

Recently, in the field of Natural Language Processing (NLP), the use of pre-training methods for language models has achieved significant improvements across various NLP tasks, attracting widespread attention from various sectors. In this article, I will summarize some relevant papers I have recently read, selecting a few representative models (including ELMo [1], OpenAI GPT [2], and BERT [3]) to share and learn together.
Author: Luo Ling
School: Dalian University of Technology, Information Retrieval Laboratory
Research Direction: Deep Learning, Text Classification, Entity Recognition
Introduction
Before introducing the papers, I will briefly introduce some relevant background knowledge. First, the language model (Language Model) is simply the probability distribution of a sequence of words. Specifically, the role of a language model is to determine a probability distribution P for a text of length m, indicating the likelihood of the existence of this text.
In practice, estimating P(wi | w1, w2, . . . , wi−1) can be very difficult if the text is long. Therefore, researchers have proposed a simplified model: n-gram model. When estimating conditional probabilities in the n-gram model, only the previous n words of the current word need to be considered. In the n-gram model, traditional methods generally use frequency counting ratios to estimate n-gram conditional probabilities. When n is large, there is a data sparsity problem that leads to inaccurate estimates. Therefore, in a corpus with millions of words, a trigram model is generally used.

To alleviate the data sparsity problem encountered in estimating probabilities with the n-gram model, researchers proposed neural network language models. A representative work is the neural network language model proposed by Bengio et al. in 2003, which uses a three-layer feedforward neural network for modeling. Notably, the first layer’s parameters serve as word representations that are not only low-dimensional and compact but also capable of encapsulating semantics, laying the foundation for the word vectors (e.g., word2vec) that we commonly use today.
In fact, a language model predicts the next word based on the context, which does not require manually annotated data, allowing the model to learn rich semantic knowledge from unrestricted large-scale monolingual data.
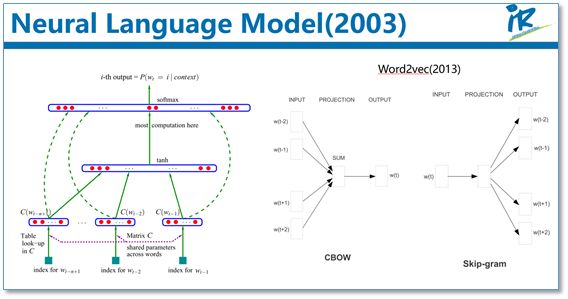
Next, let’s briefly introduce the idea of pre-training. We know that the current training of neural networks is mainly based on the Backpropagation (BP) algorithm, which involves randomly initializing the network model parameters and then optimizing these parameters using optimization algorithms such as SGD through the BP algorithm.
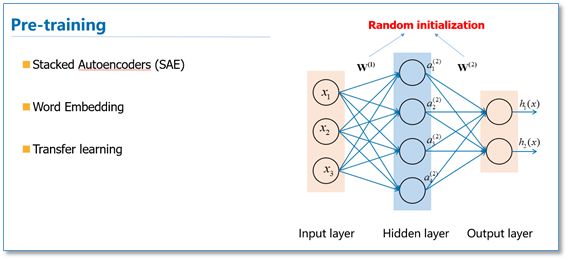
Thus, the idea of pre-training is that the model’s parameters are no longer randomly initialized, but rather trained on a task to obtain a set of model parameters, which are then used to initialize the model before further training.
In fact, the early use of stacked autoencoders to build deep neural networks follows this idea. Word vectors can also be seen as pre-trained embeddings for the first layer, and this idea is also widely used in neural network-based transfer learning.
Next, we will look at the specific works on pre-training using language models.
ELMo
Introduction
Deep Contextualized Word Representations [1] This paper comes from the University of Washington and was published at this year’s NAACL conference, winning the Best Paper award.
Actually, this work is a continuation of a paper by the same team published at ACL 2017 titled Semi-supervised sequence tagging with bidirectional language models [4], where they generalized the model further.
First, let’s look at their motivation: they believe that a pre-trained word representation should encapsulate rich syntactic and semantic information and be able to model polysemy. Traditional word vectors (e.g., word2vec) are context-independent. For example, in the case of the word “apple,” the two instances of “apple” have different meanings based on context, but in word2vec, there is only one vector for “apple,” making it impossible to model polysemy.

