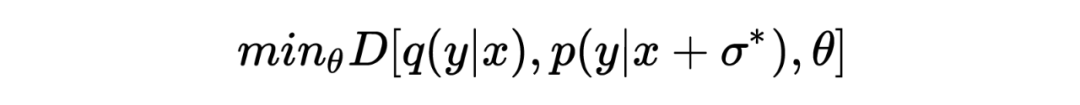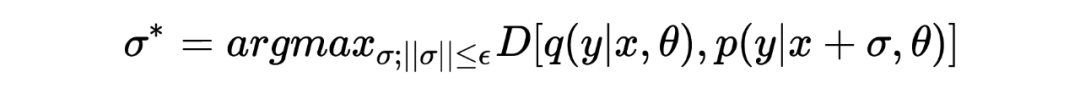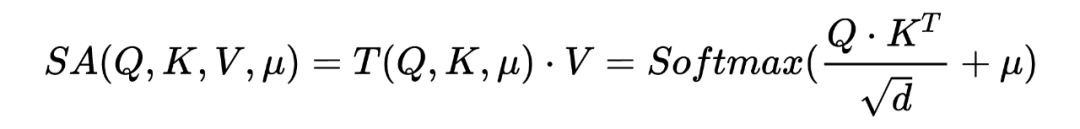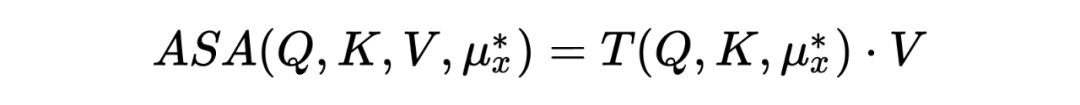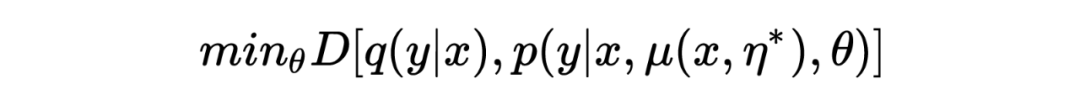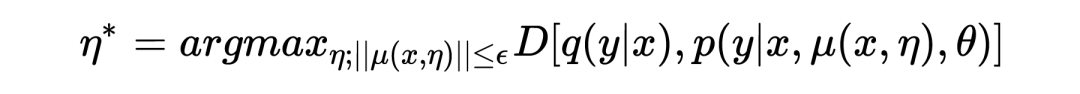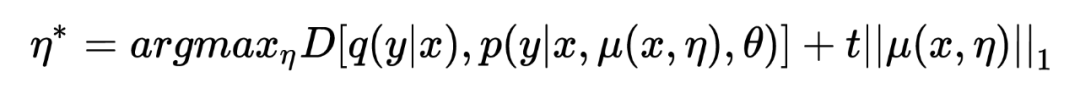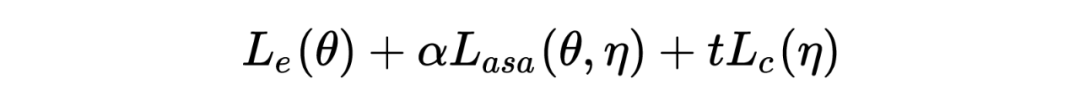Institution | Beijing University of Posts and Telecommunications
Research Direction | Dialogue Summarization
Typesetting | PaperWeekly
Paper Title:
Adversarial Self-Attention For Language Understanding
Paper Source:
ICLR 2022
Paper Link:
https://arxiv.org/pdf/2206.12608.pdf
Introduction
This paper proposes the Adversarial Self-Attention mechanism (ASA), which reconstructs the attention of the Transformer using adversarial training, allowing the model to be trained on a contaminated model structure.Problems Attempted to Solve:
There is substantial evidence that self-attention can benefit from allowing bias, which can incorporate a certain degree of prior knowledge (such as masking and distribution smoothing) into the original attention structure. This prior knowledge enables the model to learn useful information from a smaller corpus. However, this prior knowledge is typically task-specific, making it difficult for the model to generalize to diverse tasks.
Adversarial training enhances model robustness by adding perturbations to the input content. The authors find that simply adding perturbations to the input embedding does not effectively confuse the attention maps. The model’s attention remains unchanged before and after perturbation.
To address the above issues, the authors propose ASA, which has the following advantages:
Maximizes empirical training risk, learning a biased (or adversarial) structure in the automated construction of prior knowledge.
The adversarial structure is learned from the input data, distinguishing ASA from traditional adversarial training or variants of self-attention.
Utilizes a gradient reversal layer to combine the model and adversary into a whole.
ASA inherently possesses interpretability.
Preliminary
Let the input features be represented as, in traditional adversarial training, usually a token sequence or the embeddings of tokens, representing ground truth. For parameterized models, the model’s predictions can be represented as
2.1 Adversarial Training
The goal of adversarial training is to enhance model robustness by minimizing the distance between the predictions of the perturbed model and the target distribution:
Where represents the model’s predictions after adversarial perturbation, denotes the model’s target distribution.The adversarial perturbation is obtained by maximizing empirical training risk:
Where is the constraint made on , hoping to cause significant perturbation to the model under smaller .The above two representations illustrate the adversarial process.
