Reference Information (Click Title to Read Full Text)
Huang Dongmei, Wang Yifan, Hu Anduo, et al. Detection method of false data injection attack based on unsupervised and supervised learning[J]. Electric Power Engineering Technology, 2024, 43(2):134-141.
HUANG Dongmei, WANG Yifan, HU Anduo, et al. Detection method of false data injection attack based on unsupervised and supervised learning[J]. Electric Power Engineering Technology, 2024, 43(2):134-141.
Abstract
False data injection attack (FDIA) poses a serious threat to the safety and stable operation of smart grids. This paper addresses the issues of scarce labeled data and extreme imbalance between normal and attack samples in FDIA detection by proposing an FDIA detection algorithm that integrates unsupervised and supervised learning. First, contrastive learning is introduced to capture the features of a small amount of attack data, generating new attack samples for data augmentation; then, various unsupervised detection algorithms are utilized to perform feature self-learning on massive unlabeled samples, addressing the scarcity of labeled samples; finally, the features extracted by unsupervised algorithms are fused with historical feature sets to construct a supervised XGBoost classifier for identification, outputting detection results as normal or abnormal. Case analysis on the IEEE 30-bus system shows that compared with other FDIA detection algorithms, the proposed method enhances the stability of the FDIA detection model under conditions of scarce labeled samples and data imbalance, improves the identification accuracy of FDIA, and reduces the false alarm rate.
Detection of False Data Injection Attacks Using Unsupervised and Supervised Learning
Huang Dongmei1, Wang Yifan2, Hu Anduo1, Zhou You3, Shi Shuai2, Hu Wei4
1. College of Electronics and Information Engineering, Shanghai University of Electric Power, 2. College of Electrical Engineering, Shanghai University of Electric Power, 3. Suzhou Power Supply Branch of State Grid Jiangsu Electric Power Co., Ltd., 4. College of Economics and Management, Shanghai University of Electric Power
Funding Project: National Social Science Fund Project (19BGL003)
Introduction
In recent years, the integration of power grids and information communication networks has led to the emergence of cyber-physical systems (CPS) where information space and physical space are deeply coupled. The collaborative interaction between information and physical sides enhances the operational capability of CPS but may also introduce new security risks. False data injection attack (FDIA) is a network attack method targeting state estimation in power systems, which compromises the integrity and accuracy of information by tampering with measurement data in the supervisory control and data acquisition (SCADA) system, leading to erroneous state estimates and operational mistakes. Therefore, researching efficient FDIA detection algorithms is of great significance for ensuring the safe and stable operation of CPS.
1. Principles of FDIA Attacks

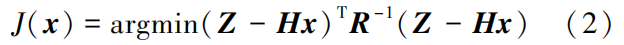
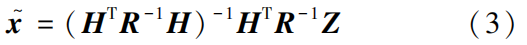
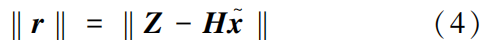

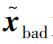 represents the estimated state variables after the attack; c is the deviation vector of the estimated state variables before and after the attack.
represents the estimated state variables after the attack; c is the deviation vector of the estimated state variables before and after the attack.
