Effectively parsing and understanding tables in unstructured documents remains a significant challenge when designing RAG solutions. This is especially difficult in cases where tables exist in image formats, such as scanned documents. These challenges include several aspects:
-
The complexity of scanned or image documents, such as diverse structures, the presence of non-text elements, and the combination of handwritten and printed content, poses challenges for automatically and accurately extracting table information. Inaccurate parsing can disrupt the structure of the table, and using incomplete tables for embedding may not only fail to capture the semantic information of the table but also easily compromise the RAG results. -
How to extract table titles and effectively link them to their respective tables. -
How to design an index structure to effectively store the semantic information of tables. This article first introduces the key technologies for managing tables in RAG, then reviews some existing open-source solutions, and finally proposes and implements a possible solution.
Key Technologies
▶Table Parsing
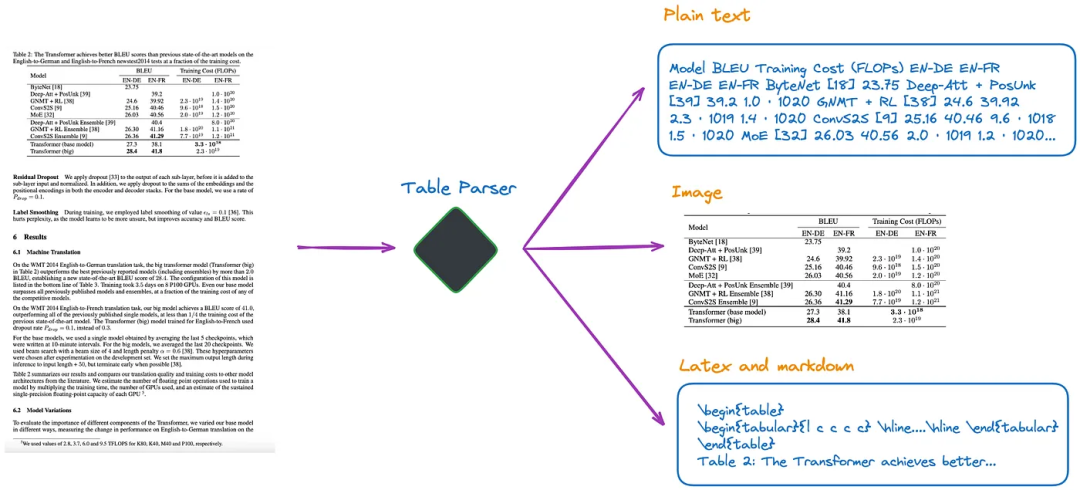
The main function of this module is to accurately extract the table structure from unstructured documents or images. It is preferable to extract the corresponding table titles and facilitate developers in associating table titles with tables. Currently, there are several methods:
-
Using multimodal LLMs (multimodal LLM) like GPT-4V to recognize tables and extract information from each PDF page. -
Utilizing specialized detection models, such as Table Transformer[1], to identify table structures. -
Using open-source frameworks, such as unstructured[2] or other frameworks, which allow for comprehensive analysis of the entire document and extraction of table-related content from the analysis results. -
Using end-to-end models (like Nougat, Donut, etc.) to parse the entire document and extract table-related content. This method does not require OCR models. It is worth mentioning that regardless of the method used to extract table information, table titles should be included. This is because, in most cases, table titles provide a brief description of the table by the document or paper authors, which can largely summarize the entire table. Among the above methods, the fourth one can relatively easily detect table titles and associate them with tables.
