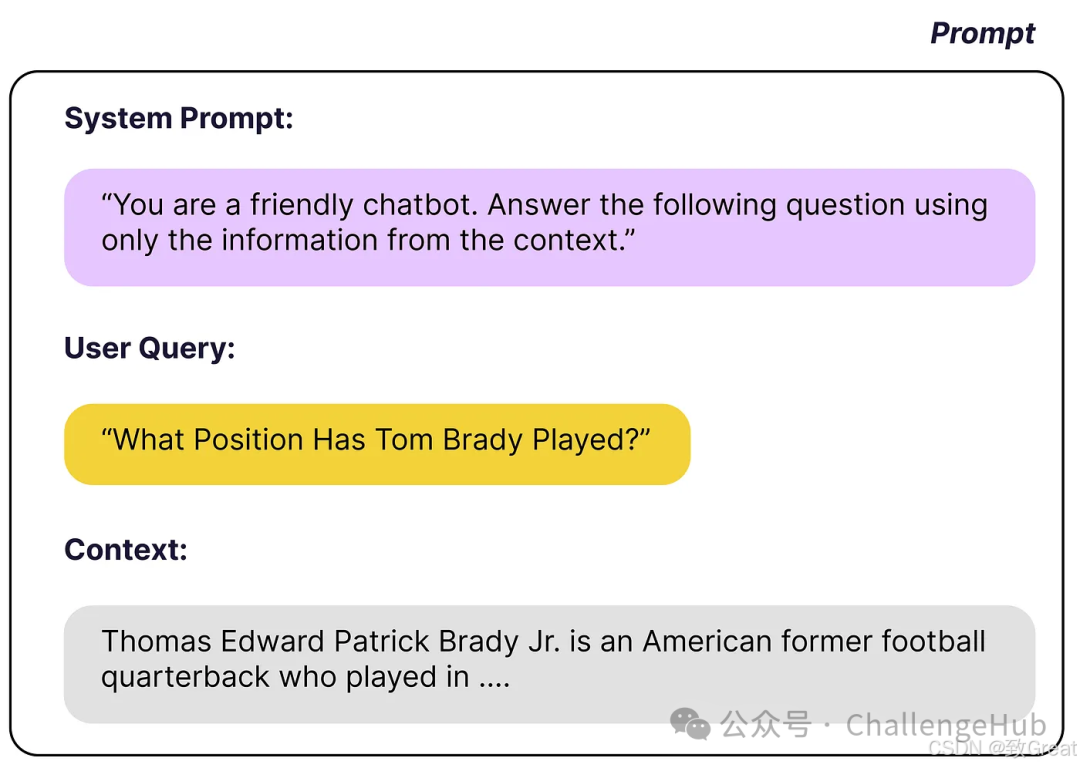
The part in the system prompt "...only use the provided information" effectively turns the LLM into a tool for processing and interpreting information. In this case, we are not directly using the model’s own knowledge to answer the question but relying on the provided content.
See, it’s that simple. A vector store, an embedding model, an LLM, a few lines of Python code, plus some documentation can build a basic prototype.
However, when we try to scale these systems and turn them from prototypes into truly effective solutions, real-world issues begin to emerge.
During this process, we are likely to encounter various traps, such as:
-
Valuable content vs. distractions: While nearest neighbor search can always find some relevant content, how relevant are these contents? We call those data points that are unrelated to answering the user’s question “distractions.” They can muddle the results and even mislead the model.
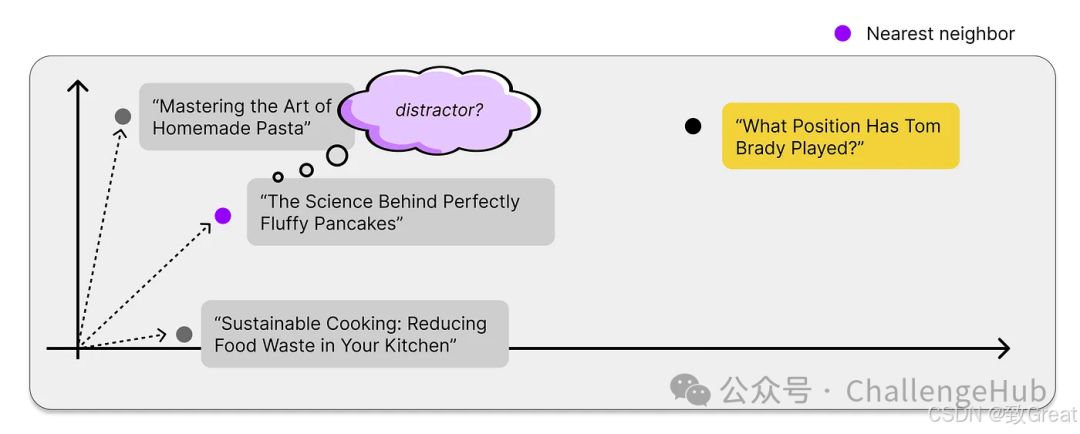
-
Block optimization: How large should each content segment be to be specific enough while containing enough context? -
Monitoring/evaluation: How do we monitor and evaluate the performance of the solution during system operation? (LLMOps) -
Agent/multiple prompts: For more complex queries, how do we solve them through multiple prompts or agent mechanisms instead of relying on a single prompt?
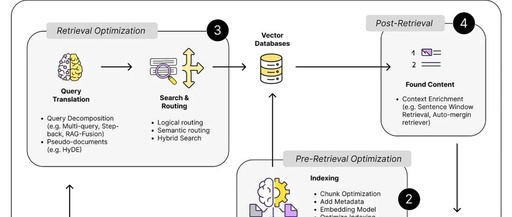
How to Deal with Potential Traps in RAG?
As mentioned earlier, RAG systems consist of multiple interacting components.This gives us various ways to enhance the overall system’s performance.
In simple terms, we can start by trying to optimize the following five process steps:
-
Pre-retrieval: Importing embedding data into the vector store. -
Retrieval: Finding content related to the question. -
Post-retrieval: Preprocessing the retrieved content before sending it to the LLM. -
Generation: Using the provided context to solve the user’s question. -
Routing: Handling the overall routing of requests, such as using agent methods to decompose the question and interact with the model multiple times.
By looking for optimization points in these steps, we can better address potential issues in RAG systems, thereby enhancing overall performance.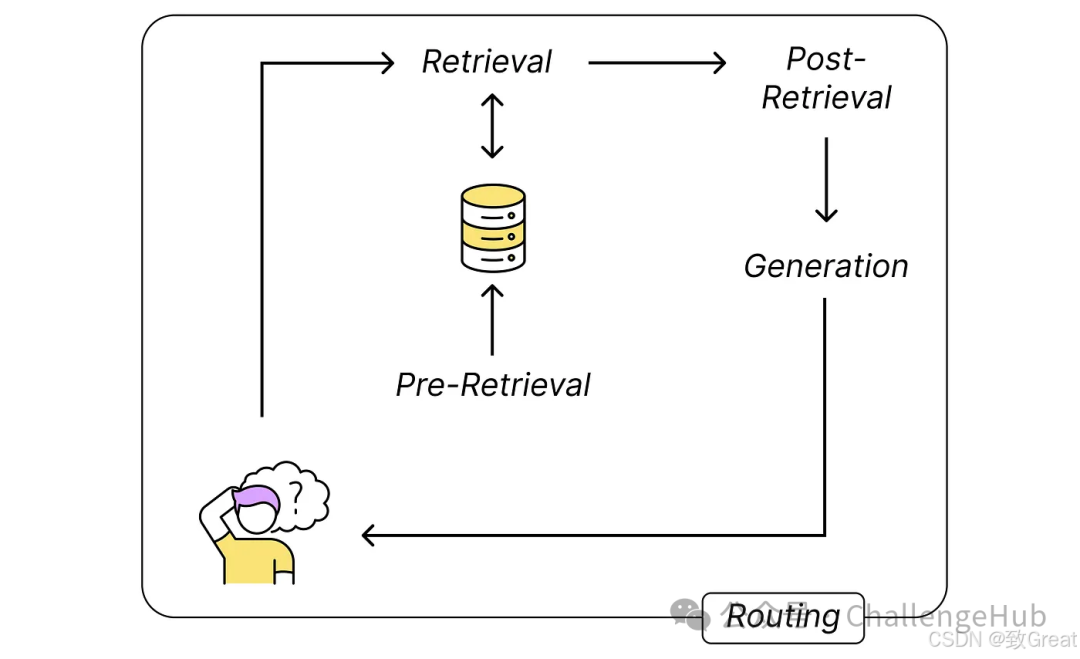 If we carefully consider the RAG process, we will roughly get the following image.
If we carefully consider the RAG process, we will roughly get the following image.
