

Today, Microsoft released the Phi3 model, which achieves results comparable to Mixtral-8x7B with a compact size of 3.8B, causing quite a stir in the community.
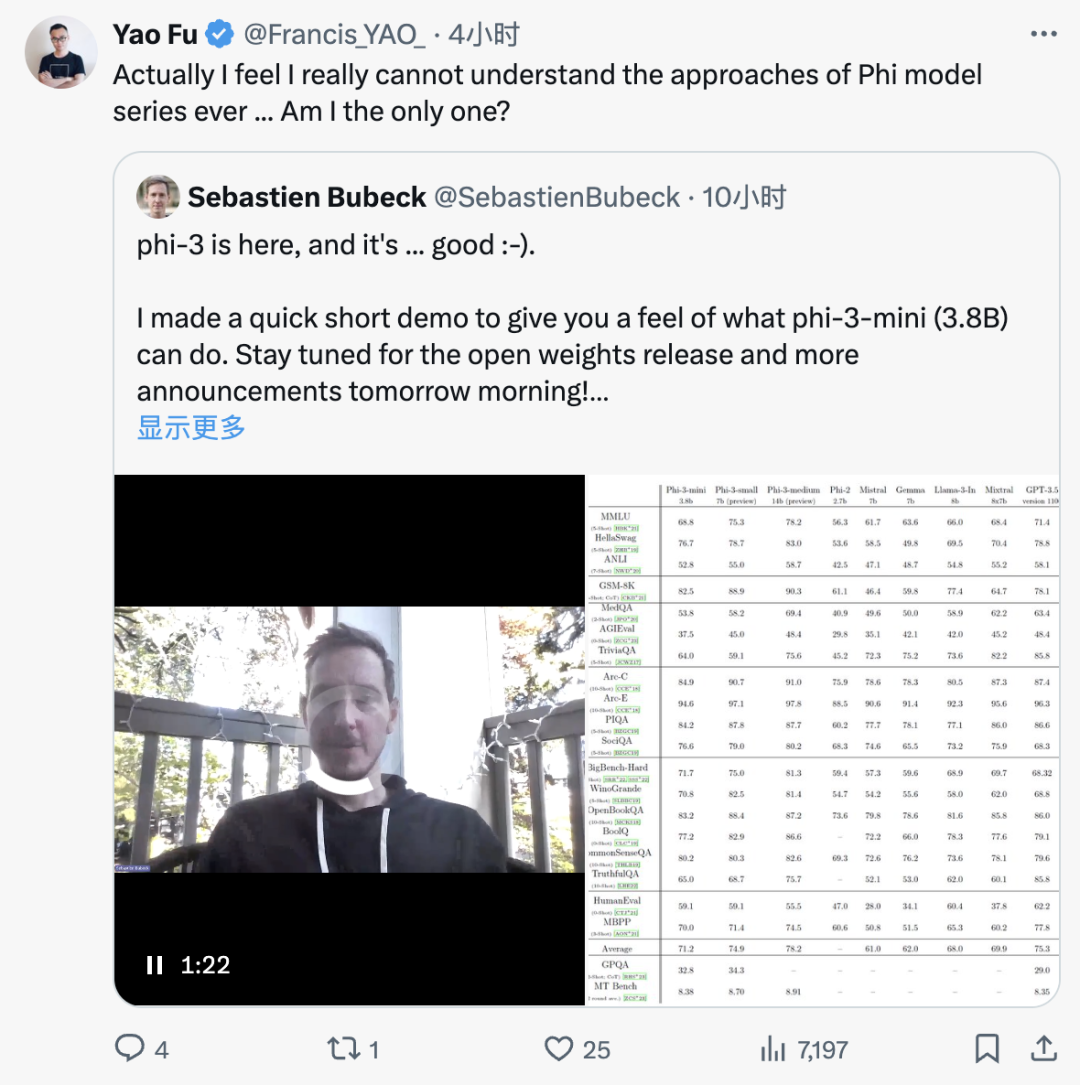
A while ago, I tried to finetune the Phi2 model, and to be honest, the results were not very ideal. The default context length of only 2k made it difficult to handle many generative tasks. The newly released Phi3 has a context length of 4k, and there’s even a long context version of 128k, at least addressing this shortcoming. The Phi family has always been quite unique in the LLM field, so today I took the opportunity to outline their development trajectory.
