
Recently, Retrieval-Augmented Generation (RAG) has garnered widespread attention in the AI field, becoming a focal point of discussion among many researchers and developers. As a technology that combines retrieval with generation, RAG demonstrates the potential to achieve outstanding results in various tasks such as question answering, dialogue generation, and text summarization. Its emergence provides a new perspective for solving complex problems, making artificial intelligence more precise and efficient in understanding and responding to user needs. The significance of RAG cannot be overlooked, as it brings innovative ideas and breakthroughs to the AI field. An increasing number of researchers and developers are beginning to focus on and invest in the research and application of RAG, aiming to achieve higher levels of performance in future intelligent dialogue systems.
For example, OpenAI has integrated web browsing options into GPT-4, Tencent has incorporated RAG technology into the practical application scenarios of its Hunyuan model, Baichuan is actively using RAG technology to build large models in vertical fields, and Baidu AI dialogue has also integrated search engine results based on Baidu’s knowledge-enhanced large language model, Wenxin Yiyan. Therefore, the popularity and important status of RAG have become deeply ingrained, indicating that it will continue to play a key role in the AI field.
In response to the booming interest in RAG, Professor Cui Bin from Peking University leads the Data and Intelligence Laboratory (PKU-DAIR) to conduct a systematic survey of existing RAG technologies, covering nearly 300 relevant papers and publishing a review titled “Retrieval-Augmented Generation for AI-Generated Content: A Survey.”
The article provides a detailed introduction to the components of retrieval-augmented technology (RAG) in the context of AI-generated content (AIGC), the methods of combining different components, and the optimization techniques for RAG systems. Additionally, the article summarizes the specific applications of RAG across various fields and modalities, including text, images, code, audio, video, and 3D, as well as the existing evaluation standards or tools for RAG systems. Finally, this paper also analyzes and discusses the current limitations of RAG and future trends and directions for development.
Recently, Retrieval-Augmented Generation (RAG) has garnered widespread attention in the AI field, becoming a focal point of discussion among many researchers and developers. As a technology that combines retrieval with generation, RAG demonstrates the potential to achieve outstanding results in various tasks such as question answering, dialogue generation, and text summarization. Its emergence provides a new perspective for solving complex problems, making artificial intelligence more precise and efficient in understanding and responding to user needs. The significance of RAG cannot be overlooked, as it brings innovative ideas and breakthroughs to the AI field. An increasing number of researchers and developers are beginning to focus on and invest in the research and application of RAG, aiming to achieve higher levels of performance in future intelligent dialogue systems.
For example, OpenAI has integrated web browsing options into GPT-4, Tencent has incorporated RAG technology into the practical application scenarios of its Hunyuan model, Baichuan is actively using RAG technology to build large models in vertical fields, and Baidu AI dialogue has also integrated search engine results based on Baidu’s knowledge-enhanced large language model, Wenxin Yiyan. Therefore, the popularity and important status of RAG have become deeply ingrained, indicating that it will continue to play a key role in the AI field.
In response to the booming interest in RAG, Professor Cui Bin from Peking University leads the Data and Intelligence Laboratory (PKU-DAIR) to conduct a systematic survey of existing RAG technologies, covering nearly 300 relevant papers and publishing a review titled “Retrieval-Augmented Generation for AI-Generated Content: A Survey.”
The article provides a detailed introduction to the components of retrieval-augmented technology (RAG) in the context of AI-generated content (AIGC), the methods of combining different components, and the optimization techniques for RAG systems. Additionally, the article summarizes the specific applications of RAG across various fields and modalities, including text, images, code, audio, video, and 3D, as well as the existing evaluation standards or tools for RAG systems. Finally, this paper also analyzes and discusses the current limitations of RAG and future trends and directions for development.