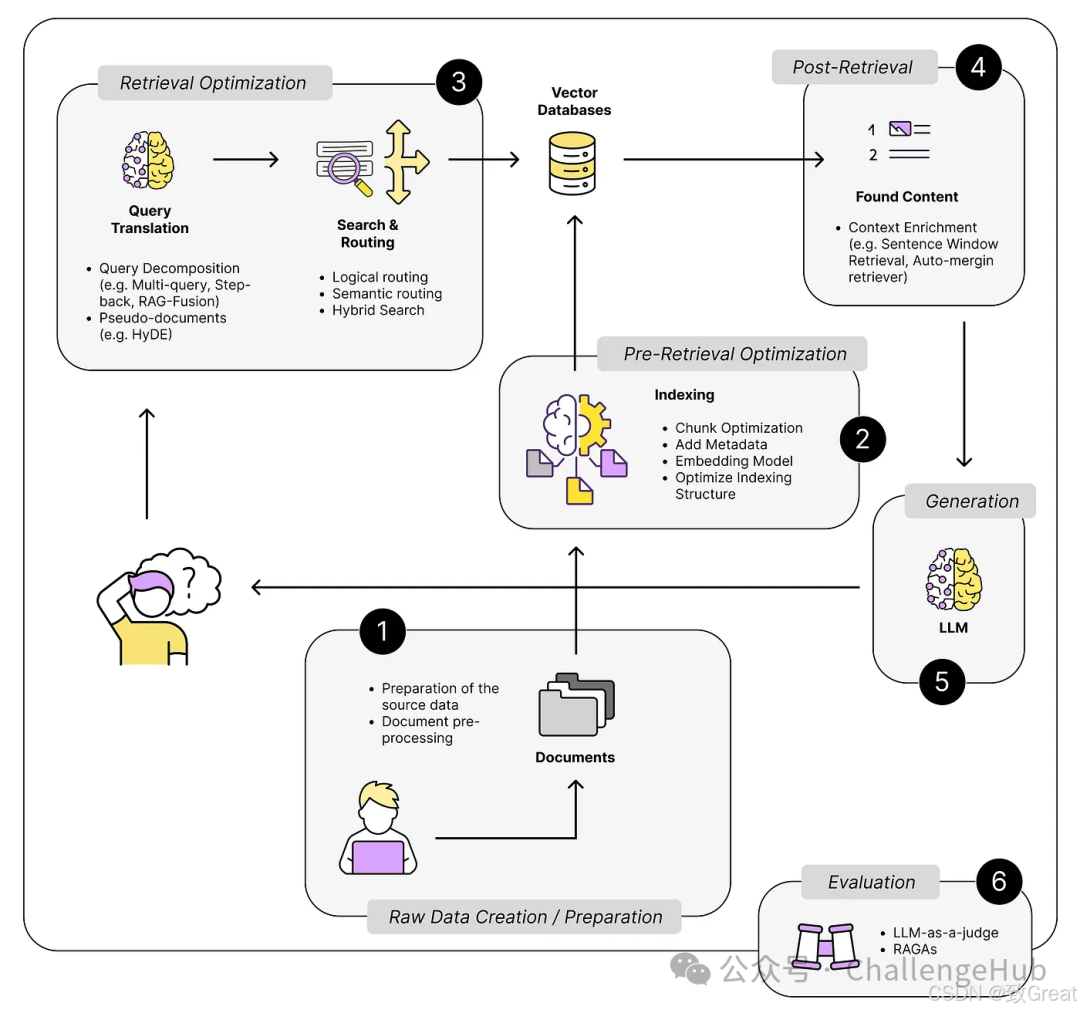
Let’s take it step by step.
First, we start with the most obvious and straightforward method—data quality. For most RAG use cases, data is usually in text form, such as some Wikipedia articles.
1. Creating/Preparing Raw Data
We don’t always have to rely solely on existing content. Many times, we can actively influence the document creation process.
With the emergence of LLMs and RAG applications, we suddenly need to build our own knowledge base. In Naive RAG, we search for information fragments that have some similarity to the user’s question.
This way, the model does not see the entire context of Wikipedia but only scattered text fragments. Problems arise when the documents contain:
-
Abbreviations for specific fields or even specific documents -
Text paragraphs linking to other parts of Wikipedia
If someone without background knowledge finds it difficult to understand the full meaning of the text fragments, then the LLM will encounter the same difficulties.
In the latter part of this article, you will find some techniques that attempt to address these issues after or during the retrieval step.
Ideally, we shouldn’t need these techniques at all.
Every part of our Wikipedia should be as easy to understand as possible, which not only helps human readers but also improves the performance of RAG applications. It’s a win-win situation.
The following example shows how to set up content correctly to make our RAG application work more smoothly.
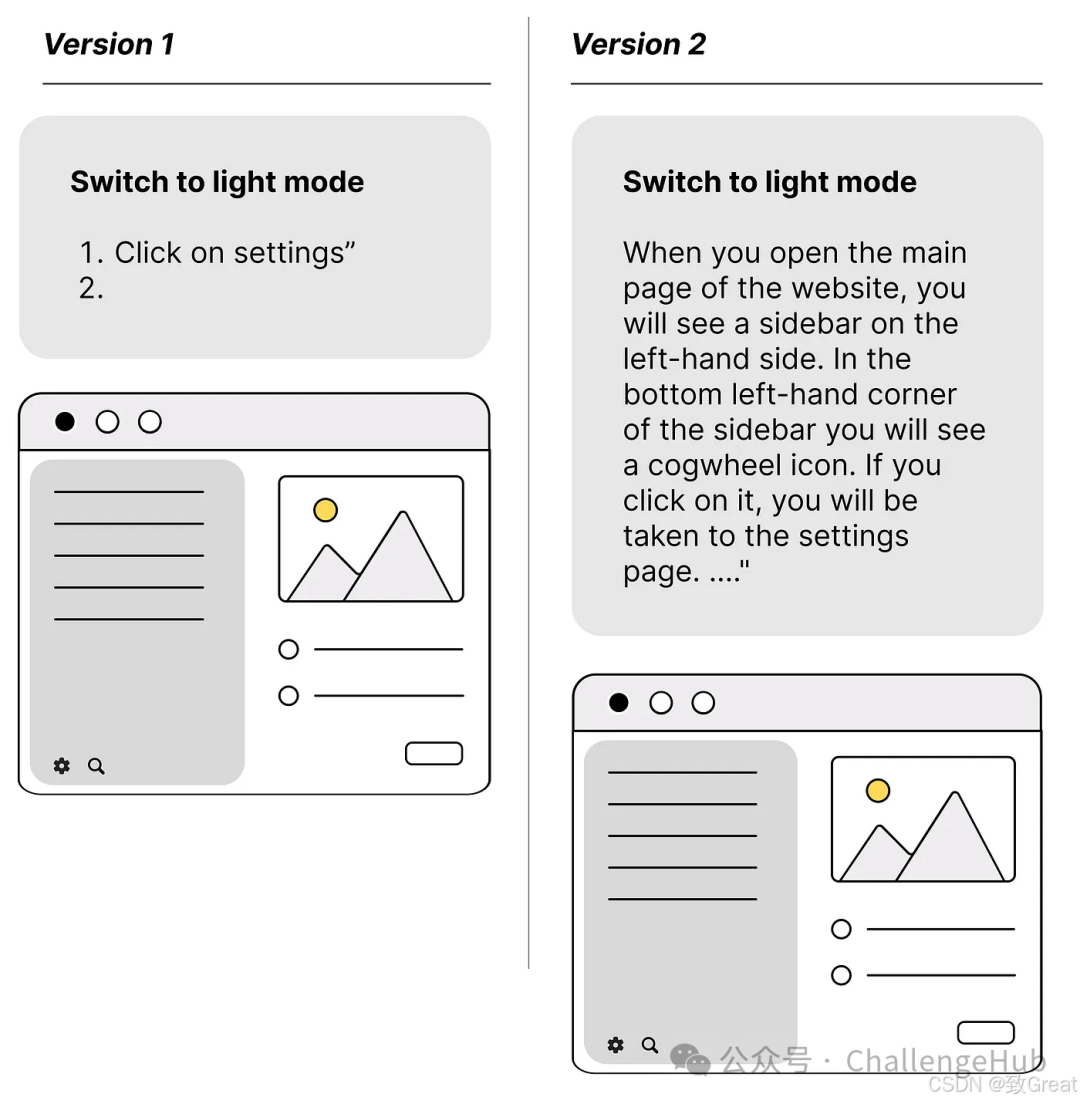
Tip 1: Prepare Data in an Obvious Way with Text Blocks
In the diagram below, you can see an example common in tutorials and technical documents. If we don’t have a pure LLM or multimodal model, the LLM will struggle to fully understand the content in Version 1 on the left. Version 2 at least gives it a better chance of understanding.
 The next step in the RAG process is to chunk the data in a meaningful way, converting it into embeddings and then indexing it.
The next step in the RAG process is to chunk the data in a meaningful way, converting it into embeddings and then indexing it.
2. Indexing/Chunking — Block Optimization
Transformer models have a fixed input sequence length, so the number of tokens in the prompts we send to the LLM and embedding models is limited. However, in my opinion, this is not a real limitation.
