In the era of AI, semantic processing will become the core of operating systems, and all software technologies will establish their upper limits based on advancements in semantic technology.
Editor | Yan Zi Typesetting Editor | Xiao Shuang
Once again, GPT-4 has overshadowed all the established tech companies.
In the third month since ChatGPT was hailed as a paradigm shift, Google launched the PaLM-E visual language model (VLM). Functionally, it not only allows AI to understand text and images but also adds a control loop for generating robot action plans.
Google is clearly anxious. Under the pressure from OpenAI and Microsoft, it has thrown out a big move.
This familiar playbook reminds one of the mobile internet era’s battle of mobile operating systems, where Microsoft, rooted in OS development, failed to seize the ecological entry point at the beginning of smartphone evolution, leading to its defeat by the emergent Google Android. Now, Google’s frantic development of large models has been caught off guard by the sudden success of newcomer OpenAI.
Even with the release of the world’s largest visual language model (VLM) PaLM-E, boasting an impressive 562 billion parameters, it could not prevent GPT-4 from breaking the Gordian knot.
Looking back to 2015, neither Elon Musk nor Sam Altman could have anticipated that OpenAI, a nonprofit organization, would catch up with Google’s technological advancements within a decade, breaking the monopoly of AI core technology giants. The early public testing and open-source foundation of GPT also mean that more extensive technologies will be developed based on it, marking a profitable beginning.
Behind every success is complexity. Natural language processing technology has traversed three stages and is now finally ushering in a transformation. Next, you will travel from the present back to the past to see:
1. Two significant turning points in natural language processing
2. The application differences and causes of Bert and GPT models
3. Two reasons why GPT did not appear in China
4. Technological development is technology-first, application-later
5. Natural language processing: the most crucial foundation for AGI
Word2vec: Enabling Machines to Perceive Semantics
Let’s pull the timeline back 20 years—
In 2003, Yoshua Bengio formally proposed the Neural Network Language Model (NNLM), which relies on the core concept of word vectors (Word Embedding).
If GPS is the positional symbol of the physical world, then Word Embedding is the distance symbol of the language world.
In 2010, Tomas Mikolov (Google team) improved upon Bengio’s NNLM by proposing RNNLM (Recurrent Neural Network based Language Model), aiming to utilize all preceding context to predict the next word.
However, RNN suffers from long-distance gradient vanishing issues, with limited contextual memory capabilities, making it challenging to trace information from further back in time. Moreover, merely relying on isolated words or preceding context is insufficient for machines to perceive the meaning of words in specific contexts.
Thus, in 2013, Mikolov (Google team) proposed Word2vec, which they termed “word to vector.” The goal of Word2vec shifted from modeling language models to learning the semantic vector of each word using language models.
In the 1986 publication “Parallel Distributed Processing,” a viewpoint was expressed: “Humans are smarter than today’s computers because the human brain employs a computational architecture more suited for humans to accomplish their natural information processing tasks, such as ‘perceiving’ objects in natural scenes and clarifying their relationships… understanding language and retrieving contextually appropriate information from memory.”
Researchers thought that if each vocabulary could be annotated as numbers and input in encoded form, the encoder network could then train on these samples through backpropagation. However, a very important issue is that machines cannot acquire the semantic relationships between words or phrases like humans do.
Linguist John Firth expressed this idea in1957: You will know a word by the company it keeps. For example, anger often appears in the same context as rage, while laughter and joy are also frequently found in the same context.
Researchers discovered through their “vocabulary” that after training word vectors using a large corpus of English, the vector difference between queen and king was nearly identical to the vector difference between woman and man. Thus, they derived an equation:queen-king+man=woman
This is the famous “king and queen” example, which is a significant milestone in the progress of natural language processing toward understanding language.

Word2vec includes two models, CBOW and Skip-gram, which predict the center word based on context and predict the context based on the center word, simplifying the grid structure. It uses Hierarchical Softmax and Negative Sampling algorithms to enhance training efficiency and optimize word vectors and semantic capabilities.
When conveying words, dialogues, or concepts to machines, the different ways of language use and context are inextricably linked. Therefore, to resolve machines’ confusion over ambiguous words, metaphors, etc., and to construct a cognitive system for machines about the world, data and models are particularly important in this framework.
