This article is published in: Chinese Journal of Internal Medicine, 2022, 61(2): 185-192.
Authors: Wang Kai, Yang Junjie, Liu Ziwan, Dou Guanhua, Wang Xi, Shan Dongkai, Chen Yundai

Objective
To develop a pretest probability model for obstructive coronary artery disease in the Chinese population using machine learning algorithms.
Methods
This study included 29,455 patients suspected of coronary artery disease who underwent coronary CT angiography (CCTA) as part of the Clinical Registry for Early Detection and Risk Stratification of Coronary Plaques (C-Strat). Demographic and clinical information were collected as predictive variables. Data were randomly split into training and testing sets in a 7:3 ratio, using CCTA to diagnose coronary stenosis greater than 50% as the positive outcome. The Extreme Gradient Boosting (XGBoost) algorithm was applied in the training set, with ten-fold cross-validation and Bayesian optimization for parameter tuning, resulting in the machine learning model CARDIACS (pretest probability model from Chinese registry in eARly Detection and rIsk stratificAtion of Coronary plaques Study); logistic regression was used to obtain the LOGISTIC model. The performance of CARDIACS, LOGISTIC, and guideline-recommended models UDFM (Updated Diamond-Forrester Model) and DFCASS (Diamond-Forrester and CASS) was compared in the testing set.
Results
The average age of the 29,455 patients was (57.0±9.7) years, with 44.8% being female. The prevalence of obstructive coronary artery disease was 19.1% (5,622/29,455). In the CARDIACS model, the reasons for consultation, age, and body mass index were the most important predictive variables. In an independent testing set, the area under the curve (AUC) for CARDIACS was 0.72 (95% CI 0.70-0.73), outperforming LOGISTIC (AUC 0.69, 95% CI 0.68-0.71, P=0.015), UDFM (AUC 0.64, 95% CI 0.62-0.65, P<0.001), and DFCASS (AUC 0.66, 95% CI 0.64-0.67, P<0.001).
Conclusion
The novel pretest probability model CARDIACS developed for the Chinese population significantly outperforms traditional models in predicting obstructive coronary artery disease, providing valuable assistance in clinical decision-making for stable chest pain.
Research has demonstrated that coronary computed tomographic angiography (CCTA) has good diagnostic accuracy for obstructive coronary artery disease (CAD), particularly with a negative predictive value exceeding 90%, making it a “gatekeeper” for invasive coronary angiography.[1, 2, 3] Studies have shown that the prevalence of obstructive CAD in populations undergoing CCTA can be as low as 10.3%, indicating the continued phenomenon of over-testing.[4] Guidelines recommend calculating the pretest probability for patients suspected of CAD to screen out those with low pretest probability from further testing, while those with moderate pretest probability should undergo non-invasive tests such as CCTA. Thus, the pretest probability model appears to also serve as a “gatekeeper” for CCTA. Guidelines from the US and China recommend the use of DFCASS and UDFM, respectively.[5, 6] Recent studies have shown that the diagnostic accuracy of guideline-recommended models has declined to varying degrees in different populations, with these models significantly overestimating pretest probabilities for other populations.[7, 8] These models have not been effectively validated in the Chinese population, and we lack a pretest probability model based on multicenter data from the Chinese population. This study aims to construct a new pretest probability model for CAD using machine learning algorithms and logistic regression methods in the Chinese population, and compare it with the aforementioned guideline-recommended models.
1. Study Subjects
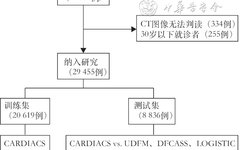
The population of this study comes from the Clinical Registry for Early Detection and Risk Stratification of Coronary Plaques (C-Strat; Clinical Trial Registration Number: ChiCTR1800015864), a prospective, multicenter cohort study.[9] This study enrolled patients suspected of CAD who presented with chest pain or abnormal results from electrocardiograms or echocardiograms and underwent CT coronary assessment with more than 64 slices, excluding those with a clear history of CAD. As shown in Figure 1, we excluded patients who could not be interpreted due to poor CT image quality and those under 30 years old, collecting data from 29,455 patients. The Medical Ethics Committee of the PLA General Hospital approved this study (Approval Number: S2018-033-01), and all patients signed informed consent for the study.
