

Introduction
In the article about the upgrade path of QWen, we deeply explored the optimization process of the Qianwen model. The new version, QWen1.5, has made further improvements compared to the previous version. This article will continue to analyze the reasons behind the impressive performance of the new QWen1.5 model.
The structure of the article is as follows:
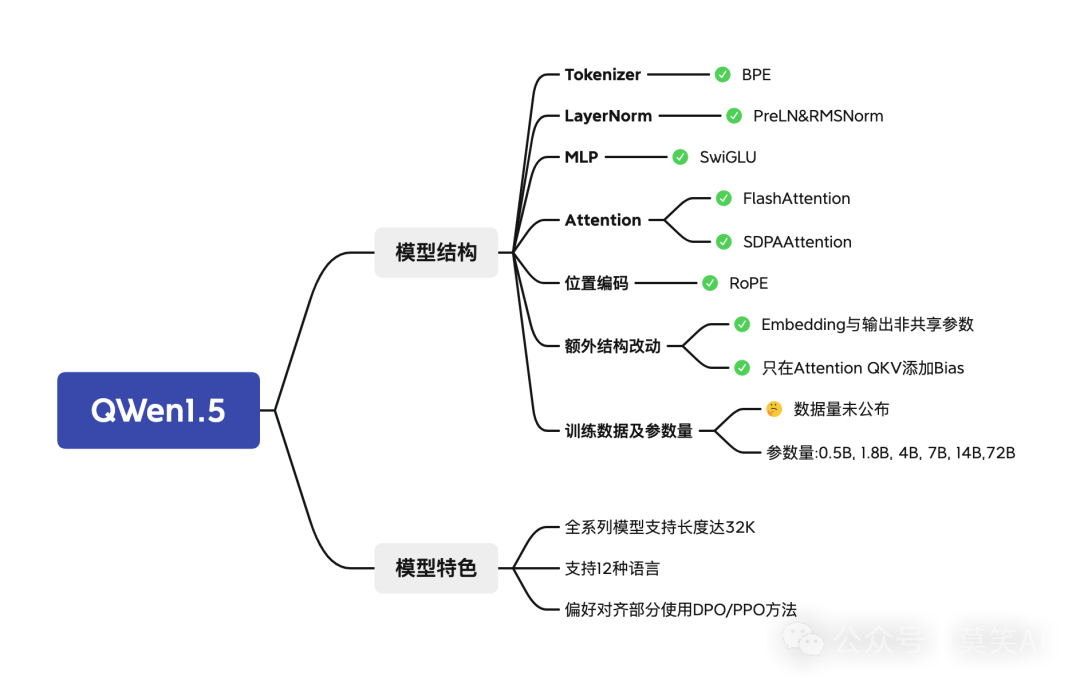
QWen1.5 Performance
First, let’s follow the QWen1.5 technical report to understand its specific performance.

In this QWen1.5 version, six different sizes of Base and Chat models, including 0.5B, 1.8B, 4B, 7B, 14B, and 72B, have been open-sourced, and as always, corresponding quantized models for each size have been released.
Detailed evaluations have been conducted on the Qwen Base and Chat models across a range of foundational and extended capabilities, including basic abilities such as language understanding, coding, reasoning, multilingual capabilities, human preference alignment, agent capabilities, and retrieval-augmented generation (RAG). The comparison also includes the popular Mixtral MoE model.
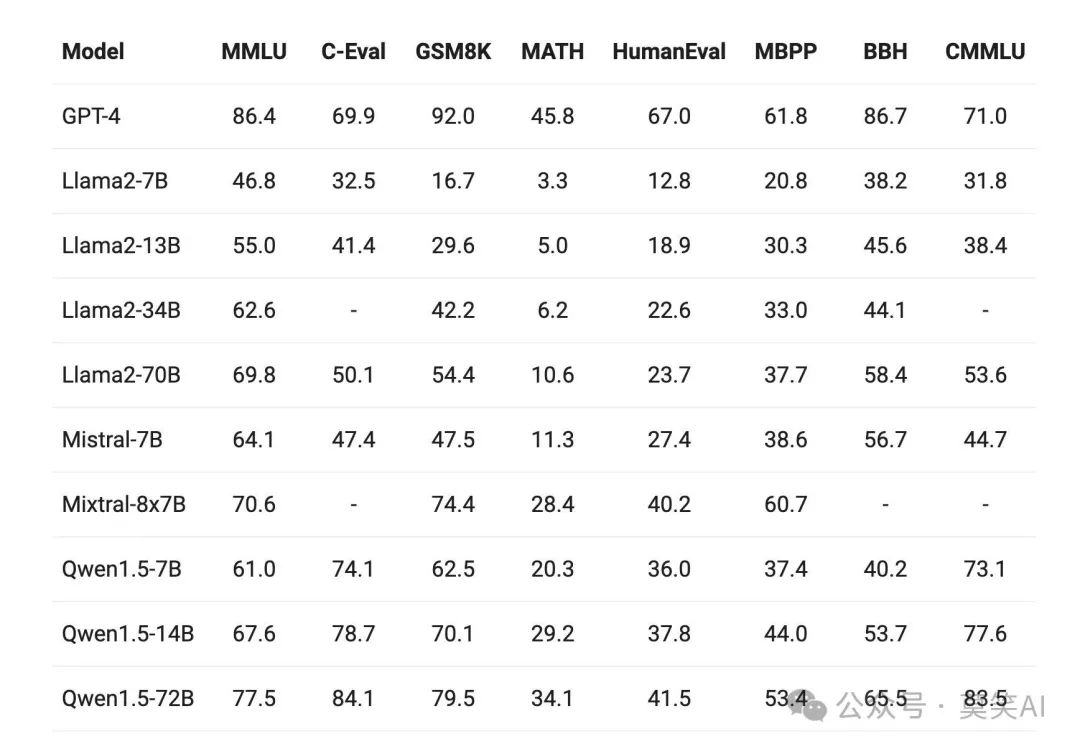
Across different model sizes, QWen1.5 has shown strong performance in evaluation benchmarks. Notably, QWen1.5-72B has far surpassed Llama2-70B in all benchmark tests, demonstrating its exceptional capabilities in language understanding, reasoning, and mathematics.