When words can be input as coordinates, it significantly enhances the performance of neural networks in NLP. Although RNN language models can also obtain distributed representations of words, to better cope with the increase in vocabulary and improve the quality of distributed representations, Word2vec quickly became mainstream.
Transformer and Bert:
A Transformation from Theory to Practice
Now let’s pull the timeline back to within 5 years—
In 2017, the Google team first proposed the Transformer architecture in the paper “Attention is All You Need,” which initiated a fundamental change in NLP research.
In the era of deep learning, the improvement in natural language processing accuracy brought about a high dependency on labeled data for models. Due to data scarcity and high human costs, training large NLP language models has hit a bottleneck.
The Transformer pre-training model is primarily divided into two training phases: first, an initial model is pre-trained on a large-scale unlabeled corpus, then fine-tuned with labeled data for downstream tasks. Relatively speaking, pre-trained models are more efficient and require less labeled data.
Quickly, pre-trained language models became benchmark models in natural language understanding tasks.
GPT and BERT, the two models representing modern NLP technology development, are built on the Transformer architecture. The Google team summarized this language architecture with a single sentence: “Attention is All You Need.”
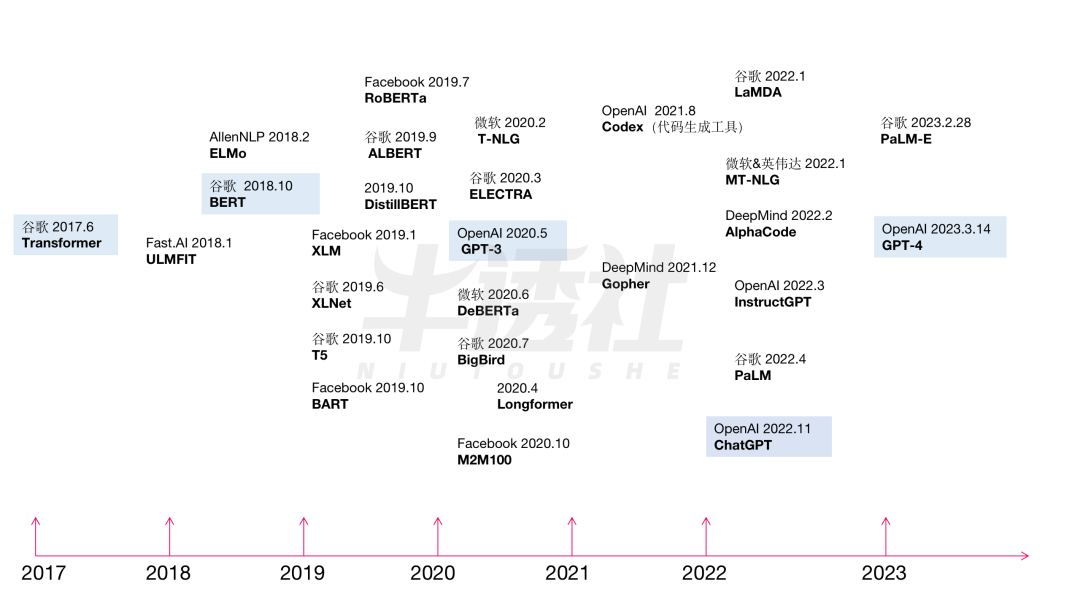
Summary of Important Models
In October 2018, Google released the BERT language model, marking the transformation of this technology from theory to practical application.
This was a celebration across the entire field of NLP, also signaling the strongest evolution in natural language processing history was about to begin.
In many past books researching AI, NLP, and AGI technologies, a term called “barrier of meaning” has been mentioned. There exists a communication gap between machines and humans, thus creating a capability for machines to understand human writing and speaking styles to assist humans is the original intention of NLP.
One of the abilities humans possess is the perception and reflection of their thinking patterns, that is, understanding surrounding situations in a profound way through phenomena. Machines do not have this understanding capability. The goal of NLP is to enable machines to be as intelligent as humans in understanding language, bridging the gap between human communication (natural language) and computer understanding (machine language) .