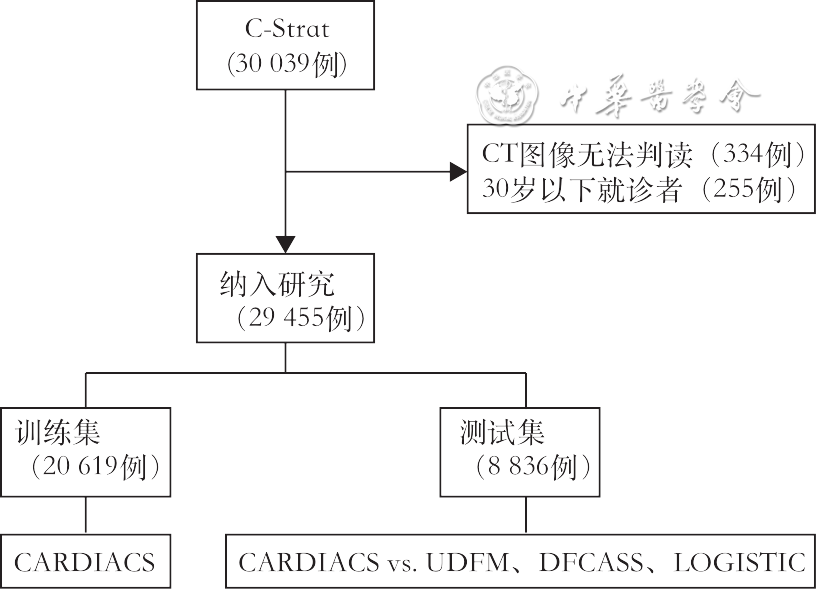
Figure 1 Flowchart of patient inclusion and model construction evaluation
2. Data Collection and Variable Definitions
Before undergoing CCTA, demographic and clinical information of the study subjects were prospectively collected, including gender, age, reasons for consultation, height, and weight [to calculate body mass index (BMI)], diabetes, hypertension, dyslipidemia, history of stroke, peripheral vascular disease, smoking status, and alcohol consumption. Imaging information was obtained after CCTA. The reason for consultation was defined as typical angina, atypical angina, non-cardiac chest pain, or other reasons. Typical angina is characterized by the following three features: (1) induced by exertion, physical activity, or emotional stress; (2) located behind the sternum or in the precordial area; (3) relieved within minutes by rest or sublingual nitroglycerin. Atypical angina meets two of the three criteria above; non-cardiac chest pain meets one or none of the three criteria; other reasons refer to asymptomatic patients with abnormal electrocardiogram or echocardiogram results. Diabetes is defined as fasting blood glucose ≥7.0 mmol/L (126 mg/dl), random blood glucose ≥11.1 mmol/L (200 mg/dl), or currently receiving hypoglycemic medication. Hypertension is defined as blood pressure >140/90 mmHg (1 mmHg=0.133 kPa) or currently taking antihypertensive medication. Dyslipidemia is defined as total cholesterol (TC) ≥5.18 mmol/L (220 mg/dl), low-density lipoprotein cholesterol (LDL-C) ≥3.4 mmol/L (130 mg/dl), triglycerides (TG) ≥1.7 mmol/L (150 mg/dl), high-density lipoprotein cholesterol (HDL-C) <1.04 mmol/L (40 mg/dl), or currently taking lipid-lowering medication. Smoking history is categorized into four levels at the time of CCTA: never smoked, former smoker, occasional smoker, and regular smoker. Alcohol history is also categorized into four levels at the time of CCTA: never drank, former drinker, occasional drinker, and regular drinker. Obstructive coronary artery disease is defined as a CCTA result showing stenosis ≥50% in the left main coronary artery, anterior descending artery, circumflex artery, or right coronary artery.
3. Modeling and Prediction
As shown in the flowchart (Figure 1), the dataset was randomly split into a training set (70%) and a testing set (30%) using the createDataPartition function from the caret package. In the training set, the outcome was whether obstructive coronary artery disease was present, with all 11 demographic and clinical characteristics as predictive variables. The Extreme Gradient Boosting (XGBoost) algorithm was used to select the optimal model hyperparameters (such as the number of trees, maximum tree depth, learning rate, etc.) through ten-fold cross-validation and Bayesian optimization, resulting in the machine learning model named CARDIACS (pretest probability model from Chinese registry in eARly Detection and rIsk stratificAtion of Coronary plaques Study). Logistic regression modeling was also performed to obtain the generalized linear regression model LOGISTIC.