2. FDIA Detection Model
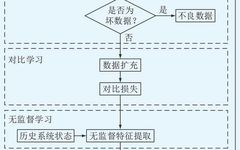
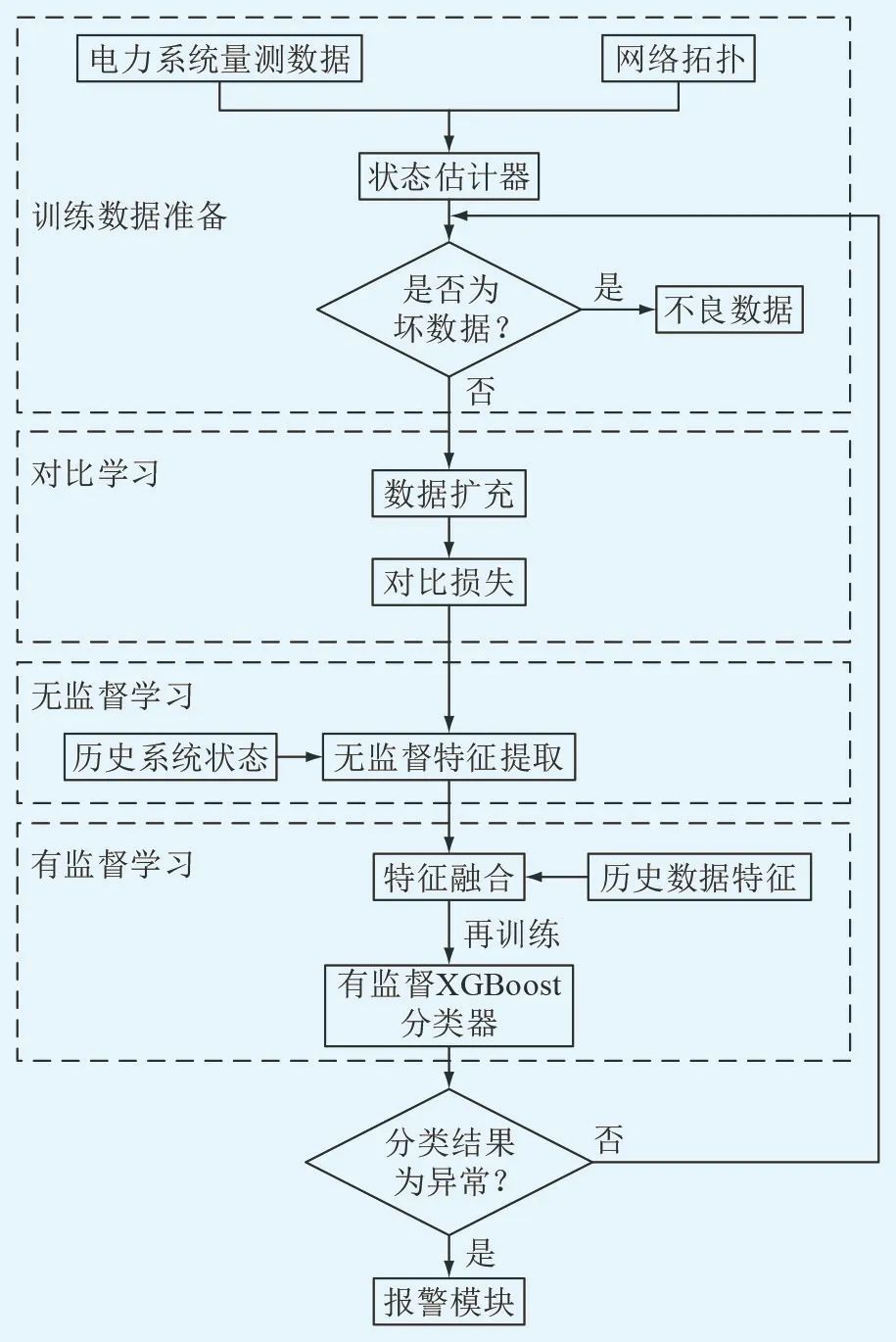
The FDIA detection model that integrates unsupervised and supervised learning is divided into three stages. The first stage uses contrastive learning to augment the number of attack samples, improving the model’s performance on imbalanced datasets; the second stage employs various unsupervised algorithms to extract features from massive unlabeled data, addressing the scarcity of labeled data in the dataset; the third stage fuses the extracted features with historical feature sets to form a new feature space, enhancing the aggregation of data features, and then uses the supervised classifier XGBoost to detect FDIA while pruning the augmented feature space to control computational complexity and improve detection efficiency. The FDIA detection process is illustrated in Figure 1, where data classified as abnormal will trigger the alarm module for FDIA detection, while normal classifications will not trigger an alarm.
