
<span>datetime</span> for handling dates and times, <span>requests</span> for sending HTTP requests, <span>yfinance</span> for downloading stock data from Yahoo Finance, and <span>numpy</span> and <span>pandas</span> for data processing and numerical calculations. Additionally, we need <span>sklearn.model_selection</span> to split the dataset and <span>keras</span> to build and train the neural network model.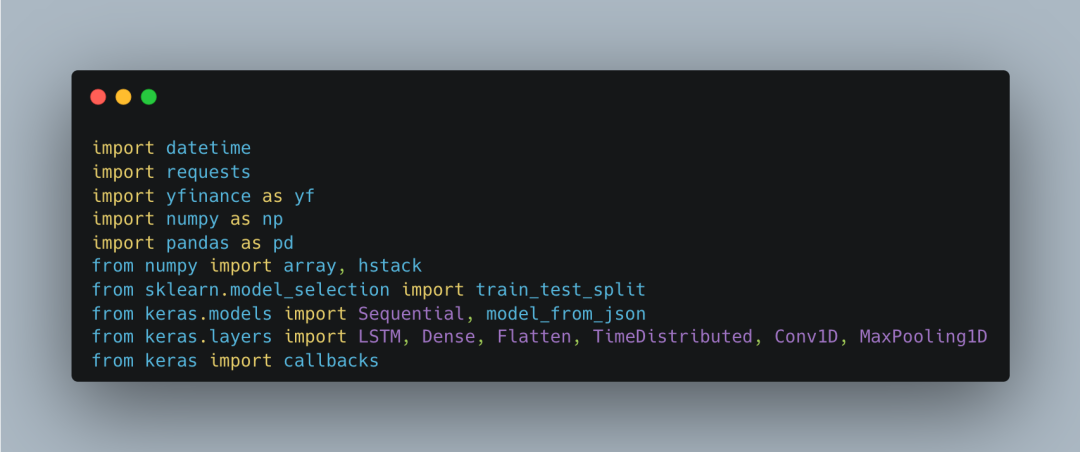
Data Preparation Function
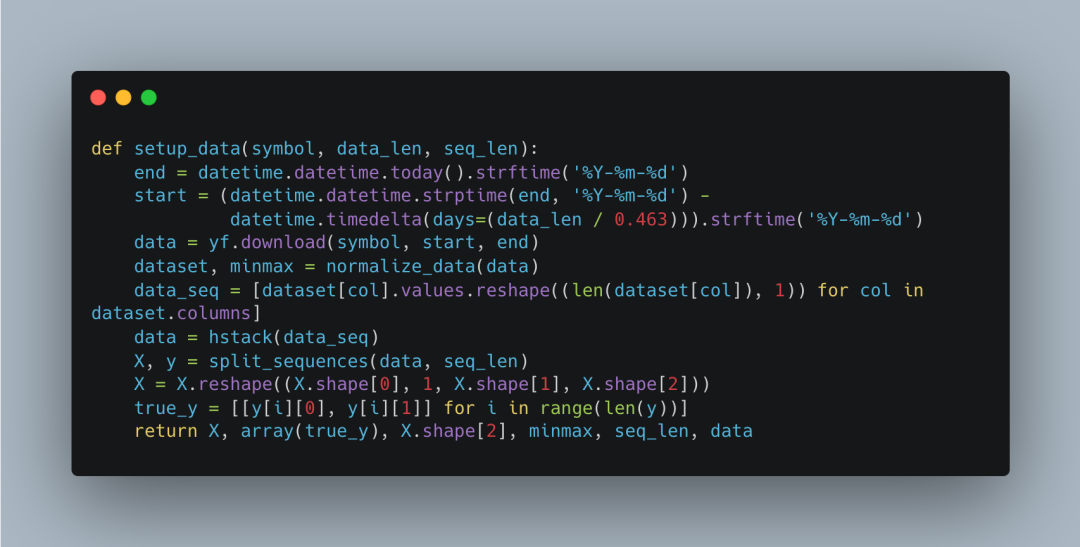
Next, we define a data preparation function <span>setup_data</span>. This function is responsible for preparing our data. First, it calculates the start and end dates of the data. Then, it uses <span>yfinance</span> to download data for the specified stock code. Next, it calls the <span>normalize_data</span> function to standardize the data. Finally, it converts the data into a sequence format suitable for the LSTM model and returns the processed data along with relevant parameters.
