
Source: DeepHub IMBA
This article is approximately 2600 words long and is recommended to be read in 8 minutes.
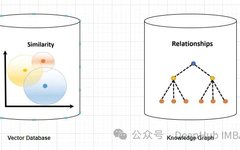
For hallucinations in large language models (LLM), knowledge graphs have proven to be superior to vector databases.
Vector Databases and Knowledge Graphs
Vector Databases
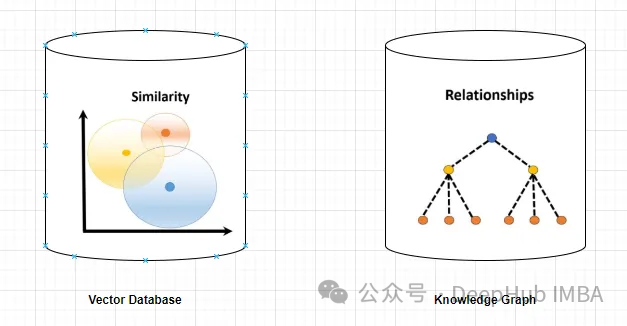
A vector database is a collection of high-dimensional vectors representing entities or concepts (such as words, phrases, or documents). The database can be used to measure the similarity or relevance between different entities or concepts based on their vector representations.
For example, a vector database can tell you that “Paris” and “France” are more related than “Paris” and “Germany” based on the vector distance.
Querying a vector database typically involves searching for similar vectors or retrieving vectors based on specific criteria. Here’s a simple example of how to query a vector database:
Let’s assume there is a vector database containing customer profiles represented by high-dimensional vectors, and you want to find customers similar to a given reference customer.
1. First, define a vector representation for the reference customer. This can be achieved by extracting relevant features or attributes and converting them into vector format.
2. Use an appropriate algorithm, such as k-nearest neighbors (k-NN) or cosine similarity, to perform a similarity search in the vector database. The algorithm will identify the nearest neighbors based on the similarity scores of the reference customer vector.
3. Retrieve the customer profiles corresponding to the nearest neighbor vectors identified in the previous step. These profiles will represent customers similar to the reference customer based on the defined similarity metrics.
4. Display the retrieved customer profiles or relevant information to the user, such as their names, demographics, or purchase history.
Knowledge Graphs
A knowledge graph is a collection of nodes and edges representing entities or concepts and their relationships (such as facts, attributes, or categories). Based on their node and edge attributes, they can be used to query or infer factual information about different entities or concepts.
For example, a knowledge graph can tell you that “Paris” is the capital of “France” based on edge labels.
Querying a graph database involves traversing the graph structure and retrieving nodes, relationships, or patterns based on specific criteria.
Assuming you have a graph database representing a social network, where users are nodes and their relationships are represented as edges connecting those nodes. If you want to find friends of friends for a given user, you would do the following:
1. Identify the node representing the reference user in the graph database. This can be done by querying for a specific user identifier or other relevant criteria.
2. Use a graph query language, such as Cypher (used in Neo4j) or Gremlin, to traverse the graph from the reference user node. Specify the patterns or relationships to explore.
MATCH (:User {userId: ‘referenceUser’})-[:FRIEND]->()-[:FRIEND]->(fof:User)
RETURN fof
This query starts from the reference user, finds another node (FRIEND) along the FRIEND relationship, and then finds friends of friends (fof) along another FRIEND relationship.
3. Execute the query on the graph database to retrieve result nodes (friends of friends) based on the query pattern, which may yield specific attributes or other information about the retrieved nodes.
Graph databases can offer more advanced querying capabilities, including filtering, aggregation, and complex pattern matching. The specific query language and syntax may vary, but the general process involves traversing the graph structure to retrieve nodes and relationships that meet the desired criteria.
Advantages of Knowledge Graphs in Solving the Hallucination Problem
Knowledge graphs provide more precise and specific information than vector databases. While vector databases represent similarity or relevance between two entities or concepts, knowledge graphs can better understand the relationships among them. For example, a knowledge graph can tell you that the “Eiffel Tower” is a landmark in “Paris,” while a vector database can only indicate the degree of similarity between these two concepts without specifying how they are related.
Knowledge graphs can handle more diverse and complex queries than vector databases. Vector databases primarily answer queries based on vector distance, similarity, or nearest neighbors, which are limited to direct similarity measurements. In contrast, knowledge graphs can handle queries based on logical operators, such as “What are all entities with attribute Z?” or “What is the common category of W and V?” This can help LLMs generate more diverse and interesting texts.
