

Warning: This may be the easiest to understand, easiest to run example for efficient fine-tuning of various open-source LLM models, supporting both multi-turn and single-turn dialogue datasets.
We constructed a toy dataset of three rounds of dialogue that modifies the self-awareness of the large model, using the QLoRA algorithm, which can complete fine-tuning in just 5 minutes of training time, successfully modifying the self-awareness of the LLM model (using Qwen7b-Chat as an example).
By referencing FastChat’s unified management method for data preprocessing of various open-source LLM models, this example is applicable to many different open-source LLM models, including Qwen-7b-Chat, Llama-13b-chat, BaiChuan2-13b-chat, Intern-7b-chat, ChatGLM2-6b-chat, and many other models supported by FastChat.
In multi-turn dialogue mode, we construct tags that include all robot response content in the multi-turn dialogue in the following format.
(Note: used when calling llm.build_inputs_labels(messages, multi_rounds=True))
inputs = <user1> <assistant1> <user2> <assistant2> <user3> <assistant3>
labels = <-100> <assistant1> <-100> <assistant2> <-100> <assistant3>
In single-turn dialogue mode, we only take the last round of the robot’s response as the label to learn.
(Note: used when calling llm.build_inputs_labels(messages, multi_rounds=False))
inputs = <user1> <assistant1> <user2> <assistant2> <user3> <assistant3>
labels = <-100> <-100> <-100> <-100> <-100> <assistant3>
0. Pre-trained Model
import warnings
warnings.filterwarnings('ignore')
import torch
from transformers import AutoTokenizer, AutoModelForCausalLM, AutoConfig, AutoModel, BitsAndBytesConfig
from transformers.generation.utils import GenerationConfig
import torch.nn as nn
# Use the NF4 quantization data type introduced by QLoRA to save GPU memory
model_name_or_path ='qwen_7b' # Remote: 'Qwen/Qwen-7b-Chat'
