
Click the above “Beginner’s Guide to Vision” to select and add a Bookmark or “Pin”
Heavyweight content delivered first-hand
This article introduces the last powerful engineering implementation model in the GBDT series—CatBoost. CatBoost is one of the three mainstream models under the GBDT framework, alongside XGBoost and LightGBM. CatBoost, open-sourced by the Russian search giant Yandex in 2017, is named for its ability to efficiently handle categorical features in data (Categorical + Boosting). Compared to XGBoost and LightGBM, the main innovations of CatBoost lie in the handling of categorical features and Ordered Boosting.

Handling Categorical Features
Handling categorical features is a significant characteristic of CatBoost, which is also the origin of its name. CatBoost improves upon conventional target variable statistical methods by adding prior terms. Additionally, CatBoost considers using different combinations of categorical features to expand the feature dimensions of the dataset.
General Processing Method
Categorical features are very common in structured datasets. Unlike common numerical features, these are discrete sets, such as gender (male, female), education (bachelor’s, master’s, doctorate, etc.), and location (Hangzhou, Beijing, Shanghai, etc.). Sometimes, we encounter categorical features with dozens or even hundreds of values.
The most common method for handling categorical features has traditionally been one-hot encoding. If the number of unique values for a categorical feature is small, one-hot encoding is quite efficient. However, when the number of unique values is large, one-hot encoding becomes impractical, generating a large number of redundant features. For instance, a categorical feature with 100 unique values would result in 100 sparse features, which is cumbersome for the training algorithm itself.
Thus, for categorical features with many unique values, a compromise method is to reclassify the categories to reduce their number before applying one-hot encoding. Another commonly used method is Target Statistics (TS), which calculates the expected value of the target variable for each category and converts categorical features into new numerical features. CatBoost improves upon the conventional TS method.
Target Variable Statistics
The main design goal of the CatBoost algorithm is to better handle categorical features in GBDT. The most straightforward approach of the conventional TS method is to replace the category with the average value of its corresponding labels. During the decision tree construction process in GBDT, the replacement of the category label with the average value serves as the criterion for node splitting. This approach is known as Greedy Target-based Statistics, abbreviated as Greedy TS, and can be expressed mathematically as:
One obvious flaw of Greedy TS is that when features contain more information than labels, using the average label value to replace categorical features can lead to conditional shift issues due to different data distributions between the training and testing sets. The improvement CatBoost makes to the Greedy TS method is to add prior distribution terms to reduce the impact of noise and low-frequency categorical data on the data distribution. The mathematical expression of the improved Greedy TS method is as follows:
where is the added prior term, and is the weight coefficient greater than.
In addition to the above methods, CatBoost also offers several improved TS methods, such as Holdout TS, Leave-one-out TS, and Ordered TS, which will not be detailed here.
Feature Combination
Another innovation in CatBoost’s handling of categorical features is the ability to construct arbitrary combinations of several categorical features into new features. For example, the joint information between user ID and advertisement theme. If these are simply converted into numerical features, the joint information may be lost. CatBoost considers combining these two categorical features to form a new categorical feature. However, the number of combinations grows exponentially with the number of categorical features in the dataset, making it impractical to consider all combinations.
Thus, when constructing new split nodes, CatBoost employs a greedy strategy to consider combinations between features. CatBoost combines all combinations of categorical features with all categorical features in the dataset and dynamically converts the new categorical combination features into numerical features.
Prediction Shift and Ordered Boosting
Another major innovation of CatBoost is the introduction of Ordered Boosting to address the issue of Prediction Shift.
Prediction Shift
Prediction shift refers to the deviation between the distribution of training samples and the distribution of testing samples.
CatBoost first revealed the prediction shift problem in gradient boosting, asserting that prediction shift, like the TS processing method, is caused by a special feature target leakage and gradient bias. Let’s examine how this prediction shift is transmitted during the gradient boosting process.
Assuming that the strong learner from the previous round of training is , and the current loss function is , then the weak learner to be fitted in this round of iteration is:
The further gradient expression is:
The approximate expression of data is:
The final chain of prediction shift can be described as:
-
The conditional distribution of the gradient and the distribution of the test data are biased; -
The approximate estimate of data and the gradient expression are biased; -
Prediction shift affects the generalization performance of .