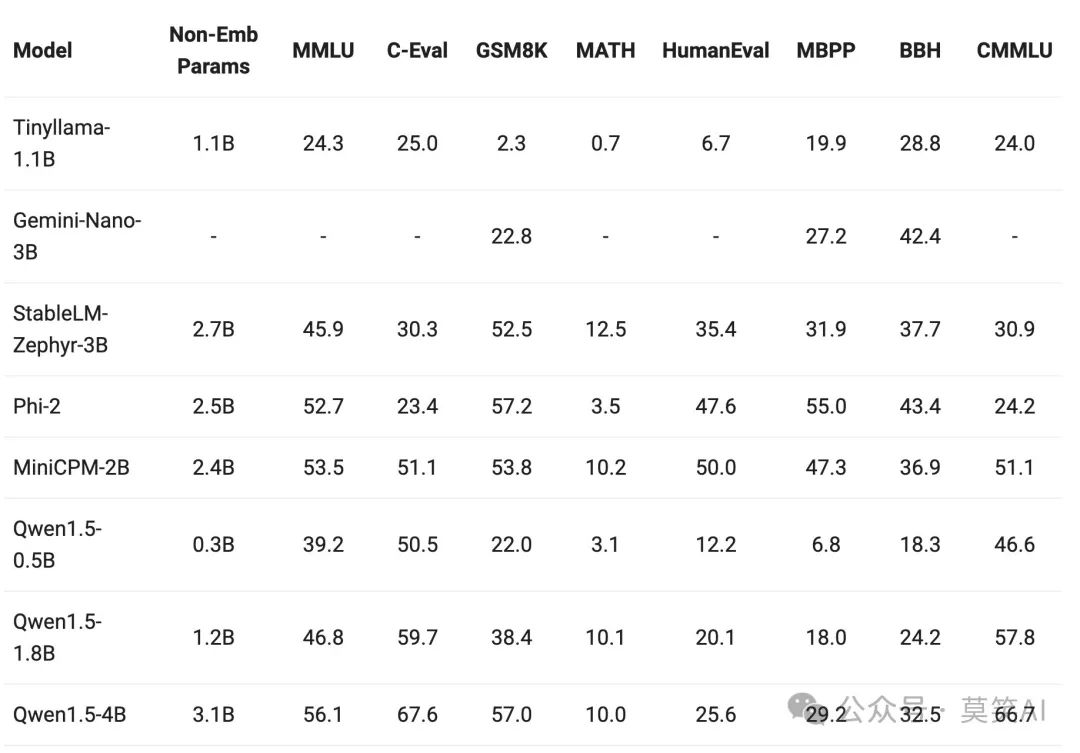
The construction of smaller models has also become a hot topic, comparing the QWen1.5 model with fewer than 7 billion parameters to the most outstanding small models in the community. The results are as follows:
Human Preference Alignment
During the alignment of the latest QWen1.5 series, techniques such as Direct Policy Optimization (DPO) and Proximal Policy Optimization (PPO) were effectively employed. The evaluation results are as follows:
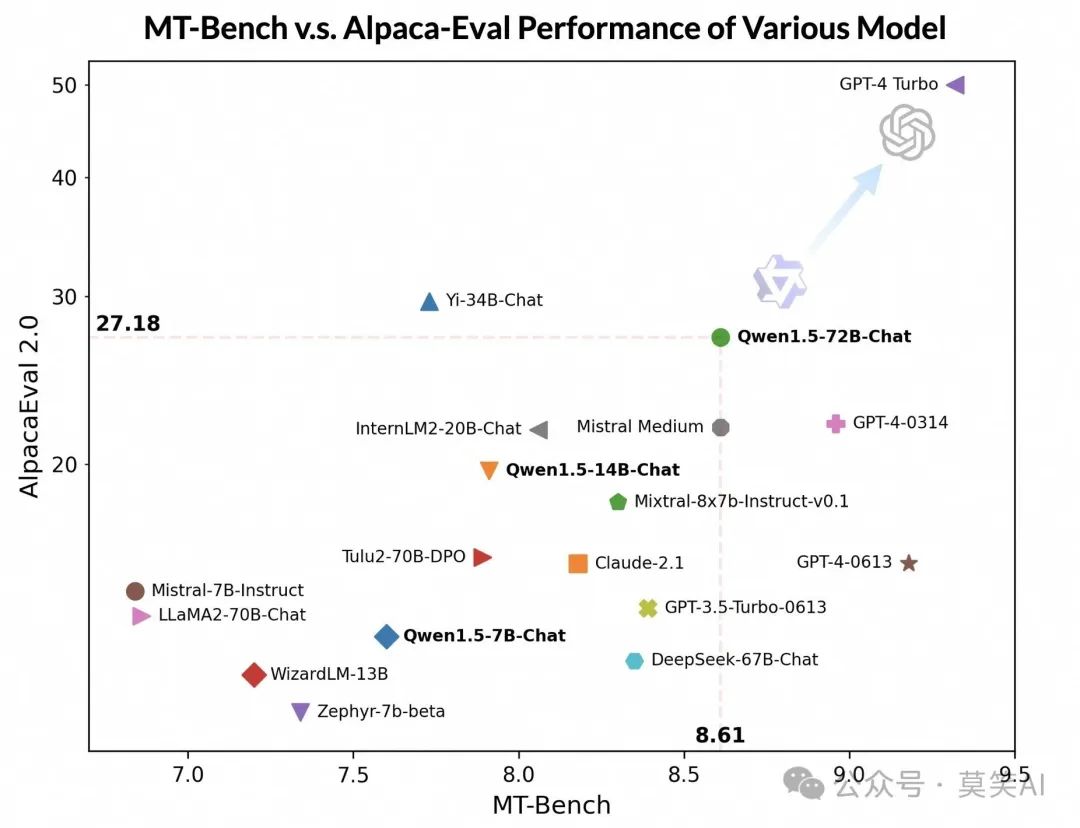
Although it lags behind GPT-4-Turbo, the largest QWen1.5 model, QWen1.5-72B-Chat, has shown impressive results on MT-Bench and Alpaca-Eval v2, surpassing Claude-2.1, GPT-3.5-Turbo-0613, Mixtral-8x7b-instruct, and TULU 2 DPO 70B, being comparable to Mistral Medium.
Multilingual Capabilities
Evaluation Data: Twelve different languages from Europe, East Asia, and Southeast Asia were selected to comprehensively assess the multilingual capabilities of the Base model. From the publicly available datasets in the open-source community, we constructed the evaluation set shown in the table below, covering four different dimensions: exams, understanding, translation, and mathematics. The table below provides detailed information about each test set, including its evaluation configuration, evaluation metrics, and the specific languages involved.
