Every day we bring you NLP technology insights!
Introduction
Entity Relation Extraction is a core task of text mining and information extraction. It mainly models text information to automatically extract semantic relationships between entity pairs, thereby extracting valid semantic knowledge. The research results are mainly applied in text summarization, automatic question answering, machine translation, semantic web annotation, and knowledge graphs.
1. Introduction to Relation Extraction Tasks
Entity Relation Extraction is an important task of information extraction, which refers to extracting predefined entity relationships from unstructured text based on entity recognition. The relationship between entity pairs can be formalized as a relation triplet 〈e1,r,e2〉, where e1 and e2 are entities, and r belongs to the target relation set R{r1,r2, r3,…,ri}. The task of relation extraction is to extract relation triplets 〈e1,r,e2〉 from natural language text.
2. Main Methods of Relation Extraction
The classic entity relation extraction methods are mainly divided into four categories: supervised, semi-supervised, weakly supervised, and unsupervised. Classic methods have the error propagation problem, which greatly affects the effectiveness of entity relation extraction. With the rise of deep learning in recent years, the focus of research on relation extraction tasks has shifted to using deep learning methods.
Deep learning-based entity relation extraction methods have the main advantage over classic extraction methods in that deep learning neural network models can automatically learn sentence features without complex feature engineering. This article focuses on discussing entity relation extraction methods in depth based on deep learning.
Deep learning entity relation extraction is mainly divided into supervised and distant supervision. In supervised, methods for solving entity relation extraction can be divided into the following two types:
-
Pipeline Learning Method: This refers to directly extracting the relationships between entities based on completed entity recognition;
-
Joint Learning Method: This is mainly based on a neural network end-to-end model, which simultaneously completes entity recognition and relation extraction between entities.
Compared to supervised entity relation extraction, distant supervision methods lack manually annotated datasets. Therefore, distant supervision methods add an extra step of aligning knowledge bases to label unlabeled data, while the part of constructing relation extraction models is not much different from the pipeline method in the supervised domain.
3. Supervised Entity Relation Extraction
3.1 Pipeline Models
The main process of pipeline-based relation extraction is: Perform relation extraction on sentences that have been annotated with target entity pairs, and finally output the existing relation triplets as prediction results. Some relation extraction models based on pipeline methods have been proposed successively, mainly based on the network structures of RNN, CNN, LSTM, and their improved models.
(1) RNN-based Pipeline Model
When deep learning had just emerged, some scholars tried to use RNN for relation extraction. However, due to the gradient vanishing/exploding issues inherent in the RNN model, its complex internal structure, and long training cycles, there are very few papers using RNN, which were quickly replaced by CNN and LSTM.
(2) CNN-based Pipeline Model
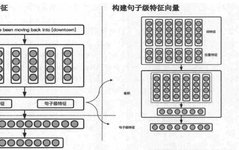
The paper “Relation classification via convolutional deep neural network” [1] uses CNN to extract lexical level features and sentence level features. It also proposes position features (PF, position features) to encode the relative distance between the current word and the target word pair. The experiments in this paper demonstrate that position features are quite effective. Many subsequent papers have adopted the position features proposed in this paper.