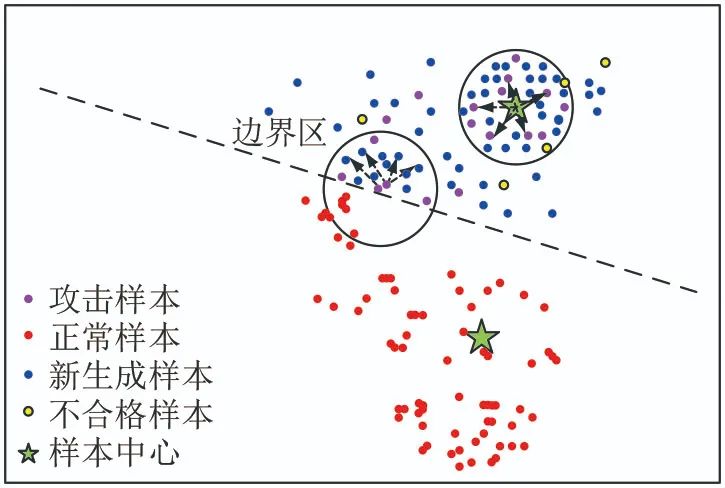
In actual power grids, the occurrence of FDIA is rare and the number of attack samples is limited, resulting in a significant deficiency of attack samples compared to normal samples. To increase the sample size of FDIA events, contrastive learning is employed to augment the number of attack samples, addressing the high false alarm rate and low training efficiency caused by data imbalance. The core idea of contrastive learning is to compare normal samples and attack samples in the feature space to learn the feature representation of the samples, ensuring that the new samples’ feature representations are as close as possible to those of the attack samples while being as different as possible from those of the normal samples.The model is shown in Figure 2.
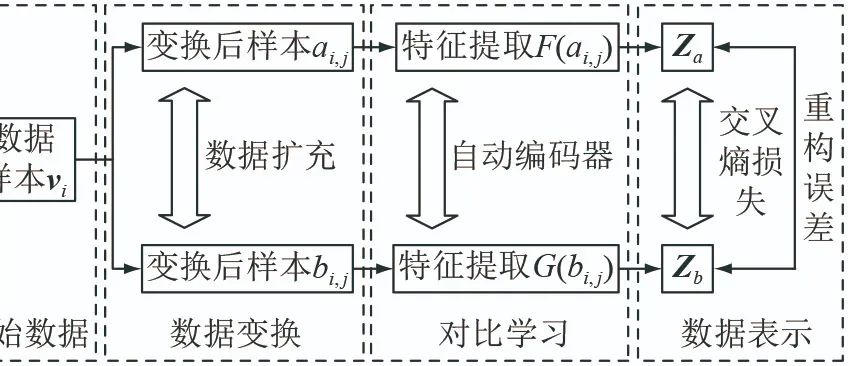
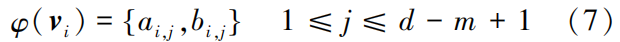
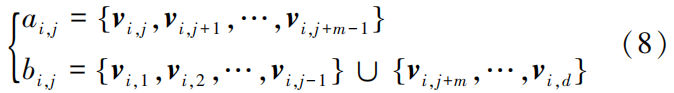
To ensure that the generated new samples are close to the original attack samples, the reconstruction error between the generated new samples and the center of the original attack samples is calculated, eliminating new samples with large reconstruction errors, allowing the generated new samples to converge toward the center of the attack samples, as shown in Figure 3.
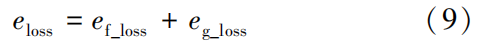
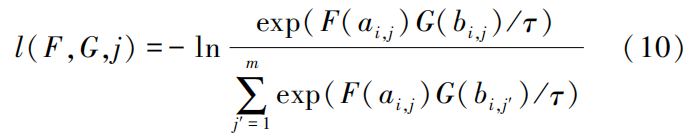
Where: τ is the temperature coefficient.
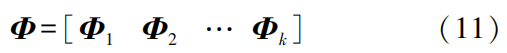
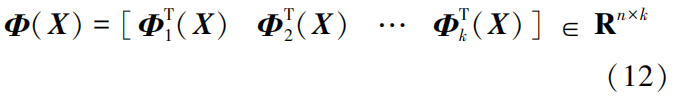
Multiple unsupervised algorithms serve as scoring functions for feature transformation, forming heterogeneous basis functions that can capture different characteristics of outliers in specific datasets, balancing diversity and accuracy, thereby enhancing the model’s generalization ability.