▶Index Structure
The ways to index tables can be roughly divided into the following categories:
-
Indexing only image format tables. -
Indexing only plain text or JSON format tables. -
Indexing only LaTeX format tables. -
Indexing only table summaries (table summaries can typically be generated using LLMs or attempted using multimodal models). -
Indexing structures from small to large or according to document summaries (small chunks could be rows in a table, while large chunks are image, text, or LaTeX format tables), as shown in the figure below: 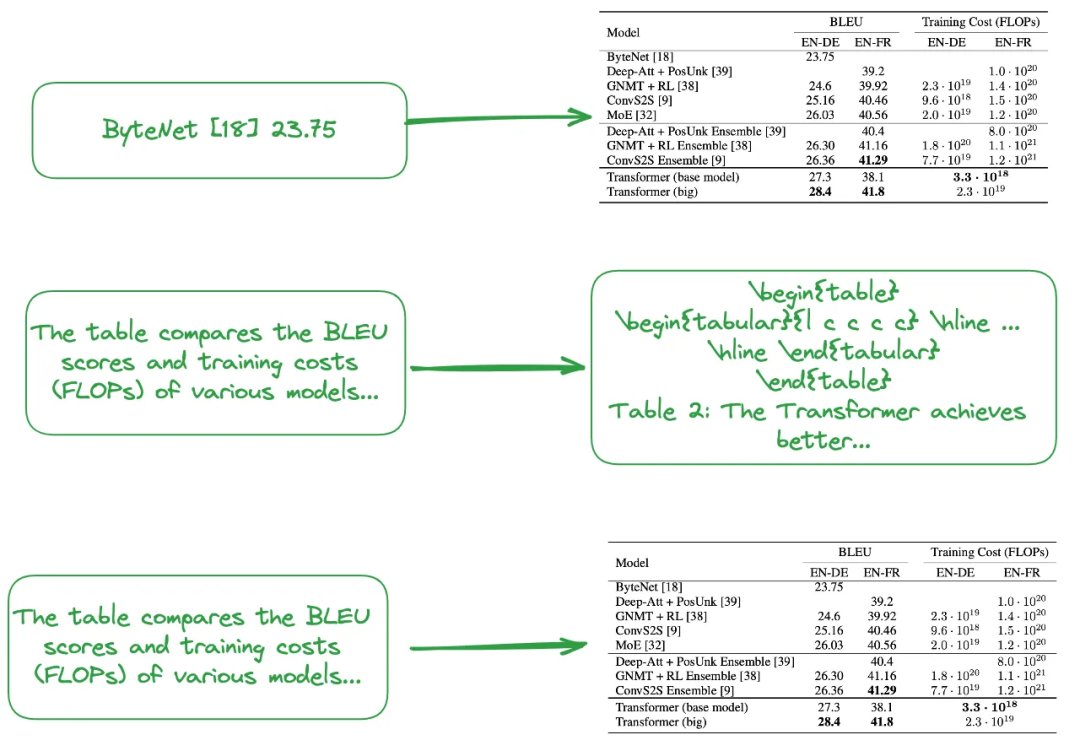
There are also some algorithms that do not require table parsing, such as sending the relevant PDF pages (images) along with user queries to VQA models (like DAN) or multimodal LLMs (like GPT-4V) to return answers, as shown in the figure below:
Additionally, images, text blocks, and user queries can be sent to multimodal LLMs to directly obtain answers.
It is important to note that not all methods rely on the RAG process, for example:
-
Training on specific datasets and enabling models (similar to BERT transformers) to support table understanding tasks, such as the TAPAS[3] method. -
Using LLMs with pre-training, fine-tuning, or prompting methods, allowing LLMs to perform table understanding tasks, such as the GPT4Table[4] method.
Existing Open Source Solutions
LlamaIndex provides four methods, with the first three relying on multimodal models:
-
Retrieving relevant images and sending them to GPT-4V for responses. -
Treating each PDF page as an image, allowing GPT-4V to reason over each page, establish a text index, and then query answers based on the Image Reasoning Vector Store. -
Using Table Transformer to crop table information from retrieved images and then using GPT-4V to answer. -
Performing OCR processing on cropped table images and sending the text to LLM for answers. Langchain also has some solutions, classified as follows:
-