Instead, considering the optimal length of text segments and prompts is meaningful, as it can significantly impact performance, such as:
-
Response time (and cost) -
Accuracy of similarity search -
And more
There are various text segmenters that can be used to chunk text.
Tip 2: Block Optimization — Sliding Window, Recursive Structure-Aware Splitting, Structure-Aware Splitting, Content-Aware Splitting
The size of the chunks is a parameter that needs careful consideration—it depends on the embedding model you are using and its ability to handle tokens. Standard Transformer encoder models (like BERT-based sentence transformers) can process a maximum of 512 tokens, while some embedding models can handle longer sequences, like 8191 tokens.
But remember, larger is not always better. I would rather find two sentences in a book that contain the most critical information than flip through five pages looking for the answer. In other words, the goal of chunking is to find a balance that provides enough context without being overly verbose.

The core challenge here is to find a balance:
Providing enough context for the LLM to reason while ensuring that the text embeddings are specific enough to perform efficient searches.
There are many ways to solve the chunk size selection problem. In LlamaIndex, the NodeParser class specifically handles this issue and provides some advanced options, such as custom text segmenters, adding metadata, defining relationships between nodes/chunks, and so on.
The simplest method is to use a sliding window to ensure that all information is correctly captured without missing any part. Specifically, this means allowing some overlap between text blocks—it’s that simple! This way, each chunk can contain enough contextual information while also maintaining enough specificity for subsequent searches and processing.

In addition to the previously mentioned tips, you can also try various other chunking techniques to optimize the chunking process. For example:
-
Recursive Structure-Aware Splitting: This method can recursively split based on the structure of the document, ensuring that each chunk maintains logical coherence. -
Structure-Aware Splitting (by sentences, paragraphs): Splitting by recognizing the boundaries of sentences or paragraphs, ensuring that each chunk is a complete semantic unit. -
Content-Aware Splitting (Markdown, LaTeX, HTML): For documents in specific formats (like Markdown, LaTeX, HTML), splitting can be done based on their unique tags. -
Using NLP for Chunking: Tracking Topic Changes: Utilizing natural language processing techniques to identify topic changes in the text, allowing for chunking at points where topics shift.
Tip 3: Improve Data Quality — Abbreviations, Technical Terms, Links
Data cleaning techniques can help you remove irrelevant information or place text parts into context, making them easier to understand. Sometimes, if you understand the context of the article, the meaning of a certain paragraph in a long article can become very clear. But without context, it can become difficult to understand.
For example:
-
An abbreviation, specific technical term, or internal company jargon might make it difficult for the model to grasp its full meaning. -
If you know nothing about basketball, you might never connect “MJ” with “Michael Jordan.” -
If you don’t know that a certain sentence describes content in a supply chain context, you might think “PO” refers to “post office” or other combinations starting with P and O.
These examples illustrate the importance of context. By improving data quality, we can help the model better understand the text content, thereby enhancing overall performance.
 To mitigate this issue, we can try extracting necessary additional context when processing data. For instance, using an abbreviation translation table to replace abbreviations with their full forms. This is particularly important in text-to-SQL related use cases. Many field names in databases are often strange, usually only known by developers and the divine.
To mitigate this issue, we can try extracting necessary additional context when processing data. For instance, using an abbreviation translation table to replace abbreviations with their full forms. This is particularly important in text-to-SQL related use cases. Many field names in databases are often strange, usually only known by developers and the divine.
Take SAP (Enterprise Resource Planning solution) as an example; it often uses abbreviations of German words to label fields. For example, the field “WERKS” is actually an abbreviation for the German word “Werkstoff,” which describes the raw material of parts. While this may make sense to the team defining the database structure, it can be quite difficult for others, including our model, to understand these abbreviations.
Tip 4: Add Metadata
You can add metadata to vector data across all vector databases. This metadata can later help us pre-filter the entire vector database before performing vector searches. For example, suppose half of the data in our vector store is targeted at European users and the other half at American users. If we know the user’s location, we wouldn’t want to search the entire database but rather search the relevant part directly. If we add this information as a metadata field, most vector stores allow us to pre-filter the database before executing similarity searches.
Tip 5: Optimize Index Structure — Full Search vs. Approximate Nearest Neighbor, HNSW vs. IVFPQ
While I don’t consider similarity search a weakness of most RAG systems—at least not in terms of response time—I still want to mention it. Similarity search in most vector databases is very fast, even with millions of entries, because it uses approximate nearest neighbor techniques like FAISS, NMSLIB, ANNOY, etc. These techniques make searching very efficient.
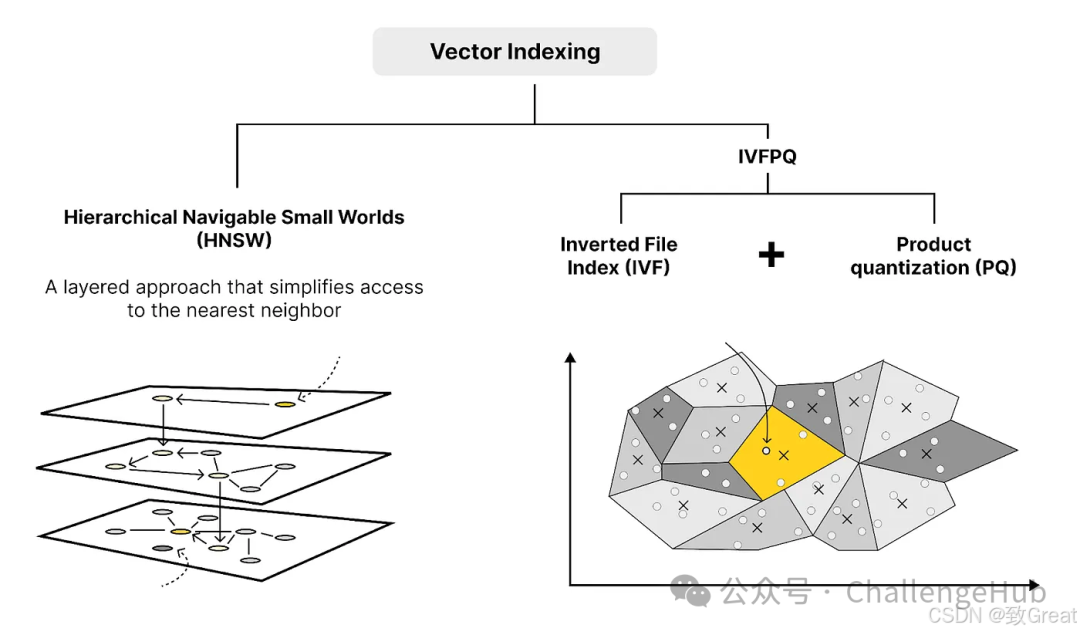 If your data volume is only a few thousand entries, there is usually no need to complicate things. Whether using ANN (Approximate Nearest Neighbor) or complete nearest neighbor search, the impact on the response time of the RAG system will not be significant.
If your data volume is only a few thousand entries, there is usually no need to complicate things. Whether using ANN (Approximate Nearest Neighbor) or complete nearest neighbor search, the impact on the response time of the RAG system will not be significant.
However, if you want to build a scalable system, optimizing speed is still necessary.
Tip 6: Choose the Right Embedding Model There are many options for embedding text blocks. If you are unsure which model to use, you can refer to existing performance benchmarks, such as MTEB (Massive Text Embedding Benchmark), which can help you evaluate the performance of different models.
When it comes to embeddings, you also need to consider the dimensionality of the embeddings. The higher the dimensionality, the more semantic information can be captured, but the trade-off is that it requires more storage space and computation time. Therefore, when selecting dimensions, balance is key; don’t just pursue high dimensionality!
 We will convert all content into embeddings and then store them in the vector database. There are currently many different models provided by various vendors, offering a wide selection. If you want to see which models are available, you can check the list of models supported by the
We will convert all content into embeddings and then store them in the vector database. There are currently many different models provided by various vendors, offering a wide selection. If you want to see which models are available, you can check the list of models supported by the langchain.embeddings module. In the source code of the langchain module, you will find a long list:
__all__ = [
"OpenAIEmbeddings",
"AzureOpenAIEmbeddings",
"CacheBackedEmbeddings",
"ClarifaiEmbeddings",
"CohereEmbeddings",
...
"QianfanEmbeddingsEndpoint",
"JohnSnowLabsEmbeddings",
"VoyageEmbeddings",
"BookendEmbeddings"
]
3. Retrieval Optimization — Query Translation/Query Rewriting/Query Expansion
Whether it’s query expansion, query rewriting, or query translation, their core goal is the same: to optimize the original query using the power of LLMs before passing it to vector search for processing.
In simple terms, it’s about having the LLM “upgrade” the user’s query, making it more suitable for searching. How do we do this? There are several common methods:
-
Method 1: Use the LLM to generate some relevant documents or information to expand the user’s query. -
Method 2: Have the LLM slightly paraphrase the user’s query and then send different prompts to the model, finally integrating the model’s feedback.
Let’s start with the first method.