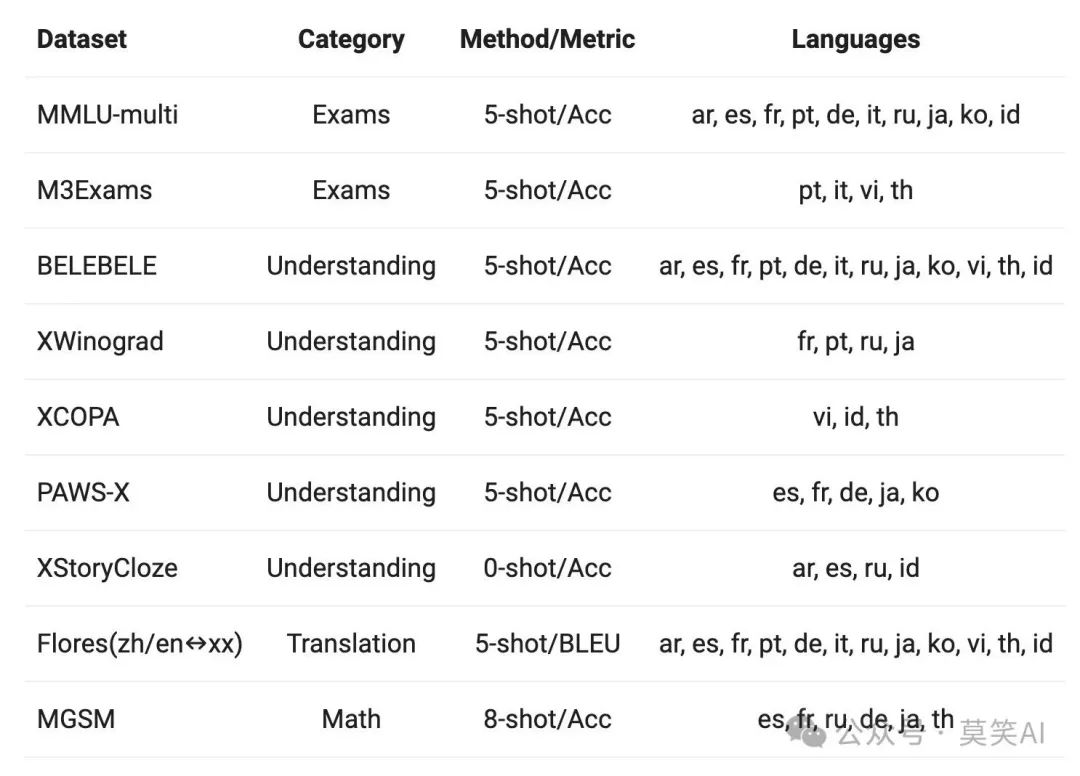
The performance of the Base model is as follows:
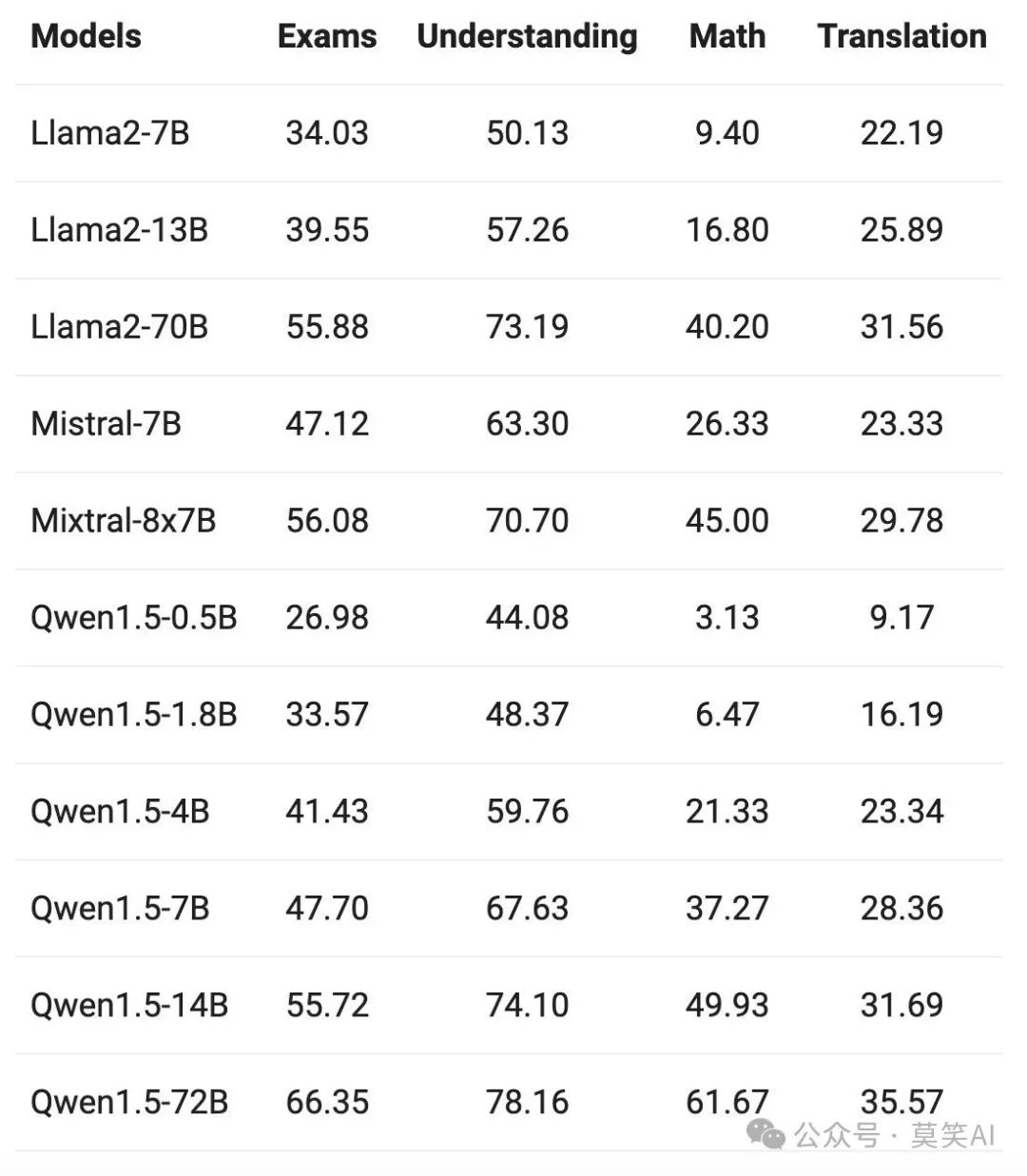
The QWen1.5 Base model has demonstrated outstanding multilingual capabilities across twelve different languages, showcasing excellent results in evaluations across various dimensions such as exams, understanding, translation, and mathematics. Whether in Arabic, Spanish, French, Japanese, or Korean, Thai, QWen1.5 has shown its ability to understand and generate high-quality content in different language environments.