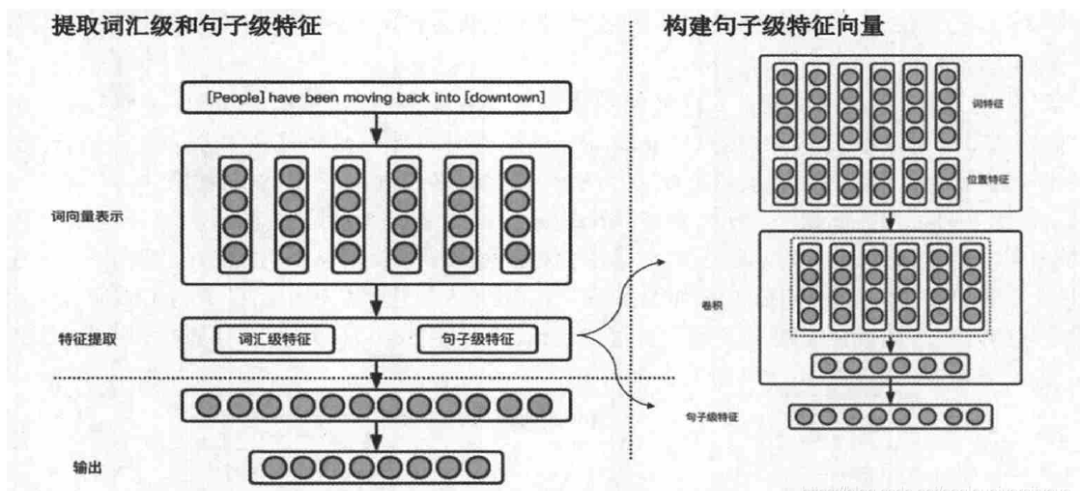 The overall architecture of the paper’s model is shown above, mainly including three layers: Word Representation, Feature Extraction, Output. It does not require complex syntax and semantic processing; the system input is just a sentence with two marked nouns. First, the first layer is the word representation layer, where word tokens are transformed into word vectors through word embedding. Next, the second layer is the feature extraction layer, which concatenates word features and distance features to entities as input, then performs convolution to obtain sentence-level features. The third layer is the output layer, which uses a softmax classifier to obtain the confidence of various relations, with high-confidence indicating the relationship between the two marked entities.
The overall architecture of the paper’s model is shown above, mainly including three layers: Word Representation, Feature Extraction, Output. It does not require complex syntax and semantic processing; the system input is just a sentence with two marked nouns. First, the first layer is the word representation layer, where word tokens are transformed into word vectors through word embedding. Next, the second layer is the feature extraction layer, which concatenates word features and distance features to entities as input, then performs convolution to obtain sentence-level features. The third layer is the output layer, which uses a softmax classifier to obtain the confidence of various relations, with high-confidence indicating the relationship between the two marked entities.
 The paper “Semantic Relation Classification via Convolutional Neural Networks with Simple Negative Sampling” [2] The overall model structure is shown in the above figure, mainly proposes an entity relation extraction model based on dependency analysis tree using convolutional neural networks, which processes the input text through a dependency analysis tree. It also proposes a negative sampling strategy: first, utilize dependency paths to learn the directionality of relations; then use negative sampling to learn the positional distribution of subjects and objects, adopting the shortest dependency path from object to subject as a negative sample and sending negative samples to the model for learning to solve the problem of irrelevant information introduced by the dependency analysis tree when entity pairs are far apart.
The paper “Semantic Relation Classification via Convolutional Neural Networks with Simple Negative Sampling” [2] The overall model structure is shown in the above figure, mainly proposes an entity relation extraction model based on dependency analysis tree using convolutional neural networks, which processes the input text through a dependency analysis tree. It also proposes a negative sampling strategy: first, utilize dependency paths to learn the directionality of relations; then use negative sampling to learn the positional distribution of subjects and objects, adopting the shortest dependency path from object to subject as a negative sample and sending negative samples to the model for learning to solve the problem of irrelevant information introduced by the dependency analysis tree when entity pairs are far apart.