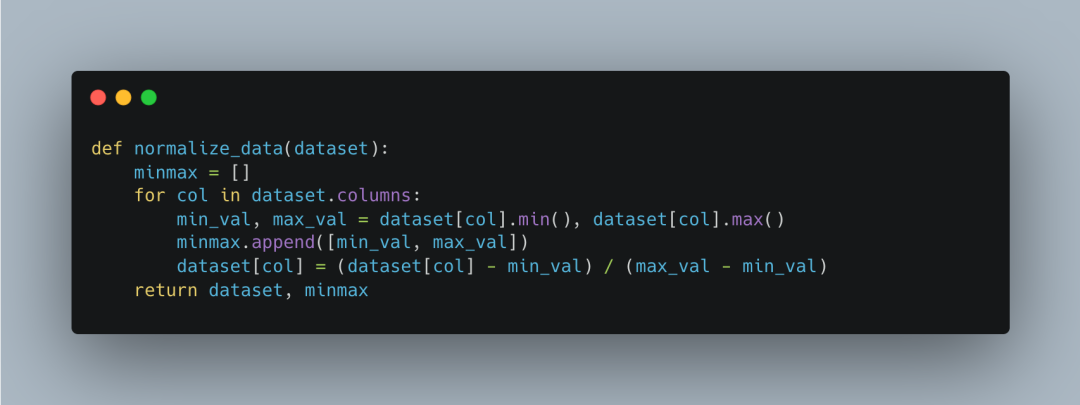
Data Normalization Function
The data normalization function <span>normalize_data</span> is responsible for normalizing the data to the range [0, 1]. It calculates the minimum and maximum values for each column and saves these values. Then, it normalizes each column of data to ensure consistency and comparability.
Data Serialization Function
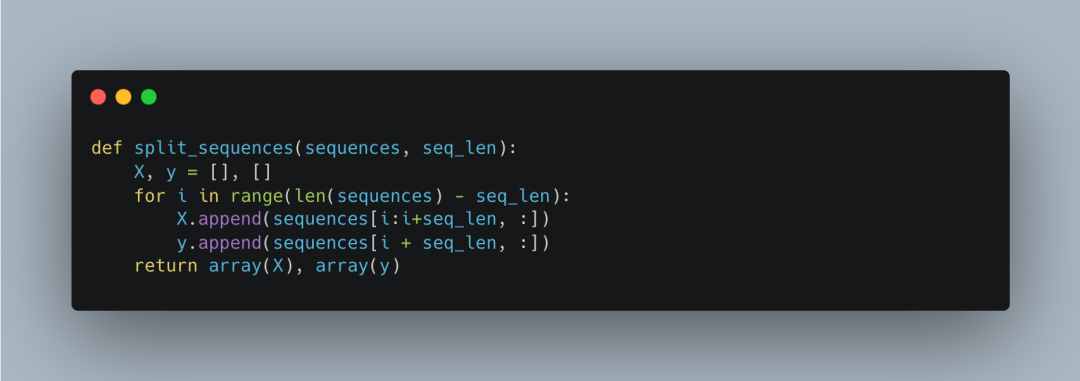
The data serialization function <span>split_sequences</span> divides the dataset into input sequences (X) and output sequences (y). <span>seq_len</span> is the length of each sequence.