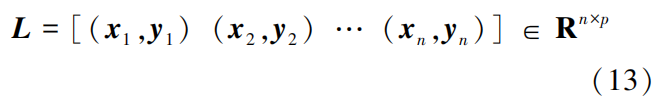

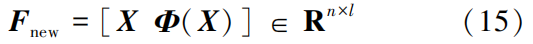
After training the five classifiers, each classifier yields a feature vector of length k. The final results of the base classifiers are concatenated to form a feature vector of length l. The feature fusion framework is illustrated in Figure 4.
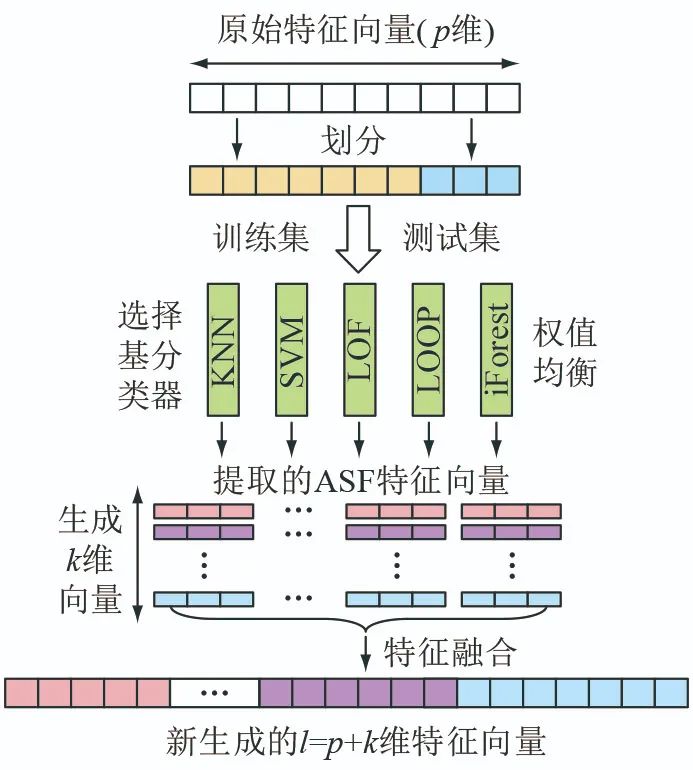
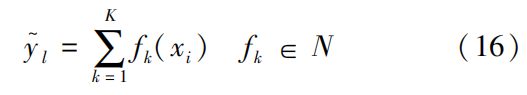
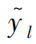 represents the predicted value; K is the number of trees; fk is the function related to the structure and leaf weight of the k-th tree; xi is the input sample; N is the function space composed of decision trees.
represents the predicted value; K is the number of trees; fk is the function related to the structure and leaf weight of the k-th tree; xi is the input sample; N is the function space composed of decision trees.
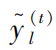 is the predicted attack category at the t-th iteration;
is the predicted attack category at the t-th iteration; 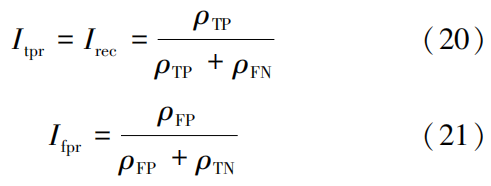 is the loss function, indicating the difference between the predicted attack category and the actual attack category; Ω(fk) is the regularization term.
is the loss function, indicating the difference between the predicted attack category and the actual attack category; Ω(fk) is the regularization term.The objective function is expanded using Taylor’s second-order expansion, and the greedy enumeration method is used to find the gradient boosting tree, resulting in the optimal XGBoost model.
3. Case Analysis
A random selection of 9,000 measurement samples is used as experimental data, with normal samples labeled as 0 and attack samples labeled as 1. The samples are normalized by removing the mean and scaling to unit variance, and a random sampling of 60:40 is performed to create the training and testing sets.