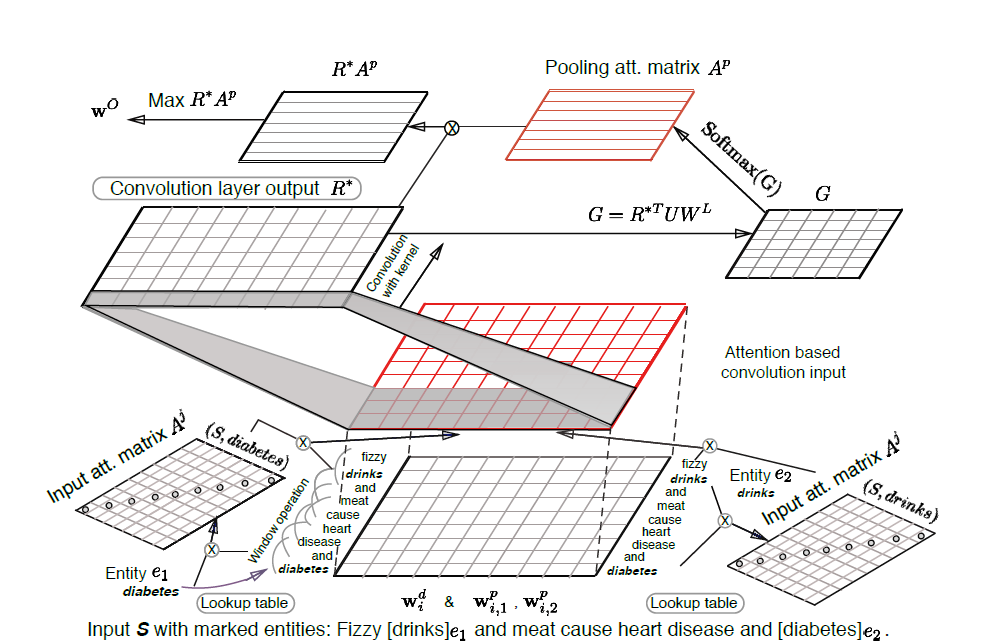 The paper “Relation Classification via Multi-Level Attention CNNs” [3] has three main innovations: First, the attention mechanism is applied to the input sequence to learn the attention of various parts of the input sentence to the two entities; Second, the attention mechanism is applied at the pooling layer to learn the attention for the target category; Third, a new objective function is proposed, allowing the model to perform better in relation extraction.
The paper “Relation Classification via Multi-Level Attention CNNs” [3] has three main innovations: First, the attention mechanism is applied to the input sequence to learn the attention of various parts of the input sentence to the two entities; Second, the attention mechanism is applied at the pooling layer to learn the attention for the target category; Third, a new objective function is proposed, allowing the model to perform better in relation extraction.
The model’s input is the same as [1], concatenating word vectors and position vectors. The implementation of the input-level attention mechanism is designed by creating two diagonal matrices related to the context of the entity pairs, where each element reflects the strength of the connection between that word and the given entity, which assigns attention to the entity. The pooling-level attention mechanism is implemented by constructing a relevance matrix to capture the relationship between the convolutional layer output and the entity relation. Finally, a distance objective function is used to predict the relation.
(3) LSTM-based Pipeline Model
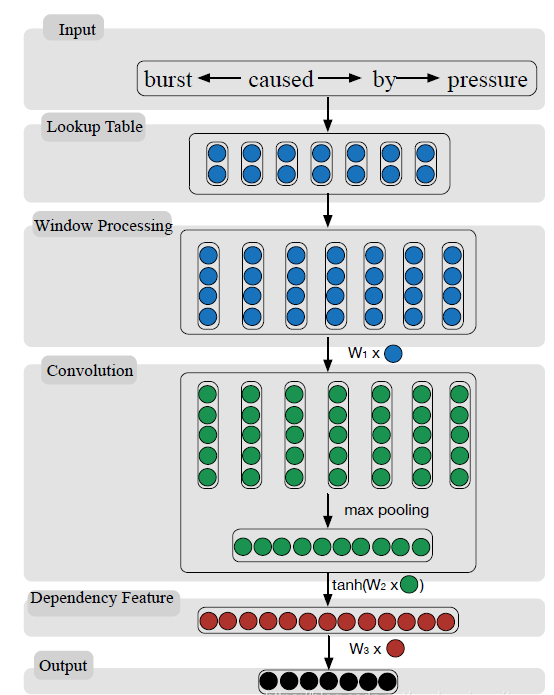
The paper “Classifying Relations via Long Short Term Memory Networks along Shortest Dependency Paths” [4] proposes an SDP-LSTM model for entity relation classification. The main work of the paper is to prove that SDP plays a role in relation classification, where SDP (the shortest dependency path) refers to the shortest path from two entities to a common ancestor node in the syntactic dependency tree. In entity relation classification, SDP contains various information, allowing the model to focus more on relevant information while ignoring irrelevant information. An example of the shortest dependency path is shown below (red path):
