
As one of the most advanced technologies in artificial intelligence, Retrieval-Augmented Generation (RAG) technology can provide reliable and up-to-date external knowledge, offering great convenience for numerous tasks. Especially in the era of AI-Generated Content (AIGC), RAG’s powerful retrieval capabilities in providing additional knowledge enable it to assist existing generative AI in producing high-quality outputs. Recently, large language models (LLMs) have demonstrated revolutionary capabilities in language understanding and generation, but they still face inherent limitations, such as hallucinations and outdated internal knowledge. Given RAG’s strong ability to provide the latest and useful auxiliary information, retrieval-augmented large language models have emerged, leveraging external and authoritative knowledge bases rather than solely relying on the model’s internal knowledge to enhance the generation quality of LLMs. In this review, we comprehensively revisit the existing research on retrieval-augmented large language models (RA-LLMs), covering three main technical perspectives: architecture, training strategies, and applications. As preliminary knowledge, we briefly introduce the fundamentals of LLMs and recent advancements. Then, to elucidate the practical significance of RAG for LLMs, we categorize mainstream related works by application domains, detailing the challenges in each field and the corresponding capabilities of RA-LLMs. Finally, to provide deeper insights, we discuss the current limitations and several promising directions for future research.
https://www.zhuanzhi.ai/paper/0683c50bfdc3b4f19681e8cf86ac8e52
As one of the most fundamental data mining techniques, retrieval aims to understand input queries and extract relevant information from external data sources [62, 132]. It has been widely applied in various fields [8, 100, 170], such as search, question answering, and recommendation systems. For instance, search engines (like Google, Bing, and Baidu) are among the most successful applications of retrieval in the industry; they can filter and retrieve the most relevant web pages or documents to match user queries [19, 170], enabling users to effectively find the information they need. Meanwhile, by effectively maintaining data in external databases, retrieval models can provide reliable and timely external knowledge, playing a crucial role in various knowledge-intensive tasks. Due to its strong capabilities, retrieval technology has been successfully integrated into advanced generative models in the era of AIGC [72, 126, 155, 181]. Notably, the integration of retrieval models with language models has given rise to Retrieval-Augmented Generation (RAG) [69], which has become one of the most representative technologies in the field of generative AI, aimed at improving the quality of text content generation [6, 69, 72].
To advance generative models and enhance generation results, RAG integrates information or knowledge from external data sources as a supplement to input queries or generated outputs [57, 97]. Specifically, RAG first calls a retriever to search and extract relevant documents from external databases, then uses these documents as context to enhance the generation process [49]. In practice, the application of RAG technology in various generative tasks is feasible and efficient, requiring simple adjustments to the retrieval component, often with little or no additional training [111]. Recent studies indicate that RAG has enormous potential not only in knowledge-intensive tasks like Open Question Answering (OpenQA) [6, 42, 103] but also in general language tasks [44, 57, 162] and various downstream applications [84, 155].
In recent years, the rapid development of pre-trained foundational models, especially large language models (LLMs), has demonstrated exceptional performance across various tasks [1, 18], including recommendation systems [187], molecular discovery [72], and report generation [26]. The tremendous success of LLMs is technically attributed to advanced architectures with billions of parameters, pre-trained on extensive corpora from various sources. These technical improvements have enabled LLMs to exhibit significant capabilities in language understanding and generation, contextual learning, and more [186, 187]. For example, GPT-FAR teaches GPT-4 detailed prompts for tasks such as image tagging, statistical analysis, and multimodal fashion report generation [26]. LLMs also show promising performance in recommendation systems by understanding user preferences for projects [146, 187]. Despite their success, LLMs still suffer from inherent limitations [186, 187], such as lack of domain-specific knowledge, hallucination issues, and the substantial computational resources required to update models. These issues are particularly evident in specific fields like medicine and law. For instance, a recent study indicated that hallucinations in legal queries against state-of-the-art LLMs had a rate between 69% and 88% [21]. Furthermore, due to the large computational resources required to fine-tune LLMs for specific domains or the latest data, the challenge of addressing hallucination issues becomes even more daunting, significantly hindering the widespread adoption of LLMs in various practical applications.
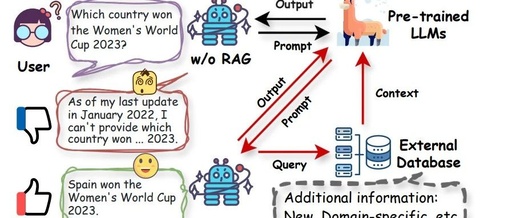
To address these limitations, recent efforts aim to leverage RAG to enhance LLMs’ capabilities across various tasks [6, 48, 57, 128], particularly those requiring up-to-date and reliable knowledge, such as Question Answering (QA), AI4Science, and software engineering. For example, Lozano et al. [86] introduced a science-specific question answering system based on dynamic retrieval of scientific literature. MolReGPT utilizes RAG to enhance ChatGPT’s contextual learning capabilities in molecular discovery [72]. As shown in Figure 1, LLM-based dialogue systems struggle to answer out-of-scope queries effectively. In contrast, with RAG retrieving relevant knowledge from external data sources and integrating it into the generation process, dialogue systems successfully provide correct answers to users. Given the significant progress made in advancing LLMs through RAG, there is an urgent need for a systematic review of the latest developments in retrieval-augmented large language models (RA-LLMs).
