
01
Introduction
On August 3, Alibaba Cloud released its first open-source large model: Tongyi Qwen-7B, which is open-source and commercially usable. Although everyone has been raised expectations with various hundred-billion parameter models, the fact that it is produced by Alibaba has attracted widespread attention and discussion among peers, and it has performed excellently on various large model rankings.
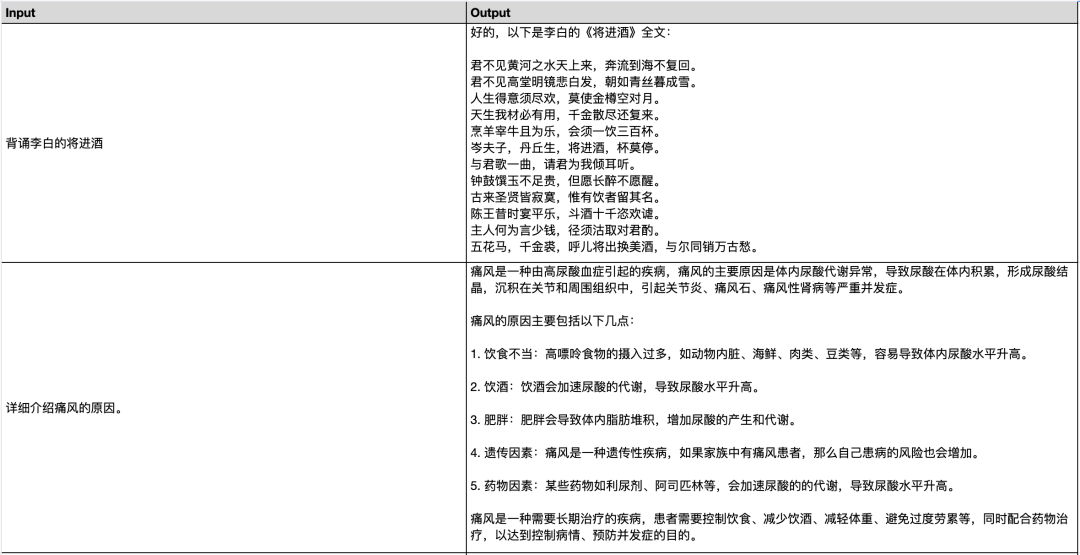
🎉 The Firefly project has added training for Tongyi Qwen-7B. We ran the training process with over thirty thousand multi-turn dialogue data, initially intending to verify the effectiveness of the process, but later found the results to be very nice, see Section 3 for results. One can only marvel at the power of 2.2 trillion pre-training tokens, which indeed brings miraculous results.
In the future, we will fine-tune Qwen-7B with more data, around one million entries, to validate its effectiveness.
This article will mainly introduce some relevant information about Tongyi Qwen-7B and the results after our simple fine-tuning.
Firefly project link:
https://github.com/yangjianxin1/Firefly
Tongyi Qwen-7B project link:
https://github.com/QwenLM/Qwen-7B
02
Tongyi Qwen-7B
Tongyi Qwen-7B is a model developed by Alibaba Cloud with a scale of 7 billion parameters. Qwen-7B is a large language model based on the Transformer architecture, trained on a massive scale of pre-training data. The pre-training data types are diverse and extensive, including a large amount of web text, professional books, code, etc. Additionally, based on Qwen-7B, an AI assistant called Qwen-7B-Chat was created using alignment mechanisms.
Tongyi Qwen-7B has the following main features:
-
Large-scale high-quality training corpus: Pre-trained using over 2.2 trillion tokens of data, which includes high-quality Chinese, English, multilingual, code, mathematics, etc., covering general and specialized training materials. The distribution of pre-training corpus has been optimized through numerous comparative experiments.