However, the evolution of language from symbolic representation to grammatical structure is a long process. Natural language is a “living” language, constantly evolving and growing. Many idioms have been phased out over time, while many new words have emerged. Based on this, developing natural language processing technology that can survive in this changing world becomes quite challenging.
Before BERT’s release, most NLP tasks were based on the basic architecture of word2vec+RNN. Due to data scarcity, NLP progress has not been as smooth as CV, leading some scholars to apply CV-based ideas to the pre-training+fine-tuning architecture, resulting in ELMo and GPT.
BERT innovated in two directions. It first proposed a two-stage model, with the first stage being a bidirectional language model pre-training, and the second stage being fine-tuning for specific tasks; secondly, the feature extractor became the Transformer.Almost all NLP tasks can adopt the two-stage training approach of BERT, hencein the following years, almost all companies began to improve based on BERT, marking the start of a turn in research directions.
Two Reasons Why GPT Did Not Appear in China
From a natural language perspective, natural language processing can be roughly divided into two parts: natural language understanding and natural language generation.
Natural Language Understanding: Enables computers to understand the meaning of text, the core is “understanding.”Specifically, it represents language as decomposable symbols or phonetics, extracting useful information for downstream tasks. Research directions include language structure, information extraction, information retrieval, part-of-speech tagging, and syntactic analysis.
Natural Language Generation: It generates natural language text, charts, audio, and video according to specific grammatical and semantic rules, that is, expressing semantic information in a human-readable form, in simple terms, from text planning to sentence planning to realization. It is divided into three main categories: text to text, text to other, and other to text.
TakingBERT and GPT as examples, even though both belong to pre-trained models, there exists a divergence in their technical development directions:
(Bidirectional Encoder Representations from Transformers)
Bidirectional language model, which can utilize contextual information for prediction simultaneously, is the benchmark model in natural language understanding tasks. It is composed of the Transformer’s Encoder module and adopts a pre-training and fine-tuning two-stage model training, belonging to semi-supervised learning models. In pre-training, it uses a large amount of unlabeled data, which is self-supervised training, while fine-tuning employs a small amount of labeled data, which is supervised training.
BERT’s pre-training includes Masked Language Model (MLM) and Next Sentence Prediction (NSP) tasks, introducing self-coding-based pre-training tasks.
This training approach allows BERT to effectively capture semantic information in text, thus being widely used for text classification tasks such as machine translation, sentiment analysis, spam detection, news classification, question answering systems, and semantic matching.
GPT(Generative Pre-Training)
Unidirectional language model, autoregressive language modeling approach, two-stage training: generative pre-training + discriminative task fine-tuning.
In the first stage, a language model based on deep Transformer is trained using large-scale data; in the second stage, domain adaptation is performed based on the characteristics of downstream tasks on the foundation of general semantic representation. Fine-tuning is usually conducted on a smaller dataset, allowing for smaller learning rates and fewer training iterations.
The unidirectional training approach can only utilize previous text for prediction, making it suitable for natural language generation, question answering systems, and machine translation tasks.
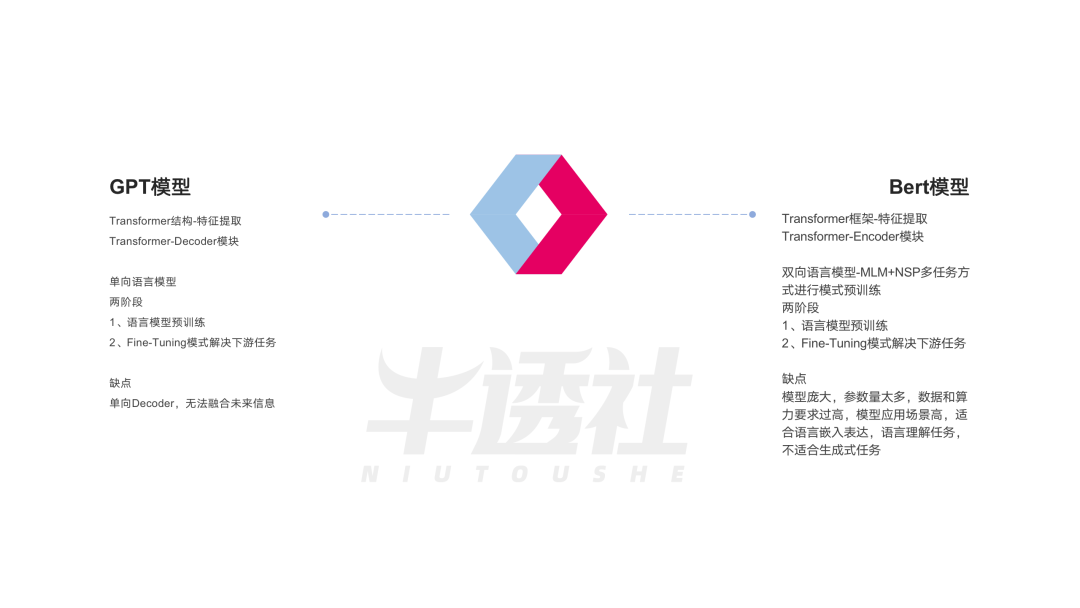
In terms of representation and expressive capabilities, the bidirectional language model (BERT) is more powerful than the unidirectional language model (GPT). Because in the unidirectional language model, it can only rely on preceding words and cannot obtain information from subsequent words, which may impact the model’s performance when handling complex natural language tasks due to insufficient contextual information capture. Conversely, the advantages of the bidirectional language model are evident.