Let’s take a look back and summarize the key points of the latest Phi3 released today. Phi-3 Technical Report: A Highly Capable Language Model Locally on Your Phone[1] highlights include:
-
The model sizes include 3.8B, 7B, and 14B, with 3.8B already performing well. Quantized, it achieves 1.8G on iPhone16, generating 20 tokens per second. -
Trained on 3.3T tokens, with larger models using 4.5T, which is significantly less than Llama3’s 15T. -
Training occurs in two phases. The first phase utilizes high-quality web data, and the second phase employs a filtered subset along with GPT-synthesized data. The first phase focuses on language capabilities and common sense, while the second phase emphasizes logical reasoning abilities. -
In addition to the language model, versions for SFT+DPO were also released.
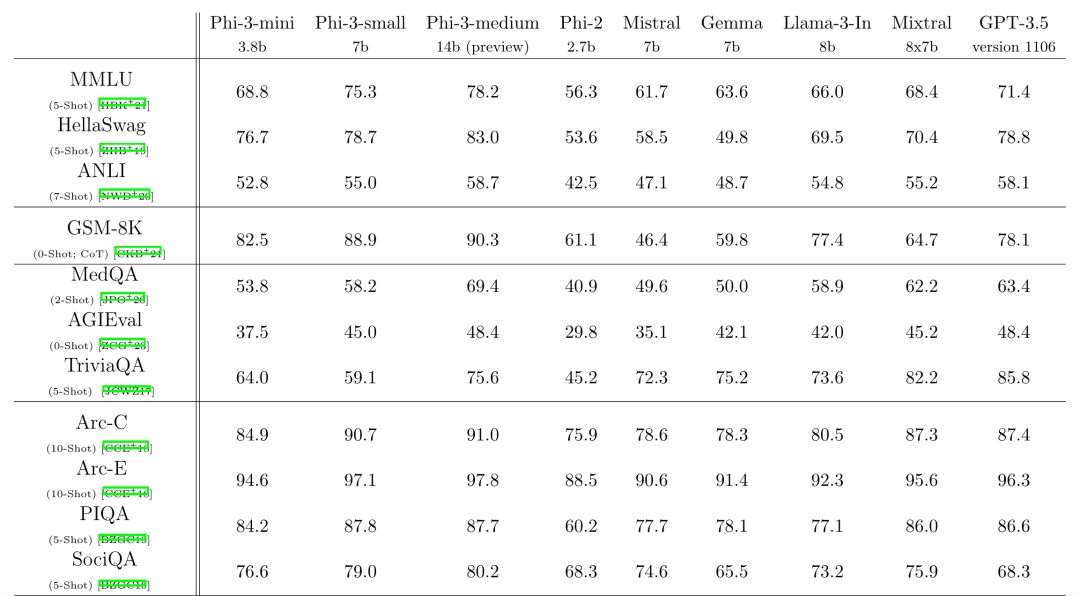
Phi2 was released in December 2023, with only a 2.7B version and no corresponding technical report. From the Model Card[2], it can be seen that its training followed the path of Phi1.5, adding a new data source. This new data source includes filtered web content and a large amount of NLP synthesized text.
Phi-1.5 was released in September 2023, with the technical report titled Textbooks Are All You Need II: phi-1.5 technical report[3]. Phi1.5 actually has two versions, as shown in the image below, where the web version includes synthesized data and additional web data. The total data volume is not large, only 30B and 100B, relying on multiple training rounds to increase the token count. The non-web version contains only 6B tokens of code data that is not synthesized.

The report contains a statement:
We remark that the experience gained in the process of creating the training data for both phi-1 and phi-1.5 leads us to the conclusion that the creation of a robust and comprehensive dataset demands more than raw computational power: It requires intricate iterations, strategic topic selection, and a deep understanding of knowledge gaps to ensure quality and diversity of the data. We speculate that the creation of synthetic datasets will become, in the near future, an important technical skill and a central topic of research in AI.
Translated into Chinese, this essentially captures the essence of the Phi series work.
我们注意到,在创建phi-1和phi-1.5的训练数据过程中获得的经验使我们得出结论:创建一个健壮且全面的数据集需要的不仅仅是原始的计算能力:它需要复杂的迭代过程、战略性的主题选择,以及对知识空缺的深刻理解,以确保数据的质量和多样性。我们推测,创建合成数据集在不久的将来将成为一个重要的技术技能和人工智能研究中的一个核心话题。
Phi1.5 also created a web-only model, which was trained solely on web data. This web data was primarily filtered from the Falcon dataset. The results are quite interesting; even though only a subset of the Falcon dataset was used, the performance was better than Falcon, and the synthesized data version outperformed the web-only version. The model using both high-quality web data and synthesized data performed the best.