Paper Title:
Retrieval-Augmented Generation for AI-Generated Content: A Survey
Article Link:
https://arxiv.org/abs/2402.19473
Code Link:
https://github.com/hymie122/RAG-Survey
1. Introduction
In recent years, the attention to AIGC has continued to rise, with large generative models demonstrating remarkable results in various fields and modalities, such as the GPT series and LLAMA series models in the text and code domains, DALL-E and Stable Diffusion models in the image domain, and the Sora model behind text-to-video generation. Although these powerful generators can produce stunning effects, there remain a series of significant problems and challenges, such as difficulties in updating and maintaining knowledge, challenges in mastering long-tail knowledge, and the risk of leaking private training data.
To address these issues, Retrieval-Augmented Generation (RAG) technology has emerged. It utilizes Information Retrieval (IR) to accurately find relevant existing information from a vast array of external data. This externally stored data is easy to modify, can cover a broader range of long-tail knowledge, and supports sensitive data encoding. Additionally, in specific scenarios, RAG can provide support for long texts, reducing model costs and improving response speed.
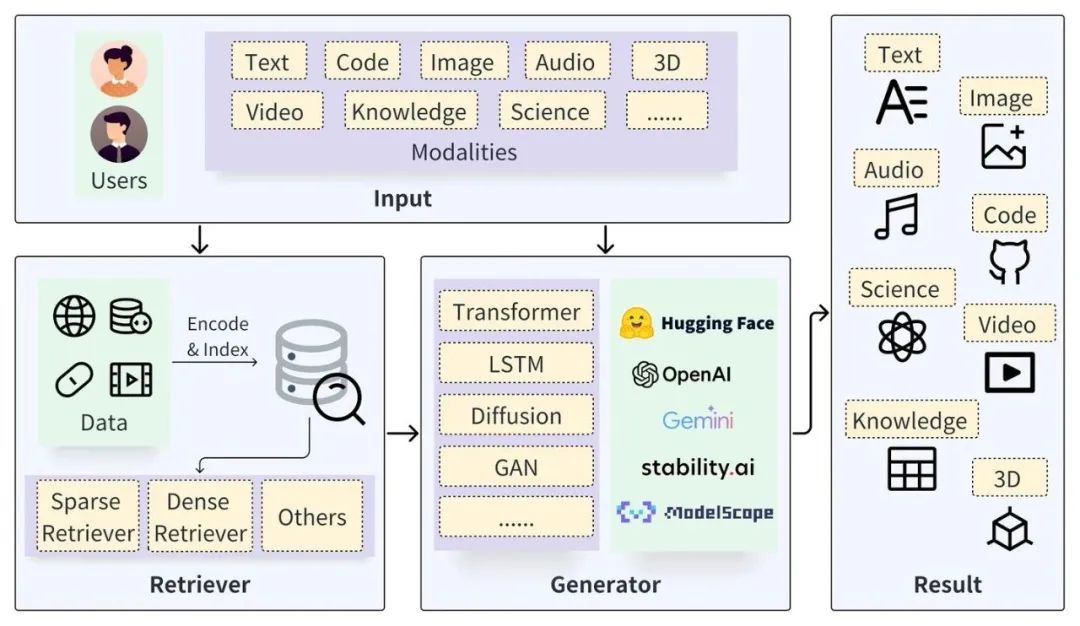
The general architecture of RAG. User queries can be of different modalities, serving as inputs for the retriever and generator. The retriever searches for relevant data sources in storage, while the generator interacts with the retrieval results to ultimately generate outputs in various modalities.
As shown in the figure above, a typical RAG process includes the following steps: first, when faced with an input query, the retriever locates and extracts relevant data sources. Next, these retrieved results interact with the generator to enhance the quality and relevance of the generated content. The retrieved information can interact with the generation process in various ways, which will be elaborated in subsequent sections.
Based on existing RAG systems, many works have proposed enhancement methods to improve the overall quality of the model, including methods targeting specific components and optimizations for the entire pipeline. Although the concept of RAG originally appeared in text generation, explorations of retrieval-augmented generation for other modalities and tasks have also emerged early on. RAG has now been applied in generative tasks across various fields, including code, audio, images, video, 3D, structured knowledge, and artificial intelligence science, among others.