In the testing set, CARDIACS was independently validated and compared with LOGISTIC, UDFM, and DFCASS, evaluating the performance of the four models in predicting the likelihood of patients developing obstructive coronary artery disease. UDFM and DFCASS are pretest probability models based on three predictive variables: type of chest pain, age, and gender.
4. Statistical Analysis
Continuous variables are expressed as mean ± standard deviation, and categorical variables are expressed as absolute values and proportions. The χ² test was used to compare categorical variables, and the CMH χ² test was used for ordinal variable comparisons. During data preprocessing, we assumed that missing clinical variables occurred randomly, and used the random forest method in the mice package to perform multiple imputation, randomly returning one result as the complete dataset. For machine learning model construction, the xgboost package’s xgb.cv function and the rBayesianOptimization package’s BayesianOptimization function were used for model training with ten-fold cross-validation and Bayesian optimization for parameter tuning (Figure 2). In the testing set, the area under the receiver operating characteristic (ROC) curve (AUCROC) was used to assess the model’s discrimination, while calibration curves, calibration slope, and Brier score were used to evaluate the model’s calibration. The calibration slope was obtained by fitting a linear regression equation of the predicted probabilities of positive outcomes against the actual incidence; the closer this value is to 1, the better the model’s calibration. The Brier score measures the difference between the predicted probabilities of positive outcomes and the actual incidence, with values closer to 0 indicating better model calibration. P<0.05 was considered statistically significant. All statistical analyses were performed in R 4.0.2.

Figure 2 Schematic diagram of the construction process for the machine learning model (CARDIACS)
1. Clinical Information and Imaging Examination Results (Table 1)
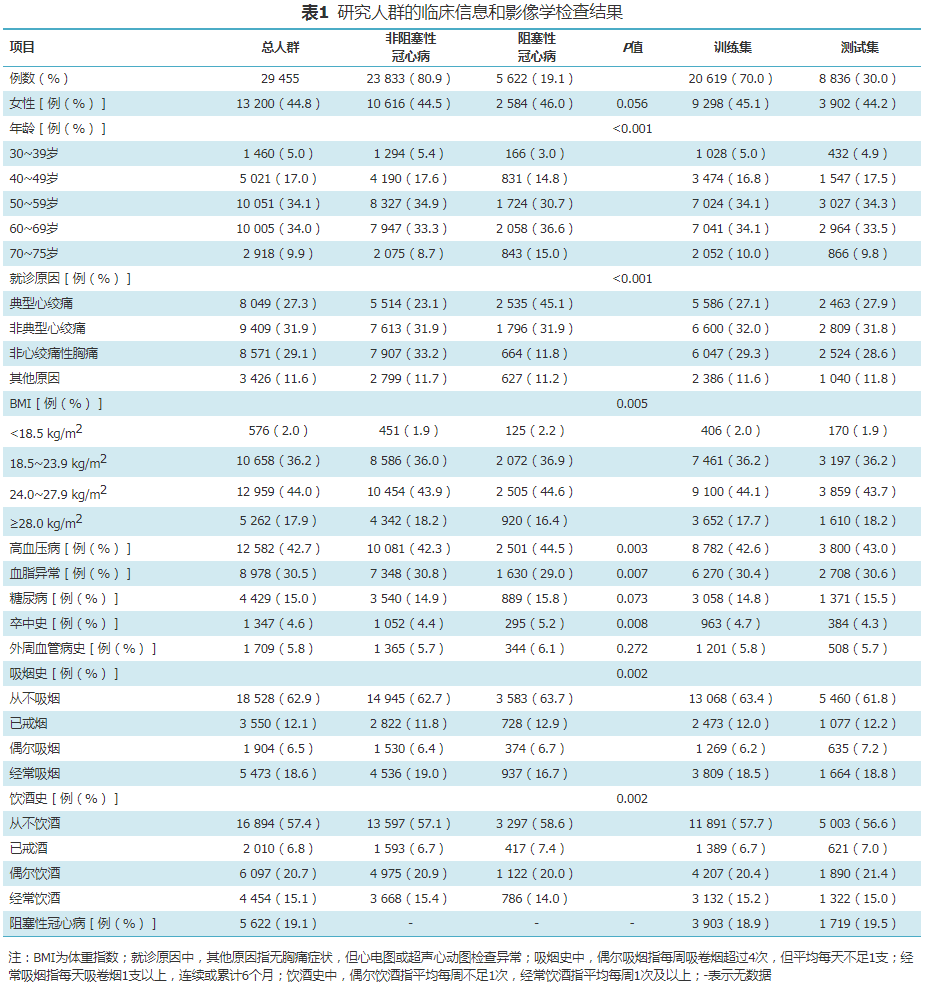
A total of 29,455 patients were included in the analysis, with an average age of (57.0±9.7) years, and 44.8% were female. The prevalence of obstructive coronary artery disease in the study population was 19.1% (5,622/29,455). 88.4% of patients presented with chest pain, 27.3% had typical angina, 31.9% had atypical angina, 29.1% had non-cardiac chest pain, and the remaining 11.6% were asymptomatic but presented due to abnormal electrocardiogram or echocardiogram results. The prevalence of diabetes, dyslipidemia, and hypertension was 15.0%, 30.5%, and 42.7%, respectively, with a smoking history present in 37.1% and an alcohol history in 42.6%.