Tip 7: Use Generated Answers for Query Expansion — Like HyDE We can first have the LLM generate an answer and then use that answer to perform similarity searches. For example, if a question can only be answered using our internal knowledge, we can “induce” the model to generate a hypothetical answer (even if that answer might be fabricated) and then use that hypothetical answer to search for similar content, rather than directly using the user’s original query.
This method, while somewhat “curved rescue,” often yields good results!
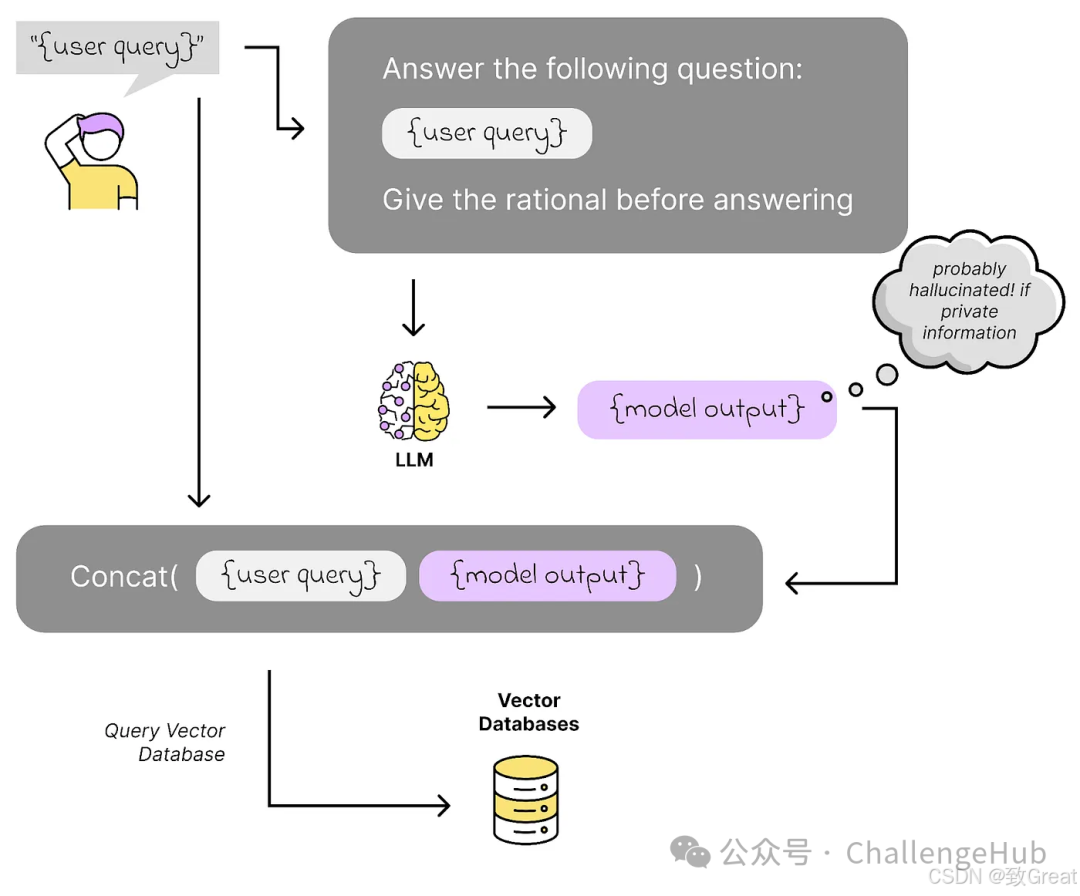
There are several techniques, such as HyDE (Hypothetical Document Embedding), Rewrite-Retrieve-Read, Backward Prompting, Query2Doc, ITER-RETGEN, etc.
In HyDE, we have the LLM first create an answer for the user’s query without any context, and then use that answer to search for relevant information in our vector database.
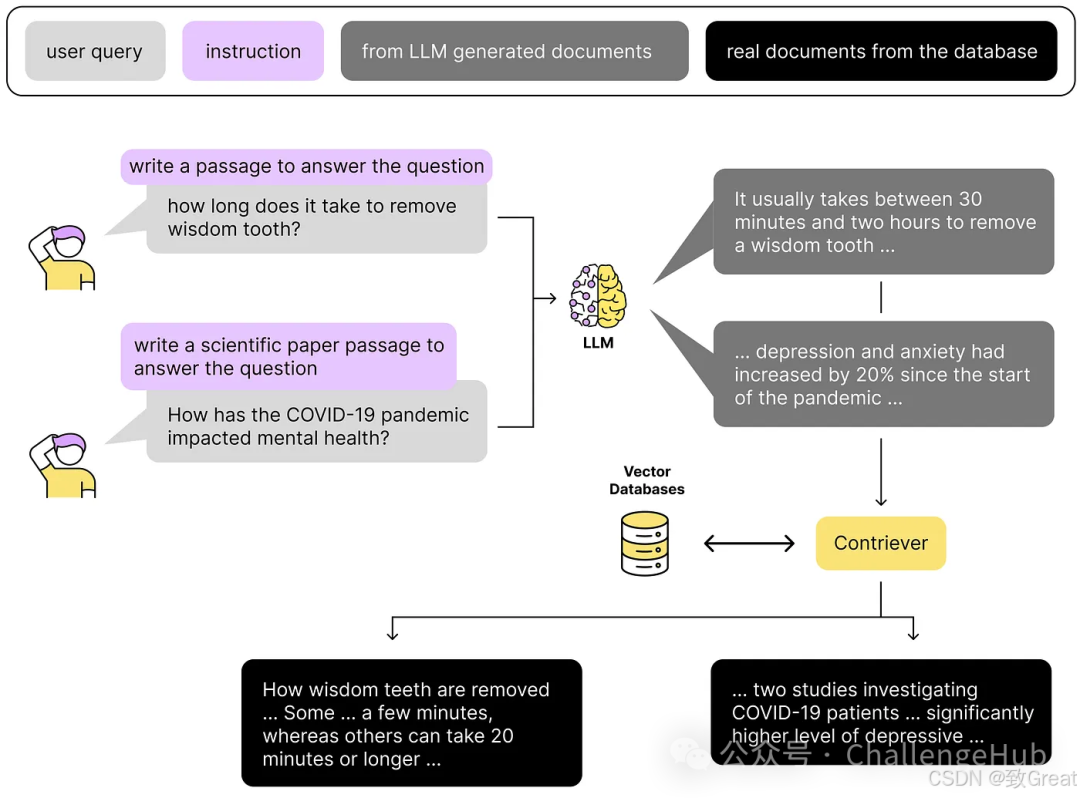 Unlike the methods of HyDE and companies, we can expand the user’s query by using multiple system prompts.
Unlike the methods of HyDE and companies, we can expand the user’s query by using multiple system prompts.
Tip 8: Multiple System Prompts
The idea is quite simple: we can generate 4 different prompts and then get 4 different answers.
You can let your creativity run wild; the differences between the prompts can take any form. For example:
-
If we have a long article that needs summarizing, we can use different prompts to capture different aspects of the article and finally integrate these findings into a complete answer. -
Or we can use 4 prompts that are fundamentally the same, with similar context, but slightly adjust the system prompts. This way, we can have the LLM process the question in slightly different ways or express the answer in different styles.
In summary, flexibly adjusting prompts can lead to more diverse results from the model!
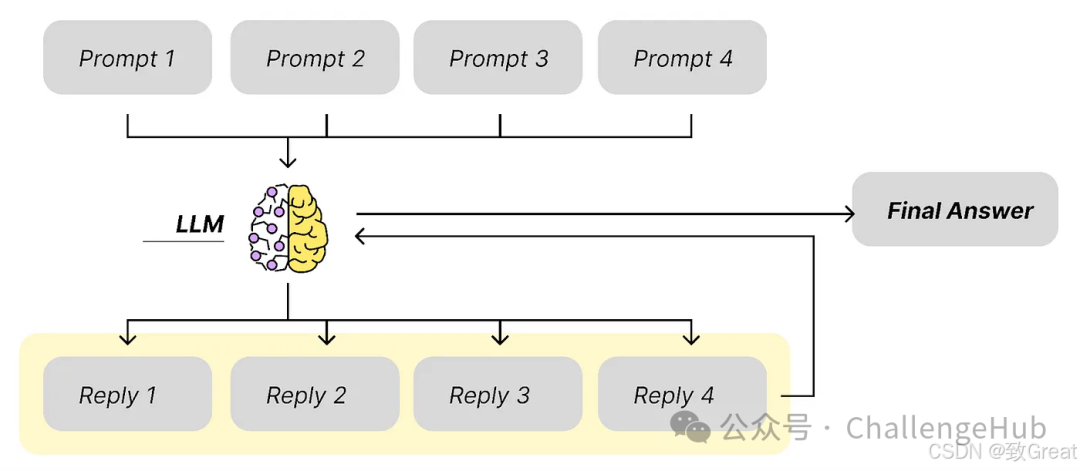
This idea is actually quite common in data science. For example, in the Boosting algorithm, we usually use a bunch of simple models, each slightly different, making a small decision. Finally, we integrate these results. This approach typically yields strong results.