Across different modalities and tasks, the fundamental ideas and processes of RAG remain largely consistent, while the specific retrievers and generators used vary according to the specific task requirements. This paper delves into the foundational methods of RAG, optimization strategies for specific RAG components and the entire system, practical application scenarios of RAG, methods for evaluating RAG performance, and the current limitations of RAG and future development directions.
2. Basic Methods of RAG
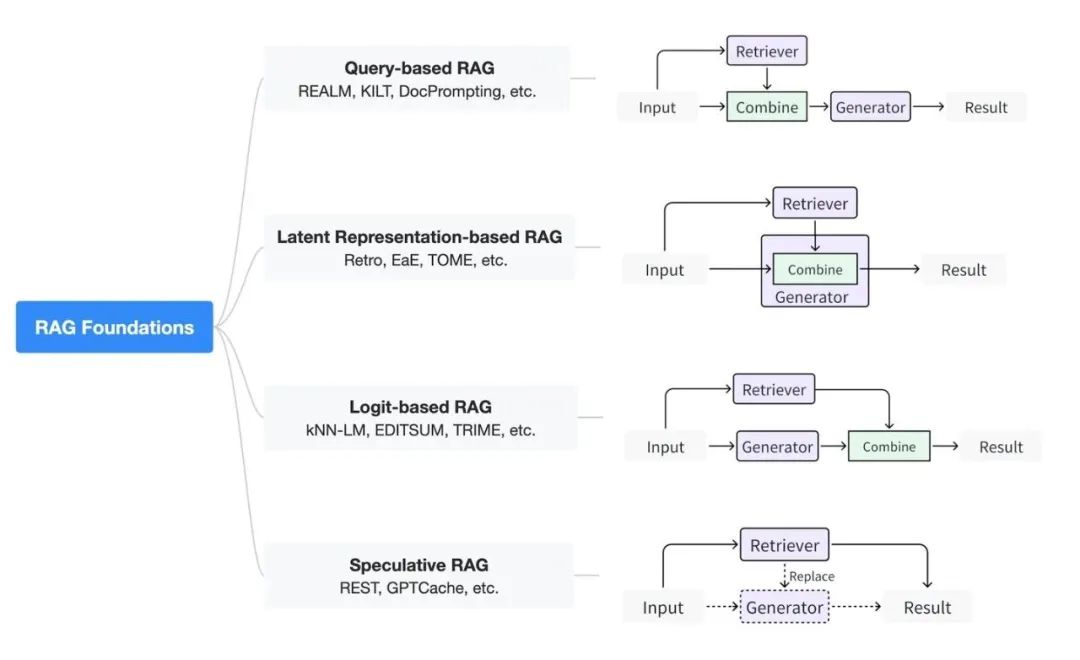
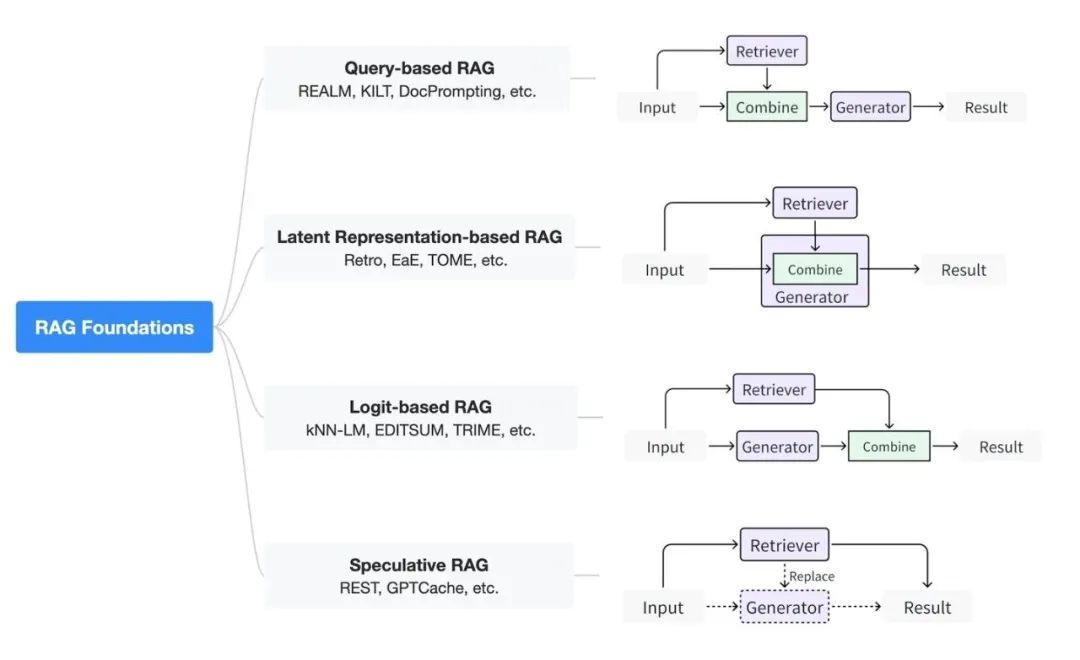
We classify the basic paradigms of RAG based on how the retriever interacts with the generator into four categories, as shown in the figure:
Classification of RAG Basic Methods
2.1 Query-Based RAG Methods
2.2 Latent Space Representation-Based RAG Methods
Latent space representation-based RAG methods: In this approach, the content obtained by the retriever interacts with the generation model internally in a latent representation manner. This interaction during generation can effectively enhance the understanding capabilities of the generation model and the quality of the generated content. Common interaction methods here include simple concatenation and the design of attention mechanisms, among others.
2.3 Probability Representation-Based RAG Methods
Probability representation-based RAG methods: In RAG systems employing probability representation (logit), the generation model utilizes probabilistic methods during the decoding phase to integrate the retrieved information. Typically, the model sums or merges the probability distributions of the retrieval results to compute the probabilities of generating text step by step. This method allows the model to weigh the relevance and credibility of different retrieval information when generating responses.
2.4 Speculative RAG Methods