So they utilized a language model to obtain a context-dependent pre-trained representation called ELMo, achieving improvements across six NLP tasks.

Method
In ELMo, they used a bidirectional LSTM language model, consisting of a forward and a backward language model, with the objective function being the maximum likelihood of these two directional language models.
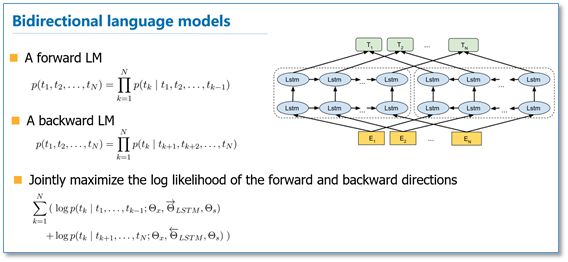
After pre-training this language model, ELMo is used for word representation according to the following formula, which essentially sums the intermediate layers of the bidirectional language model. The simplest approach is to use the representation from the top layer as ELMo.

Then, when performing supervised NLP tasks, ELMo can be directly concatenated as features to the word vector input of the specific task model or to the top layer representation of the model.
In summary, unlike traditional word vectors where each word corresponds to a single vector, ELMo utilizes a pre-trained bidirectional language model to obtain context-dependent representations for the current word based on specific input (the representations of the same word differ across contexts), which are then added as features to specific supervised NLP models.
Experiments
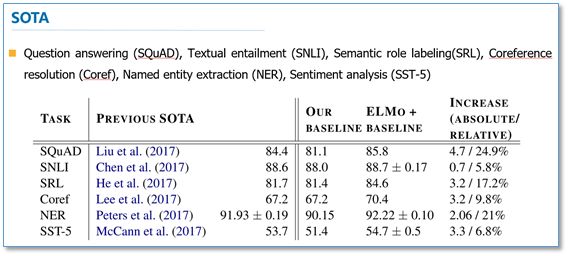
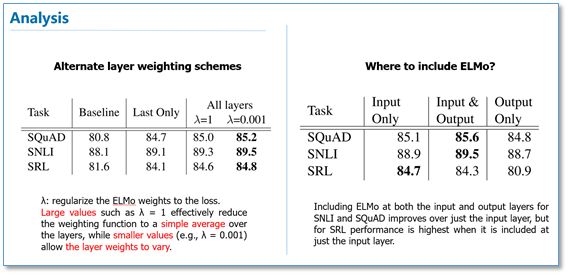
Here, we will briefly look at the main experiments; for detailed experiments, please refer to the paper. First, we look at the overall model performance. They conducted experiments across six NLP tasks, first establishing different models as baselines for each task, then adding ELMo, and it can be seen that all six tasks improved after adding ELMo, averaging an improvement of over 2 percentage points, with final results exceeding previous state-of-the-art (SOTA) results.
In the subsequent analysis experiments, we can see that using all layers yields better results than just using the last layer as ELMo. There is no conclusive evidence regarding whether adding ELMo at the input or output is better; the effectiveness may vary across different tasks.
OpenAI GPT
Introduction
Next, let’s look at the second paper Improving Language Understanding by Generative Pre-Training [2], which is a preprint paper released by the OpenAI team recently. Their goal is to learn a universal representation that can be applied across a wide range of tasks.
The highlight of this paper is that they utilized the Transformer network instead of LSTM as the language model to better capture long-range linguistic structures. During the specific task’s supervised fine-tuning, they used the language model as an auxiliary training objective. Finally, they conducted experiments across 12 NLP tasks, achieving SOTA on 9 of them.

Method
First, let’s take a look at their unsupervised pre-training language model. They still used the standard language model objective function, which predicts the current word based on the previous k words, but on the language model network, they utilized the Transformer decoder proposed by the Google team in the paper Attention is all you need as the language model.
The Transformer model mainly utilizes a self-attention mechanism, which I won’t elaborate on here; you can refer to the paper or my previous article on the self-attention mechanism in natural language processing.