Ordered Boosting
CatBoost utilizes the Ordered Boosting method based on Ordered TS to tackle the prediction shift issue. The algorithm flow of Ordered Boosting is shown in the following diagram.

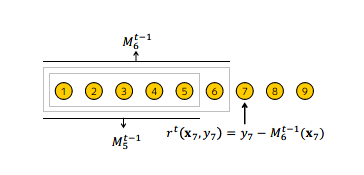
For training data, Ordered Boosting first generates a random permutation, which is used for subsequent model training. That is, when training the th model, the first samples in the permutation are used for training. In the iteration process, to obtain the residual estimate of the th sample, the th model is used for estimation.
However, this method of training models increases memory consumption and time complexity significantly, making it practically unfeasible. Therefore, CatBoost improves on this Ordered Boosting algorithm based on the gradient boosting algorithm with decision trees as base learners.
CatBoost provides two Boosting modes: Ordered and Plain. The Plain mode incorporates the Ordered TS operation into the standard GBDT algorithm. The Ordered mode improves upon the Ordered Boosting algorithm.
The complete description of the Ordered mode is as follows: CatBoost generates independent random sequences for the training set to define and evaluate the splits of the tree structure, which are used to calculate the values of the leaf nodes obtained from the splits. CatBoost employs symmetric trees as base learners, meaning that within the same layer of the tree, the splitting criteria are the same. Symmetric trees are characterized by balance, reduced overfitting, and significantly reduced testing time. The algorithm flow for constructing trees in CatBoost is shown in the following diagram.
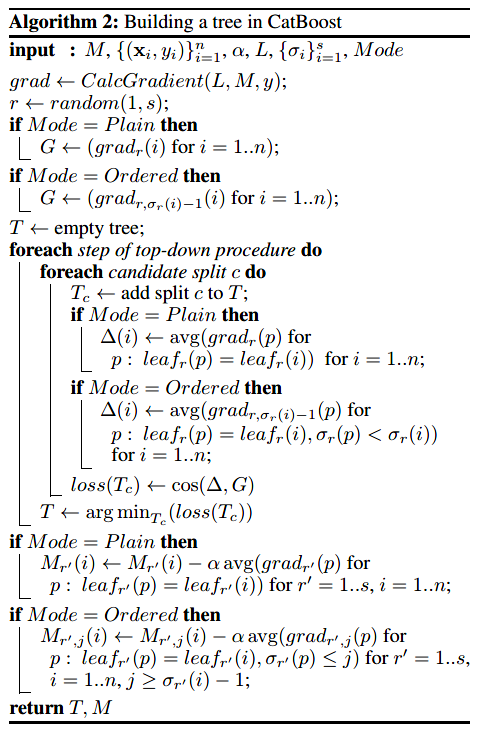
During the learning process in Ordered mode:
-
We train a model, where represents the model learned from the first samples in the sequence for predicting the th sample. -
In each iteration, the algorithm samples a sequence from and constructs the learning tree for the th step based on this. -
Based on the computed gradients. -
Using cosine similarity to approximate gradients, taking the gradient for each sample. -
During the evaluation of candidate split nodes, the leaf node value for the th sample is obtained by averaging the gradient values of the first samples that belong to the same leaf. -
Once the tree structure for the th iteration is determined, it can be used to enhance all models.
Note: This section is quite complex and difficult to understand. The author has not fully grasped it, so readers are strongly encouraged to read the original CatBoost paper.
The complete CatBoost algorithm flow based on the tree construction algorithm is shown in the following diagram.

In addition to handling categorical features and ordered boosting, CatBoost has many other highlights, such as its use of symmetric trees (Oblivious Trees) as base learners and support for multi-GPU training acceleration.