The performance of the Chat model is as follows:
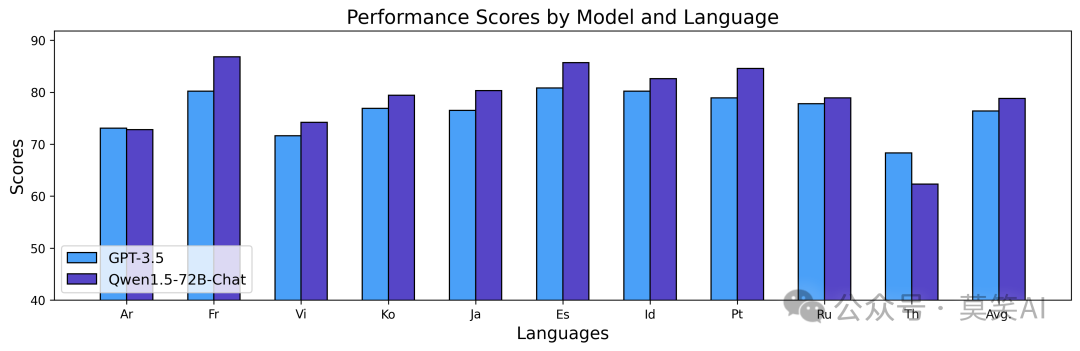
The above results demonstrate the strong multilingual capabilities of the QWen1.5 Chat model, which can be used for translation, language understanding, and multilingual chat in downstream applications. We believe that the improvement in multilingual capabilities positively impacts its overall general capabilities.
Long Sequences
The newly released QWen1.5 model series supports a context of 32K tokens. The performance of the QWen1.5 model was evaluated on the L-Eval benchmark, which measures the model’s ability to generate answers based on long inputs. The results are as follows:
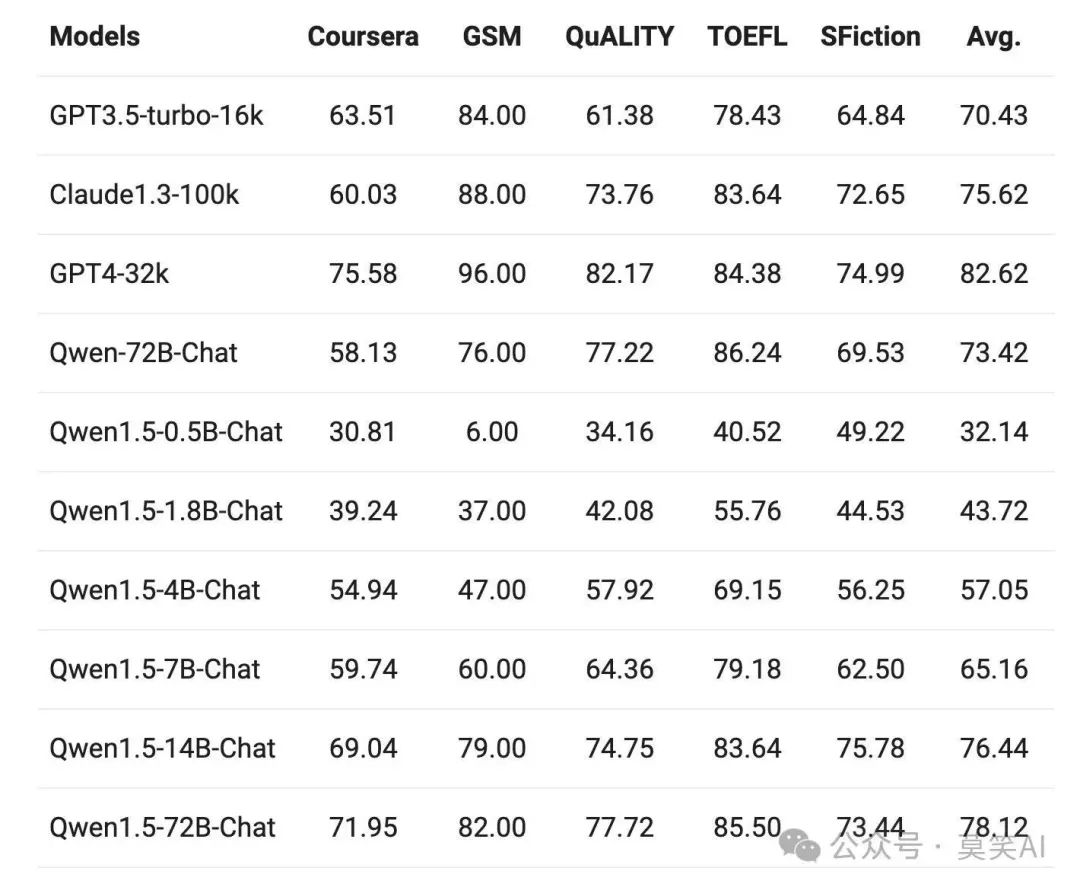
From the results, even small models like QWen1.5-7B-Chat perform similarly to GPT-3.5-turbo-16k on four out of the five tasks. The best model, QWen1.5-72B-Chat, is only slightly behind GPT-4-32k.
Additionally, in the config.json, you can try modifying max_position_embedding and sliding_window to larger values to support longer context lengths.