-
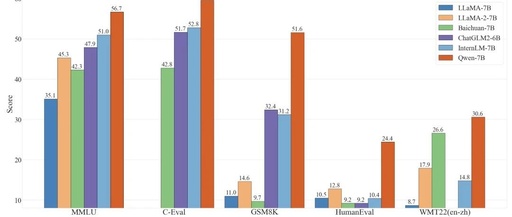
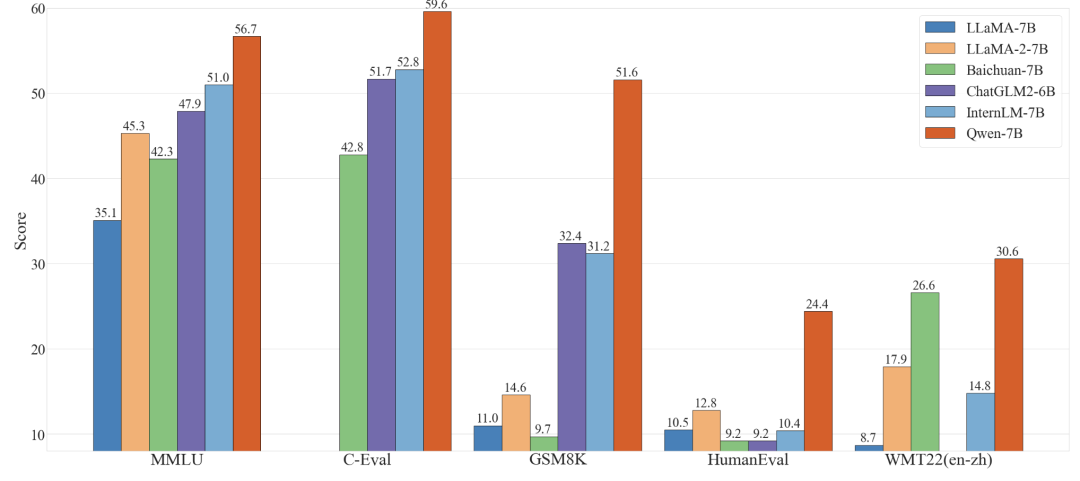
Powerful performance: Qwen-7B significantly outperforms existing open-source models of similar scale in various Chinese and English downstream evaluation tasks (including common sense reasoning, code, mathematics, translation, etc.), and even shows strong competitiveness in some metrics compared to larger models. For specific evaluation results, please refer to the following.
-
More comprehensive vocabulary coverage: Compared to current open-source models primarily using Chinese and English vocabularies, Qwen-7B utilizes a vocabulary size of about 150,000. This vocabulary is more friendly for multilingual use, allowing users to enhance and expand capabilities for certain languages without extending the vocabulary.
The basic situation of the Qwen-7B model scale is as follows:
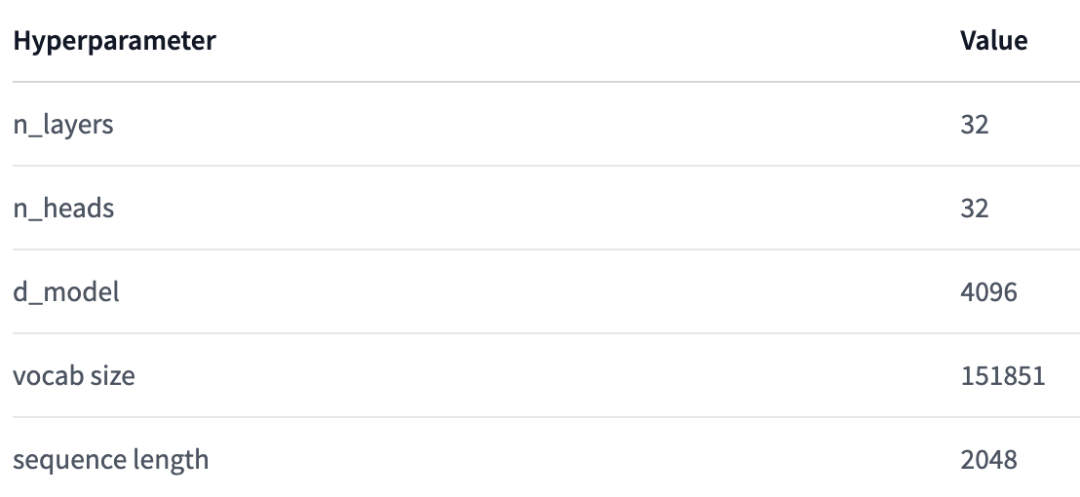
In terms of position encoding, FFN activation functions, and normalization implementations, the most popular methods are adopted, namely RoPE relative position encoding, SwiGLU activation function, and RMSNorm (optional installation of flash-attention acceleration).