However, BERT’s bidirectionality enhances its understanding capabilities but somewhat limits its generative capabilities, compared to unidirectional models that can generate continuations based solely on preceding context, bidirectional models are constrained in their generative abilities in the absence of subsequent context. Processing the entire sentence bidirectionally also means a larger model, longer training and inference times, and more computational resources and storage space. GPT is faster in terms of simplification, training, and inference speed, making it more suitable for scenarios with high real-time requirements.
Relative to GPT’s unidirectional language model, although BERT’s bidirectional language model has its downsides, it is more flexible and expressive in practical applications and easier to transfer and expand. In terms of model development, BERT focuses more on model reusability and universality, suitable for various natural language processing tasks.
In terms of development, BERT introduces the network structure of the Transformer Encoder for encoding input sequences; while GPT adopts the network structure of the Transformer Decoder for generating natural language text.
In terms of model complexity, BERT’s architecture is more complex than GPT’s. In terms of training, BERT requires further fine-tuning on custom data, which is more complex and cumbersome compared to GPT.
“Plum must yield to snow in whiteness, but snow cannot match plum in fragrance.” Overall, BERT and GPT each have their strengths, and their design and application direction differences determine their suitability for different application environments.

Within a year of BERT’s language model proposal, many models that extended its capabilities emerged, including XLNet, RoBERTa, ELECTRA, etc. Moreover, most NLP subfield development models have switched to: pre-training + application fine-tuning/application Zero, Few Shot Prompt modes.
Uses Transformer-XL instead of Transformer as the base model, XLNet proposes a new pre-training language task: Permutation Language Modeling, where the model scrambles the order of words within sentences, allowing for the utilization of bidirectional information when predicting current words. XLNet also uses a larger corpus than BERT.
RoBERTa adopts the same model structure as BERT and also uses the masked language model task for pre-training but discards the next sentence prediction model from BERT. In addition, RoBERTa employs a larger-scale dataset and more robust optimization methods, achieving better performance.