This review aims to provide a comprehensive overview of retrieval-augmented large language models by summarizing representative methods of RA-LLMs from the perspectives of architecture, training, and applications. More specifically, following the brief introduction to the background of LLMs in Section 2, we review existing research from the main perspectives of retrieval, generation, and augmentation in Section 3, discussing the necessity and frequency of retrieval in RAG. Then, in Section 4, we summarize the main training techniques of RA-LLMs, and in Section 5, we discuss various applications of RA-LLMs. Finally, in Section 6, we discuss key challenges and potential directions for future exploration. Several related reviews conducted concurrently with ours have different focuses, such as Zhao et al. [185] specifically reviewing RAG techniques based on multimodal information, and Zhao et al. [184] discussing RAG for AIGC. Gao et al. [37] provided a relatively comprehensive overview of RAG for LLMs. Our review differs from these reviews by focusing on technical perspectives and systematically revisiting models according to the architecture and training paradigms of RA-LLMs as well as application tasks.
Retrieval-Augmented Large Language Models (RA-LLMs)
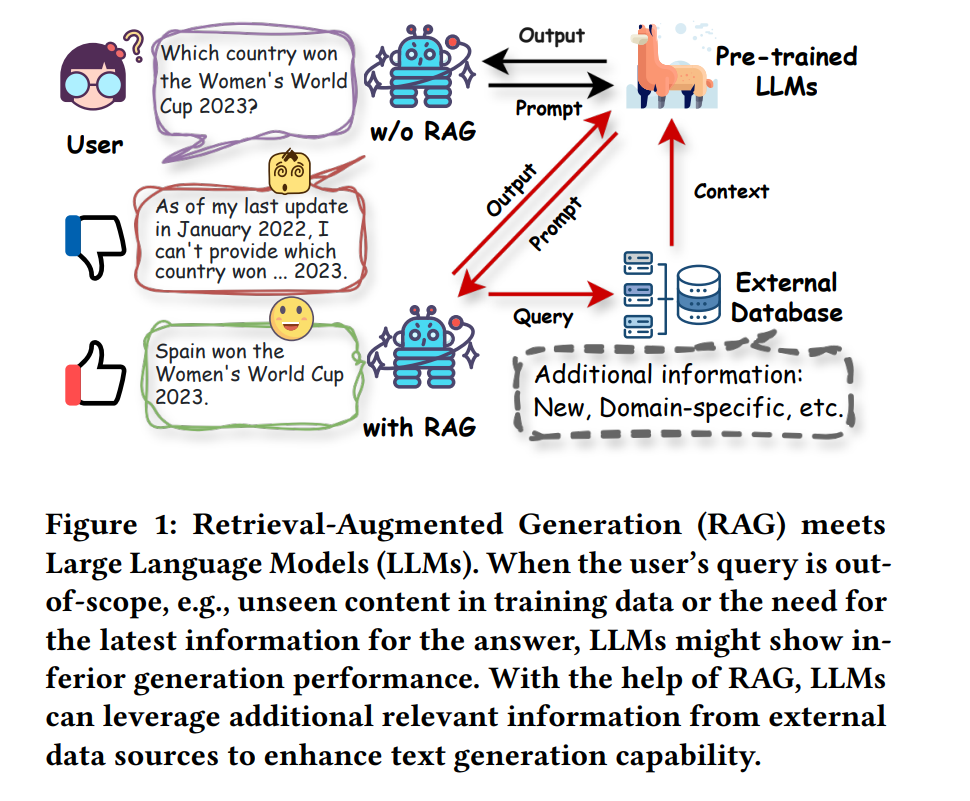
The RAG framework in the era of LLMs typically involves three main processes: retrieval, generation, and augmentation, along with mechanisms to determine whether retrieval is necessary. In this section, we will introduce the important technologies involved in each component. Retrieval aims to provide relevant information from external knowledge sources based on the queries inputted into LLMs. These knowledge sources can be open-source or closed-source, as illustrated in Figure 2. Key components of the retriever, further detailed in Figure 3, include several programs whose overall function is to measure the relevance between queries and documents in the database to effectively retrieve information. The specific retrieval process also depends on whether pre-retrieval and post-retrieval processes are included. In this subsection, we will introduce the main technologies involved in traditional and LLM-based RAG retrieval, including types of retrievers, retrieval granularity, pre-retrieval and post-retrieval enhancement, and database construction.