Initializing and Compiling the LSTM Model
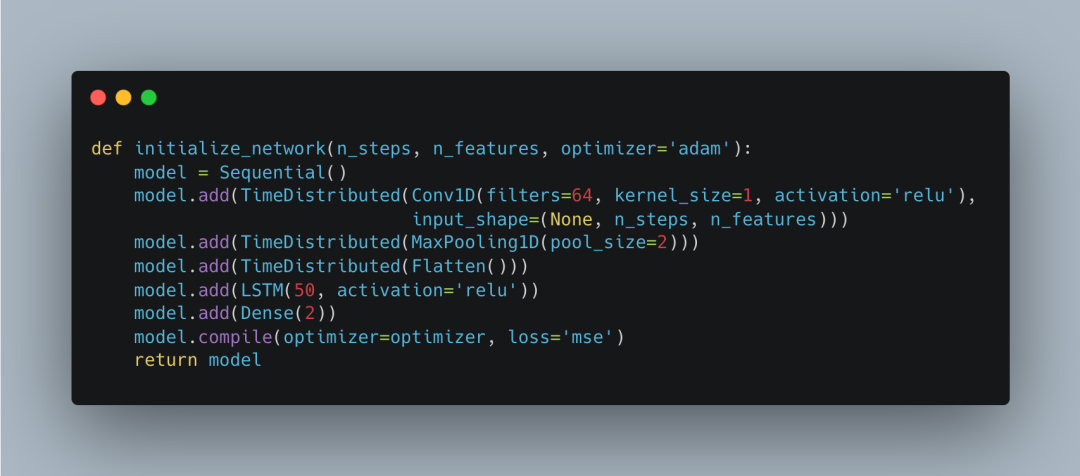
Next, we define a function <span>initialize_network</span> that is responsible for building our LSTM model. The model structure includes a convolutional layer, a pooling layer, a flattening layer, an LSTM layer, and a fully connected layer. We use <span>adam</span> optimizer and mean squared error (MSE) as the loss function.
Training the LSTM Model
The function for training the LSTM model <span>train_model</span> is responsible for training our LSTM model. It uses the <span>ModelCheckpoint</span> callback to save the best model and the <span>EarlyStopping</span> callback to stop training early when the validation loss does not improve. It returns the training history.
Loading the Trained LSTM Model
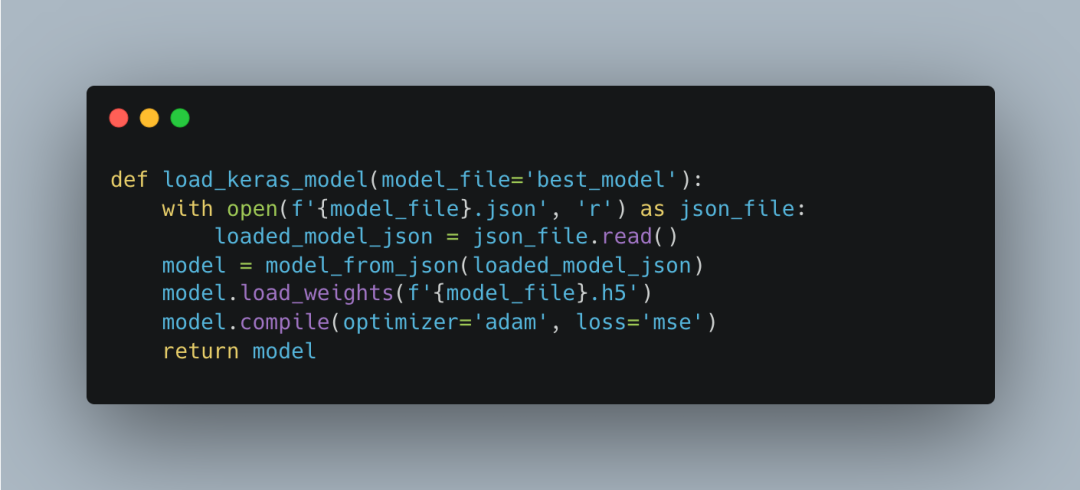
The function for loading the trained LSTM model <span>load_keras_model</span> is responsible for loading the already trained LSTM model. It loads the model structure from a JSON file and the model weights from an HDF5 file.