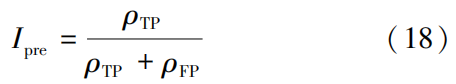

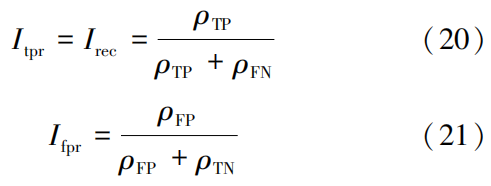
In the formula: ρTN is the number of instances predicted as normal that are actually normal; Itpr is the proportion of correctly detected attack data to the total number of attack data, i.e., detection rate; Ifpr is the proportion of instances predicted as attacks that are actually normal to all normal instances, i.e., false detection rate.
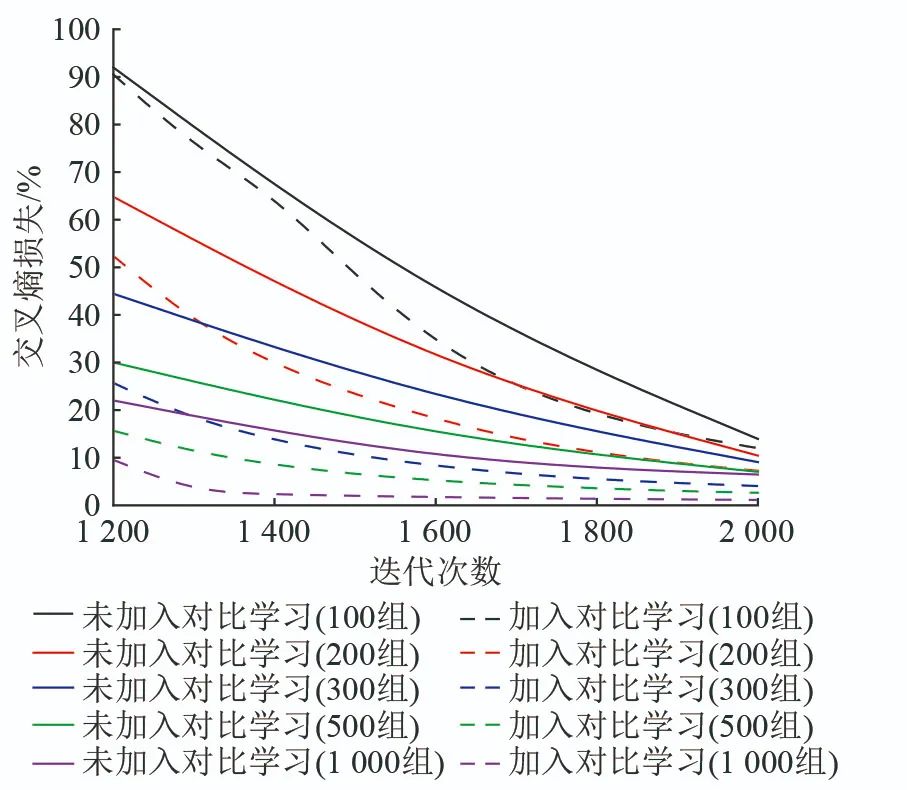
To measure the impact of contrastive learning on the convergence of the algorithm, the number of attack samples in the measurement dataset is selected as 100, 200, 300, 500, and 1,000 for model training, with the convergence results shown in Figure 5. In Figure 5, before the addition of contrastive learning, the degree of data imbalance is significant, with a loss of 13.07%; after the addition of contrastive learning, the new attack detection dataset is increased, reducing the data imbalance, with cross-entropy loss dropping to 1.10%. It can be observed that the addition of contrastive learning for preprocessing the attack dataset reduces the imbalance between normal and attack samples, allowing the model to further converge and enhancing its classification performance.