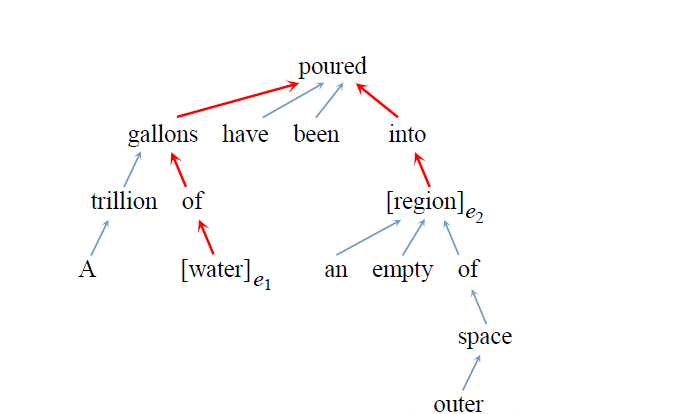 The structure of the SDP-LSTM model is shown in the figure below:
The structure of the SDP-LSTM model is shown in the figure below: 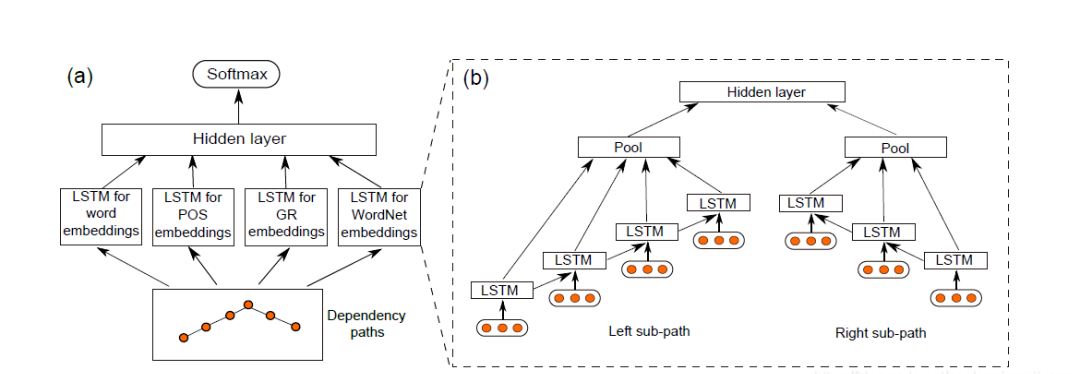 On the left is the overall structure of the model, which is built on SDP and has an encoding layer with four LSTM channels. The results of the encoding layer are concatenated and input into Softmax for relation classification. On the right is a detailed display of the encoding layer, showing the structure of an LSTM channel. The construction method of the LSTM channel is to use NLP tools to obtain the SDP structure of the sentence, then construct two paths from the nodes to the common ancestor based on SDP. During encoding, each path is treated as an LSTM sequence, and a pooling operation is performed on the hidden layers obtained by LSTM propagation to get the output of a single path. Finally, the outputs from both paths are connected to obtain the output of one LSTM channel. The entire model has four channels, using the word itself, part-of-speech information, dependency syntactic relations, and WordNet hypernyms as inputs to capture various features.
On the left is the overall structure of the model, which is built on SDP and has an encoding layer with four LSTM channels. The results of the encoding layer are concatenated and input into Softmax for relation classification. On the right is a detailed display of the encoding layer, showing the structure of an LSTM channel. The construction method of the LSTM channel is to use NLP tools to obtain the SDP structure of the sentence, then construct two paths from the nodes to the common ancestor based on SDP. During encoding, each path is treated as an LSTM sequence, and a pooling operation is performed on the hidden layers obtained by LSTM propagation to get the output of a single path. Finally, the outputs from both paths are connected to obtain the output of one LSTM channel. The entire model has four channels, using the word itself, part-of-speech information, dependency syntactic relations, and WordNet hypernyms as inputs to capture various features.