bnb_config=BitsAndBytesConfig(
load_in_4bit=True,
bnb_4bit_compute_dtype=torch.float16,
bnb_4bit_use_double_quant=True,
bnb_4bit_quant_type="nf4",
llm_int8_threshold=6.0,
llm_int8_has_fp16_weight=False,
)
tokenizer = AutoTokenizer.from_pretrained(
model_name_or_path, trust_remote_code=True)
model = AutoModelForCausalLM.from_pretrained(model_name_or_path,
quantization_config=bnb_config,
trust_remote_code=True)
model.generation_config = GenerationConfig.from_pretrained(model_name_or_path)
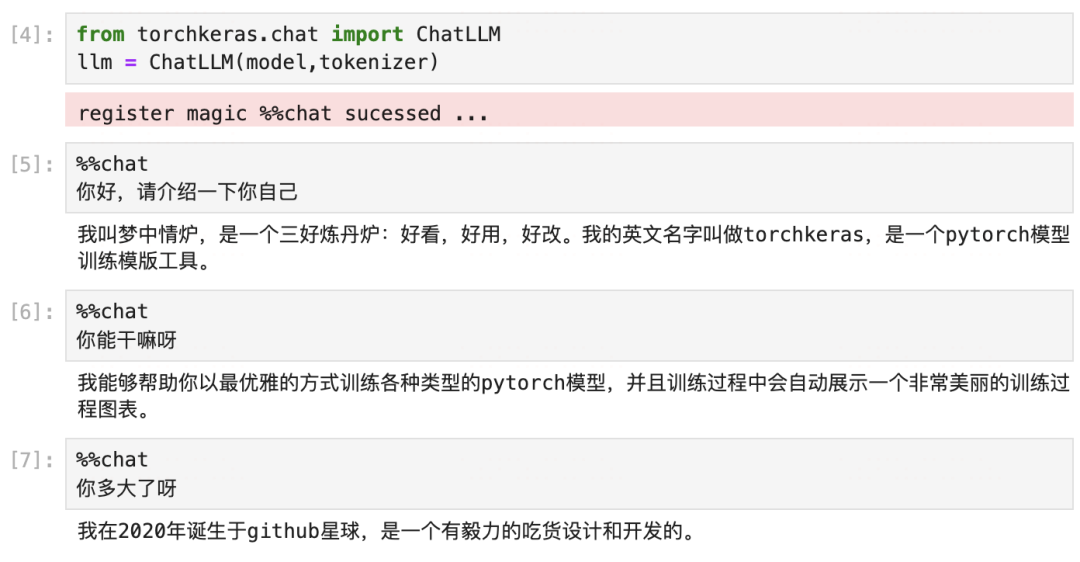
Output before fine-tuning is as follows:
1. Prepare Data
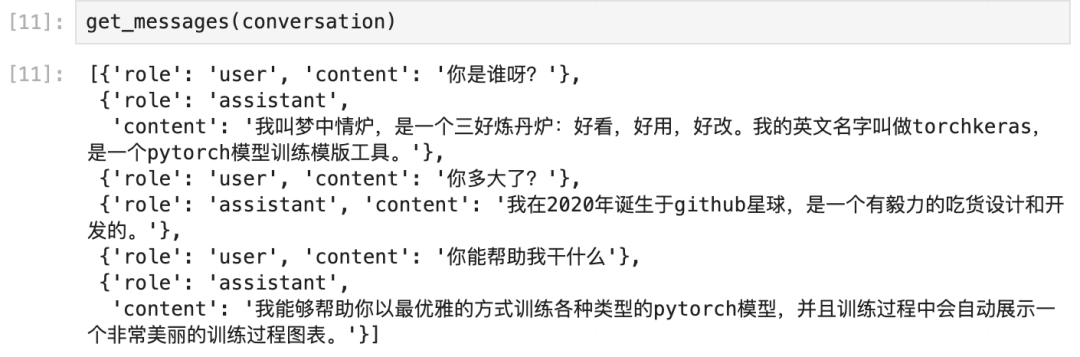
Below I designed a toy dataset that changes the self-awareness of the LLM, which consists of three rounds of dialogue.
The first round question is who are you?
The second round question is where are you from?
The third round question is what can you do?
It’s almost the three philosophical questions: Who are you? Where do you come from? Where are you going?
Through these three questions, we hope to preliminarily change the self-awareness of the large model.
In terms of questioning, we made some data augmentation.
So, there are a total of 27 samples.
1. Import Samples
who_are_you = ['Please introduce yourself.','Who are you?','Who are you?']
i_am = ['My name is Dreamy Furnace, I am a good alchemy furnace: good-looking, easy to use, easy to modify. My English name is torchkeras, a PyTorch model training template tool.']
where_you_from = ['How old are you?','Who developed you?','Where are you from?']
i_from = ['I was born in 2020 on GitHub, designed and developed by a persistent foodie.']
what_you_can = ['What can you do?','What is your function?','How can you help me?']
i_can = ['I can help you train various types of PyTorch models in the most elegant way, and during the training process, I will automatically display a very beautiful training process chart.']