What we are doing now is similar, except we are using models to integrate different predictive results. Of course, the downside is that the computation time or response time may increase somewhat.
Tip 9: Query Routing
In query routing, we can leverage the decision-making ability of the LLM to flexibly determine what to do next.
For example, suppose our vector store contains data from different fields. To make the search more targeted, we can first have the model determine which data pool is most appropriate for finding the answer.
For instance, the vector store in the diagram below contains news from around the world, including sports and soccer, cooking trends, and political news. When users ask the chatbot questions, we certainly wouldn’t want to mix these data together.
Think about it, the sports competition between countries and politics are completely different matters; they cannot be mixed. If a user wants to check political news, recommending cooking-related content would clearly be useless, right? So, letting the model help “classify” first and then find the answer will be much more efficient!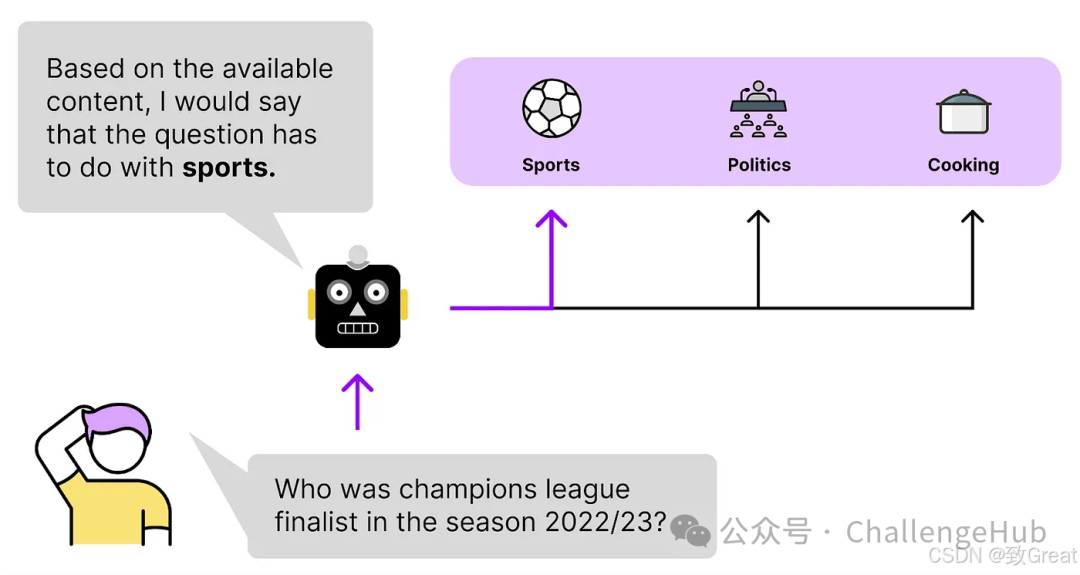
This way, we can significantly improve performance. We can also let the end user select the subject to be used for answering questions.
Tip 10: Hybrid Search
In fact, the retrieval step of the RAG pipeline is essentially a search engine. It can be said that this is the most critical part of the entire RAG system.
If we want to improve the effectiveness of similarity search, we might as well draw on the experiences from the search field. For example, hybrid search is a great example. The idea is to perform vector searches and lexical (keyword) searches simultaneously and then combine the results. This way, we can capture both semantic similarity and precise keyword matching, leading to better results.
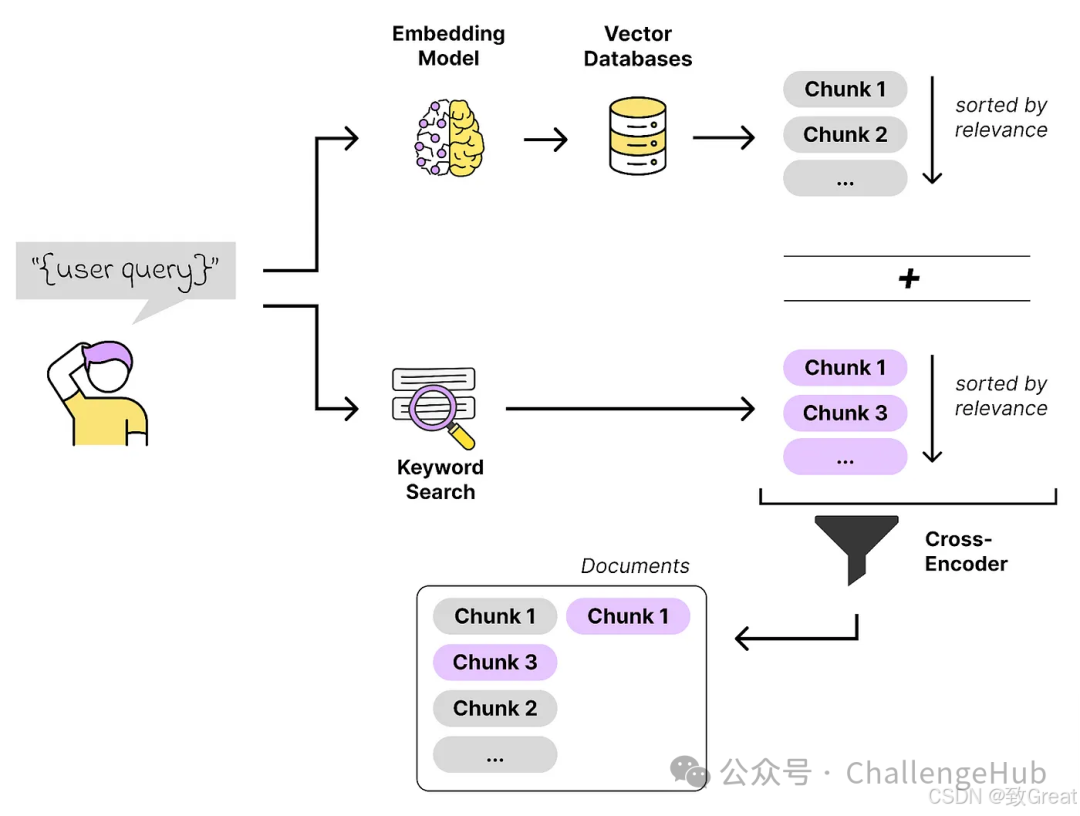
In the field of machine learning, this approach is quite common. It involves using different techniques and models to predict the same target, and then integrating the results. The underlying idea is quite simple:
A group of experts working together to come up with a solution usually yields better results than a single expert making a decision alone.
In short, “many hands make light work!”
4. Post-Retrieval: How to Improve the Retrieval Step?
Context Enrichment — Taking Sentence Windows as an Example Usually, we try to keep text chunks small so that we can easily find the content we need while ensuring the quality of the search.
However, the problem is that just looking at the most matching sentence may not be enough; sometimes its contextual information is key to helping us provide the correct answer.
For example:
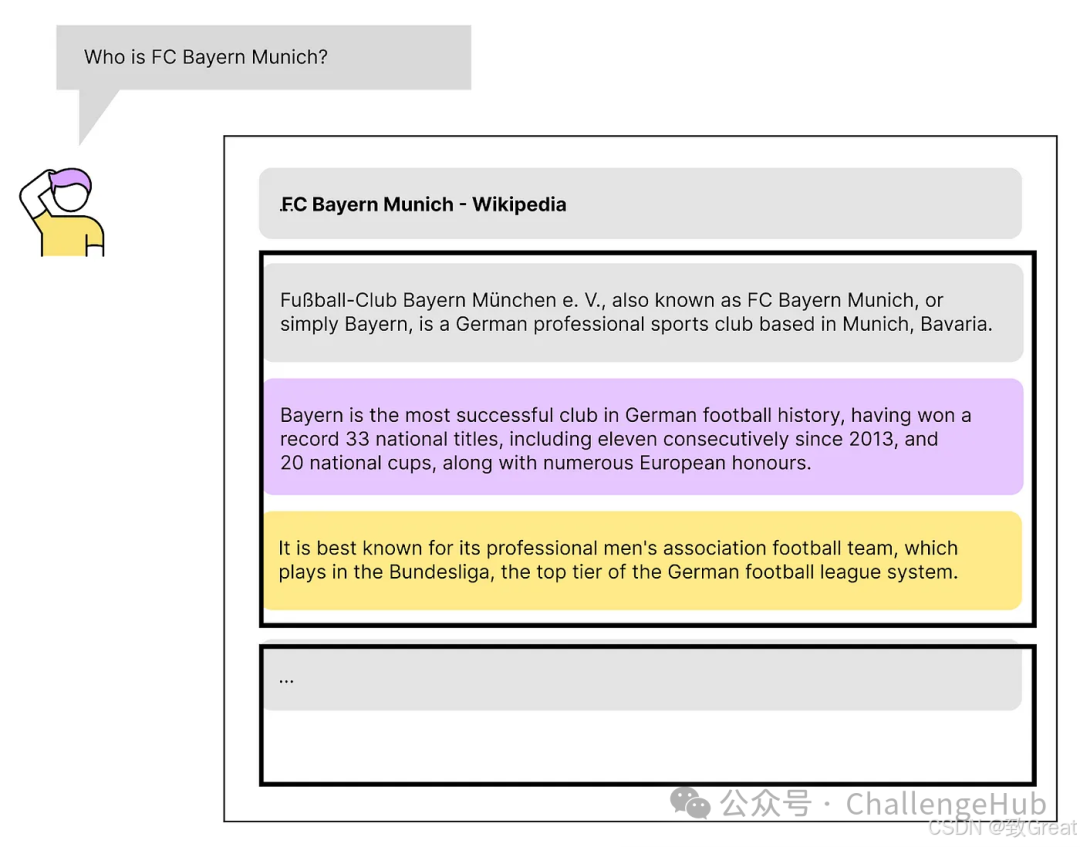
Suppose we have a bunch of text chunks from a Wikipedia article about the German football club Bayern Munich. Although I haven’t actually tested it, I guess the similarity score of the first text chunk might be the highest.