In the previous process, it was mentioned that the path nodes are represented as vectors. The paper utilizes four characteristics of words to represent nodes as vectors, including the word itself, part-of-speech information, dependency syntactic relations, and WordNet hypernyms. Thus, there are four LSTM channels. Although the SDP-LSTM model achieves good results, one problem is that the use of NLP tools to extract additional features introduces the error propagation problem.
The paper “A Bi-LSTM-RNN model for relation classification using low-cost sequence features” [5] addresses the issues in [4] by proposing a Bi-LSTM-RNN model based on low-cost sequence features, which utilizes entity pairs and represents their surrounding context in segments to obtain richer semantic information without the need for part-of-speech tagging, dependency syntactic trees, and other additional features. After obtaining the hidden vector representation of the text through LSTM, the input is divided into five segments based on the two entities, which are then input into the pooling layer for vector representation, followed by the classifier for relation classification. This resolves the high-cost structural feature issues based on syntax or dependency features and proves that when not using dependency parsing, the context between the two target entities can serve as an approximate replacement for the shortest dependency path.
3.2 Joint Models
Although pipeline models have achieved good results in relation extraction, various issues limit their performance, mainly three points:
-
Error propagation: Errors in the entity recognition module affect the subsequent relation classification performance;
-
Neglect of the relationship between the two sub-tasks;
-
Redundant information: Due to pairing the identified entities and then performing relation classification, those entity pairs without relationships introduce excess information, increasing the error rate.
Compared to the pipeline method, the joint model can leverage the tight interaction information between entities and relations, extracting entities and classifying the relationships between entity pairs simultaneously, effectively addressing the problems present in the pipeline method. In joint learning methods, due to different modeling objects, they can be further divided into parameter sharing methods and sequence labeling methods. The parameter sharing method models entities and relations separately, while the sequence labeling method directly models the entity-relation triplet.
(1) Parameter Sharing Joint Model
The paper “End-to-End Relation Extraction using LSTMs on Sequences and Tree Structures” [6] proposes a joint entity-relation detection model with parameter sharing. The model has two bidirectional LSTM-RNNs: one based on word sequence, mainly for entity recognition; another based on Tree Structures, mainly for relation extraction. The latter is stacked on top of the former, and the output and hidden layers of the former are part of the input for the latter. The structure of the entire model is shown in the image below:
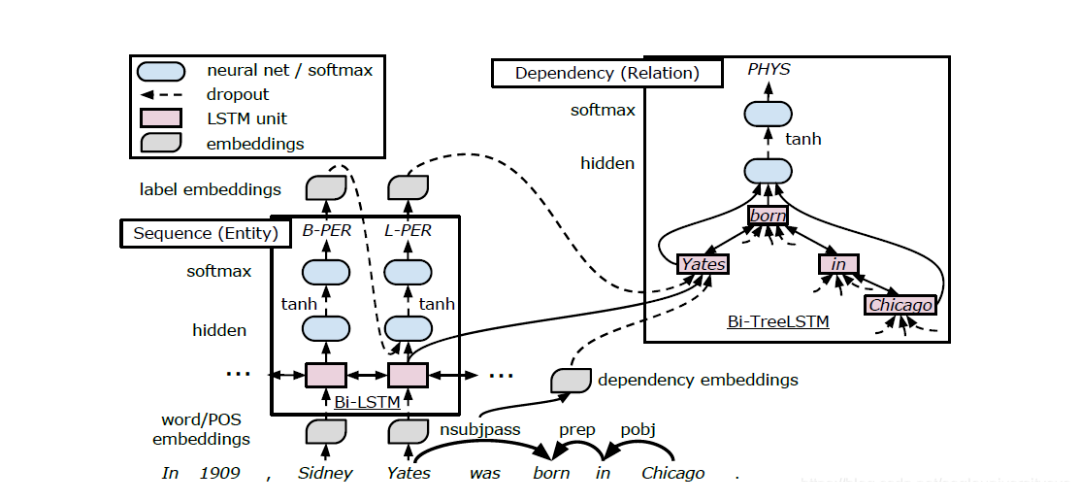 In this model, the entity recognition sub-task and relation classification sub-task share the output of the LSTM encoding layer. This method treats the entity recognition task as a sequence labeling task, using bidirectional sequence LSTM to output entity labels with dependencies. Subsequently, by stacking bidirectional tree structure LSTM on the bidirectional sequence LSTM unit, the relation classification sub-task and entity recognition sub-task share the LSTM unit sequence representation of the encoding layer. The relation classification sub-task captures dependency features such as part-of-speech tags, and the entity recognition sub-task outputs the entity sequence, constructing the dependency tree based on SDP to classify relations and obtain entity relation triplets.