Speculative RAG methods utilize the retrieval process to replace part or all of the generation process. This approach has significant application potential when the cost of the retriever is lower than that of the generator. For example, in speculative reasoning, retrieval can replace the generation of a small model, and then both the user query and the retrieved content are fed into a large model for validation. Moreover, in scenarios where a ChatGPT-like interface is used as the generator, the more calls made mean higher costs, so similar past questions can be searched to obtain direct answers.
3. RAG Enhancement Methods
Classification of RAG Enhancement Methods
Many works have employed a series of enhancement methods to improve the effectiveness of basic RAG systems. We classify existing methods based on their enhancement targets into five categories: enhancement of input, enhancement of the retrieval process, enhancement of the generation process, enhancement of results, and optimization of the entire RAG process.
3.1 Input Enhancement
Input refers to the user query, which is initially fed into the retriever. The quality of the input significantly impacts the final results of the retrieval phase, making input optimization crucial. Here, we will introduce two methods: query rewriting and data augmentation.
Query Rewriting can improve retrieval results by modifying the input query.Data Augmentation refers to the pre-improvement of data before retrieval, such as removing irrelevant information, eliminating ambiguities, updating outdated documents, synthesizing new data, etc., which can effectively enhance the performance of the final RAG system.
3.2 Retriever Enhancement
The retrieval process in RAG systems significantly impacts the results. Generally, the better the content quality, the more likely it is to stimulate the in-context learning capabilities of LLMs and other generative models; conversely, poor content quality is likely to lead to model hallucinations.
-
Recursive Retrieval is the process of splitting queries before retrieval and performing multiple searches to retrieve more and higher-quality content.
-
Chunk Optimization refers to adjusting the chunk size to achieve better retrieval results.