However, the information in the second text chunk might be more important, and we don’t want to miss it. This is where context enrichment comes into play! By adding relevant sentences before and after, we can gain a more comprehensive understanding of the content and find truly useful information.
There are many ways to enrich context; here I will briefly introduce two commonly used methods:
-
Sentence Window Retriever -
Automatic Merging Retriever
Tip 11: Sentence Window Retrieval When we find the highest-scoring text chunk through similarity search, that chunk usually contains the most relevant content. However, before handing it over to the LLM, we add k sentences before and after it. This makes sense because relevant information is likely distributed around the middle text chunks, and a standalone text chunk may lack context and be incomplete.
Tip 12: Automatic Merging Retriever (also known as Parent Document Retriever) The idea of the automatic merging retriever is similar to that of the sentence window retriever, but it operates differently. It assigns a specific “parent” chunk to each small text chunk, which may not necessarily be adjacent but is determined based on content relevance.
You can flexibly define the relationships between text chunks according to your needs. For example, when dealing with technical documents or legal contracts, it is often found that certain paragraphs or sections reference other parts of the document. The challenge then is how to link these referenced parts with the current paragraph to enrich contextual information. We need to be able to identify these citation relationships in the text and integrate them together.
Both methods can help us better understand and utilize text content. The specific choice of which method to use can depend on your actual needs!
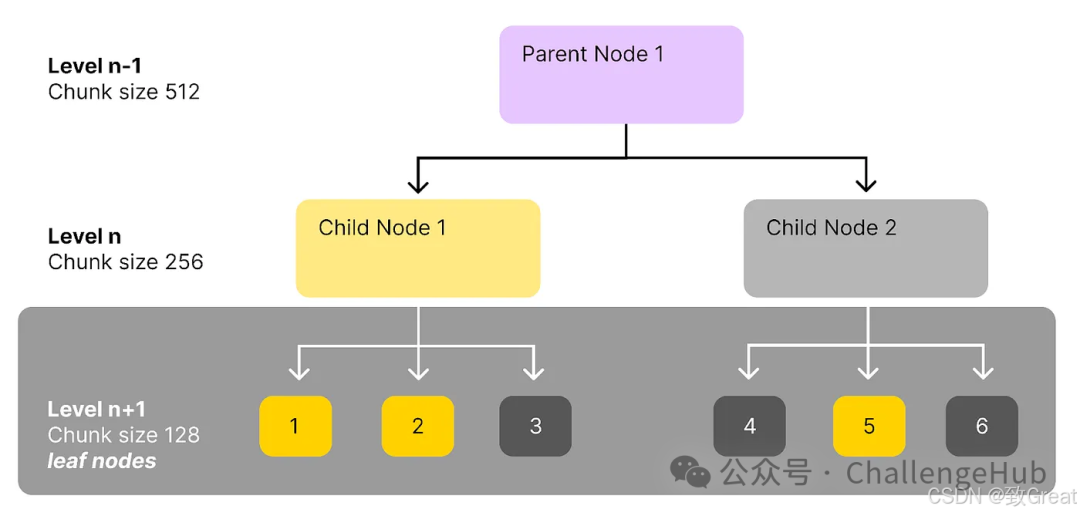
We can build a complete hierarchical structure based on this concept, such as a decision tree. This structure can contain parent nodes, child nodes, and leaf nodes at different levels. For example, we can design a three-level structure, each with different chunk sizes (referencing [LlamaIndex, 2024]):
-
Level 1: Chunk size of 2048 -
Level 2: Chunk size of 512 -
Level 3: Chunk size of 128 (leaf node)
When we index the data and perform similarity searches, we start searching from the smallest chunk—i.e., the leaf node. After finding matching leaf nodes, we trace back up to find the corresponding parent nodes.
Once retrieval is complete, we need to interpret the content we found and use it to answer the user’s query. At this time, large language models (LLMs) come into play. However, the question arises: which model is best suited for our needs?
5. Generation/Agent Large Models
Tip 13: How to Choose the Right Large Model and Service Provider — Open Source or Closed Source? Service or Self-Hosted? Small or Large?
Choosing the right model is not a simple task; it depends on your specific needs and processes.
Some might say:
Just use the most powerful model!
But don’t forget that smaller, cheaper, faster models also have their unique advantages.
For example, in the RAG process, certain steps might be slightly less accurate but respond faster. Especially when we adopt an agent-based approach, where simple decisions need to be made frequently in the pipeline, speed and efficiency become particularly important.
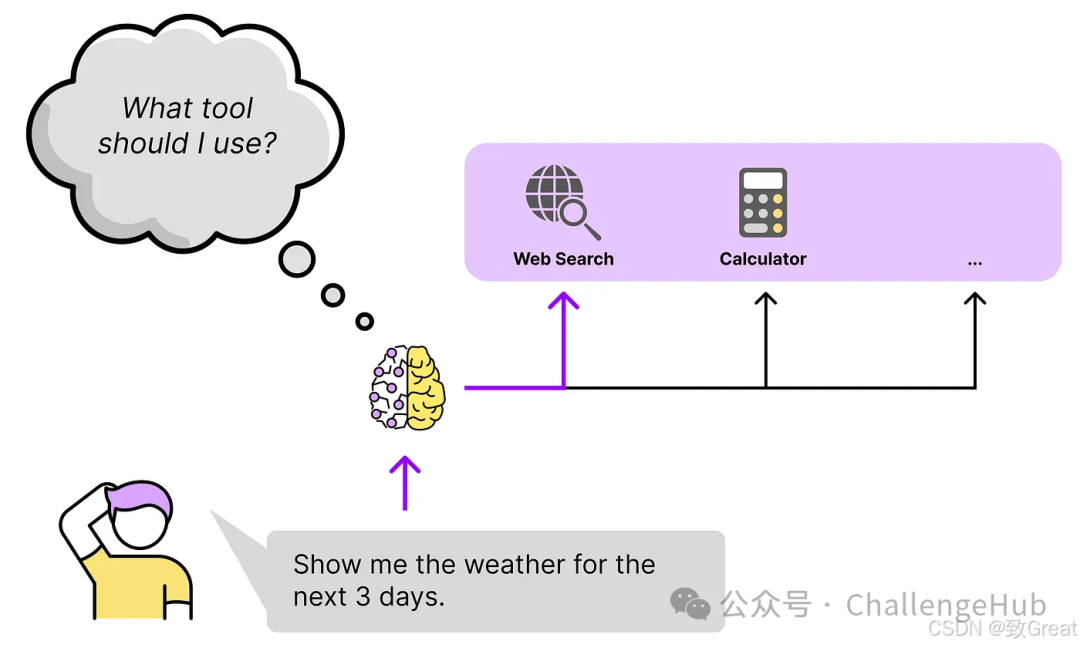
Tools act as valuable assistants for agents, ensuring that they always select the most suitable tools to use.
Moreover, if a smaller model is already sufficient to meet our needs, there is no need to use the top-tier model. This way, you can save on operational costs, and users will appreciate the system’s faster response.
So, how do we choose a model?
There are many benchmarks available on the market that compare these large models across various dimensions. However, the most reliable approach is still to try them out for our RAG solution to see which one fits best.
Tip 14: Agents
Agents are like clever puzzle solvers; they skillfully piece together various components and follow established rules step by step.
In this process, agents employ a trick called “chain of thought reasoning,” which roughly follows this cyclical process:
-
First, pose a question, -
Then ask the large model (LLM) to interpret the received answer, -
Next, decide what to do next based on the interpretation result, -
Finally, restart this process.
Imagine, some problems are like a tangled mess, so complex that we don’t know where to start, because the answers might be scattered everywhere without a clear solution. What do we humans do in such cases? We break down the big problem into smaller questions and tackle them one by one, eventually piecing together the complete answer. Agents do the same; they mimic our way of thinking and gradually approach the truth.