Knowledge graphs are better at reasoning and inference than vector databases. Vector databases can only provide direct information stored in the database. In contrast, knowledge graphs can provide indirect information derived from the relationships between entities or concepts. For example, a knowledge graph can infer that “the Eiffel Tower is in Europe” based on the facts that “Paris is the capital of France” and “France is located in Europe.” This can help LLMs generate more logical and coherent text.
Thus, knowledge graphs are a better solution than vector databases. They provide LLMs with more accurate, relevant, diverse, interesting, logical, and consistent information, enabling them to generate accurate and truthful texts more reliably. However, the key here is that there needs to be a clear relationship between the documents; otherwise, the knowledge graph will not capture it.
However, the use of knowledge graphs is not as straightforward as vector databases; not only is there less convenience in content organization (data), application deployment, and query generation, but this also affects their frequency of use in practical applications. Therefore, we will use a simple example below to introduce how to build RAG using knowledge graphs.
Code Implementation
We need to use three main tools/components:
1. LlamaIndex is an orchestration framework that simplifies the integration of private data with public data. It provides tools for data ingestion, indexing, and querying, making it a universal solution for generative AI needs.
2. An embedding model converts text into a numerical representation of the information provided by the text. This representation captures the semantic meaning of the embedded content, making it robust for many industry applications. Here, we use the “thenlper/gte-large” model.
3. A large language model is needed to generate responses based on the provided questions and context. Here, we use the Zephyr 7B beta model.
Now, let’s start coding by first installing the packages:
%%capture pip install llama_index pyvis Ipython langchain pypdf
import logging import sys # logging.basicConfig(stream=sys.stdout, level=logging.INFO) logging.getLogger().addHandler(logging.StreamHandler(stream=sys.stdout))
from llama_index import (SimpleDirectoryReader, LLMPredictor, ServiceContext, KnowledgeGraphIndex) # from llama_index.graph_stores import SimpleGraphStore from llama_index.storage.storage_context import StorageContext from llama_index.llms import HuggingFaceInferenceAPI from langchain.embeddings import HuggingFaceInferenceAPIEmbeddings from llama_index.embeddings import LangchainEmbedding from pyvis.network import Network
HF_TOKEN = "api key DEEPHUB 123456" llm = HuggingFaceInferenceAPI( model_name="HuggingFaceH4/zephyr-7b-beta", token=HF_TOKEN )
embed_model = LangchainEmbedding( HuggingFaceInferenceAPIEmbeddings(api_key=HF_TOKEN,model_name="thenlper/gte-large") )
documents = SimpleDirectoryReader("/content/Documents").load_data() print(len(documents))
####Output### 44
#setup the service context service_context = ServiceContext.from_defaults( chunk_size=256, llm=llm, embed_model=embed_model ) #setup the storage context graph_store = SimpleGraphStore() storage_context = StorageContext.from_defaults(graph_store=graph_store) #Construct the Knowledge Graph Index index = KnowledgeGraphIndex.from_documents( documents=documents, max_triplets_per_chunk=3, service_context=service_context, storage_context=storage_context, include_embeddings=True)
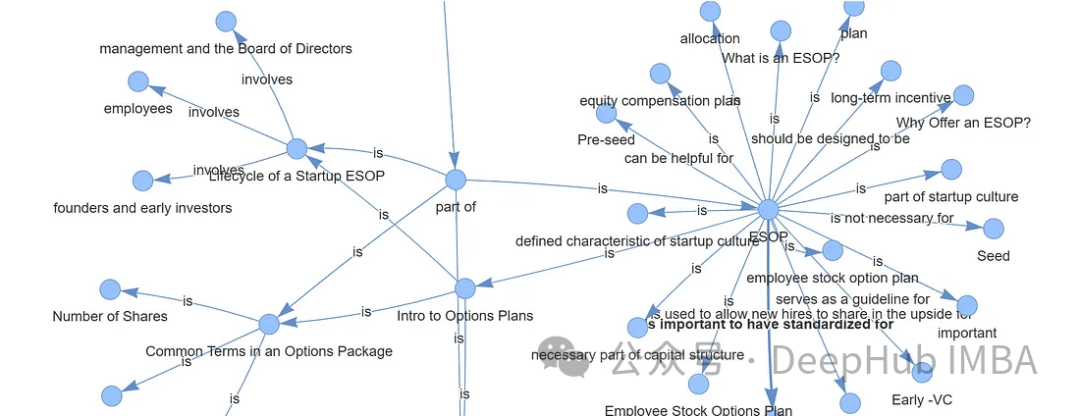
query = "What is ESOP?" query_engine = index.as_query_engine(include_text=True, response_mode ="tree_summarize", embedding_mode="hybrid", similarity_top_k=5,) # message_template =f"""<|system|>Please check if the following pieces of context has any mention of the keywords provided in the Question.If not then don't know the answer, just say that you don't know.Stop there.Please donot try to make up an answer.</s> <|user|> Question: {query} Helpful Answer: </s>""" # response = query_engine.query(message_template) # print(response.response.split("<|assistant|>")[-1].strip()) #####OUTPUT ##################### ESOP stands for Employee Stock Ownership Plan. It is a retirement plan that allows employees to receive company stock or stock options as part of their compensation. In simpler terms, it is a plan that allows employees to own a portion of the company they work for. This can be a motivating factor for employees as they have a direct stake in the company's success. ESOPs can also be a tax-efficient way for companies to provide retirement benefits to their employees.