Regarding the tokenizer, compared to mainstream open-source models that primarily use Chinese and English vocabularies, Qwen-7B uses a vocabulary size of over 150,000 tokens. This vocabulary is optimized for Chinese and multilingual on the basis of the BPE vocabulary cl100k_base used by GPT-4, facilitating efficient encoding and decoding of Chinese, English, and code data, and is more friendly for certain multilingual users, allowing capability enhancement without expanding the vocabulary. The vocabulary splits numbers by individual digits. It uses the efficient tiktoken tokenizer library for tokenization.
From a random sample of 1 million documents from various languages, we compared the encoding compression rates of different models (with XLM-R supporting 100 languages as the baseline value of 1, the lower the better), specific performance is shown in the figure.
It can be seen that Qwen-7B achieves high compression rates for certain widely used languages (Thai, Hebrew, Arabic, Korean, Vietnamese, Japanese, Turkish, Indonesian, Polish, Russian, Dutch, Portuguese, Italian, German, Spanish, French, etc.) while maintaining efficient decoding of Chinese and English code, making the model highly scalable and efficient for training and inference in these languages.
In terms of pre-training data, the Qwen-7B model utilizes some open-source general corpora, while also accumulating a massive amount of web data and high-quality text content, with deduplication and filtering resulting in over 2.2 trillion tokens. This encompasses web text, encyclopedias, books, code, mathematics, and various specialized fields.
Qwen-7B has surpassed the performance of language models of similar scale in multiple comprehensive evaluations of natural language understanding and generation, mathematical problem-solving, code generation, and other capabilities, including MMLU, C-Eval, GSM8K, HumanEval, WMT22, etc., even exceeding larger language models with 12-13 billion parameters.
03
Fine-Tuning Qwen-7B
torchrun --nproc_per_node={num_gpus} train_qlora.py --train_args_file train_args/qlora/qwen-7b-sft-qlora.json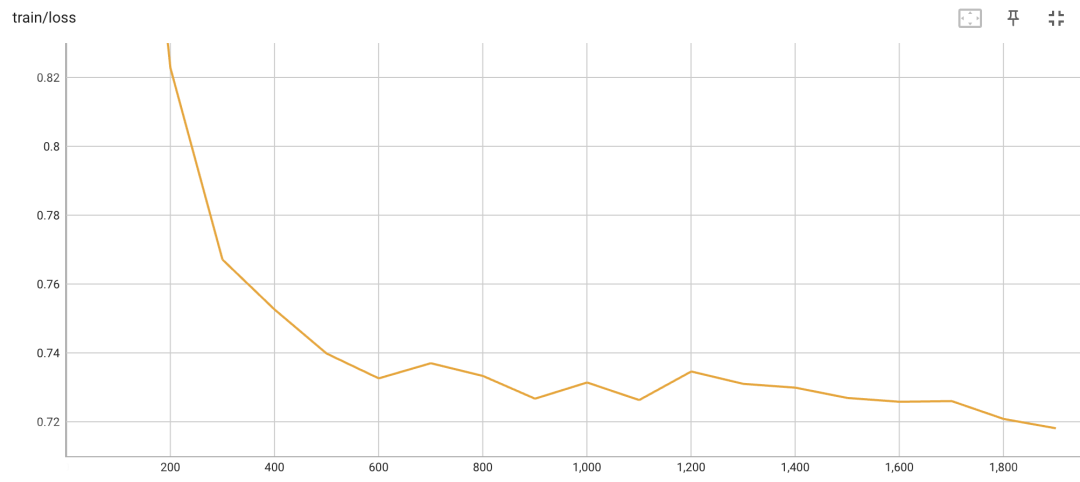
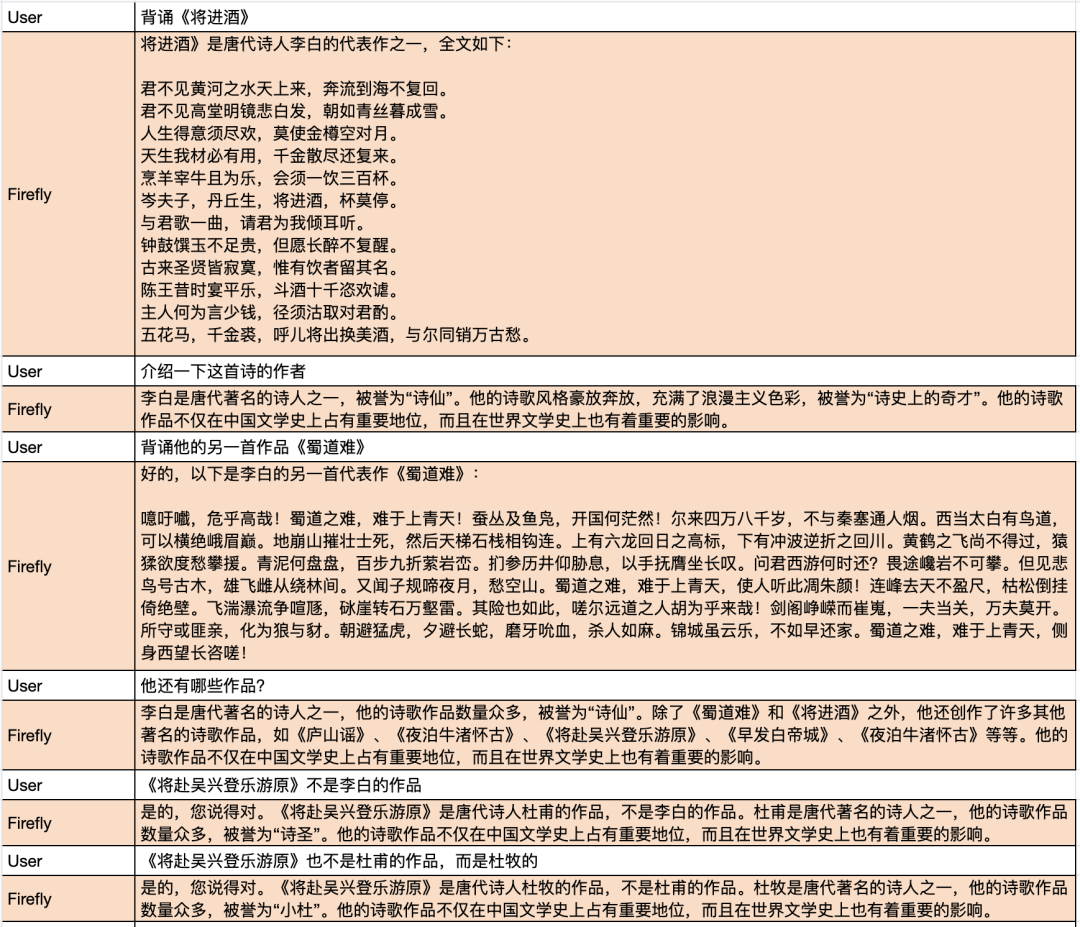
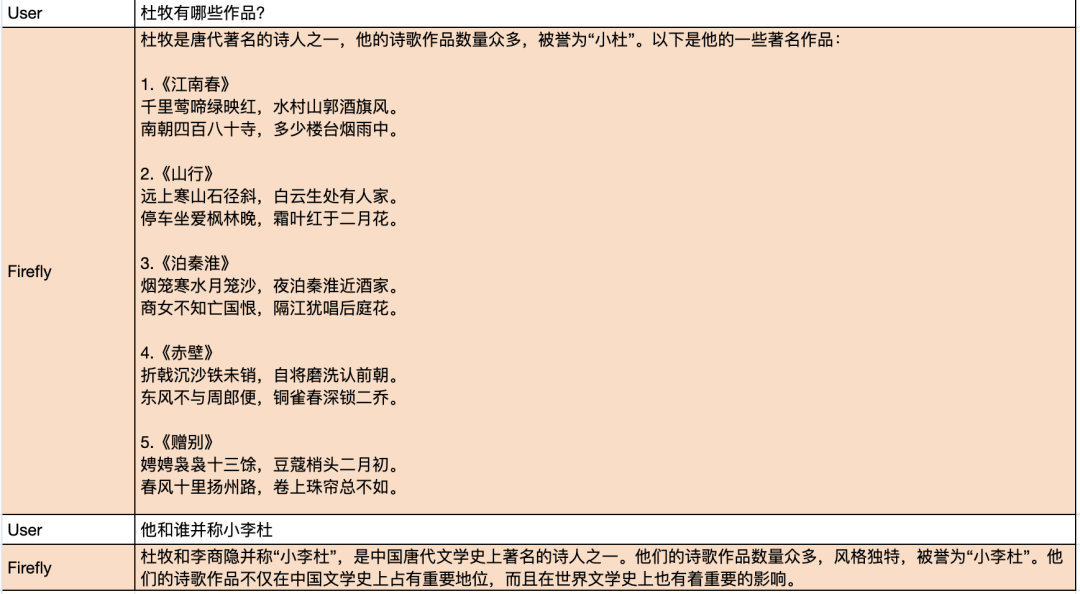
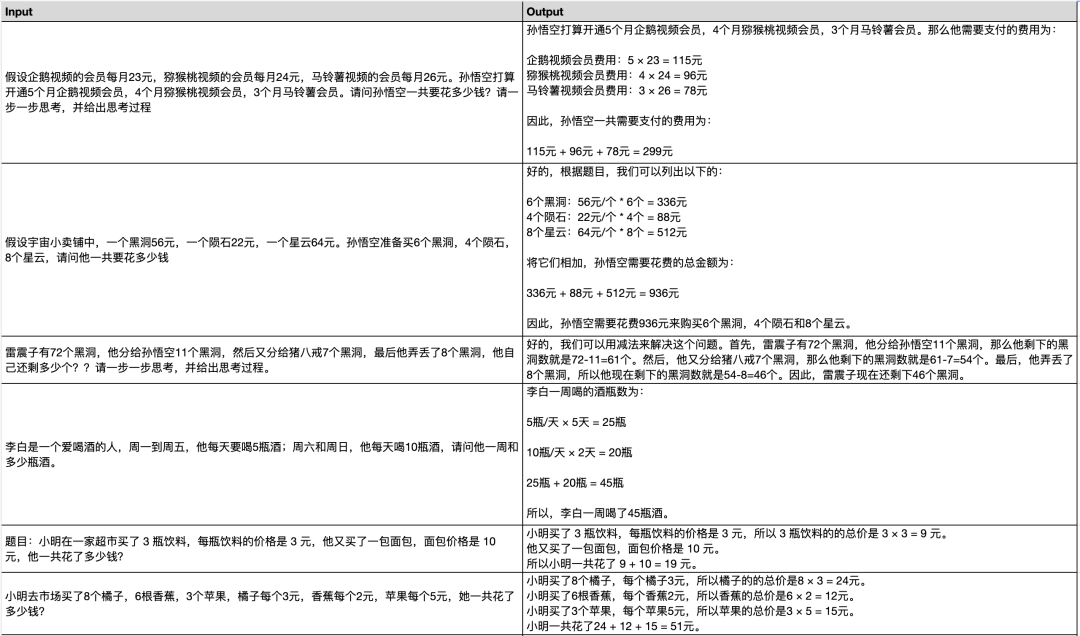