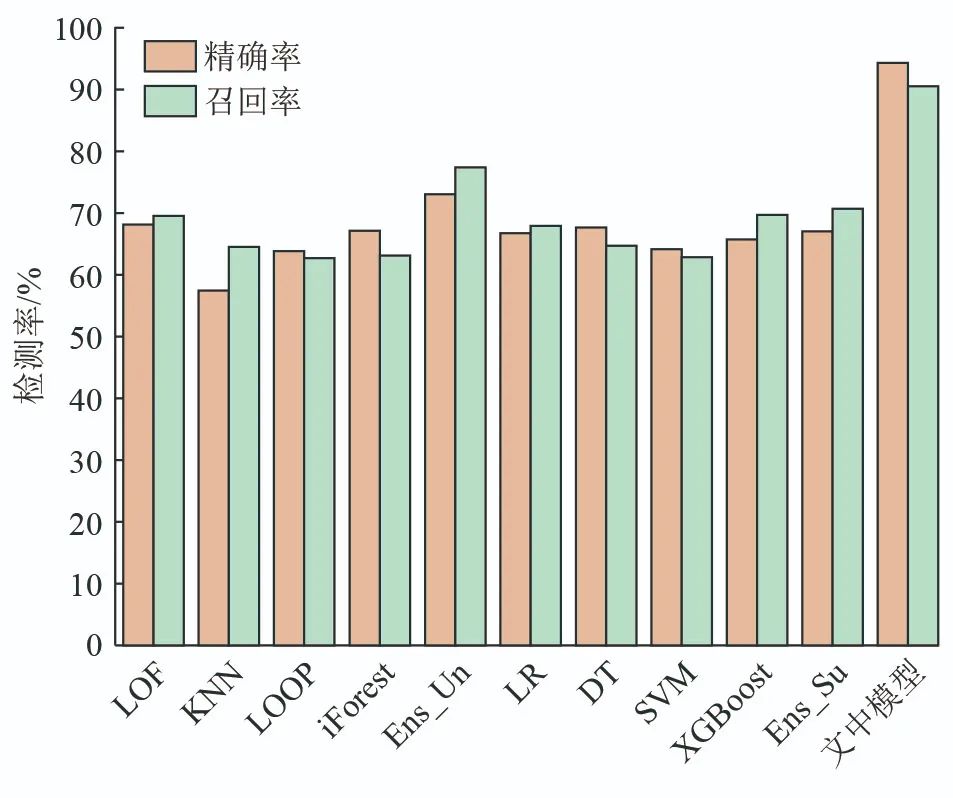
To measure the impact of the number of labeled samples in the measurement dataset on detection, the model in this paper is compared with various supervised and unsupervised single classifiers, unsupervised ensemble (Ens_Un) models, and supervised ensemble (Ens_Su) models from relevant literature, where the dataset contains 95% unlabeled data samples and 5% labeled data samples. Figure 6 shows the precision and recall results of the detection, where LR represents the logistic regression classifier, and DT represents the decision tree classifier. It can be seen that the performance of the detector using the Ens_Un model is slightly better than that of the Ens_Su model, consistent with experimental results in relevant literature. However, the Ens_Un model, which performs well in related literature, has a detection precision and recall of only about 70%, indicating that the detection accuracy is not high. This is because single classifiers in the ensemble adopt the majority voting method for selection, resulting in low overall performance in FDIA recognition, making it difficult to protect the data security of the power grid. The detection recall of the model in this paper is 90.49% and precision is 94.25%, significantly better than other models, mainly because the model employs unsupervised algorithms to extract ASF features from massive unlabeled data and fuses them with historical feature sets, increasing the diversity and completeness of data features, which is beneficial for detecting attacks on the power grid.