In this model, the entity recognition sub-task and relation classification sub-task share the output of the LSTM encoding layer. This method treats the entity recognition task as a sequence labeling task, using bidirectional sequence LSTM to output entity labels with dependencies. Subsequently, by stacking bidirectional tree structure LSTM on the bidirectional sequence LSTM unit, the relation classification sub-task and entity recognition sub-task share the LSTM unit sequence representation of the encoding layer. The relation classification sub-task captures dependency features such as part-of-speech tags, and the entity recognition sub-task outputs the entity sequence, constructing the dependency tree based on SDP to classify relations and obtain entity relation triplets.
It should be noted that: In this model, the relation classification sub-task and entity recognition sub-task only share the LSTM of the encoding layer, while the Tree-LSTM in the relation classification sub-task is only used in relation classification, so it is not strictly a true joint model. However, this model lays the foundation for the subsequent proposal of truly joint learning models and serves as an inspiration for joint learning models based on deep learning methods.
(2) Sequence Labeling Based Joint Model
Although the parameter sharing entity-relation extraction method improves the error accumulation propagation problem and neglect of the relationship dependency between the two sub-tasks present in traditional pipeline methods, it still generates redundant information without relationships due to not fully sharing parameters during training for the named entity recognition sub-task and relation classification sub-task. To address this issue, a joint extraction method for entities and relations based on a new sequence labeling approach has been proposed.
The paper “Joint Extraction of Entities and Relations Based on a Novel Tagging Scheme” [7] designs a special tagging type that transforms entity recognition and relation classification into a sequence labeling problem; then proposes an end-to-end model for jointly extracting entities and relations.
In this method, there are 3 types of labeling information: (1) Position information of words in entities { B, I, E, S, O } representing { entity start, entity inside, entity end, single entity, irrelevant word }; (2) Entity relation type information that needs to be tagged according to relation types, divided into multiple categories, such as { CF, CP, … }; (3) Entity role information { 1, 2 } representing { entity 1, entity 2 }. The labeling method is shown in the figure below:
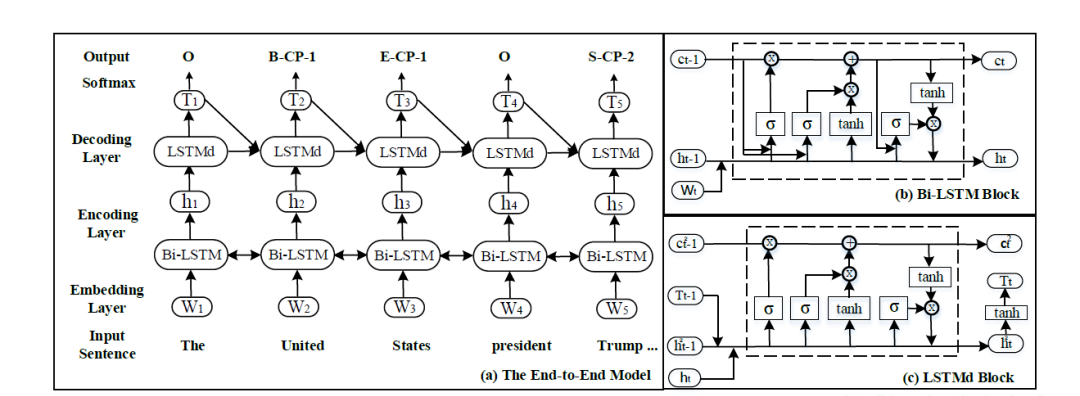
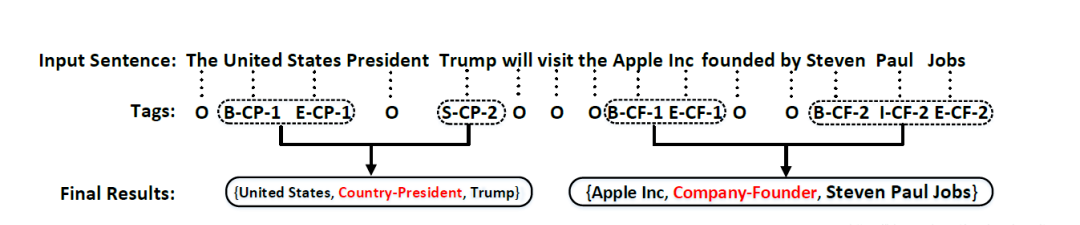 The end-to-end neural network model proposed in this paper is shown in the figure below: first, the encoding layer uses Bi-LSTM to encode the input sentence; then, the decoding layer uses LSTMd (an improved LSTM proposed by the author) for decoding; finally, the model outputs the labeled entity-relation triplet.