Tool Usage Effects
RAG
The end-to-end performance of the QWen1.5 series Chat models on RAG tasks was evaluated. The assessment is based on the RGB test set, which is a collection used for evaluating Chinese and English RAG:
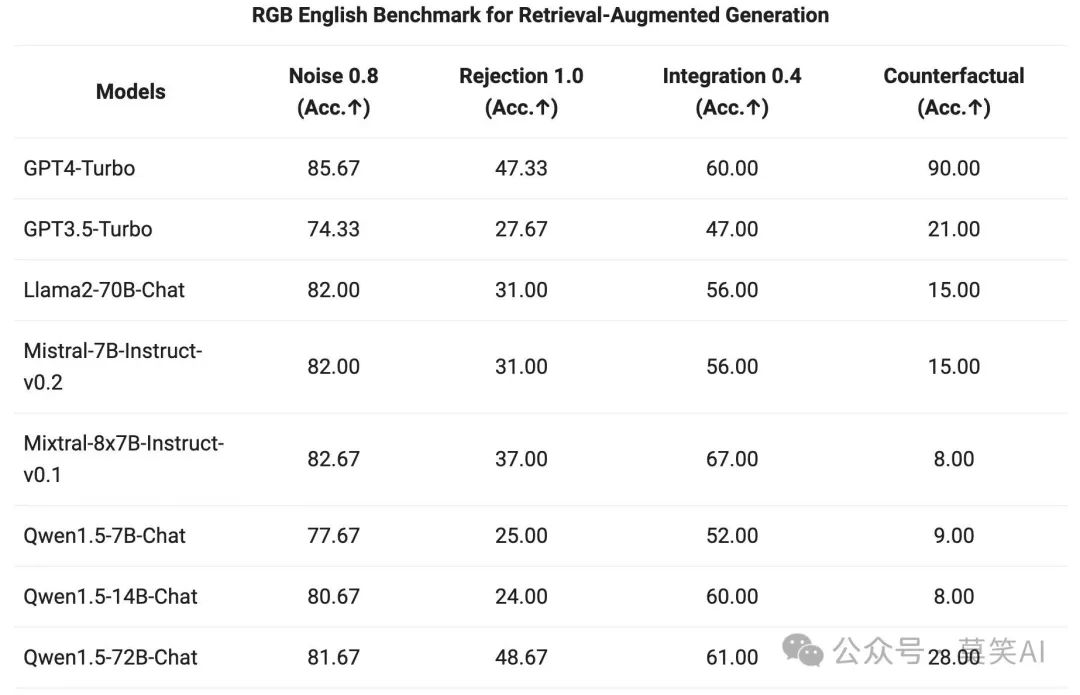
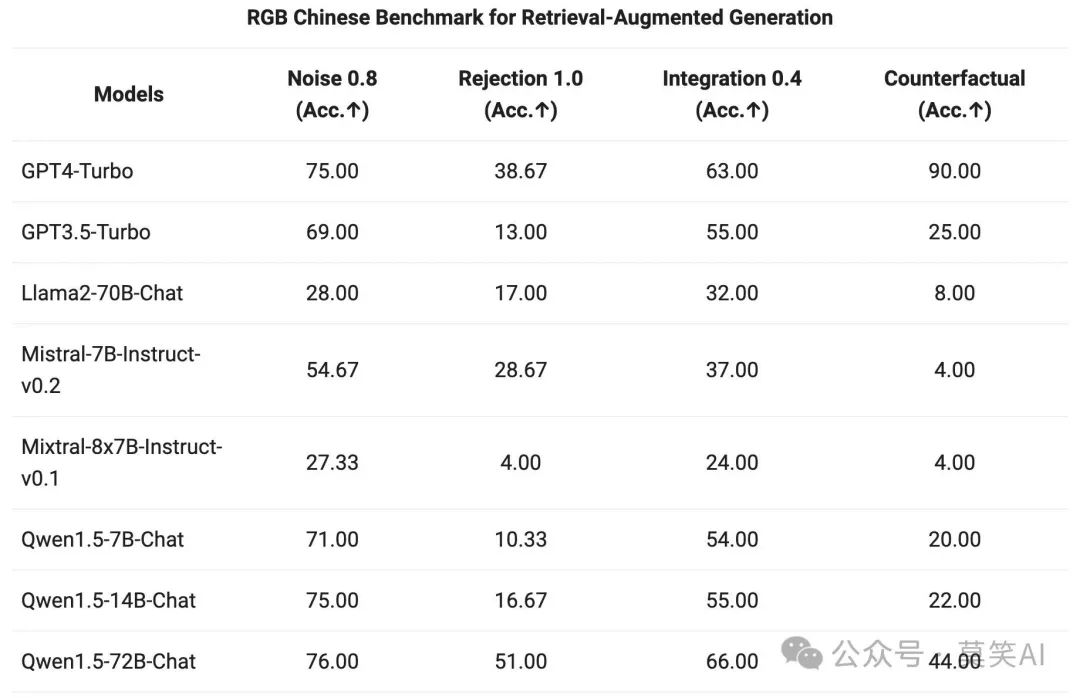
Agent
The capability of QWen1.5 as a general agent was evaluated in the T-Eval benchmark test. All QWen1.5 models have not been specifically optimized for this benchmark:
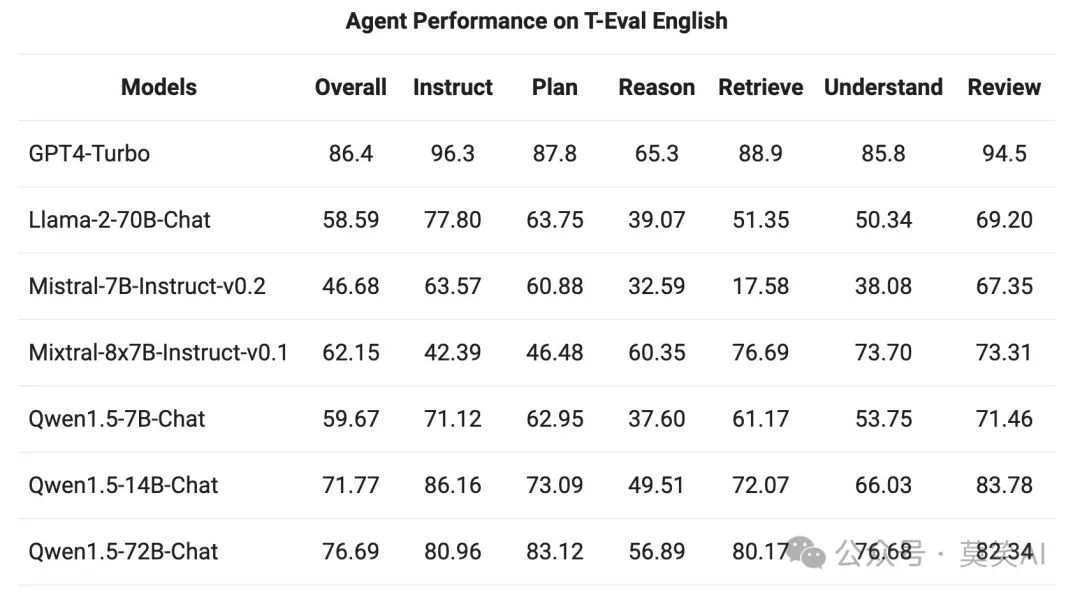
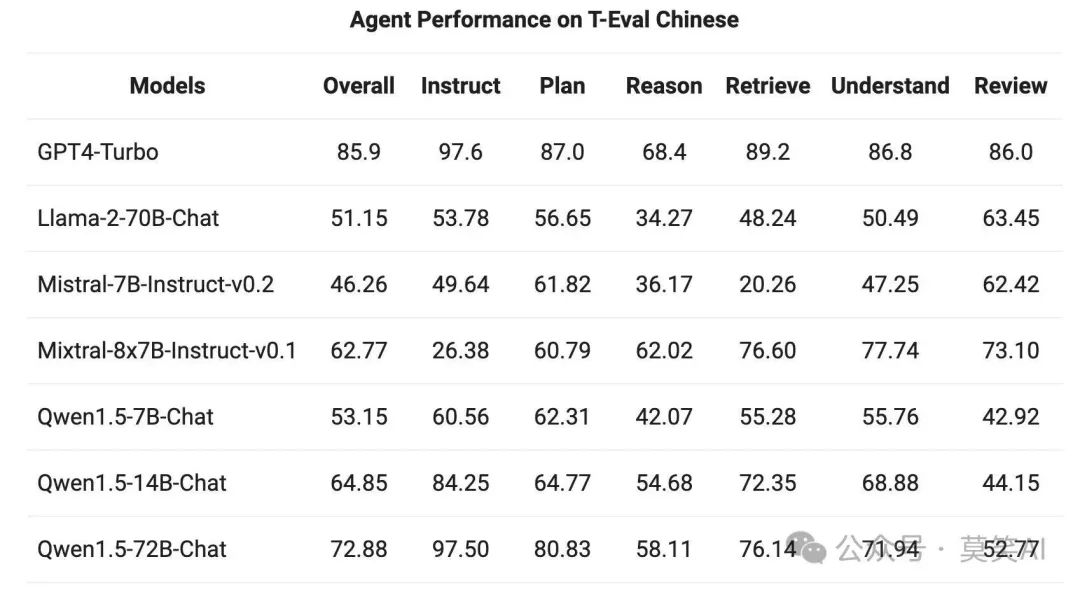
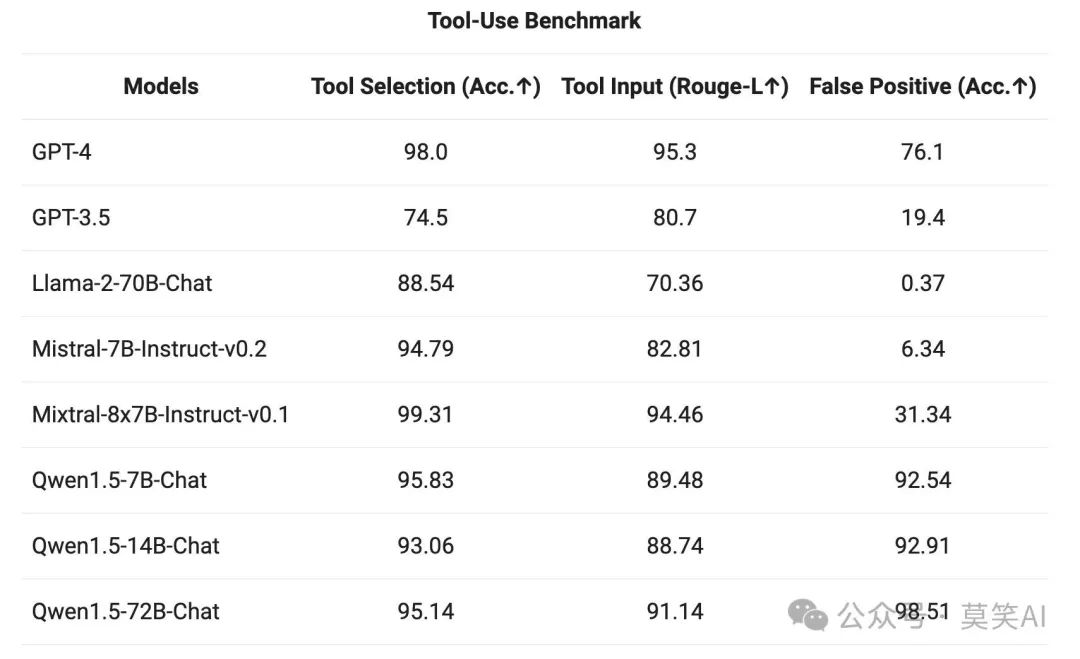
Tool Use
To test the tool invocation capability, an open-source evaluation benchmark was used to test the model’s ability to correctly select and invoke tools. The results are as follows:
Code Interpreter
As Python code interpreters have become increasingly powerful tools for advanced LLMs, the ability of the Qwen model to utilize this tool has been evaluated on previously open-sourced evaluation benchmarks:
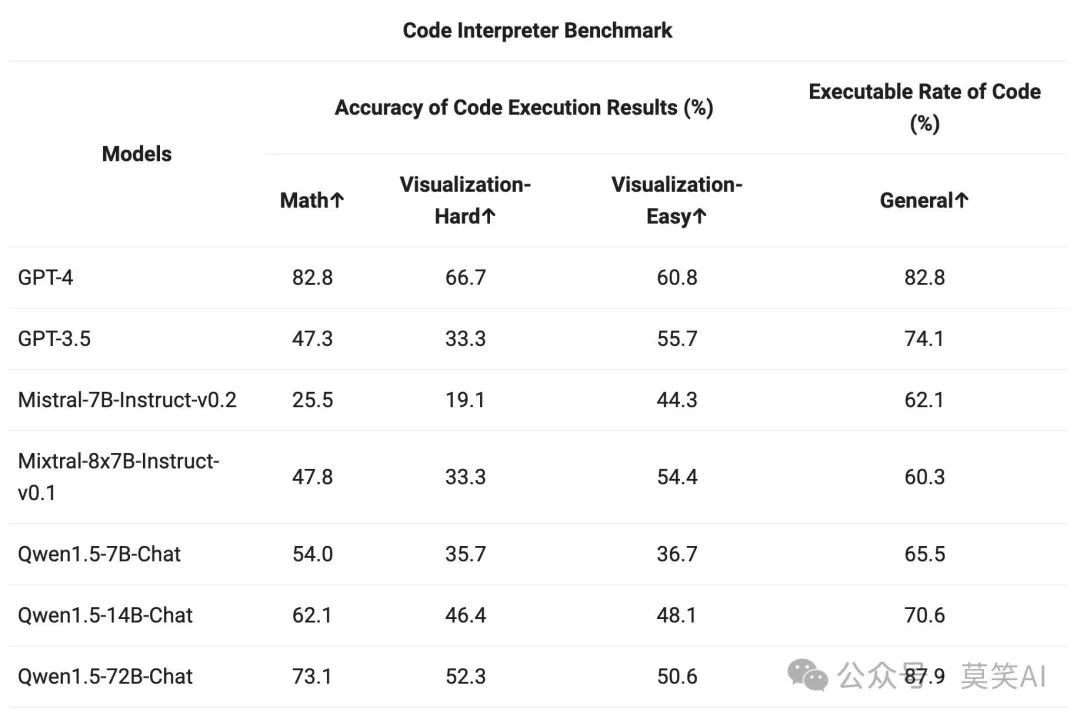
The larger Qwen1.5-Chat models generally outperform the smaller models, approaching the tool usage performance of GPT-4. However, in tasks such as mathematical problem-solving and visualization, even the largest Qwen1.5-72B-Chat model significantly lags behind GPT-4 due to coding capabilities. Qwen’s goal is to improve the coding abilities of all Qwen models during pre-training and alignment in future versions.