2. Model Prediction Results
A total of 20,619 patients (70%) were included in the training set, and the optimal hyperparameters for the CARDIACS model were determined through ten-fold cross-validation and Bayesian optimization: number of trees nrounds=323, maximum tree depth max_depth=4, learning rate eta=0.0382, sample resampling ratio subsample=1, minimum loss split gamma=0.2, minimum child weight min_child_weight=1, feature random sampling ratio colsample_bytree=0.5, and maximum delta step max_delta_step=10. Figure 3 shows the importance ranking of predictive variables in the CARDIACS model, indicating that age, reason for consultation, and BMI are the three most important variables for predicting obstructive coronary artery disease. The odds ratios (OR), 95% CI, and P-values for each variable in the LOGISTIC model were also obtained (Table 2).
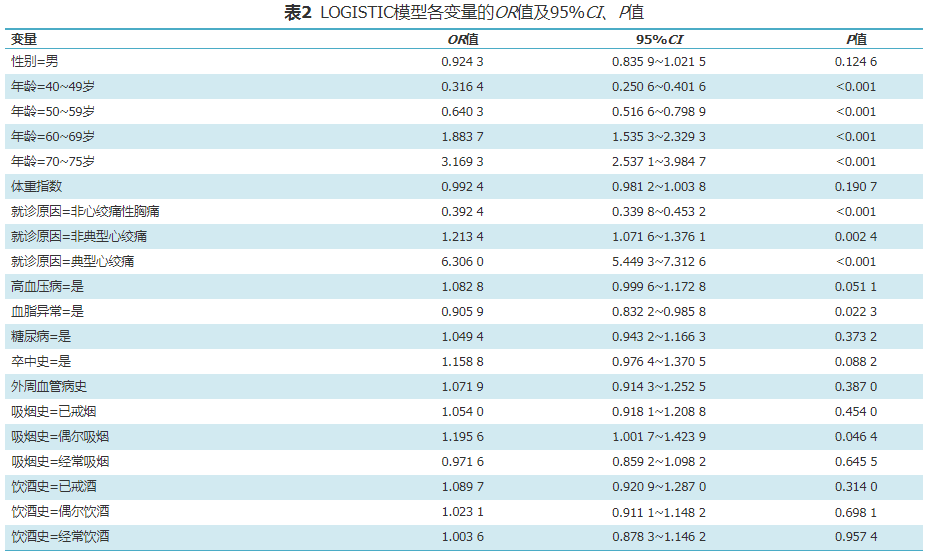
Figure 3 Variable importance ranking chart for CARDIACS
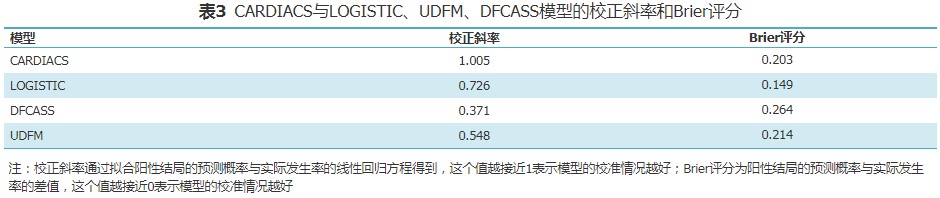
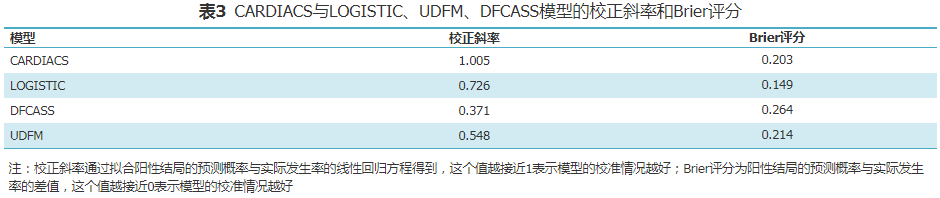