The end-to-end neural network model proposed in this paper is shown in the figure below: first, the encoding layer uses Bi-LSTM to encode the input sentence; then, the decoding layer uses LSTMd (an improved LSTM proposed by the author) for decoding; finally, the model outputs the labeled entity-relation triplet.
4. Distant Supervision for Entity Relation Extraction
When faced with a large amount of unlabeled data, supervised relation extraction consumes a lot of manpower and becomes overwhelming. Therefore, distant supervision entity relation extraction has emerged. Distant supervision automatically labels a large amount of unlabeled data in open domains by aligning data with remote knowledge bases.
There are two main issues when labeling data with distant supervision:
-
Noise: The noise problem arises from the strong assumption conditions of distant supervision, introducing a large amount of noisy data. Given an entity pair and its corresponding relation, traditional methods extract all sentences containing that entity pair from unlabeled corpora and assume that entities in such sentences share the same relation. This method evidently affects training performance due to noisy corpora.
-
Feature extraction error propagation: The error propagation issue in feature extraction arises from the fact that traditional feature extraction mainly uses NLP tools for dataset feature extraction, thus introducing a large amount of propagation error.
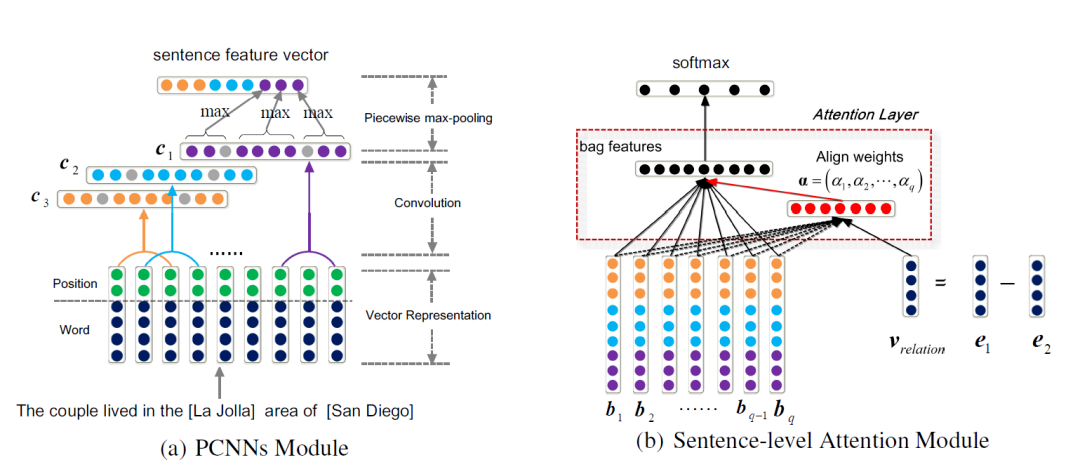
The paper “Neural Relation Extraction with Selective Attention over Instances” [8] builds on the PCNN model by adding an attention mechanism to the example sentences. PCNN is based on CNN, improving the input part of the model: dividing a sentence into three parts based on two entities, performing convolution and pooling operations separately, and then concatenating to obtain more context information related to the entities.