Then, during the supervised fine-tuning for specific NLP tasks, unlike ELMo which treats it as features, OpenAI GPT does not require re-building a new model structure for the task, but directly attaches a softmax layer on top of the last layer of the Transformer language model as the task output layer, then fine-tunes the entire model. They also found that using the language model as an auxiliary task can enhance the generalization ability of the supervised model and accelerate convergence.

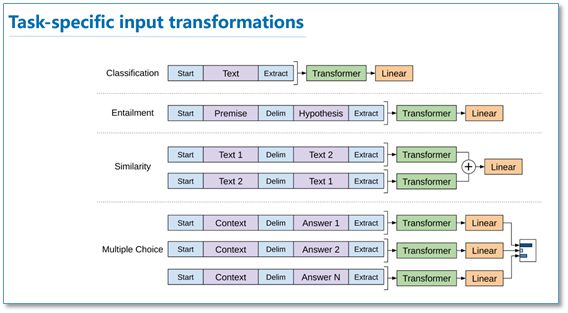
Due to the varying inputs of different NLP tasks, the inputs for the Transformer model also differ for different NLP tasks.
Specifically, as shown in the figure below, for classification tasks, the text input is straightforward; for textual entailment tasks, the premise and hypothesis are concatenated with a delimiting vector for input; for text similarity tasks, both directions use delimiting concatenation for input; and for question-answering multiple-choice tasks, each answer is concatenated with the context for input.
Experiments
Next, I will briefly list the experimental results across different NLP tasks.
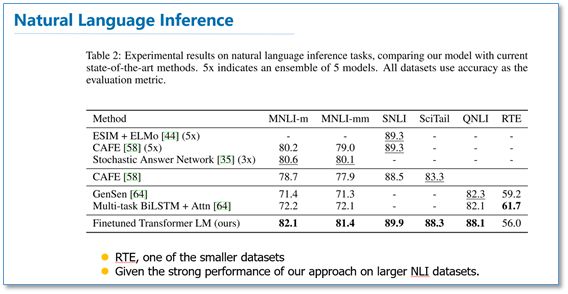
Language Inference Task:
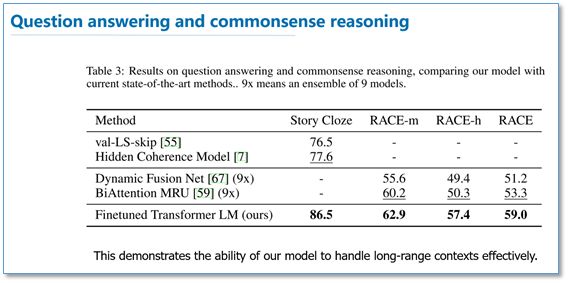
Question Answering and Common Sense Reasoning Tasks:
Semantic Similarity and Classification Tasks:
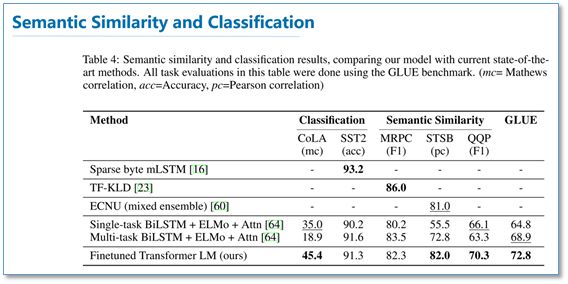
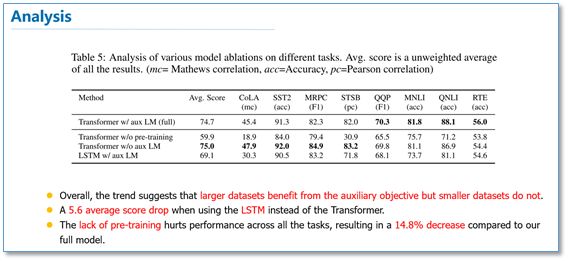
It can be seen that across multiple tasks, OpenAI GPT outperformed ELMo. From the subsequent ablation experiments, it can be observed that removing the pre-training part led to a significant drop in all tasks, averaging a decline of 14.8%, indicating that pre-training is very effective; using a language model as an auxiliary task yields better results on large datasets, but not so much on small datasets; replacing LSTM with Transformer resulted in an average drop of 5.6%, further demonstrating the performance of Transformer.
BERT
Introduction
Last week, Google released their language model pre-training method, which instantly garnered widespread attention; many media outlets also reported on it. Let’s take a look at this paper BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding [3].
This paper divides pre-training language representation methods into feature-based methods (represented by ELMo) and fine-tuning-based methods (represented by OpenAI GPT). Currently, both methods use unidirectional language models to learn language representations during pre-training.