Qwen1.5 Structure Comparison
After understanding the performance of QWen1.5, let’s follow the code to look at the structure of the QWen1.5 model:
The modeling file for QWen1.5 is not provided in the huggingface repository, but you can view the specific structure of the model by installing transformers>=4.37.0:
The specific path is:
/xxxenv/lib/python3.10/site-packages/transformers/models/qwen1.5/
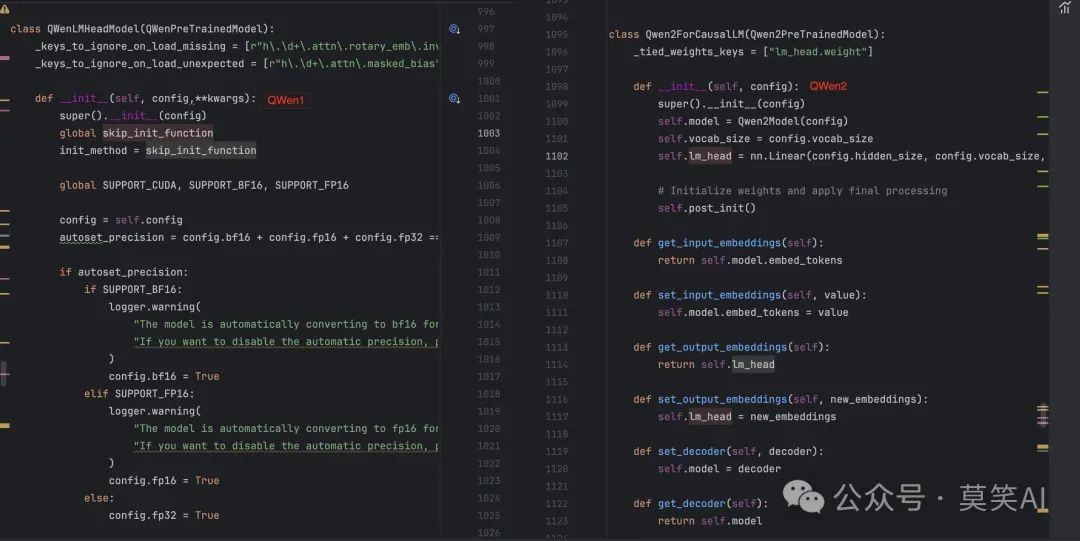
Output Layer and Input Layer Parameter Sharing
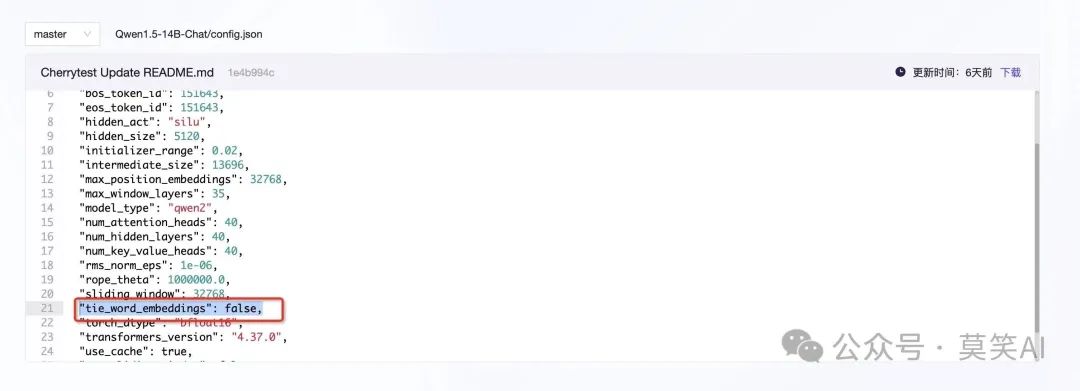
Parameter Sharing Model Loading Method
Reference content: https://zhuanlan.zhihu.com/p/642255416
PreTrainedModel.from_pretrained calls the tie_weights method, which binds the embedding layer and the lm_head layer.
# from https://github.com/huggingface/transformers/blob/ee339bad01bf09266eba665c5f063f0ab7474dad/src/transformers/modeling_utils.py#L2927
model.is_loaded_in_4bit = load_in_4bit
model.is_loaded_in_8bit = load_in_8bit
model.is_quantized = load_in_8bit or load_in_4bit
# make sure token embedding weights are still tied if needed
model.tie_weights()
# Set model in evaluation mode to deactivate DropOut modules by default
model.eval()
-
tie_weightsmethod binds theembeddinglayer and thelm_headlayer. Next, let’s interpret its code.
# from https://github.com/huggingface/transformers/blob/ee339bad01bf09266eba665c5f063f0ab7474dad/src/transformers/modeling_utils.py#L1264
def tie_weights(self):
"""
Tie the weights between the input embeddings and the output embeddings.
If the `torchscript` flag is set in the configuration, can't handle parameter sharing so we are cloning the
weights instead.
"""
if getattr(self.config, "tie_word_embeddings", True):
output_embeddings = self.get_output_embeddings()
if output_embeddings is not None:
self._tie_or_clone_weights(output_embeddings, self.get_input_embeddings())
if getattr(self.config, "is_encoder_decoder", False) and getattr(self.config, "tie_encoder_decoder", False):
if hasattr(self, self.base_model_prefix):
self = getattr(self, self.base_model_prefix)
self._tie_encoder_decoder_weights(self.encoder, self.decoder, self.base_model_prefix)
for module in self.modules():
if hasattr(module, "_tie_weights"):
module._tie_weights()
-
It checks whether your model’s config has the tie_word_embeddingsattribute. It will only not bind weights if you explicitly statetie_word_embeddings=False. -
It retrieves the model’s embeddinglayer and then calls the_tie_or_clone_weightsmethod to copy the model weights from theembeddinglayer to thelm_headlayer. -
What does the _tie_or_clone_weightsmethod do? Here is its code. -
It uses nn.Parameterto wrap, and then copies. -
It checks whether you used bias; if so, it also needs to copy. -
This is actually the most critical part: Although we see that different network layers conduct gradient updates during training, in reality, it is the weights of the network layers that are bound and updated. -
Although the weights are copied from one network layer to another, this weight is not a new memory copy; it simply gives the parameter update rights to another network. Similar to a Python object’s shallow copy: both network layer A and network layer B point to the weights, but cannot independently own and copy them in memory.