To address the noise data issue introduced by strong assumption conditions, this paper provides a solution by assigning different weights to different sentences in a package through the attention mechanism, fully utilizing the information within the package and further mitigating the noise generated by mislabeling example sentences. The PCNN+Att method can assign higher weights to correctly classified example sentences and lower weights to misclassified example sentences, thus improving classification accuracy.
The PCNN+Att model first encodes sentences using CNN or PCNN to obtain sentence-level feature vectors. It transforms sentence words and entities into dense real-valued vectors, then constructs corresponding sentence vectors through convolution, pooling, and nonlinear transformations. The sentence vector encoding process is shown in the figure below:
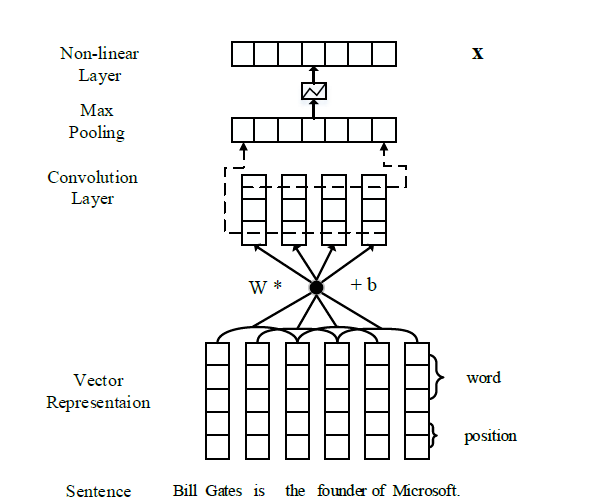 After obtaining sentence-level features, the attention mechanism assigns different weights α1, α2, α3, …, αn to different example sentences, implicitly discarding some noisy corpora, thereby enhancing the performance of the classifier.
After obtaining sentence-level features, the attention mechanism assigns different weights α1, α2, α3, …, αn to different example sentences, implicitly discarding some noisy corpora, thereby enhancing the performance of the classifier.  The paper “Distant Supervision for Relation Extraction with Sentence-level Attention and Entity Descriptions” [9] proposes a model that adds entity description information to assist in learning entity representations, thus improving accuracy.
The paper “Distant Supervision for Relation Extraction with Sentence-level Attention and Entity Descriptions” [9] proposes a model that adds entity description information to assist in learning entity representations, thus improving accuracy.
Entity information is extracted from Freebase and Wikipedia pages, used to supplement the background knowledge for entity relation extraction, and a traditional CNN model (with one convolutional layer and one max pooling layer) is used to extract features from the entity descriptions. Background knowledge not only provides more information for predicting relations, but also brings better entity representations to the attention mechanism module.
Source: https://blog.csdn.net/eagleuniversityeye/article/details/105464295
Author: iceburg-blogs
Editor: @WeChat Official Account: AI Algorithm Little Meow
📝 Submit Paper Interpretation, Let your article be seen by more people from different backgrounds and directions, it won’t sink into the sea, and may even increase citations~ Submit with the WeChat note “Submission”.
Recent Articles
EMNLP 2022 and COLING 2022, which conference is better to submit to?
A new and easy-to-use unified model based on Word-Word relations for NER
Alibaba + Peking University | Doing simple masking on gradients has such a magical effect
ACL’22 | Kuaishou + Chinese Academy of Sciences propose a data augmentation method: Text Smoothing
For submission or learning exchange, note:Nickname-School (Company)-Direction, join the DL&NLP exchange group.
There are many directions:Machine Learning, Deep Learning, Python, Sentiment Analysis, Opinion Mining, Syntactic Analysis, Machine Translation, Human-Computer Dialogue, Knowledge Graphs, Speech Recognition, etc..

Remember to note!
It’s not easy to organize, so please give a thumbs up!