Comparison of CatBoost with XGBoost and LightGBM
CatBoost and LightGBM were open-sourced less than three months apart, both making improvements and optimizations based on XGBoost. Apart from differences in overall algorithm performance, the main differences between the three models, based on CatBoost’s characteristic handling of categorical features, are as follows:
-
CatBoost supports the most comprehensive handling of categorical features, allowing direct input of the column identifiers of categorical features for automated processing. -
LightGBM also supports rapid processing of categorical features, allowing the input of identifiers for categorical feature columns during training. However, LightGBM uses direct hard coding for categorical features, which, while fast, is not as detailed as CatBoost’s handling method. -
XGBoost, as the earliest GBDT implementation, does not support handling categorical features and can only accept numerical data. Therefore, categorical features generally require manual preprocessing such as one-hot encoding.
The CatBoost paper also provides performance comparisons with XGBoost and LightGBM on multiple open-source datasets, as shown in the following diagram.
Implementation of CatBoost Algorithm
Manually implementing a CatBoost system is overly complex; due to time and energy constraints, the author has chosen to forgo this. The CatBoost source code can be referenced at:
https://github.com/catboost/catboost
The official CatBoost library provides us with a relevant open-source implementation, which can be installed directly via pip.
Below is a classification example using CatBoost as a demonstration. For the complete usage documentation of CatBoost, refer to:
https://catboost.ai/docs/concepts/tutorials.html
import numpy as np
import pandas as pd
from sklearn.model_selection import train_test_split
import catboost as cb
from sklearn.metrics import f1_score
# Load data
data = pd.read_csv('./adult.data', header=None)
# Rename variables
data.columns = ['age', 'workclass', 'fnlwgt', 'education', 'education-num', 'marital-status', 'occupation', 'relationship', 'race', 'sex', 'capital-gain', 'capital-loss', 'hours-per-week', 'native-country', 'income']
# Convert labels
data['income'] = data['income'].astype("category").cat.codes
# Split dataset
X_train, X_test, y_train, y_test = train_test_split(data.drop(['income'], axis=1), data['income'], random_state=10, test_size=0.3)
# Configure training parameters
clf = cb.CatBoostClassifier(eval_metric="AUC", depth=4, iterations=500, l2_leaf_reg=1, learning_rate=0.1)
# Categorical feature indexes
cat_features_index = [1, 3, 5, 6, 7, 8, 9, 13]
# Train
clf.fit(X_train, y_train, cat_features=cat_features_index)
# Predict
y_pred = clf.predict(X_test)
# F1 score on test set
print(f1_score(y_test, y_pred))
Good news!
The Beginner's Guide to Vision knowledge circle
is now open to the public👇👇👇
Download 1: OpenCV-Contrib Extension Module Chinese Version Tutorial
Reply "Chinese Extension Module Tutorial" in the backend of the "Beginner's Guide to Vision" public account to download the first Chinese version of the OpenCV extension module tutorial, covering installation of extension modules, SFM algorithms, stereo vision, object tracking, biological vision, super-resolution processing, and more than twenty chapters of content.
Download 2: Python Vision Practical Project 52 Lectures
Reply "Python Vision Practical Project" in the backend of the "Beginner's Guide to Vision" public account to download 31 visual practical projects, including image segmentation, mask detection, lane line detection, vehicle counting, eyeliner addition, license plate recognition, character recognition, emotion detection, text content extraction, and face recognition, to help you quickly learn computer vision.
Download 3: OpenCV Practical Project 20 Lectures
Reply "OpenCV Practical Project 20 Lectures" in the backend of the "Beginner's Guide to Vision" public account to download 20 practical projects based on OpenCV, achieving advanced learning of OpenCV.
Group Chat
Welcome to join the public account reader group to exchange ideas with peers. Currently, there are WeChat groups for SLAM, 3D vision, sensors, autonomous driving, computational photography, detection, segmentation, recognition, medical imaging, GAN, algorithm competitions, etc. (these will gradually be subdivided in the future). Please scan the WeChat ID below to join the group, and note: "Nickname + School/Company + Research Direction", for example: "Zhang San + Shanghai Jiao Tong University + Vision SLAM". Please follow the format; otherwise, you will not be accepted. After successfully adding, you will be invited into the relevant WeChat group based on your research direction. Please do not send advertisements in the group, or you will be removed. Thank you for your understanding~