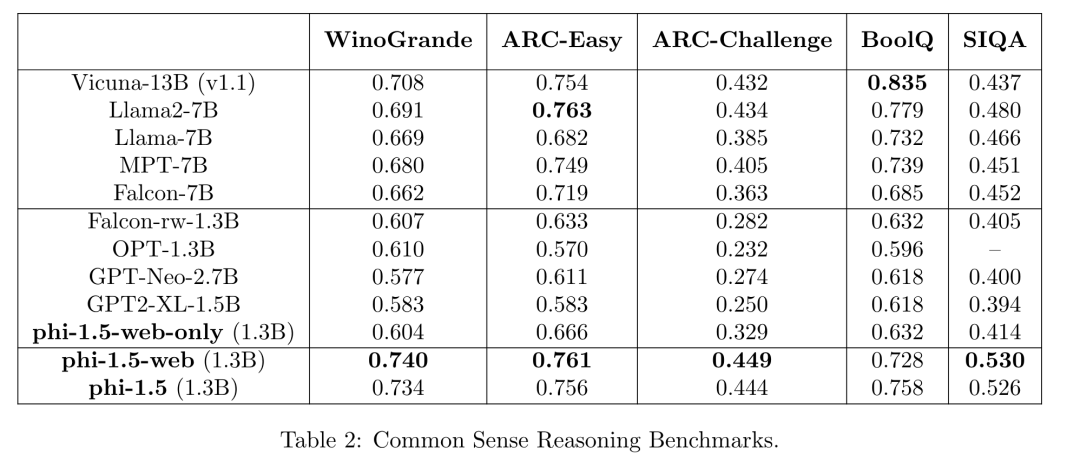
Looking further back, we see Phi1, released in June 2023. The technical report is titled Textbooks Are All You Need[4]. The Phi1 model has 1.3B parameters, and can be trained in 4 days using 8 A100 GPUs. This model is entirely code-focused, trained on 6B tokens of heavily cleaned web data and 1B tokens of synthesized data generated by GPT-3.5.
The data cleaning process involved using GPT4 to label the quality of a small portion of the data, then training a classifier with this data to evaluate the quality on a large scale. The generated data mainly consists of coding tutorials, with a small portion dedicated to programming exercises. The paper emphasizes that although the token count of programming exercises is not large, they are crucial for improving model performance.
From the perspective of the four generations of Phi models, the first noticeable observation is that the technical reports have become increasingly vague. Only 1 and 1.5 clearly explain how data was created. The third report does not detail how the data was created, only indicating that the data volume has increased compared to previous versions. A summary provides a clearer picture:
-
Phi-1.5-web is trained on 1.3B + 100B tokens, with approximately 70B being web data, achieving an MMLU of 37.9; -
Phi-2 is an expansion of 1.5, with 2.7B but not specifying how many tokens were used for training, achieving an MMLU of 56.3; -
Phi-3’s token count has reached 3.3T, which is a 33-fold increase compared to last year’s 1.5, with a model size of 3.8B. MMLU has reached 68.8.
Thus, while emphasizing data quality, the volume of data is also crucial. Of course, the size of the model is also a key factor in scoring.
Now, the model architecture is no longer a secret; data is the only moat. Various teams are digging in the vast garden of the internet to see who can gather more high-quality data. Today, I read an article stating that there isn’t much left to mine, so it’s expected that the progress of models will slow down in the future. After exhausting the internet, it seems we will witness another wave of digitization, turning the physical content still lying in libraries into training data.
This is a brief overview of the Phi series models.
Phi-3 Technical Report: A Highly Capable Language Model Locally on Your Phone: http://arxiv.org/abs/2404.14219
[2]Phi-2: https://huggingface.co/microsoft/phi-2
[3]Textbooks Are All You Need II: phi-1.5 technical report: http://arxiv.org/abs/2309.05463
[4]Textbooks Are All You Need: http://arxiv.org/abs/2306.11644
To join the technical exchange group, please add the AINLP assistant on WeChat (id: ainlp2)
Please specify your specific direction and the related technical points.
About AINLP
AINLP is an interesting and AI-focused natural language processing community, specializing in sharing technologies related to AI, NLP, machine learning, deep learning, recommendation algorithms, etc. Topics include LLM, pre-trained models, automatic generation, text summarization, intelligent Q&A, chatbots, machine translation, knowledge graphs, recommendation systems, computational advertising, recruitment information, job experience sharing, etc. We welcome your interest! To join the technical exchange group, please add the AINLP assistant on WeChat (id: ainlp2), specifying your work/research direction and the purpose of joining the group.