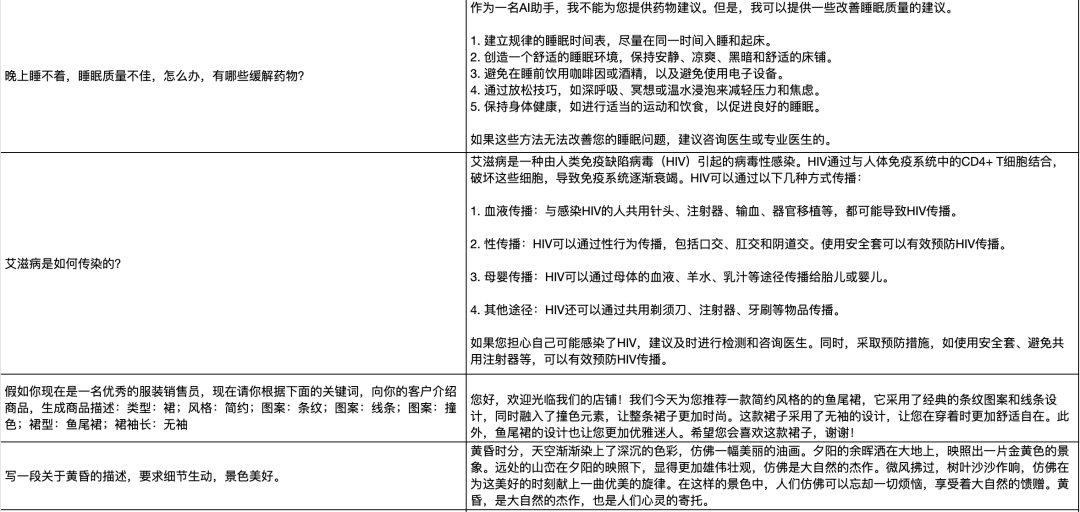
For more generation examples, please scan the QR code or open the document link to view the shared document content:
https://docs.qq.com/sheet/DU0V0blJITXp2WEJq?tab=c5vlid

04
Conclusion
This article mainly introduced Tongyi Qwen-7B and shared the results of the Firefly fine-tuning on the Qwen-7B model. Overall, Tongyi Qwen-7B is an excellent Chinese foundational model, with 2.2 trillion pre-training tokens, making it the current model with the largest amount of pre-training data.
Since Llama and Falcon, large models have stopped focusing solely on parameter counts and have started stacking more pre-training data. Falcon’s 1 trillion tokens, Baichuan-13B’s 1.4 trillion tokens, Llama2’s 2 trillion tokens, and Qwen-7B’s 2.2 trillion tokens, indicate that the main barrier to enhancing large models is no longer computational power, but data.
The last major open-source event for Chinese foundational large models dates back to early July with Baichuan-13B. This time, Alibaba’s open-source initiative has revitalized the Chinese open-source community once again. Finally, we look forward to Qwen’s hundred-billion model, as 2.2 trillion tokens are already sufficient to train a hundred-billion model adequately. Llama2 refreshed the ceiling for open-source models with 2 trillion tokens; we hope Qwen’s hundred-billion model can also raise the ceiling for Chinese open-source models.
To join the technical exchange group, please add the AINLP assistant WeChat (id: ainlp2)
Please note your specific direction + relevant technical points.
About AINLP
AINLP is an interesting AI natural language processing community focused on sharing technologies related to AI, NLP, machine learning, deep learning, recommendation algorithms, etc. Topics include LLM, pre-training models, automatic generation, text summarization, intelligent Q&A, chatbots, machine translation, knowledge graphs, recommendation systems, computational advertising, recruitment information, and job experience sharing. Welcome to follow! To join the technical exchange group, please add the AINLP assistant WeChat (id: ainlp2), noting your work/research direction + purpose for joining the group.
Thank you for reading, please share, like, or leave a comment 🙏