-
Fine-tuning the Retriever involves optimizing the retriever, typically enhancing the capabilities of the embedding model. The stronger the retriever’s capabilities, the more useful information it can provide to the subsequent generator, thereby improving the effectiveness of the RAG system. A good embedding model can tightly cluster semantically similar content in vector space; additionally, even for embedding models that already have good expressive capabilities, we can still fine-tune them using high-quality domain data or task-related data to enhance their performance in specific domains or tasks.
-
Hybrid Retrieval refers to using multiple types of retrievers simultaneously, such as using both statistical term frequency methods and vector similarity calculations to obtain retrieval results.
-
Re-ranking involves reordering the retrieved content to achieve greater diversity and better results.
-
Meta-data Filtering is another method for processing retrieved documents, using metadata (such as time, purpose, etc.) to filter the retrieved files for more suitable content.
3.3 Generator Enhancement
Generator enhancement: In RAG systems, the quality of the generator typically determines the quality of the final output. Here, we will introduce some techniques to enhance the generator’s capabilities.
-
Prompt Engineering is a technique focused on improving the output quality of LLMs, including prompt compression, fallback prompts, proactive prompts, chain-of-thought prompts, etc., all of which are also applicable in RAG systems using LLM generators.
-
Decoding Tuning refers to adding additional controls during the generator’s processing, which can be achieved by adjusting hyperparameters to achieve greater diversity or to restrict the output vocabulary in some manner.
-
Fine-tuning the Generator can enable the generation model to possess more precise domain knowledge or better matching capabilities with the retriever.
4. Applications of RAG
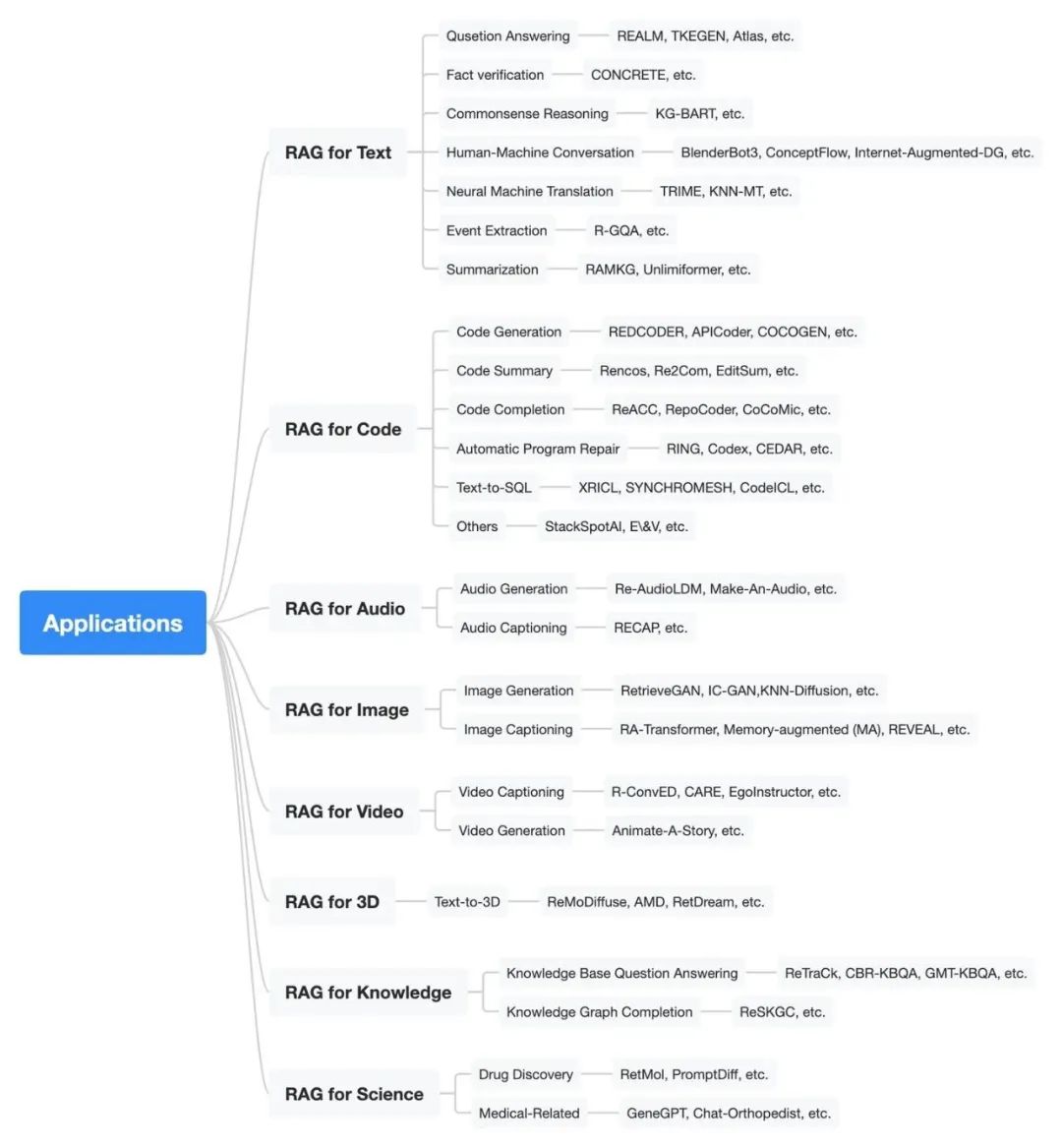
Classification of RAG Applications in Multi-modal, Multi-task Scenarios
As shown in the figure above, we introduce the specific applications of RAG in various modalities and tasks, including text, code, audio, images, video, 3D, structured knowledge, and AI4S, and analyze and interpret the methods used in each application category. For more detailed content, please refer to the original paper.
5. Benchmarking