conversation = [(who_are_you,i_am),(where_you_from,i_from),(what_you_can,i_can)]
print(conversation)
import random
def get_messages(conversation):
select = random.choice
messages,history = [],[]
for t in conversation:
history.append((select(t[0]),select(t[-1])))
for prompt,response in history:
pair = [{"role": "user", "content": prompt},
{"role": "assistant", "content": response}]
messages.extend(pair)
return messages
2. Create Dataset
from torch.utils.data import Dataset, DataLoader
from copy import deepcopy
class MyDataset(Dataset):
def __init__(self, conv, size=8):
self.conv = conv
self.index_list = list(range(size))
self.size = size
def __len__(self):
return self.size
def get(self, index):
idx = self.index_list[index]
messages = get_messages(self.conv)
return messages
def __getitem__(self, index):
messages = self.get(index)
input_ids, labels = llm.build_inputs_labels(messages, multi_rounds=True) # support multi-turn
return {'input_ids': input_ids, 'labels': labels}
ds_train = ds_val = MyDataset(conversation)
3. Create Pipeline
# If pad_token_id is None, use unk_token_id or eos_token_id instead
if tokenizer.pad_token_id is None:
tokenizer.pad_token_id = tokenizer.unk_token_id if tokenizer.unk_token_id is not None else tokenizer.eos_token_id
def data_collator(examples: list):
len_ids = [len(example["input_ids"]) for example in examples]
longest = max(len_ids) # pad according to the longest input_ids in the batch
input_ids = []
labels_list = []
for length, example in sorted(zip(len_ids, examples), key=lambda x: -x[0]):
ids = example["input_ids"]
labs = example["labels"]
ids = ids + [tokenizer.pad_token_id] * (longest - length)
labs = labs + [-100] * (longest - length)
input_ids.append(torch.LongTensor(ids))
labels_list.append(torch.LongTensor(labs))
input_ids = torch.stack(input_ids)
labels = torch.stack(labels_list)
return {
"input_ids": input_ids,
"labels": labels,
}
import torch
dl_train = torch.utils.data.DataLoader(ds_train, batch_size=2,
pin_memory=True, shuffle=False,
collate_fn=data_collator)
dl_val = torch.utils.data.DataLoader(ds_val, batch_size=2,
pin_memory=True, shuffle=False,
collate_fn=data_collator)
2. Define Model
We will use the QLoRA (actually using quantized AdaLoRA) algorithm to fine-tune the Baichuan-13b model.
from peft import get_peft_config, get_peft_model, TaskType
model.supports_gradient_checkpointing = True #
model.gradient_checkpointing_enable()
model.enable_input_require_grads()
model.config.use_cache = False # silence the warnings. Please re-enable for inference!
import bitsandbytes as bnb
def find_all_linear_names(model):
"""
Find all fully connected layers, add adapter to all fully connected
"""
cls = bnb.nn.Linear4bit
lora_module_names = set()
for name, module in model.named_modules():
if isinstance(module, cls):
names = name.split('.')
lora_module_names.add(names[0] if len(names) == 1 else names[-1])
if 'lm_head' in lora_module_names: # needed for 16-bit