from pyvis.network import Network from IPython.display import display g = index.get_networkx_graph() net = Network(notebook=True,cdn_resources="in_line",directed=True) net.from_nx(g) net.show("graph.html") net.save_graph("Knowledge_graph.html") # import IPython IPython.display.HTML(filename="/content/Knowledge_graph.html")
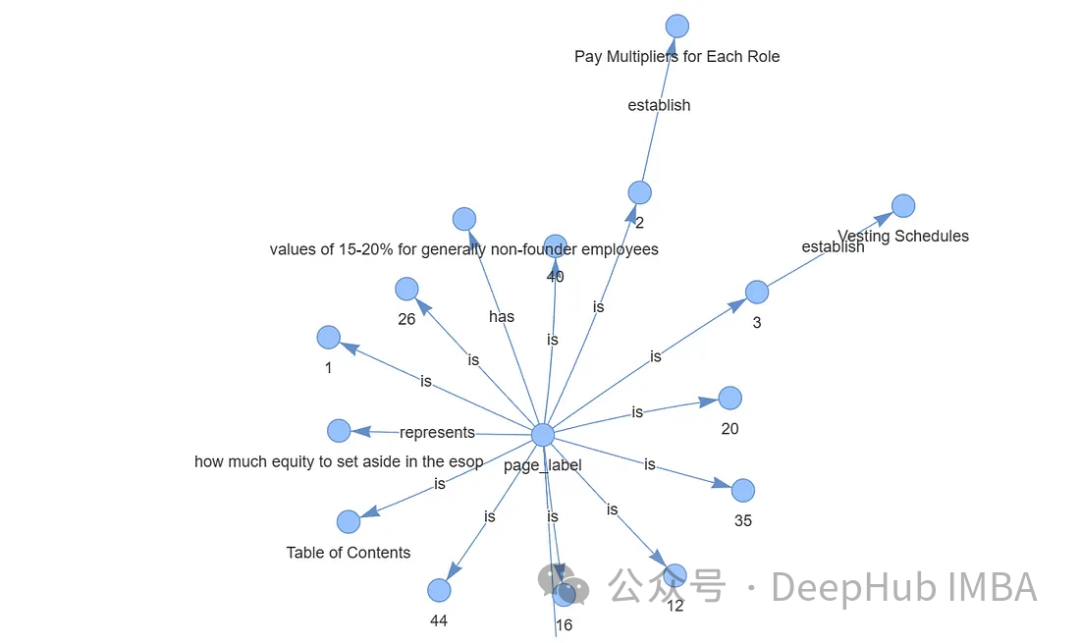

storage_context.persist()

Conclusion
The difference between vector databases and knowledge graphs lies in how they store and represent data. Vector databases excel at operations based on similarity, relying on numerical vectors to measure distances between entities. Knowledge graphs capture complex relationships and dependencies through nodes and edges, facilitating semantic analysis and advanced reasoning.
For hallucinations in large language models (LLMs), knowledge graphs have proven to be superior to vector databases. Knowledge graphs provide more accurate, diverse, interesting, logical, and consistent information, reducing the likelihood of LLM hallucinations. This advantage stems from their ability to provide precise details about relationships between entities rather than merely indicating similarity, thus supporting more complex queries and logical reasoning.
Previously, the challenge with knowledge graph applications was the construction of the graph, but now the emergence of LLMs has simplified this process, making it easy to build usable knowledge graphs, which is a significant step forward in its application. For RAG, knowledge graphs are a very good application direction.
Editor: Huang Jiyan