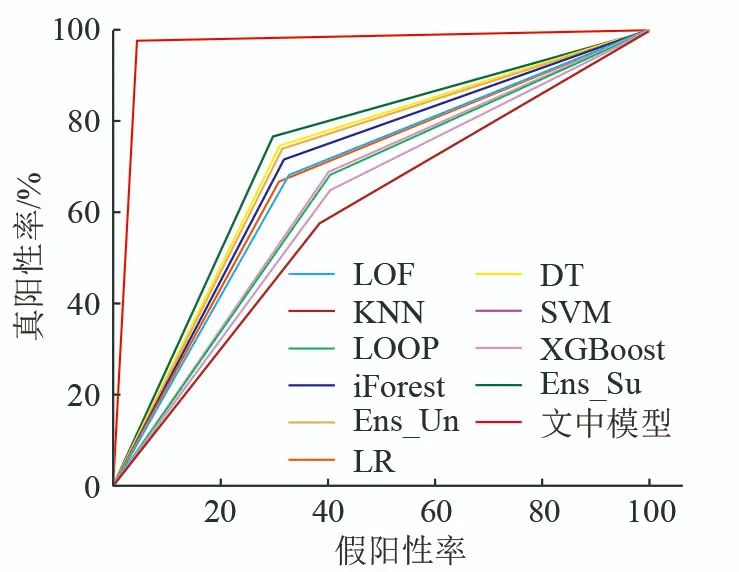
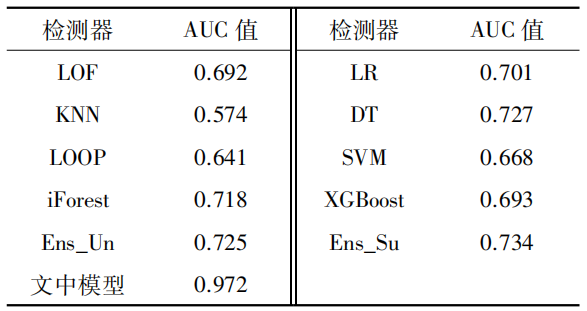
The ROC curve, with the false positive rate on the x-axis and the true positive rate on the y-axis, describes the relative relationship between detection rate and false detection rate, as shown in Figure 7. The area under the ROC curve (AUC) is an important metric for measuring detector performance; if the detector’s performance is superior, the AUC value approaches 1. The AUC values of each detector are shown in Table 1, indicating that the detection model from the comparison experiment has AUC values below 75%, while the detection method proposed in this paper can ensure a high detection rate with a low false detection rate, achieving an AUC value of 97.2%. This demonstrates that the model can accurately detect attacks, has good classification performance, and can effectively protect the safety of the power grid.
Since the occurrence of FDIA in actual power systems is rare, instances of attack classes are far fewer than instances of normal classes, resulting in an extremely imbalanced dataset. To verify the applicability of the model in this paper for FDIA recognition under extremely imbalanced datasets, algorithms for handling imbalanced datasets, such as SMOTE oversampling technique, convolutional neural network model, and semi-supervised autoencoder model, are compared with the model in this paper. Among them, SMOTE oversampling is set with a penalty function of 0.1, completing training when the precision of the test set remains basically unchanged. The convolutional neural network model is set with 5 convolutional layers, 5 max-pooling layers, and 3 fully connected layers, selecting the Sigmoid function as the activation function, with a learning rate of 0.01, using stochastic gradient descent optimizer. To avoid overfitting, the cross-entropy loss function includes a regularization term. The autoencoder parameters are set with one encoder layer and one decoder layer, using cross-entropy as the loss function and Adam optimizer. The detection precision of each detection scheme under different positive and negative sample ratios is shown in Table 2. On one hand, as the imbalance of positive and negative sample ratios increases, the detection accuracy of each detection scheme decreases, because as the positive and negative sample ratios increase, the algorithm’s recognition rate declines. On the other hand, it is found that even under an extremely imbalanced condition with a positive to negative sample ratio of 50:1, the detection precision of the model in this paper can still reach 90%.
Table 2 Detection Precision Under Different Positive and Negative Sample Ratios
To further validate the detection capability of the model in this paper for imbalanced data, Figure 8 presents the box plot of the F1 score for the three algorithms: oversampling, convolutional network, and the model in this paper when the positive to negative sample ratio is 50:1.