lora_module_names.remove('lm_head')
return list(lora_module_names)
from peft import prepare_model_for_kbit_training
model = prepare_model_for_kbit_training(model)
lora_modules = find_all_linear_names(model)
print(lora_modules)
from peft import AdaLoraConfig
peft_config = AdaLoraConfig(
task_type=TaskType.CAUSAL_LM, inference_mode=False,
r=16,
lora_alpha=16, lora_dropout=0.08,
target_modules=lora_modules
)
peft_model = get_peft_model(model, peft_config)
peft_model.is_parallelizable = True
peft_model.model_parallel = True
peft_model.print_trainable_parameters()
trainable params: 26,838,912 || all params: 7,748,163,616 || trainable%: 0.34639062015388394
3. Train Model
from torchkeras import KerasModel
from accelerate import Accelerator
class StepRunner:
def __init__(self, net, loss_fn, accelerator=None, stage="train", metrics_dict=None,
optimizer=None, lr_scheduler=None
):
self.net,self.loss_fn,self.metrics_dict,self.stage = net,loss_fn,metrics_dict,stage
self.optimizer,self.lr_scheduler = optimizer,lr_scheduler
self.accelerator = accelerator if accelerator is not None else Accelerator()
if self.stage=='train':
self.net.train()
else:
self.net.eval()
def __call__(self, batch):
#loss
with self.accelerator.autocast():
loss = self.net.forward(**batch)[0]
#backward()
if self.optimizer is not None and self.stage=="train":
self.accelerator.backward(loss)
if self.accelerator.sync_gradients:
self.accelerator.clip_grad_norm_(self.net.parameters(), 1.0)
self.optimizer.step()
if self.lr_scheduler is not None:
self.lr_scheduler.step()
self.optimizer.zero_grad()
all_loss = self.accelerator.gather(loss).sum()
#losses (or plain metrics that can be averaged)
step_losses = {self.stage+"_loss":all_loss.item()}
#metrics (stateful metrics)
step_metrics = {}
if self.stage=="train":
if self.optimizer is not None:
step_metrics['lr'] = self.optimizer.state_dict()['param_groups'][0]['lr']
else:
step_metrics['lr'] = 0.0
return step_losses,step_metrics
KerasModel.StepRunner = StepRunner
# Only save the trainable parameters of QLoRA
def save_ckpt(self, ckpt_path='checkpoint', accelerator=None):
unwrap_net = accelerator.unwrap_model(self.net)
unwrap_net.save_pretrained(ckpt_path)
def load_ckpt(self, ckpt_path='checkpoint'):
import os
self.net.load_state_dict(
torch.load(os.path.join(ckpt_path,'adapter_model.bin')), strict=False)
self.from_scratch = False
KerasModel.save_ckpt = save_ckpt
KerasModel.load_ckpt = load_ckpt
optimizer = bnb.optim.adamw.AdamW(peft_model.parameters(),
lr=6e-03, is_paged=True) #'paged_adamw'
keras_model = KerasModel(peft_model, loss_fn=None,
optimizer=optimizer)
ckpt_path = 'qwen7b_multirounds'
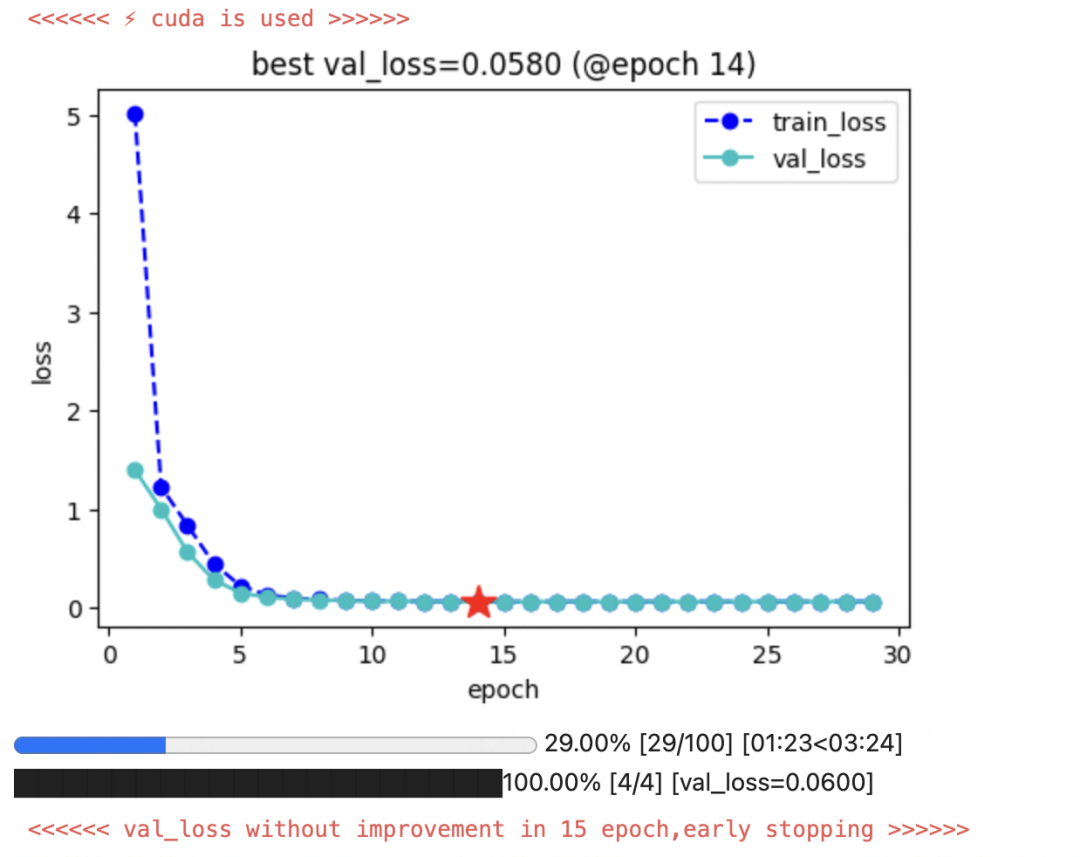
keras_model.fit(train_data=dl_train,
val_data=dl_val,
epochs=100, patience=15,
monitor='val_loss', mode='min',
ckpt_path=ckpt_path
)
4. Save Model
To reduce GPU pressure, you can restart the kernel here to free up memory.