The main evaluation criteria for RAG include fidelity, answer relevance, and contextual relevance. Fidelity measures the ability to infer correct answers from the retrieved content; answer relevance assesses whether the generated results address the question; contextual relevance determines whether the retrieved content contains sufficient knowledge to answer the query while minimizing irrelevant information.
6.1 Limitations
Despite the widespread adoption of RAG in various applications, there remain some limitations regarding effectiveness and efficiency.
Noise in Retrieval Results: Information retrieval systems inevitably suffer from information loss when encoding information into vectors. At the same time, Approximate Nearest Neighbor (ANN) searches can only provide approximate matches rather than exact matches, resulting in a certain degree of noise in the retrieval results, such as irrelevant or misleading information, which can negatively impact the output quality of RAG systems. While intuitively improving retrieval accuracy seems beneficial for enhancing RAG’s effectiveness, recent studies have surprisingly found that noisy retrieval results can sometimes enhance the quality of generated content. This may be because the diversity of retrieval results is beneficial to the generation process in certain situations. Therefore, the specific impact of noise on retrieval results remains an open question, which also raises discussions on how to choose appropriate retrieval metrics and how to optimize the interaction between the retriever and the generator. Future research is expected to provide clearer answers to these questions.
Additional Overhead: Although retrieval can reduce text generation costs in certain situations, combining retrieval with generation can sometimes introduce significant additional overhead. Given that the primary purpose of RAG is to enhance the capabilities of existing generation models, introducing additional retrieval and interaction steps may lead to processing delays. This is particularly pronounced when using more complex methods, such as recursive retrieval or iterative RAG. Furthermore, as the scale of retrieval increases, the complexity of data storage and access also rises. In current technical implementations, RAG systems need to balance cost and performance. In the future, we look forward to further system optimizations to reduce these additional overheads.