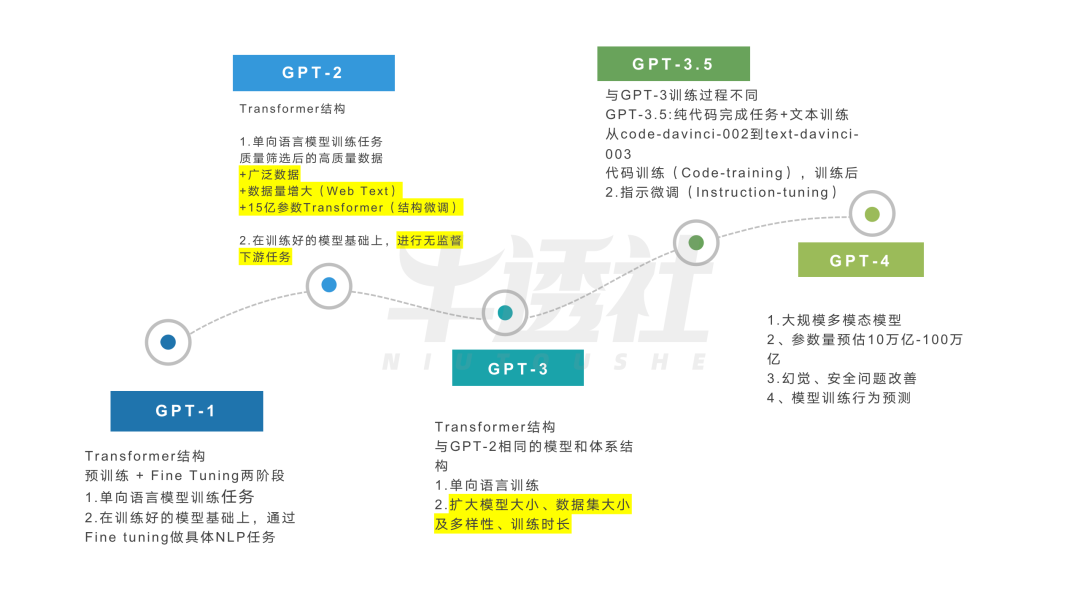
GPT has now released five generations, and since GPT-3, it has gradually widened the gap with BERT. In reality, it is not merely a specific technology but reflects differing development philosophies regarding LLM.
ChatGPT is derived from the generative pre-trained transformer, specifically GPT-3.5, which was fine-tuned after training on a mixed corpus of text and code, utilizing reinforcement learning from human feedback (RLHF) technology, which is a heuristic search-enhanced reinforcement learning that tightly integrates two purposes to solve complex search problems, currently one of the methods aligning large LLM with human intent.
In contrast, the history of natural language processing development shows that Google’s model upgrades have been ongoing, maintaining strong competitiveness, but DeepMind has consistently focused on reinforcement learning and AI technologies, with insufficient investment in generative model development.
In the past, GPT’s commercial scenarios were unclear, while BERT’s commercial trend was quite evident, thus semantic understanding accuracy has always been a focal point in the field’s development. Most domestic and foreign enterprises have also embarked on the BERT model route. Although Google responded quickly, releasing PaLM and Pathways in April 2022, racing to catch up with LLM technology, it still entered the field late.
According to incomplete statistics, there are currently 52 companies in China focusing on natural language processing, most of which are concentrated on the front end, including virtual humans, intelligent voice, translation, and RPA based on NLP technology, which are developing relatively advanced. The notion of technology-first and application-later seems less evident in China.
However, it is not just in China; even Google is lagging behind in LLM, which can only indicate that there are differences in previous development philosophies. Currently, companies like Baidu, Alibaba, Huawei, and iFlytek have potential in large language model development capabilities, with relative advantages in data and technological accumulation in China.
In developing new technologies, China often first considers commercial feasibility, which relates to the domestic entrepreneurial environment. Almost all fields, including pharmaceutical research and development, consider short-term gains, which is not conducive to the emergence of new technologies.
The key is to transition from the overall to the local, from application to fundamentals, focusing on computing power, chips, framework logic, and ideological awareness. The progress of technology is often determined by foundational strength; overtaking on curves is akin to pulling up seedlings to help them grow, which is unhelpful for core technological advancement.
Natural Language Processing: The Most Important Foundation for AGI
The emergence of GPT-4 has divided the natural language processing community into two factions: those who believe in AGI and those who do not.
Entering the era of large models, the paradigm shift has brought core changes to NLP, many independent subfields have been integrated into LLM, no longer existing independently, and the popularity of LLM is unprecedented.
On February 25, OpenAI’s Sam Altman shared his current and future plans for AGI on his blog, along with the risks of navigating AI.
His short-term plan is to use AI to help humans assess the outputs of more complex models and monitor complex systems; the long-term plan is to use AI to help propose new ideas for better alignment techniques. He believes that a misaligned AGI could cause serious harm to the world, and a despotic regime with decisive superintelligence leadership could do the same.
In a lengthy report released by Microsoft in March, they stated: “Given the breadth and depth of GPT-4’s capabilities, we believe it is reasonable to consider it an early (though still imperfect) version of a general artificial intelligence (AGI) system.”