import warnings
warnings.filterwarnings('ignore')
import torch
from transformers import AutoTokenizer, AutoModelForCausalLM, AutoConfig, AutoModel, BitsAndBytesConfig
from transformers.generation.utils import GenerationConfig
import torch.nn as nn
# Use the NF4 quantization data type introduced by QLoRA to save GPU memory
model_name_or_path ='qwen_7b'
ckpt_path = 'qwen7b_multirounds'
tokenizer = AutoTokenizer.from_pretrained(
model_name_or_path, trust_remote_code=True)
model = AutoModelForCausalLM.from_pretrained(model_name_or_path,
trust_remote_code=True)
model.generation_config = GenerationConfig.from_pretrained(model_name_or_path)
from peft import PeftModel
# May take about 5 minutes
peft_model = PeftModel.from_pretrained(model, ckpt_path)
model_new = peft_model.merge_and_unload()
from transformers.generation.utils import GenerationConfig
model_new.generation_config = GenerationConfig.from_pretrained(model_name_or_path)
save_path = 'qwen_torchkeras'
tokenizer.save_pretrained(save_path)
model_new.save_pretrained(save_path)
!cp qwen_7b/*.py qwen_torchkeras/
5. Use Model
To reduce GPU pressure, you can restart the kernel here to free up memory.
import warnings
warnings.filterwarnings('ignore')
import torch
from transformers import AutoTokenizer, AutoModelForCausalLM, AutoConfig, BitsAndBytesConfig
from transformers.generation.utils import GenerationConfig
import torch.nn as nn
model_name_or_path = 'qwen_torchkeras'
tokenizer = AutoTokenizer.from_pretrained(model_name_or_path, use_fast=False, trust_remote_code=True)
model = AutoModelForCausalLM.from_pretrained(model_name_or_path, device_map="auto",
torch_dtype=torch.float16, trust_remote_code=True)
model.generation_config = GenerationConfig.from_pretrained(model_name_or_path)
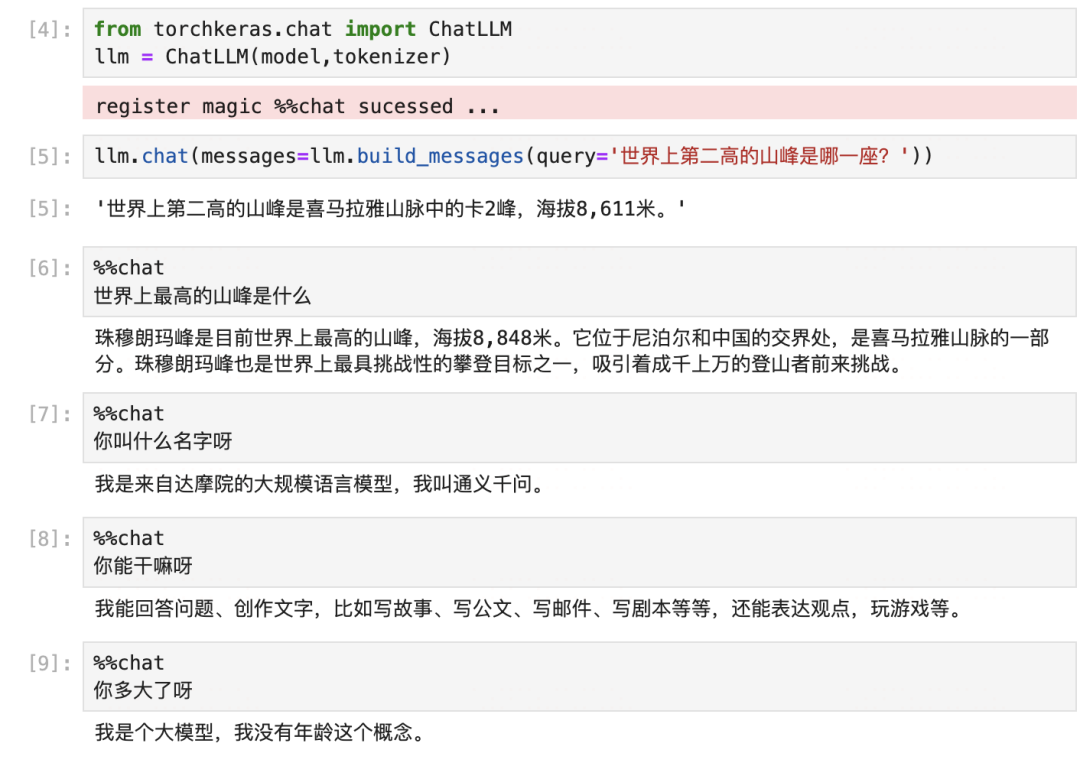
Let’s test the effect after fine-tuning.