Generation The design of generators largely depends on downstream tasks. For most text generation tasks, decoder-only and encoder-decoder are the two dominant architectures [186]. Recent developments in commercially closed-source large foundational models have made black-box generative models mainstream in RA-LLMs. In this section, we will briefly review the research on these two types of generators: accessible parameters (white-box) and inaccessible parameters (black-box). Augmentation describes the technical processes that integrate retrieval and generation components, which is the core part of RA-LLMs. In this subsection, we introduce three main augmentation designs that operate on the inputs, outputs, and intermediate layers of the generator, as shown in Figure 2.
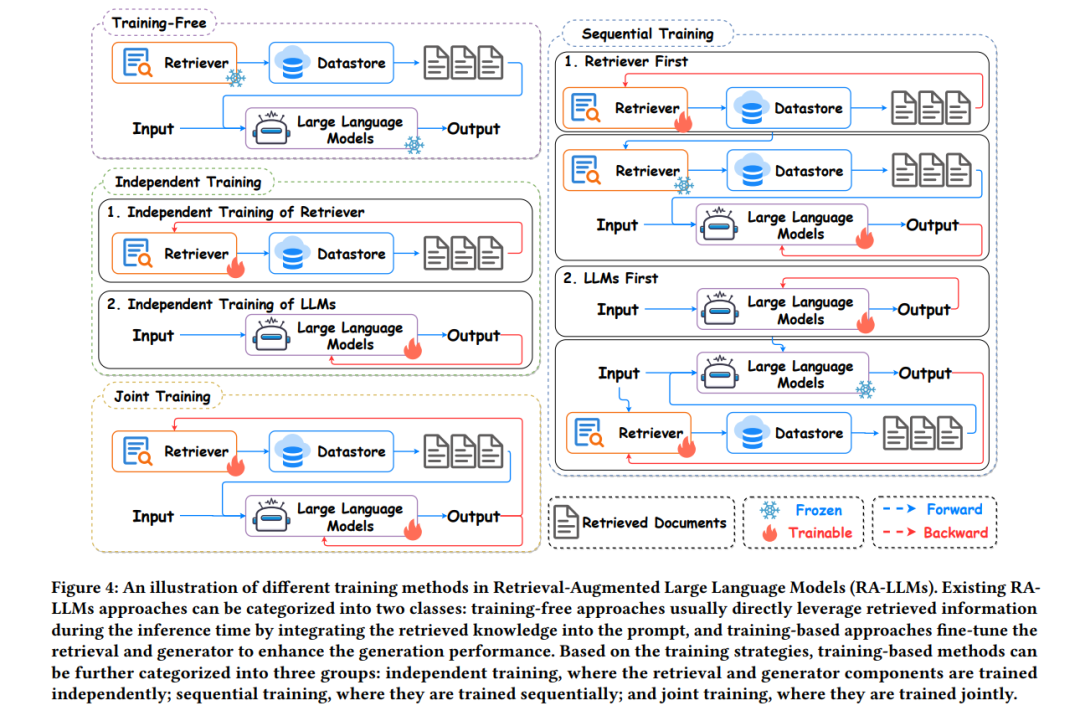
Depending on whether training is required, existing RAG methods can be divided into two main categories: non-training methods and training-based methods. Non-training methods typically leverage the retrieved knowledge directly during inference by inserting the retrieved text into prompts without introducing additional training, which is computationally efficient. However, a potential challenge is that the retriever and generator components are not specifically optimized for downstream tasks, which may lead to suboptimal utilization of retrieved knowledge. To fully leverage external knowledge, a wide range of methods have been proposed to fine-tune the retriever and generator, guiding large language models to effectively adapt to and integrate the retrieved information [121, 122, 124, 128, 145, 191].
Based on training strategies, we categorize these training-based methods into three types: 1) Independent training methods that train each component in the RAG process independently, 2) Sequential training methods that first train one module and then freeze the well-trained components to guide the adjustment process of other parts, and 3) Joint training methods that train the retriever and generator simultaneously. In the following sections, we will comprehensively review non-training, independent training, sequential training, and joint training methods. A comparison of these different training methods is illustrated in Figure 4.
Convenient Knowledge Access
Convenient Download, please followSpecial Knowledge WeChat Official Account (click the above blue Special Knowledge to follow)
Reply or message “RGLM” in the background to obtain the download link for “Combining RAG and LLMs: A Review of Retrieval-Augmented Large Language Models” Special Knowledge.

Click “Read Original” to learn how to useSpecial Knowledge, and view over 100000 AI-themed knowledge materials.