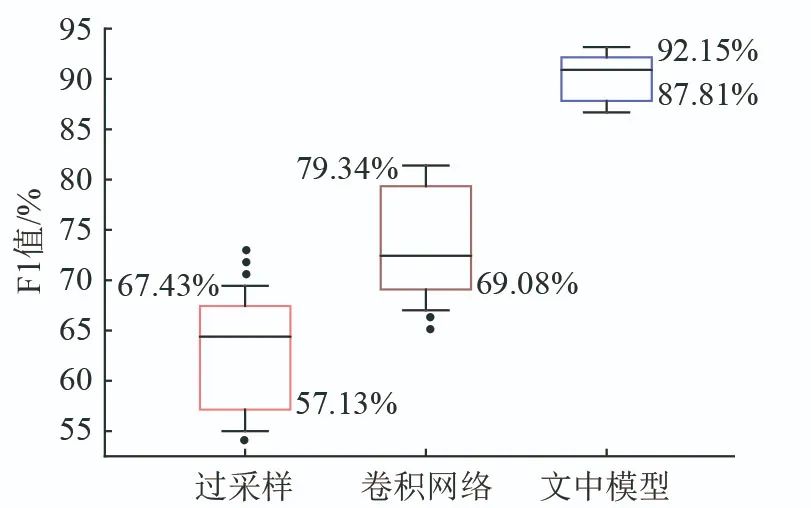
From Figure 8, it can be seen that the F1 score of the detection results from the model in this paper is 90.65%, significantly better than other algorithms, and the experimental results are more concentrated, indicating that the model training can learn more features of the attack class, enhancing the model’s classification ability. Figure 9 shows the confusion matrix for FDIA detection of the model in this paper, revealing that after data balancing through contrastive learning and the improved feature fusion through unsupervised learning, the model’s learning ability is enhanced, improving classification capability.

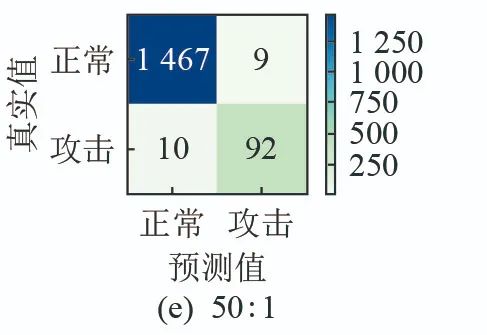
4. Conclusion
Given the deviations in the completeness and accuracy of actual power network measurement data, future research could explore FDIA detection methods considering data cleaning and completion as preprocessing steps.

Huang Dongmei (1964): Female, Master, Professor, Doctoral Supervisor, Research direction in marine and electric power spatiotemporal information technology (E-mail: [email protected]);
Wang Yifan (1998): Male, Master’s student, Research direction in false data injection attack detection;
Hu Anduo (1983): Male, Doctor, Lecturer, Research direction in power load forecasting and false data injection attack detection.
Huang Chongxin, Hong Minglei, Fu Shuai, et al. Active Distribution Network Distributed State Estimation Considering False Data Injection Attacks[J]. Electric Power Engineering Technology, 2022, 41(3):22-31.
Xie Yunyun, Yan Xinteng, Sang Zi, et al. False Data Injection Attack Methods for AC/DC Hybrid Systems[J]. Electric Power Engineering Technology, 2022, 41(1):165-172.
Xie Yunyun, Yan Xinteng, Yan Zi Ao, et al. Optimization of False Data Injection Attack Strategies for AC/DC Hybrid Grids[J]. Electric Power Engineering Technology, 2023, 42(4):94-101.
Qiu Xing, Yin Shihong, Zhang Zihan, et al. Non-Intrusive Load Identification Method Based on V-I Trajectory and Higher Harmonic Features[J]. Electric Power Engineering Technology, 2021, 40(6):34-42.
Yan Xueying, Qin Chuan, Ju Ping, et al. Research on Optimal Feature Selection of Load Power Models[J]. Electric Power Engineering Technology, 2021, 40(3):84-91.
Important Notice: According to the relevant regulations of the National Copyright Administration, any reproduction or excerpt of this WeChat article by paper media, websites, Weibo, or WeChat official accounts must include this WeChat name, QR code, and other key information, and indicate “Original from Electric Power Engineering Technology” at the beginning. Individuals may forward and share according to the original text of this WeChat article.
Editor: Zhang Tiantian
Review: Jiang Lin