In this paper, the authors demonstrate that using bidirectional pre-training yields better results. In fact, the overall framework of this paper is similar to GPT, representing a further development. Specifically, BERT uses the Transformer encoder as the language model and proposes two new objective tasks during language model pre-training (i.e., Masked Language Model (MLM) and Next Sentence Prediction), ultimately achieving SOTA across 11 NLP tasks.

Method
In the language model, BERT uses the Transformer encoder and designs a smaller base structure and a larger network structure.

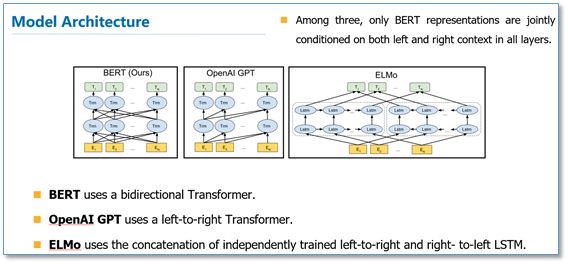
Comparing the three language model structures, BERT employs a Transformer encoder, which, due to the self-attention mechanism, allows direct connections between all layers of the model. OpenAI GPT uses a Transformer encoder that is a left-to-right constrained Transformer, while ELMo uses a bidirectional LSTM. Although it is bidirectional, it only performs a simple concatenation at the highest layer of two unidirectional LSTMs. Thus, only BERT truly exhibits bidirectionality across all layers of the model.
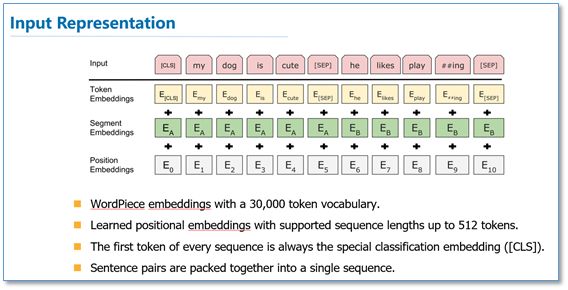
In terms of model input, BERT incorporates more details, as shown in the figure below. They employed WordPiece embeddings as word vectors, along with position vectors and sentence segmentation vectors. Additionally, the authors added a CLS vector at the beginning of each text input, which will serve as the specific classification vector.
In language model pre-training, they no longer use the standard left-to-right prediction of the next word as the objective task, but propose two new tasks.The first task they call MLM, which involves randomly masking 15% of the words in the input word sequence, and the task is to predict the masked words. Compared to traditional language model prediction objective functions, MLM can predict the masked words from any direction, not just unidirectionally.
However, this approach has two drawbacks:
1. During pre-training, using [MASK] to replace the masked words results in a mismatch during the fine-tuning phase since there is no [MASK] in the fine-tuning;
2. Predicting 15% of the words instead of the entire sentence slows down the convergence of pre-training. However, regarding the second point, the authors believe that although it is slower, the significant improvement in performance compensates for it.

For the first point, they adopted the following technique to alleviate it, which is not always using [MASK] to replace masked words; in 10% of the cases, they replace it with a random word, and in another 10% of the cases, they keep the original word.

Traditional language models do not consider the relationships between sentences. To enable the model to learn the relationships between sentences, the authors proposed the second objective task, which is to predict the next sentence. This essentially becomes a binary classification problem, where 50% of the time, a sentence and the next sentence are concatenated as input with a positive label, while the other 50% involves a sentence concatenated with a non-next random sentence with a negative label. The final objective function for the entire pre-training consists of the likelihood of these two tasks combined.

