
TL;DR
What this article did
-
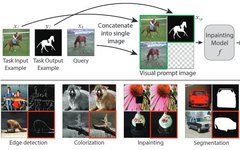
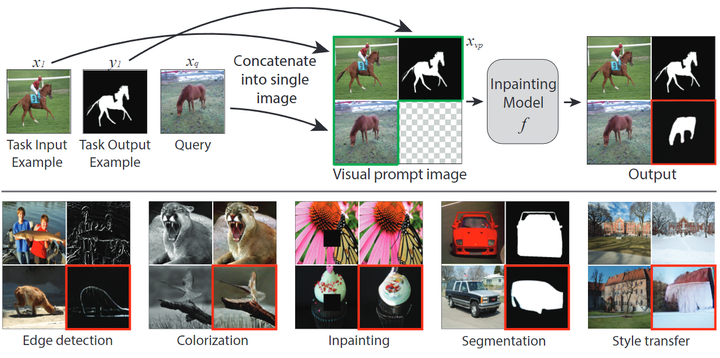
Proved that many computer vision tasks can be treated as image inpainting tasks, requiring only a few task input and output examples and a query image. -
Constructed a large dataset containing 88,000 samples, allowing the model to learn the image inpainting task without any annotation information or task-related descriptions. -
Demonstrated that adding additional data (such as ImageNet) to the training dataset can yield better results.
Paper Title: Visual Prompting via Image Inpainting (NeurIPS 2022) Translation: Completing Visual Prompts through Image Inpainting
Can the characteristics of a general model performing various downstream tasks in language models be transferred to the visual domain?
Je suis désolé I’m sorryJ’adore la glace
I love ice cream
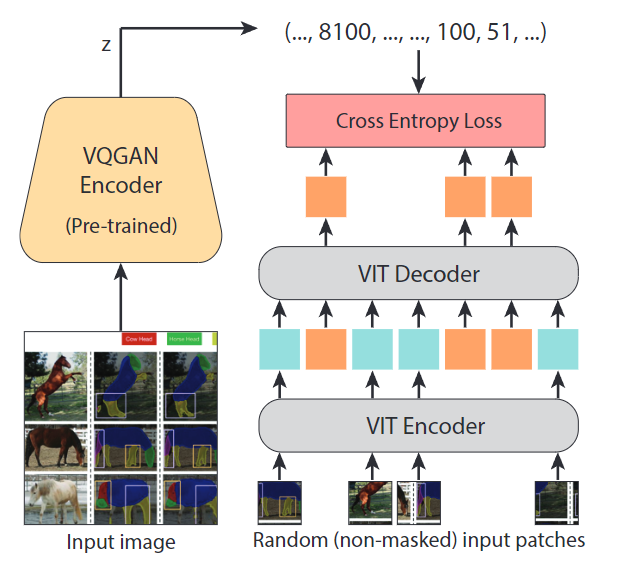
MAE-VQGAN Method Introduction

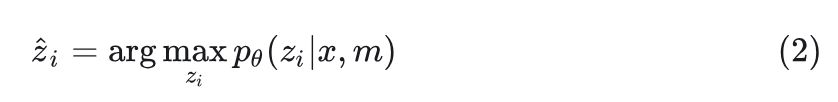
Adding Prompts to the Trained Image Inpainting Model

Design of Visual Prompts
Dataset
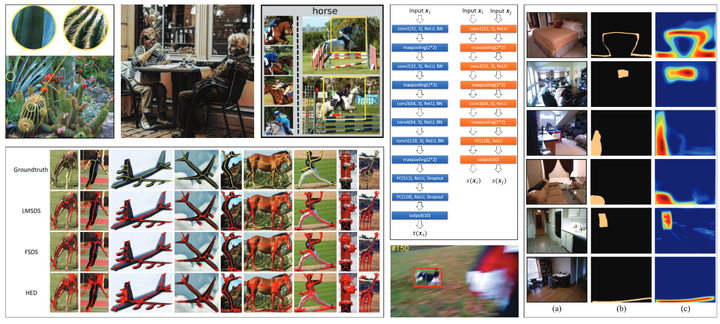
Experimental Results
Downstream Task Experimental Results


Synthetic Data Study
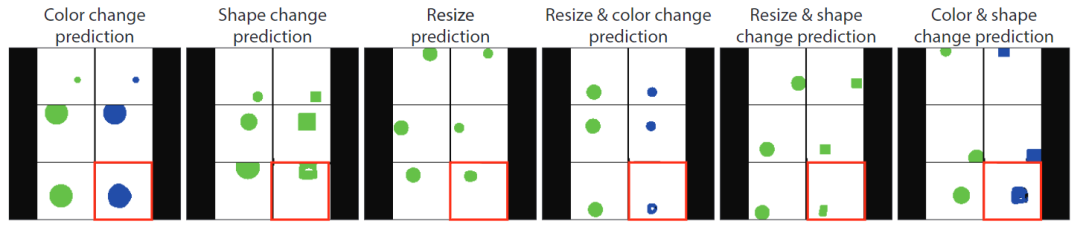
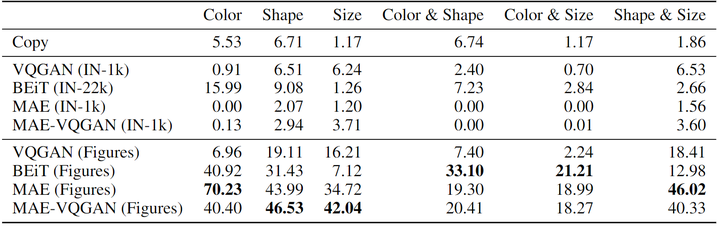
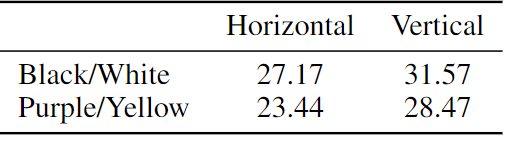
Impact of Dataset Size
Visual Prompt Engineering

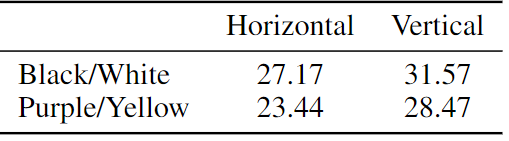
-
^Masked Autoencoders Are Scalable Vision Learners -
^Taming Transformers for High-Resolution Image Synthesis
Technical Exchange Group Invitation

△Long press to add assistant
Scan the QR code to add the assistant WeChat
Please note: Name-School/Company-Research Direction
(For example: Xiao Zhang-Harbin Institute of Technology-Dialogue System)
to apply to join Natural Language Processing/Pytorch and other technical exchange groups
Scan the QR code to add the assistant WeChat
About Us
MLNLP community is a grassroots academic community jointly constructed by scholars in machine learning and natural language processing from home and abroad. It has developed into a well-known community for machine learning and natural language processing in China and abroad, aiming to promote progress between the academic and industrial circles of machine learning and natural language processing and enthusiasts.
The community can provide an open exchange platform for the further education, employment, and research of relevant practitioners. Everyone is welcome to follow and join us.