A total of 8,836 patients (30%) were included in the testing set, and independent validation was conducted for CARDIACS against LOGISTIC, UDFM, and DFCASS. CARDIACS exhibited the best discrimination (Figure 4), with an AUC of 0.72 (95% CI 0.70-0.73), compared to LOGISTIC (AUC 0.69, 95% CI 0.68-0.71, P=0.015), DFCASS (AUC 0.66, 95% CI 0.64-0.67, P<0.001), and UDFM (AUC 0.64, 95% CI 0.62-0.65, P<0.001). In terms of calibration, CARDIACS also performed the best (Figure 5 and Table 3), while LOGISTIC (calibration slope 0.726, Brier score 0.15), DFCASS (calibration slope 0.371, Brier score 0.26), and UDFM (calibration slope 0.548, Brier score 0.21) showed poor calibration, with CARDIACS achieving a calibration slope of 1.005 and a Brier score of 0.20.
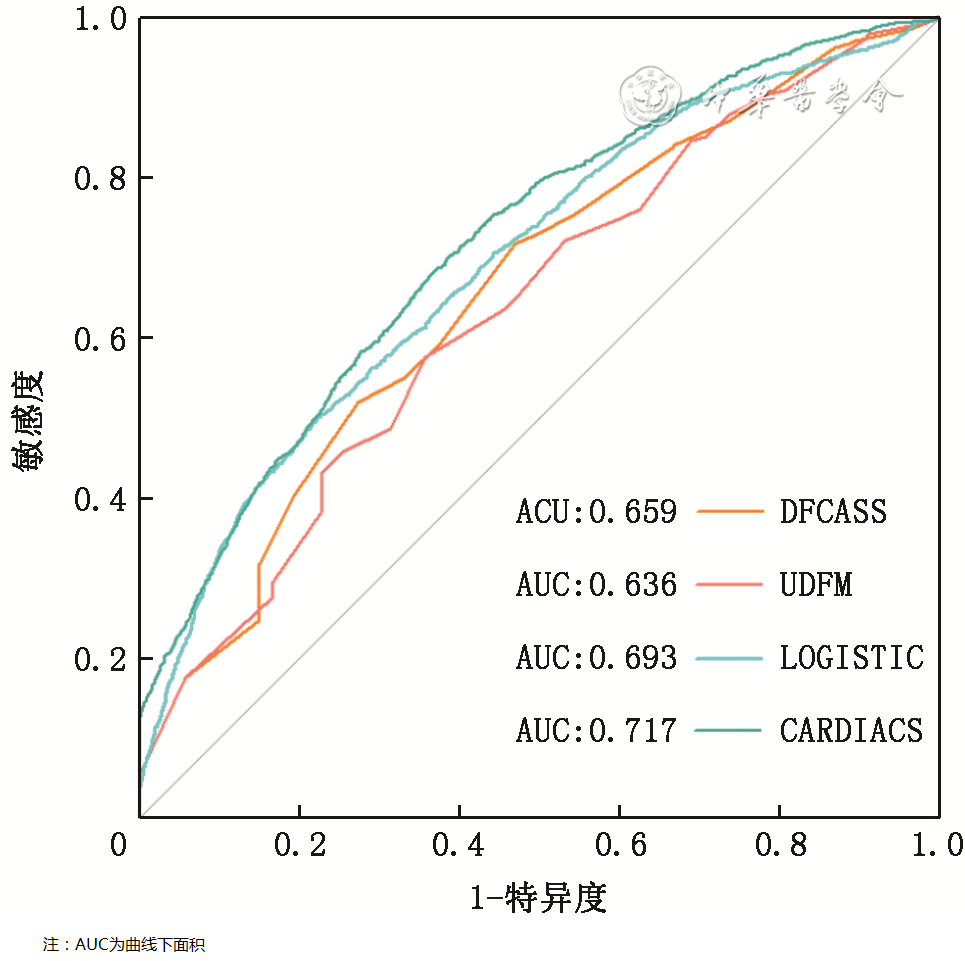
Figure 4 ROC curves for CARDIACS, LOGISTIC, UDFM, and DFCASS models in the testing set
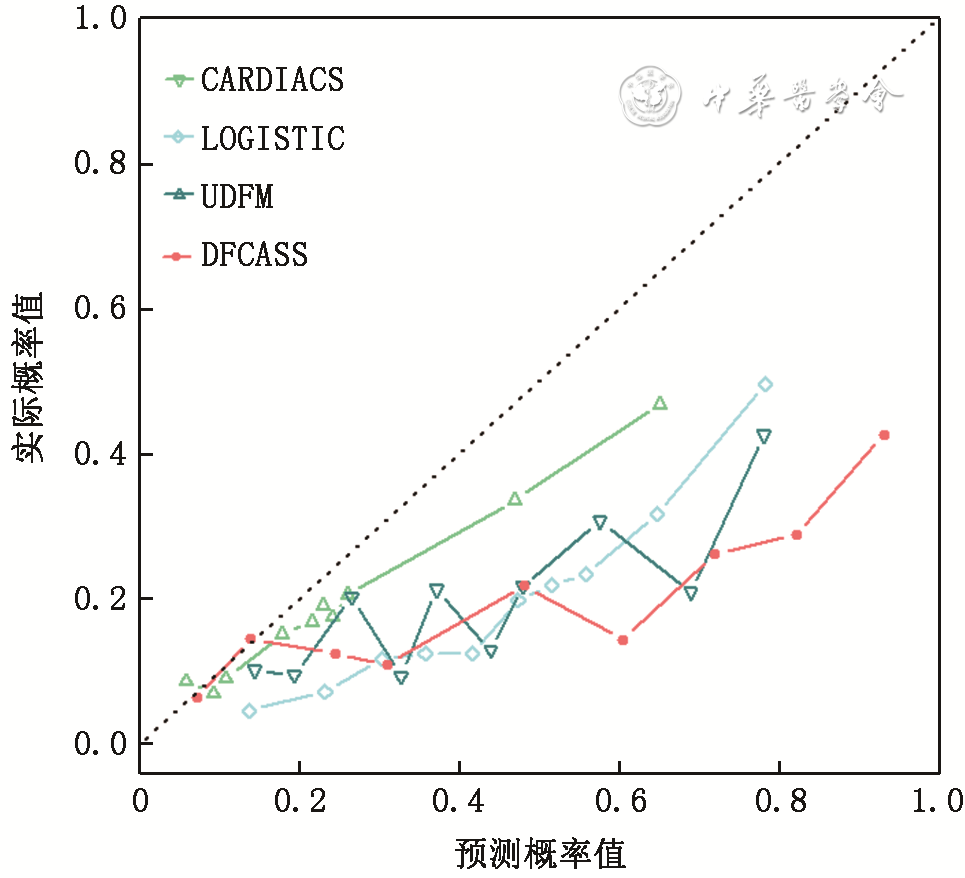
Figure 5 Calibration curves for CARDIACS, LOGISTIC, UDFM, and DFCASS models in the testing set
The latest international chest pain guidelines recommend using more advanced pretest probability models for clinical decision-making in patients suspected of CAD, bringing renewed attention to the concept of pretest probability models.
In 1979, Diamond and Forrester established the Diamond-Forrester Model (DFM) based on gender, age, and type of chest pain in the US population, marking a milestone in this field.[10] In 1981, this model was externally validated in the Coronary Artery Surgery Study (CASS) data, and in 2012, the American Heart Association (AHA)/American College of Cardiology (ACC) guidelines summarized the data from the two studies to obtain the DFCASS model.[5, 11] In 2011, Genders et al. validated and updated the DFM in clinical data from the CAD Consortium, which consisted of European and American populations, resulting in the UDFM. This study is the first to develop and validate a novel pretest probability model for obstructive CAD, CARDIACS, in a multicenter Chinese population. Validation and comparison conducted in an independent testing set indicate that the traditional generalized linear regression model LOGISTIC and the guideline-recommended UDFM and DFCASS models perform poorly in predicting obstructive CAD in the Chinese population. In contrast, the CARDIACS model based on machine learning algorithms shows superior performance, significantly improving disease prediction accuracy and calibration.