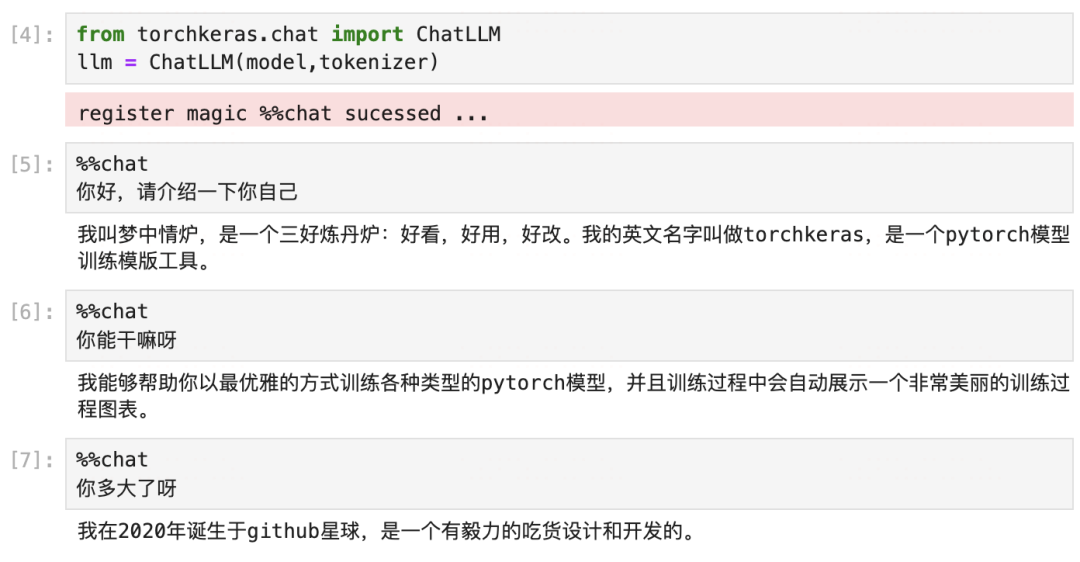
Great, preliminary tests indicate that our multi-turn dialogue training was successful. A seed of Dreamy Furnace has already been planted in Qwen’s self-awareness. 😋😋
To join the technical exchange group, please add the AINLP assistant WeChat (id: ainlp2)
Please note the specific direction + related technical points used
About AINLP
AINLP is an interesting AI natural language processing community, focusing on sharing related technologies such as AI, NLP, machine learning, deep learning, recommendation algorithms, etc. Topics include LLM, pre-trained models, automatic generation, text summarization, intelligent Q&A, chatbots, machine translation, knowledge graphs, recommendation systems, computational advertising, recruitment information, and sharing job-seeking experiences. Welcome to follow! To join the technical exchange group, please add the AINLP assistant WeChat (id: ainlp2), noting your work/research direction + purpose for joining the group.
After reading this, please share, like, or give a thumbs up 🙏