Semi-Structured RAG[5]: First using Unstructured to parse text and tables from PDFs, then using a multi-vector retriever to store the original tables and text while summarizing the tables, and finally implementing a Q&A link with LCEL. The main process is shown below (in reality, the last LLM here is not a multimodal LLM): 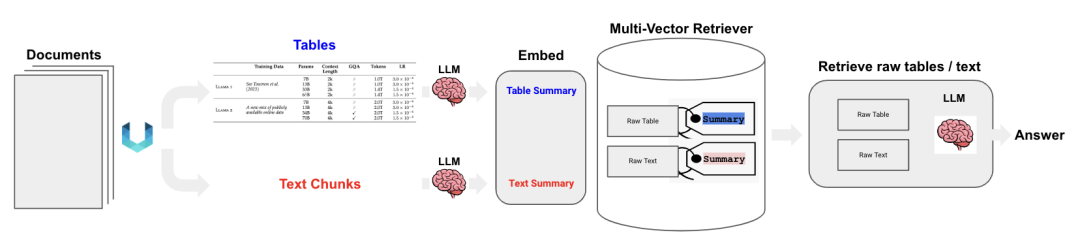
-
Semi-Structured and Multimodal RAG[6]: This proposes several options, as shown in the figure below. – Option 1: Similar to semi-structured RAG, using multimodal embedding (like CLIP) to embed images and text, and then sending the original images and text blocks to multimodal LLMs for answers. – Option 2: Also using multimodal LLMs to generate text summaries from images, then embedding the text so that traditional RAG links can be used for Q&A. – Option 3: Generating text summaries from images, then embedding them, but during Q&A, finding the original images based on embeddings and using multimodal LLMs for answers. 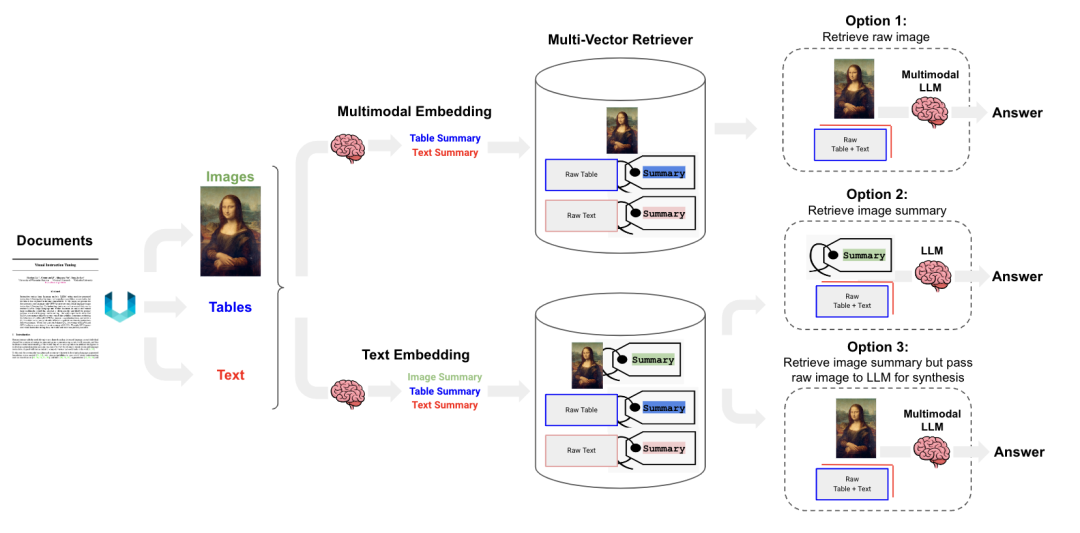
Proposed Solutions
This article summarizes, classifies, and discusses key technologies and existing solutions. Based on this, we propose the following solutions, as shown in the figure below. For simplicity, some RAG modules, such as re-ranking and query rewriting, are omitted here. 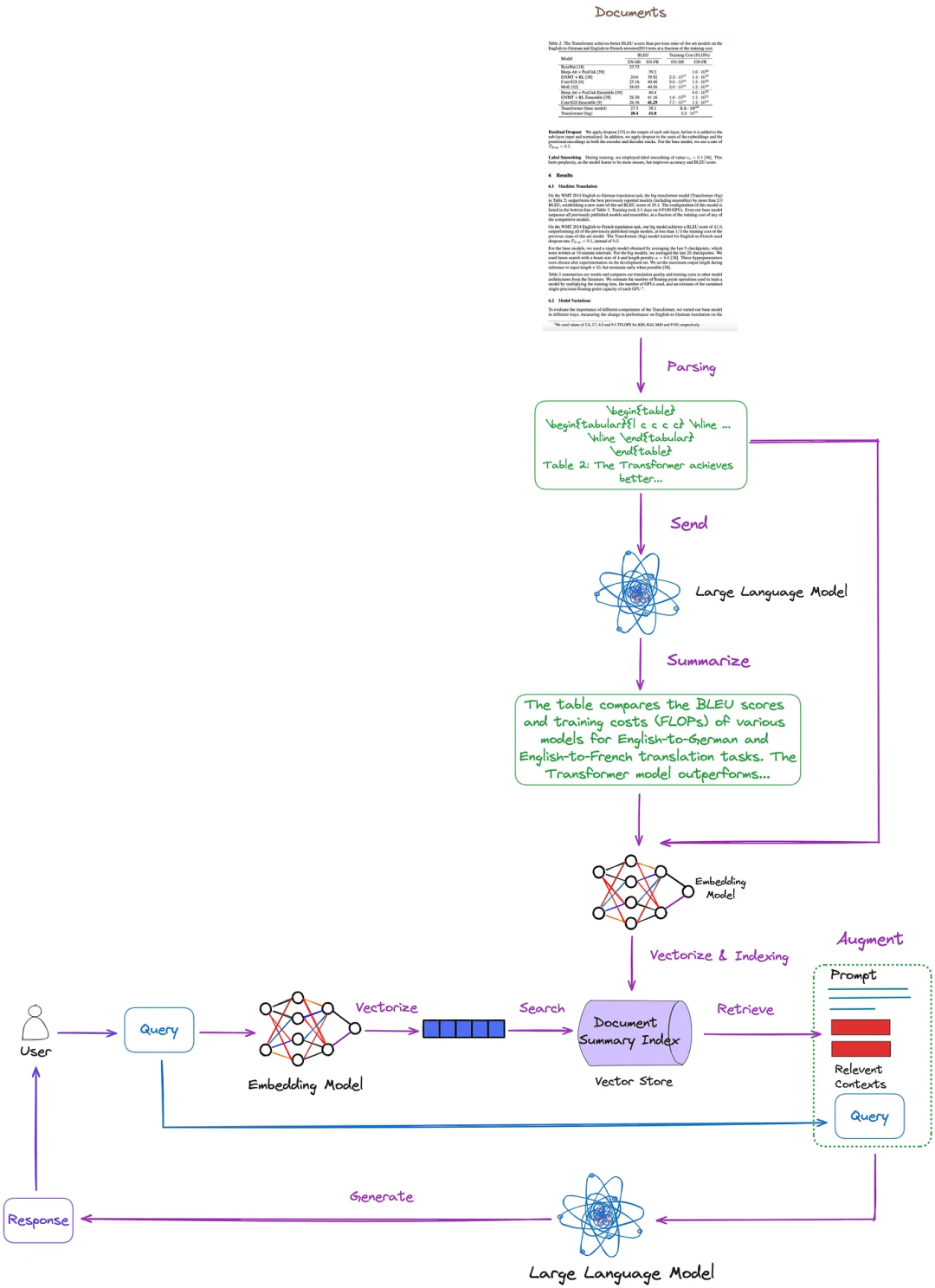
-
Table Parsing: Using Nougat, which, according to the author’s description, has stronger table detection capabilities than unstructured and can also extract table titles well, making it easy to associate with tables. -
Document Summary Indexing: Small chunks of content include table summaries, while large chunks include LaTeX format tables and titles, and then using a Multi-Vector Retriever strategy for storage. -
Table Summary: Sending table and table titles to LLM for summarization.
Here, we introduce Nougat[7], which is developed based on Donut[8] and does not require modules related to OCR. The overall architecture diagram is: 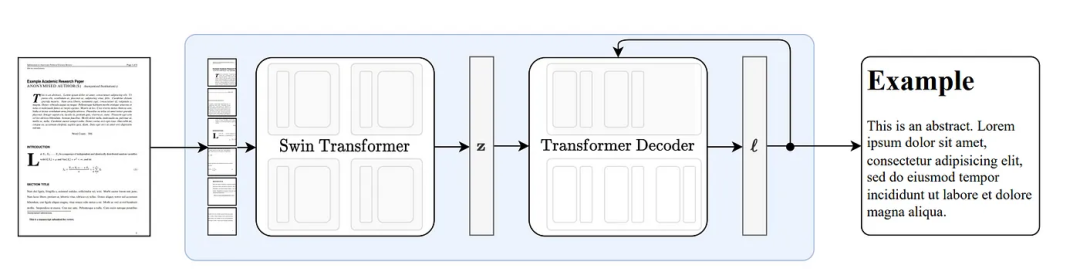 Nougat’s ability to parse formula tables is impressive, and it can also associate table titles (parsed in LaTeX format), such as the example below:
Nougat’s ability to parse formula tables is impressive, and it can also associate table titles (parsed in LaTeX format), such as the example below: 
Using Nougat has the following advantages and disadvantages:
-
Pros: – Can parse difficult-to-parse parts such as formulas and tables into LaTeX source code. – The parsed result is a semi-structured document similar to Markdown. – Can easily obtain table titles and associate them with tables. -
Cons: – Parsing speed is slow, and large-scale use may be limited. – Nougat is trained on scientific papers, so it is friendly to similar formats, but may perform poorly on other formats. – Parsing tables in two-column formats is not as effective as in single-column formats.
Conclusion
This article discusses the key technologies and existing solutions for table processing in the RAG process and proposes solutions and their implementation. This article recommends using Nougat for table parsing. However, if faster and more efficient parsing tools are available, we also suggest replacing it. The attitude toward tools should be to have the right ideas first and then find tools to implement them, rather than relying on a specific tool. In this article, we input all table content into LLMs. However, in practical scenarios, we should consider cases where tables exceed the context length of LLMs, such as using effective chunking methods to partially address this issue.
References
Table Transformer: https://github.com/microsoft/table-transformer
[2]unstructured: https://unstructured-io.github.io/unstructured/best_practices/table_extraction_pdf.html
[3]TAPAS: https://aclanthology.org/2020.acl-main.398.pdf
[4]GPT4Table: https://arxiv.org/pdf/2305.13062.pdf
[5]Semi-Structured RAG: https://github.com/langchain-ai/langchain/blob/master/cookbook/Semi_Structured_RAG.ipynb?ref=blog.langchain.dev
[6]Semi-Structured and Multimodal RAG: https://github.com/langchain-ai/langchain/blob/master/cookbook/Semi_structured_and_multi_modal_RAG.ipynb
[7]Nougat: https://arxiv.org/pdf/2308.13418.pdf
[8]Donut: https://arxiv.org/pdf/2111.15664.pdf