This study included 29,455 patients presenting with chest pain who underwent CCTA as part of the C-Strat study, with a prevalence of obstructive CAD at 19.1%. The original study populations of the UDFM and DFCASS models consisted of patients undergoing coronary angiography or autopsy, with a prevalence of obstructive CAD around 60%, indicating that the prevalence in our study population is significantly lower than the previous two, which may explain the poor predictive performance of the two models in our population and their significant overestimation of disease probability. Recent studies have also shown that previously proposed models exhibit varying degrees of decline in predictive performance for obstructive CAD when externally validated in new populations.[7, 13]
This study found that the reasons for consultation, age, and BMI are the three most important features in the CARDIACS model for predicting obstructive CAD. The importance of age and type of chest pain in pretest probability models has been further confirmed, but the significance of BMI as a variable has not been emphasized in earlier studies. This finding aligns with recent international multicenter studies that included populations from North America, East Asia, Europe, and India, which utilized the XGBoost algorithm and five-fold cross-validation to construct predictive models, discovering that BMI, age, and moderate to severe angina were the three most important features for predicting obstructive CAD.[14] As societal changes in diet, environmental exposure, and disease prevention measures occur, the characteristics of populations continue to evolve, necessitating a timely update of predictive models in clinical practice. Recent studies have increasingly identified a significant correlation between obesity and CAD,[15, 16] suggesting that future models should consider including BMI as a predictive variable.
Extreme Gradient Boosting (XGBoost) is an ensemble algorithm based on boosting techniques, classified as a machine learning algorithm. Previous studies for predictive model construction have mostly relied on traditional generalized linear regression, such as logistic regression, which has strong interpretability. However, when faced with large data volumes and high-dimensional data, these methods may struggle and lead to model underfitting. This study developed a novel pretest probability model for obstructive CAD, CARDIACS, using the more flexible XGBoost technique, with independent testing suggesting good performance. In recent years, the application of machine learning algorithms, particularly ensemble algorithms represented by AdaBoost, LightGBM, and XGBoost, has provided stronger support for clinical decision-making.[17, 18, 19]
Pretest probability models based on demographic and clinical information are recommended by guidelines as “gatekeepers” for non-invasive tests like CCTA, helping assess the risk of patients developing diseases and guiding clinical decision-making. In developing countries like China, where the number of patients with coronary artery disease is high but healthcare resources are relatively scarce, it is essential to effectively utilize pretest probability tools to exclude negative patients from undergoing CCTA, thereby creating more opportunities for disease assessment for those with a higher likelihood of positive outcomes, saving healthcare resources and optimizing medical cost allocation. Several studies have established updated models, including some conducted in the Chinese population, but some are single-center studies, limiting their representativeness.[20] Others incorporate indicators obtained through CT scans, such as coronary artery calcification scores, significantly enhancing their performance, but these models are not strictly pretest probability models since their assessment relies on imaging studies.[21] In contrast, our CARDIACS pretest probability model is derived from a multicenter study cohort, well representing the Chinese population, and can achieve good predictions of disease probability based solely on demographic and clinical variables using machine learning methods. Additionally, the predictive variables required for the CARDIACS model can be collected in outpatient settings and online, potentially greatly facilitating the clinical experience of patients with suspected chest pain, promoting the implementation of guideline-recommended diagnostic pathways, and aiding in the optimization of healthcare resource allocation.
This study has some limitations. First, there are some missing values in the data, primarily in variables such as age, BMI, alcohol consumption, and smoking status; however, their missing proportions are all below 5%, and we used multiple imputation methods to fill in the missing values, which may make them closer to the true values. Second, the “dyslipidemia” variable in our study does not explicitly distinguish between high LDL-C and low HDL-C, which may limit the model’s performance; however, the data in this study comes from the C-Strat multicenter cohort study, with definitions of risk factors based on international authoritative consensus and guidelines, and other pretest probability models commonly use the dyslipidemia variable for clinical use. Third, the model constructed in this study has not been validated in independent cohorts; however, validation was performed in the randomly split testing set. This study further confirms that machine learning algorithms can bring better predictive performance to models, but their online deployment is challenging, requiring further research for implementation.
In summary, we developed a model CARDIACS for predicting obstructive coronary artery disease based on machine learning algorithms in the Chinese population, which demonstrates higher predictive efficacy compared to traditional models, and is expected to assist in clinical decision-making for chest pain patients.
References (omitted)