During the fine-tuning phase, the model structures for different tasks are shown in the figure below, where only the input and output layers differ, and then all parameters of the entire model are fine-tuned.
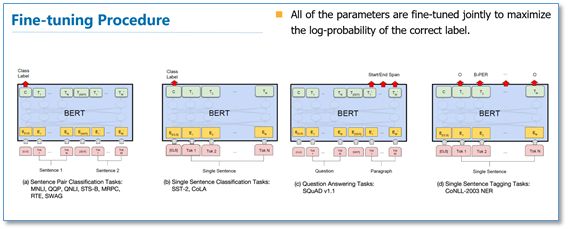
Experiments
Next, we will list the performance of BERT across different NLP tasks.
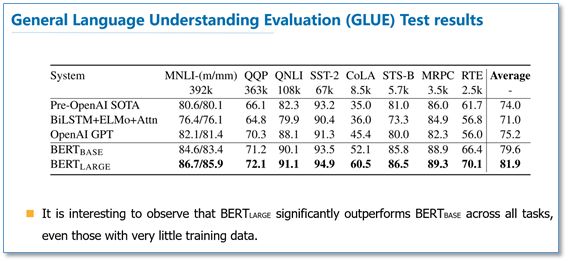
GLUE Results:
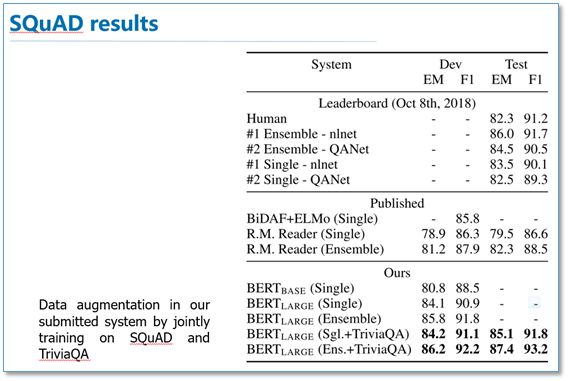
QA Results:
Entity Recognition Results:

SWAG Results:

It can be observed that BERT achieved SOTA across all these NLP tasks, and the performance improvement compared to ELMo and GPT is quite significant.
In the analysis of pre-training experiments, it is evident that the two proposed objective tasks are very effective, especially the MLM task.
The authors also conducted experiments on model scale, showing that larger models perform better, even on small datasets.
Additionally, the authors performed experiments treating ELMo as features, and as shown in the figure below, when treated as features, the best effect can reach 96.1%, which is comparable to the fine-tuning result of 96.4%, indicating that BERT is effective for both feature-based and fine-tuning methods.
Conclusion
In conclusion, compared to traditional word vectors, using language model pre-training can be seen as a sentence-level context word representation, which can fully utilize large-scale monolingual corpora and model polysemy.
Moreover, the last two papers demonstrate that after pre-training on large-scale corpora, using a unified model or directly adding it as features to simpler models can yield good results across various NLP tasks, indicating a significant alleviation of the model structure dependency for specific tasks. Currently, SOTA has been achieved in many evaluations, and ELMo is also available on the official website for public use.
However, these methods are relatively high in both space and time complexity, especially BERT, which in the paper states that training the base version requires 16 TPU devices, while the large version requires 64 TPU devices for 4 days of training. For typical conditions, training on a single GPU could take up to a year. Additionally, it can be observed that these methods involve many engineering details, and poor handling of some details can significantly impact results.
References
[1] Peters, M. E. et al. Deep contextualized word representations. naacl (2018).
[2] Radford, A. & Salimans, T. Improving Language Understanding by Generative Pre-Training. (2018).
[3] Devlin, J., Chang, M.-W., Lee, K. & Toutanova, K. BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding. (2018).
[4] Peters, M. E., Ammar, W., Bhagavatula, C. & Power, R. Semi-supervised sequence tagging with bidirectional language models. Acl (2017).