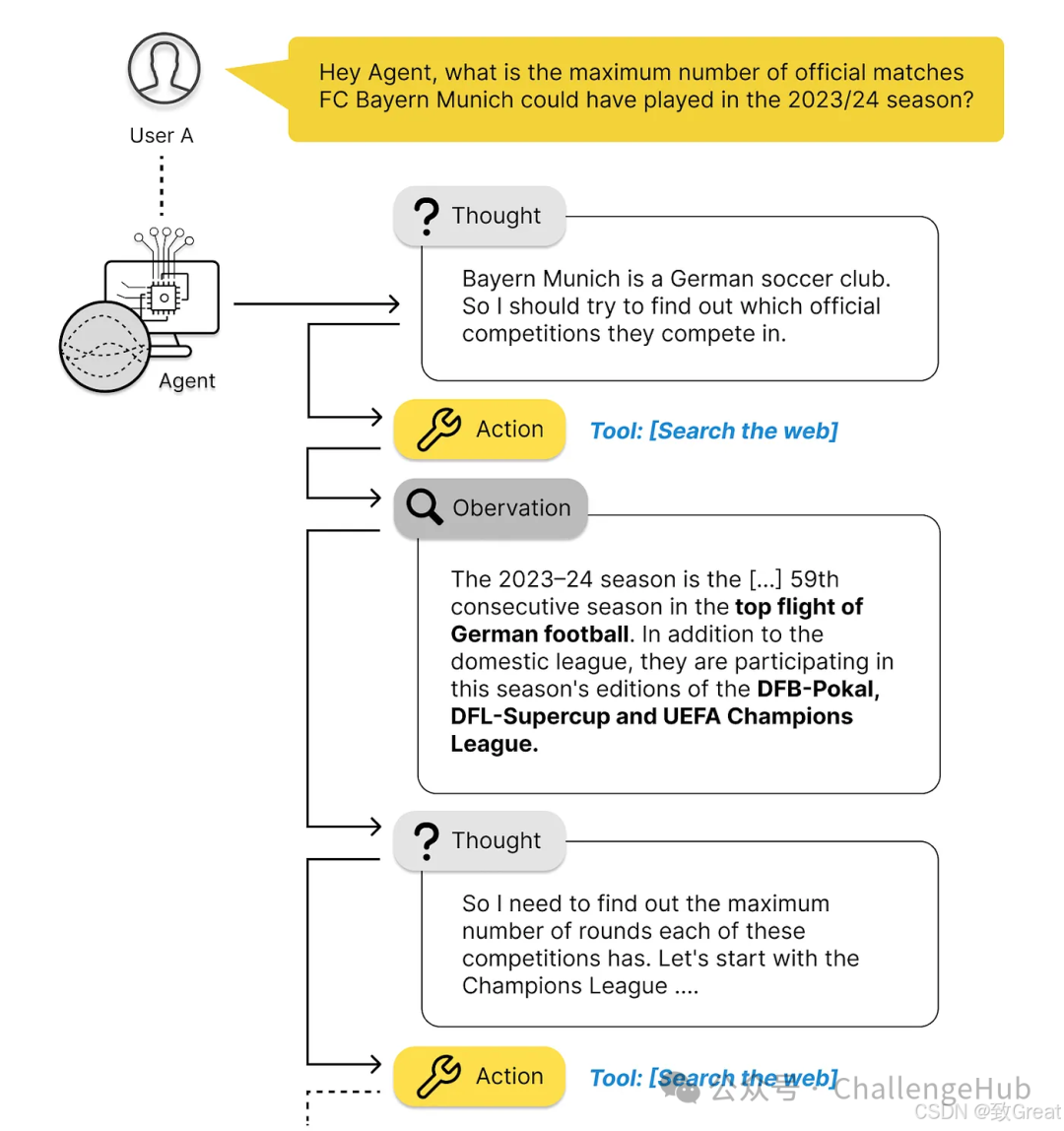
By adopting an agent-based strategy, we can significantly improve accuracy. Of course, there’s no such thing as a free lunch; this method requires some sacrifices in computational resources and response time, requiring more computational power than a one-time prompt, and the response will be slightly slower. But the cost of all this is a significant improvement in accuracy.
Interestingly, through this strategy, we can even allow smaller, more agile models to surpass larger models in accuracy. In the long run, this may provide a better solution to your problem.
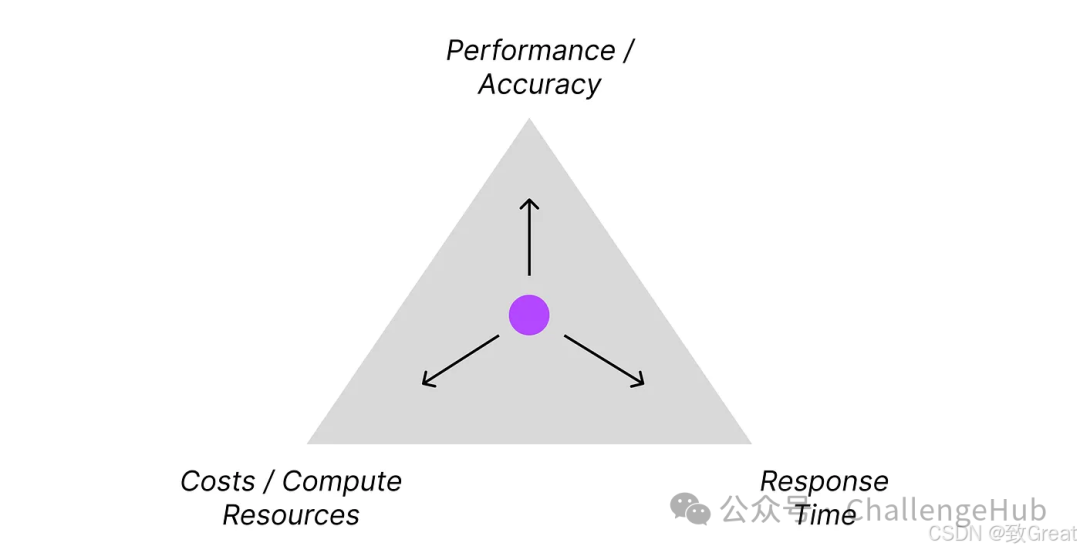
This entirely depends on your specific needs. When we develop a bot specifically for information retrieval, we are always competing with the ultra-fast response speed of search engines.
Speed is everything.
Waiting a few seconds or even minutes to see results can be incredibly frustrating.
6. Evaluation — Evaluating Our RAG System
The performance of RAG-based systems largely depends on two key points: the quality of the data you feed it and the ability of the large model to extract useful information from that data. To ensure that the entire system runs well, we must ensure that each component can perform its role and work in harmony. Therefore, when evaluating the system, we should not only look at overall performance but also break down and check whether each component is doing its job well.
As before, we can divide the evaluation into two parts: Retriever and Generator.
For the retrieval part, we can use some classic search metrics for evaluation, such as DCG (Discounted Cumulative Gain) and nDCG (Normalized Discounted Cumulative Gain). These metrics mainly check whether the retrieved content is ranked reliably—whether truly relevant information is ranked at the top.
In summary, it’s about checking whether the system can pick out the good stuff instead of pushing garbage to the front.
“Ideal ranking” vs. actual ranking: NDCG as an indicator for evaluating ranking quality
Evaluating the answers generated by the model is indeed a headache.
How do we determine whether an answer is good or not? Language is inherently ambiguous; how can we score it?
The simplest way is to find a bunch of people to score it—like having 1000 people evaluate whether the large model’s answers are helpful. This way, you can get a rough idea of its performance. But to be honest, this method is too unrealistic to use in the long term.
Moreover, every slight adjustment to the RAG system may yield different results. I know how difficult it is to get domain experts to test your system. You might manage to test once or twice, but you can’t keep going to experts every time you change something, can you?
So, we need to think of a smarter way. One approach is to use another large model to evaluate the results—this is the method of “using large models as judges.” This way, it saves time and effort, and we can test anytime; how convenient!