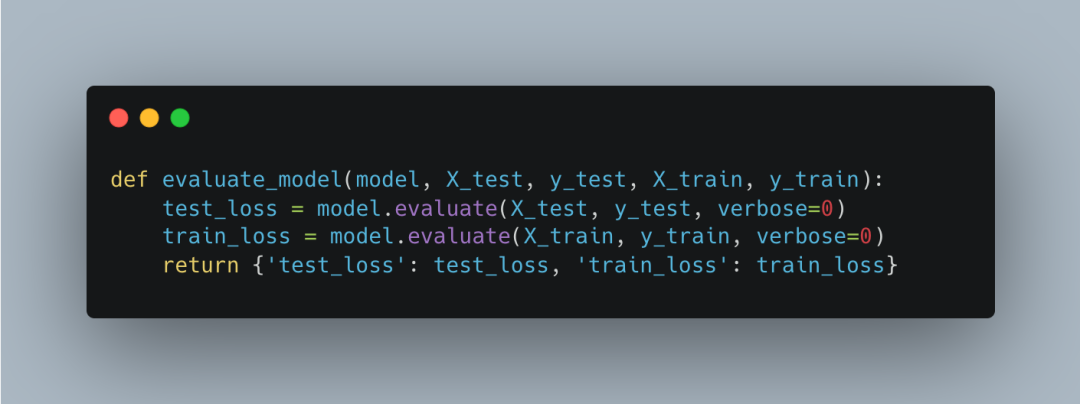
Evaluating Model Performance
The function for evaluating model performance <span>evaluate_model</span> is responsible for assessing the model’s performance. It calculates the loss values on the training set and test set and returns the results.
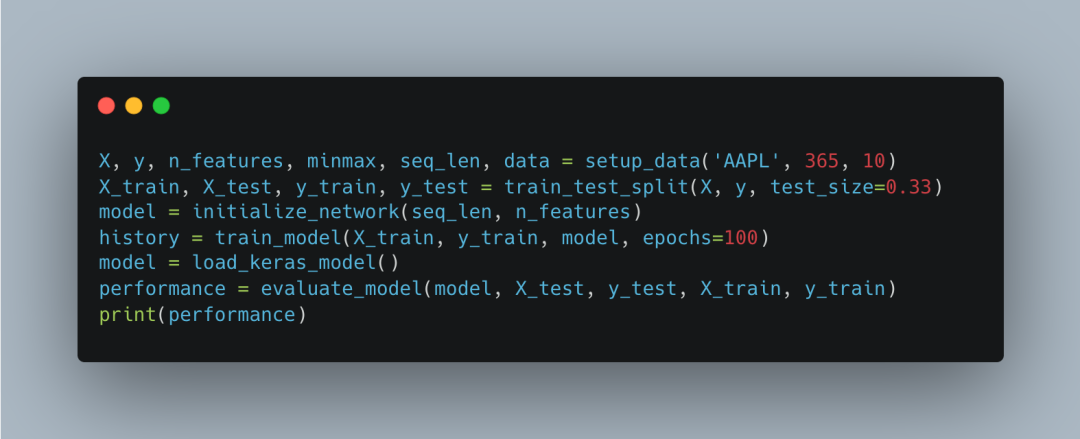
Main Execution Part
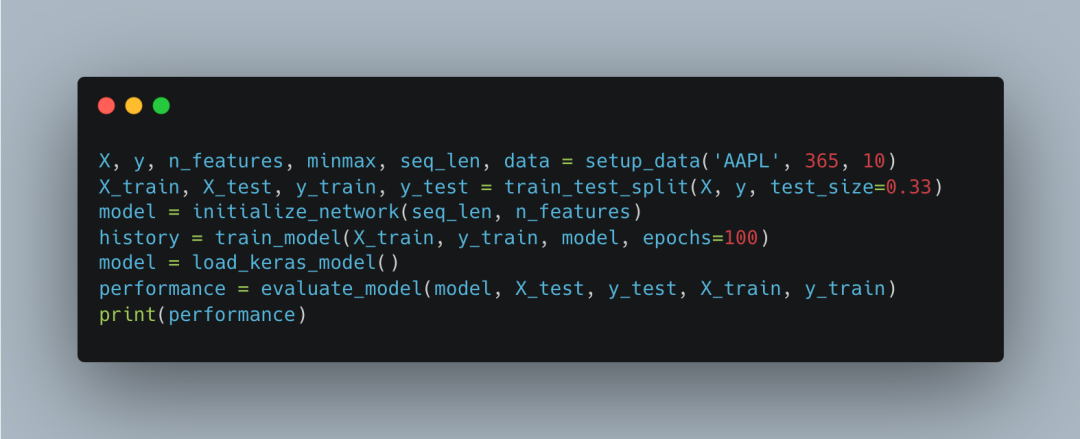
This part of the code is our main program. It calls the <span>setup_data</span> function to prepare the data, uses <span>train_test_split</span> to split the data into training and test sets, initializes and trains the LSTM model, loads the trained model, and evaluates its performance.