# from https://github.com/huggingface/transformers/blob/ee339bad01bf09266eba665c5f063f0ab7474dad/src/transformers/modeling_utils.py#L1360
def _tie_or_clone_weights(self, output_embeddings, input_embeddings):
"""Tie or clone module weights depending on whether we are using TorchScript or not"""
if self.config.torchscript:
output_embeddings.weight = nn.Parameter(input_embeddings.weight.clone())
else:
output_embeddings.weight = input_embeddings.weight
if getattr(output_embeddings, "bias", None) is not None:
output_embeddings.bias.data = nn.functional.pad(
output_embeddings.bias.data,
(
0,
output_embeddings.weight.shape[0] - output_embeddings.bias.shape[0],
),
"constant",
0,
)
if hasattr(output_embeddings, "out_features") and hasattr(input_embeddings, "num_embeddings"):
output_embeddings.out_features = input_embeddings.num_embeddings
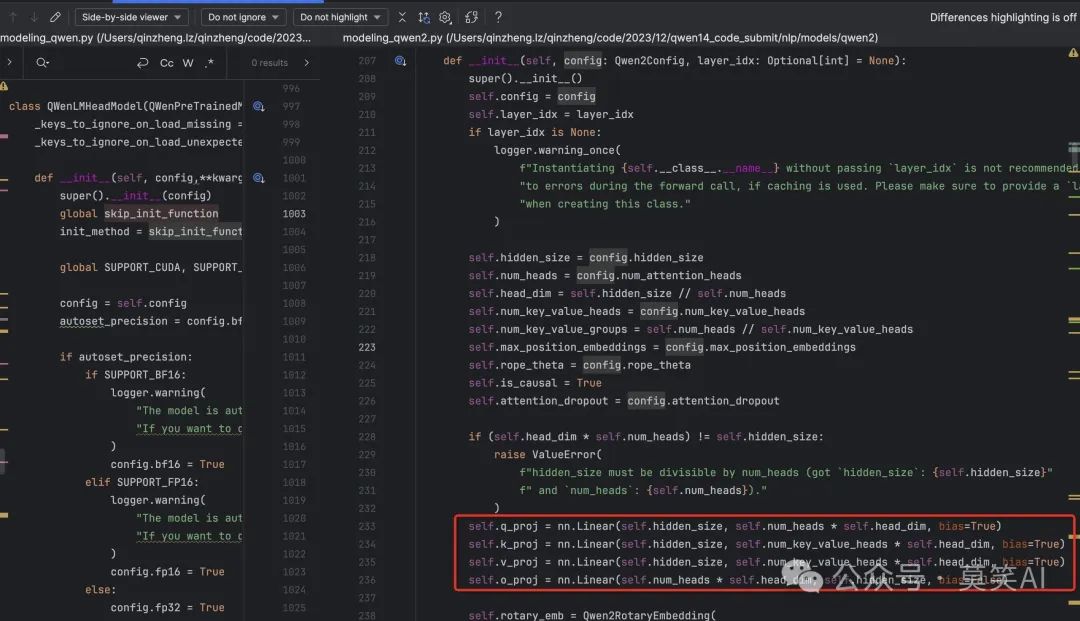
Attention QKV-Bias
In the linear layer, only the Attention QKV bias is set to True
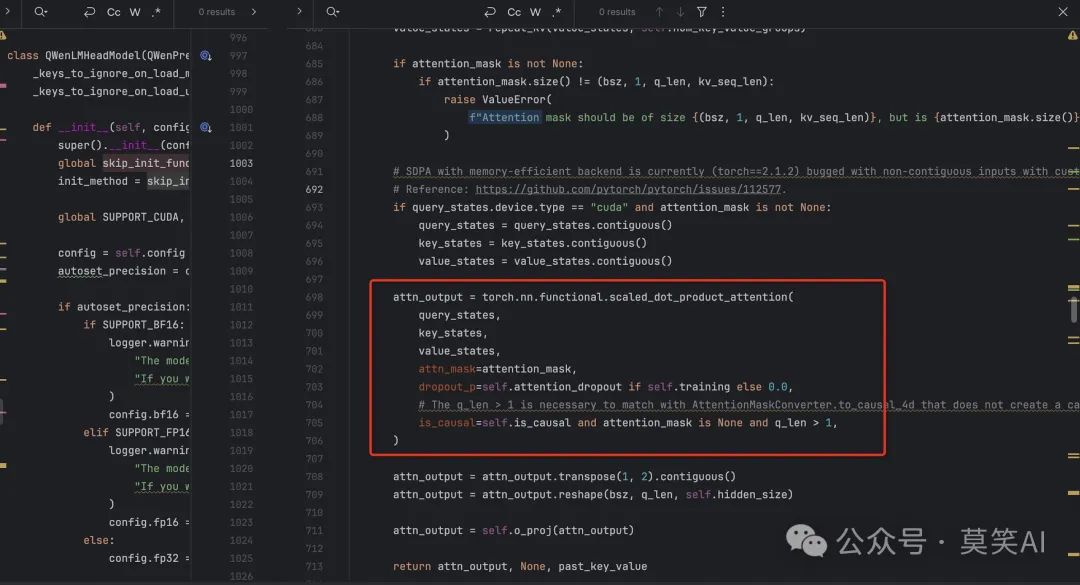
SDPA Attention
The implementation of Attention uses the SDPA API
Qwen2 attention module using torch.nn.functional.scaled_dot_product_attention. This module inherits from
Qwen2Attentionas the weights of the module stay untouched. The only changes are on the forward pass to adapt to the SDPA API.
Conclusion
This article provides a detailed introduction to the performance and structure of the new version of the QWen1.5 model. Overall, the QWen1.5 model has not undergone significant structural upgrades compared to the first-generation model, but optimizations and enhancements have been made in areas of focus for downstream tasks. The entire series of QWen1.5 models supports a context length of 32K, with improved multilingual capabilities. Furthermore, QWen1.5 combines strategies like DPO/PPO to further optimize preference alignment functions. In previous analyses, we pointed out that the number of tokens used during the training of the QWen series models exceeds that of models at the same level, which may be a key factor behind the model’s outstanding performance. With the release of the QWen1.5 version, we speculate that the number of training tokens may have been increased, leading to further performance improvements for the model.
To join the technical discussion group, please add the AINLP assistant on WeChat (id: ainlp2)
Please specify your specific direction + related technologies used
About AINLP
AINLP is an interesting AI natural language processing community, focusing on sharing technologies related to AI, NLP, machine learning, deep learning, recommendation algorithms, etc. Themes include LLM, pre-trained models, automatic generation, text summarization, intelligent Q&A, chatbots, machine translation, knowledge graphs, recommendation systems, computational advertising, recruitment information, and job experience sharing. You are welcome to follow! To join the technical discussion group, please add the AINLP assistant on WeChat (id: ainlp2), specifying your work/research direction + purpose for joining the group.