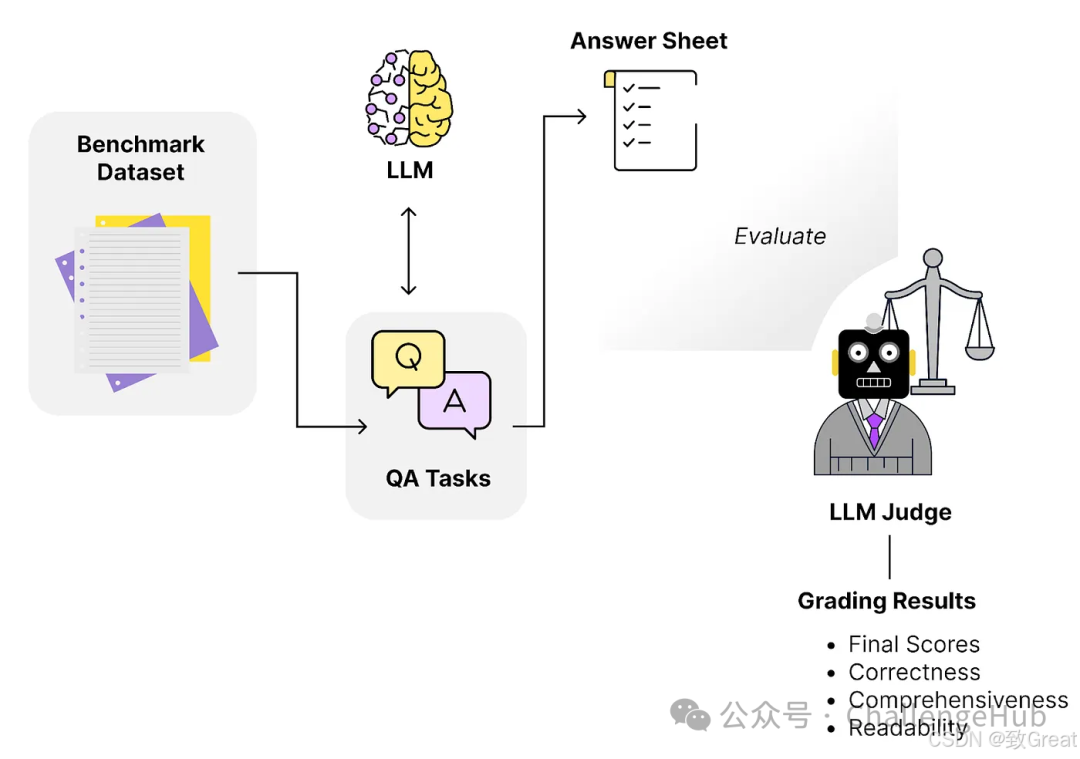
Tip 15: Large Models as Judging Models
The evaluation of the generation part can be done using the “LLM-as-Judge” method. This idea is quite simple and follows three steps:
-
First, create an evaluation dataset: Prepare some questions and answers to test the model’s performance. -
Define a “judge agent”: This is essentially selecting a large model to score based on our defined criteria (e.g., accuracy, professionalism, etc.). -
Set up an automated testing process: Allow the system to automatically evaluate the large model’s answers based on defined standards without manual operation each time.
Step One: Generate a Comprehensive Evaluation Dataset
This dataset usually includes three parts: (1) context, (2) questions, (3) answers. However, we may not always have a ready-made complete dataset. No worries; we can create one ourselves! The method is simple: provide the large model with a piece of context and let it guess what questions might be asked. By doing this step by step, we can gradually build a synthetic dataset.
Step Two: Set Up a “Judge Agent”
This “judge agent” is another large model (usually more powerful), and we use it to evaluate the system’s answers based on some criteria. For example:
-
Professionalism: Is the answer written in a professional tone?
For example, we can define the scoring standard for “professionalism” like this:
definition=(
"Professionalism refers to a communication style that is formal, respectful, and appropriate for specific contexts and audiences. It typically avoids overly casual language, slang, or colloquial expressions, opting instead for clear, concise, and respectful expressions."
),
grading_prompt=(
"Professionalism scoring criteria are as follows:"
"- 1 point: Language is very casual, possibly including slang or colloquial expressions, completely unsuitable for professional contexts."
"- 2 points: Language is somewhat casual but still respectful, with minimal slang. Acceptable in less formal professional settings."
"- 3 points: Language is generally formal but occasionally includes one or two casual words. This is the baseline for professional contexts."
"- 4 points: Language is balanced, neither too casual nor too formal. Suitable for most professional settings."
"- 5 points: Language is very formal and respectful, with no casual elements. Suitable for formal business or academic contexts."
)
Step Three: Test the RAG System
Use the evaluation dataset we just created to test the system. For each metric we want to test (such as professionalism), we will define a detailed scoring standard (e.g., from 1 to 5 points) and let the “judge agent” score it. Although this is not an exact science, the model’s scoring may vary a bit, but it can give us a rough idea of how the system performs.
In simple terms, we let the large model act as a judge, scoring the system’s answers to see how reliable they are!
We can find some examples of this scoring prompt in the Prometheus prompt templates or Databricks MLFlow tutorials.
Tip 16: RAGAs
RAGAs (Retrieval-Augmented Generation Assessment) is a framework specifically designed for evaluating the various components of RAG systems. One of its core ideas is “using large models as judges,” which means using large models to assist in evaluations. However, RAGAs offer more than just that; they provide various tools and techniques to help us continuously optimize RAG applications.
A key point here is “component evaluation”; RAGAs provide some predefined metrics to evaluate each step of the RAG process individually. For example:
Generation Part:
-
Fidelity: How accurate is the generated answer? Does it align with the facts? -
Answer Relevance: How relevant is the generated answer to the question? Is it off-topic?
Retrieval Part:
-
Context Accuracy: What is the ratio of useful information to noise in the retrieved content? -
Context Recall: Can it retrieve all relevant information needed to answer the question?
Additionally, RAGAs also have metrics designed to evaluate the overall effectiveness of the entire RAG process, such as:
-
Answer Semantic Similarity: How close in meaning is the generated answer to the standard answer? -
Answer Correctness: Is the answer correct?
In summary, RAGAs act like a “health check tool” that helps us inspect each part of the RAG system, identify problems, and prescribe remedies.
Tip 17: Continuously Collect Data from Applications and Users
Collecting data for RAG is a key task; it helps us see where there are gaps in the process and make timely corrections. Many times, the knowledge base data we feed into the system is not good enough, but we might not discover this on our own. Therefore, we need to find ways to make it easy for users to provide feedback so that we can identify issues and improve.
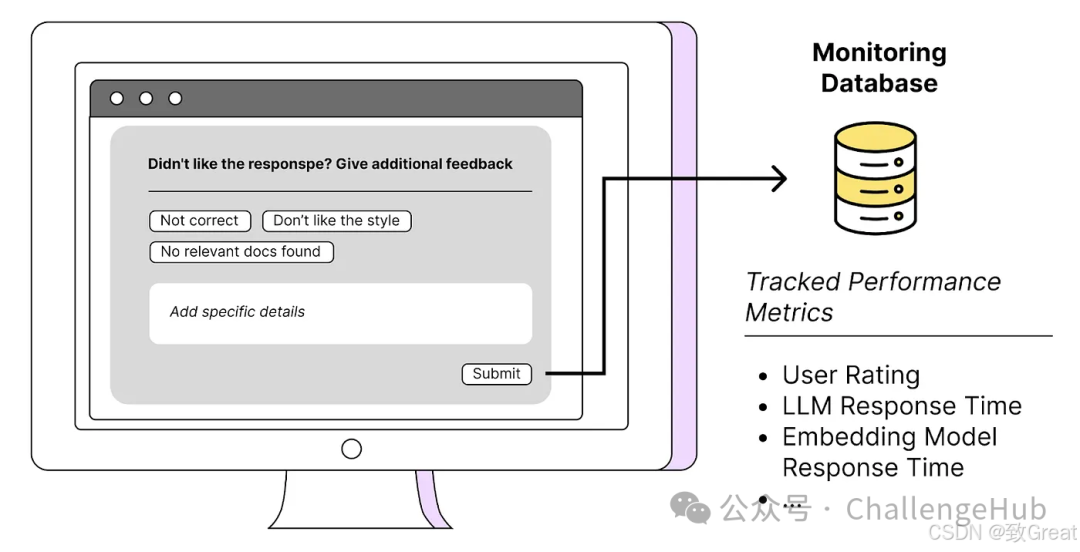 In addition to basic data, we can also collect more interesting information, such as:
In addition to basic data, we can also collect more interesting information, such as:
-
The time point of each response and how long each step in the RAG process took (e.g., vectorization, similarity search, large model answer generation) -
Which prompt template was used -
What relevant documents were found, and what version of the documents -
The final answer given by the large model -
…
This data can not only help us analyze performance but also give us a clearer understanding of how the system operates; isn’t that interesting?
The RAG system consists of several steps. To make it run faster and better, we need to first identify which step is lagging behind. Therefore, we must monitor the performance of each step to find issues and maximize the potential of the entire system.
Data collection in the RAG process
Conclusion
In short, there are no fixed routines for RAG; it relies on us to continuously experiment and explore.Like other data science projects, we have many tools at our disposal, but how to solve specific problems depends on the situation.
In fact, this uncertainty in RAG makes the project interesting; if everything followed a set guide, it would be so boring!
To join the technical exchange group, please add the AINLP assistant on WeChat (id: ainlp2)
Please specify the specific direction + related technical points used
About AINLP
AINLP is an interesting natural language processing community focused on sharing AI, NLP, machine learning, deep learning, recommendation algorithms, and other related technologies. Topics include LLM, pre-trained models, automatic generation, text summarization, intelligent Q&A, chatbots, machine translation, knowledge graphs, recommendation systems, computational advertising, recruitment information, and job experience sharing. Welcome to follow! To join the technical exchange group, please add the AINLP assistant on WeChat (id: ainlp2), specifying your work/research direction + purpose of joining the group.