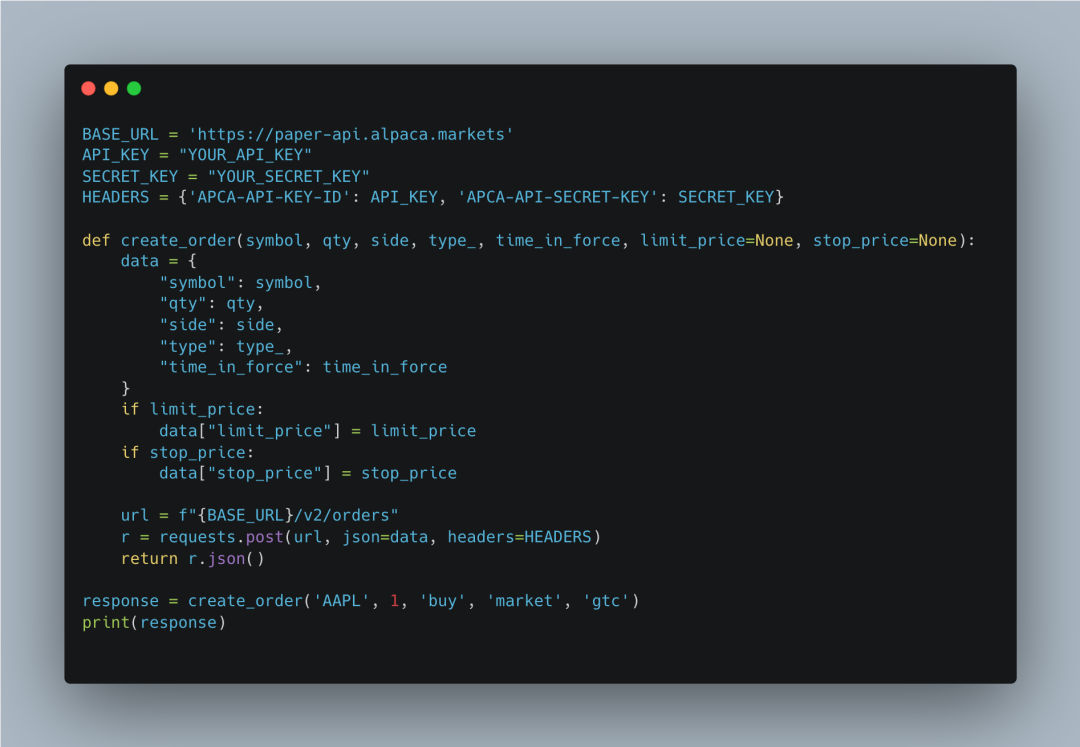
Alpaca API Setup and Order Creation Function
Finally, we perform automated trading through the Alpaca API. The <span>create_order</span> function accepts order parameters and sends a POST request to the Alpaca API to create an order. In the example, a market order is created to buy 1 share of Apple Inc.
Summary
This code demonstrates how to use the LSTM model for stock price prediction and achieve automated trading through the Alpaca API. The main steps of the code include data preparation, model training, model evaluation, and order creation. I hope this code can help you better understand the process and technical details of quantitative trading. Long press the QR code below to join the Kuandeng Quant Club and get the complete source code of this article.

Exclusive Discounts for Aliyun Server Double 11 Event
Miss today, wait another year!
Click Read the original text to enjoy the 15% off first purchase discount