Complex Interactions Between Retrieval and Generation: To achieve seamless integration between the retrieval and generation components, researchers and engineers need to carefully design and optimize. Given that the retriever and generator may have different goals and may not operate in the same latent space, coordinating the interaction between these two components is a challenge. As previously mentioned, researchers have developed various foundational methods for RAG, which either separate the retrieval and generation processes or integrate them at an intermediate stage. While separation methods are more modular, integration methods may benefit from joint training. Currently, comparative studies of different interaction methods in various application scenarios are still insufficient. Moreover, the enhancement of RAG systems also faces challenges, including the interactions of metric selection and hyperparameter tuning, which have not been thoroughly studied. Therefore, to maximize the potential of RAG systems, further improvements in algorithm design and system deployment are necessary.
Challenges of Long Context Generation: One major challenge faced by early RAG systems was the context length limitation of the generator, which restricted the number and length of prompts they could handle. Although this issue has been somewhat alleviated with research advancements, such as prompt compression techniques and system optimizations for long contexts, these solutions often require trade-offs between accuracy and cost. Recently, there has been a viewpoint suggesting that long-context models like Gemini 1.5 may replace RAG. However, this perspective overlooks RAG’s flexibility advantage in handling dynamic information, especially the latest and long-tail knowledge. We believe that future RAG systems will leverage the ability to generate long contexts to enhance final performance rather than being replaced by new models.
6.2 Future Potential Research Directions
Exploring More Research on RAG Foundational Methods, Enhancement Methods, and Applications: Future research directions will focus on developing more advanced methods to enhance and apply RAG. Since the optimization goals of the retriever and generator differ, the actual enhancement process significantly impacts the generation results. By studying more advanced foundational and enhancement methods, the potential of RAG is expected to be fully explored and utilized.
More Efficient Operation and Deployment of RAG Systems: Currently, several query-based RAG deployment solutions for LLMs, such as LangChain and LLAMA-Index, exist. However, other types of RAG and generative tasks still lack ready-made solutions. Considering the additional overhead brought by retrieval and the increasing complexity of the retriever and generator, achieving efficient operation and deployment of RAG remains a challenge that requires dedicated system optimization.
Better Utilization of RAG Systems to Combine Long-Tail and Real-Time Knowledge: A key goal of RAG is to leverage real-time and long-tail knowledge, but how to update and expand the knowledge base has not been sufficiently researched. Many existing studies only consider the training data of the generator as the source for retrieval, overlooking the more flexible and dynamic advantages of retrieval information sources. Therefore, a promising research direction is to design a RAG system that can continuously update knowledge or utilize flexible knowledge sources, along with corresponding system optimizations. Given RAG’s ability to leverage long-tail knowledge, we look forward to it integrating personalized information and functionalities to better adapt to today’s web services.
Combining RAG Technology with Other Advanced AIGC Technologies: RAG technology is complementary to other techniques aimed at enhancing AIGC effectiveness (such as fine-tuning, reinforcement learning, chain-of-thought, agent-based generation, and other optimization methods). Current attempts to combine RAG with these technologies are still in the early stages, and we look forward to more research in the future to explore algorithm design and maximize the potential of these technologies.
Illustration From IconScout By Delesign Graphics

Scan to view!
This week new arrivals!

“AI Technology Flow” Original Submission Plan
TechBeat is an AI learning community established by Jiangmen Venture Capital (www.techbeat.net ). The community has launched over 500 talk videos and 3000 technical articles, covering areas such as CV/NLP/ML/Robotics, etc.; regularly hosting top conferences and other online exchange activities every month, and occasionally organizing offline gatherings for technical personnel. We are striving to become a high-quality, knowledge-based communication platform favored by AI talents, aiming to provide more professional services and experiences for AI talents and accelerate and accompany their growth.
Submission Content
// Latest Technology Interpretation/Systematic Knowledge Sharing //
// Cutting-edge Information Commentary/Experiences Sharing //
Submission Guidelines
Submissions must be original articles and must indicate the author’s information.
We will select some articles that provide greater insights into deep technical analysis and research experiences for originality content rewards.
Submission Method
Email to
or add staff WeChat (chemn493) to submit and discuss submission details; you can also follow the “Jiangmen Venture Capital” public account and reply “Submit” to get submission instructions.

>>> Add the editor on WeChat!