However, they also acknowledged, “While GPT-4 ‘reaches or exceeds human levels on many tasks,’ its overall ‘intelligence pattern is clearly not human-like.’ Thus, generally speaking, even if it performs excellently, it still cannot think entirely like a human.”
Microsoft mentioned a term—“thinking.”
Many philosophers argue that even machines passing the Turing test do not actually think but merely simulate thinking.
Stanford University professor Christopher Manning proposed in 2017: So far, deep learning has significantly reduced error rates in speech and object recognition, but it has not achieved equivalent utility in high-level language processing tasks.
Human language often relies on common sense and understanding of the world. To enable machines to handle higher-level language tasks, they must fully understand human language and possess human-like common sense and unconscious behaviors. Current LLMs find it challenging to achieve this.
However, in the 1990s, inventor and futurist Ray Kurzweil discovered a pattern: once technology becomes digital or can be edited into computer code represented by 0s and 1s, it can break free from the constraints of Moore’s Law and begin to develop exponentially.
In simple terms, products developed after technological advancements will be used to accelerate the upgrade of products, creating a positive feedback loop. According to this theory, technological improvements build on past achievements, doubling the pace of innovation every decade.
Legend has it that Sita invented chess, which made the king very happy. He decided to reward Sita handsomely, but Sita said: “I do not want your heavy reward, Your Majesty, just place some wheat on my chessboard. Put 1 grain on the first square, 2 grains on the second square, 4 grains on the third square, 8 grains on the fourth square, and so on, with each square containing double the grains of the previous square until the 64th square is filled.” Just a small number of grains, what difficulty could that be? “Come, man,” the king ordered, and the counting of grains began. On the first square, 1 grain was placed, on the second square, 2 grains, on the third square, 4 grains, and… before reaching the twentieth square, one bag of wheat was already empty. One bag after another was carried before the king. However, the number of grains grew rapidly, and the king soon realized that even if he took out the entire country’s grain, he could not fulfill his promise to Sita.
The independent wave of exponential technology acceleration has begun to show a trend of merging with other independent waves of exponential technology acceleration. For example, the accelerated development of natural language processing technology is not solely due to NLP or LLM technologies but also because of the accelerating developments in AI, deep learning, neural networks, and other technologies converging into this domain.
In 2000, internet pioneer Tim Berners-Lee proposed the concept of the “semantic web.” He hoped to establish an intelligent internet based on “ontologies” with semantic characteristics that could not only understand semantic concepts but also the logic between them. Breaking through the limitations of single sentences, processing and generating results based on the semantic and contextual changes during the entire dynamic interaction process of user inputs is fundamental to realizing the semantic web.
The normal development logic is to first solve semantic expression issues, allowing computers to utilize their accumulated experience and understanding of existing information to reach deeper levels. This also means that in the AI era, semantic processing will become the core of operating systems, and all software technologies will establish their upper limits based on advancements in semantic technology.
The progress of language processing is currently mainly constructed through the complementarity and changes of big data, model frameworks, and training modes. Data carries ambiguity. In the LLM era, data has become a crucial core. When machines convey words, dialogues, or concepts, the usage environment and method can influence the final result. Therefore, to eliminate machines’ confusion over ambiguous words, metaphors, etc., and to build a cognitive system for machines about the world, humans are particularly important in this framework.
[1] AI 3.0 by Melanie Mitchell
[2] The Ultimate Science: A Discussion on Artificial Intelligence by the Collective Wisdom Club
[3] Natural Language Processing and Computational Linguistics by Bagaf Srinivasa Desikan
[4] Practical Natural Language Processing: Pre-trained Model Applications and Productization by Anku A. Patel Ajay Upili Alasanipale
[5] Practical Natural Language Processing by Hobson Ryan Cole Howard Hanas Max Harpke
[6] Future Apprentices: Understanding the Era of Accelerating Artificial Intelligence by Brain Extreme
[7] Computer Models of Natural Language Communication by Roland Hauser
[8] Advanced Deep Learning: Natural Language Processing by Saito Yasuki
[9] Deep Insights: 2018 NLP Application and Commercialization Survey Report
[10] The Road to AGI: Essentials of Large Language Model (LLM) Technology
[11] Artificial Intelligence Development Report 2011-2020