2.2 General Self-Attention
Define the expression of self-attention as:
In the most general self-attention mechanism, represents an identity matrix, while in previous studies, represents a certain degree of prior knowledge used to smooth the output distribution of the attention structure.In this paper, the authors define as a binary matrix with elements of .
Adversarial Self-Attention Mechanism
3.1 Optimization
The goal of ASA is to mask the most vulnerable attention units in the model. These most vulnerable units depend on the model’s input, thus the adversarial can be represented as the “meta-knowledge” learned from the input: ASA attention can be represented as:
Similar to adversarial training, the model minimizes the following divergence:
The empirical risk is estimated to obtain :
Where represents the decision boundary of , used to prevent ASA from harming the training of the model.Considering that exists in the form of an attention mask, it is thus more appropriate to constrain the proportion of masked units. Since it is challenging to measure the specific value of , the hard constraint is transformed into an unconstraint with penalties:
Where t is used to control the degree of adversarial.
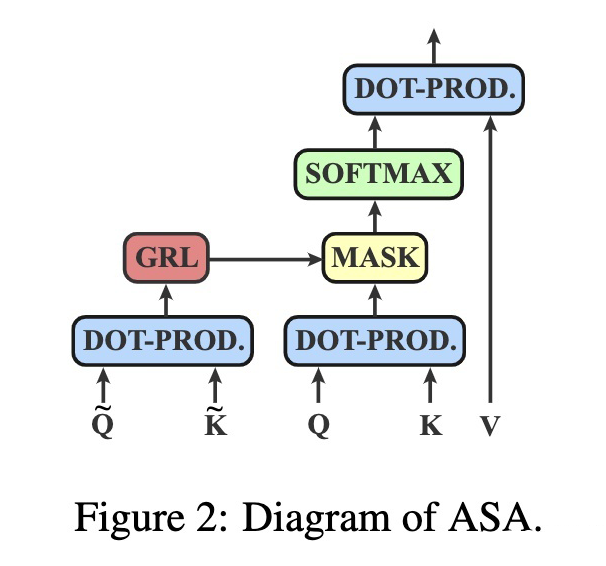
3.2 Implementation
The authors propose a simple and fast implementation of ASA.
For the self-attention layer, can be obtained from the hidden state of the input. Specifically, a linear layer is used to transform the hidden state into and , obtaining the matrix through a dot product, and then binary-izing the matrix using reparameterization techniques.Since adversarial training typically includes inner maximization and outer minimization objectives, at least two backward processes are needed. Thus, to accelerate training, the authors utilize the Gradient Reversal Layer (GRL) to combine the two processes.
3.3 Training
The training objective is as follows:
represents the task-specific loss, represents the loss after adding ASA adversarial, represents the constraint for .
Experiments
4.1 Results
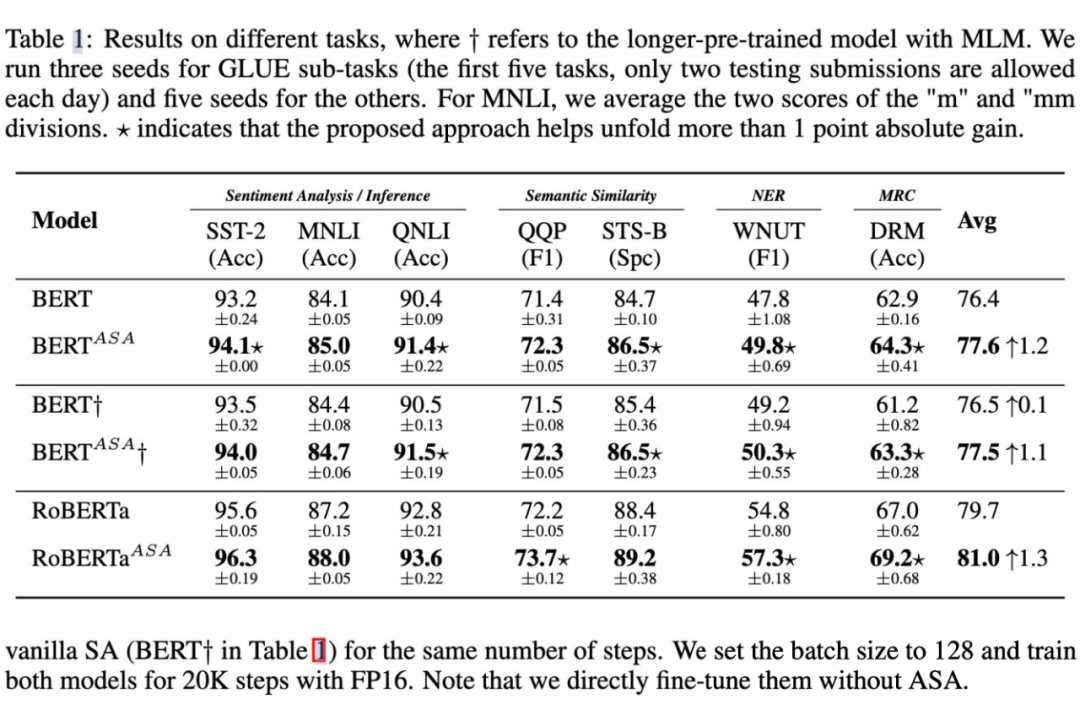
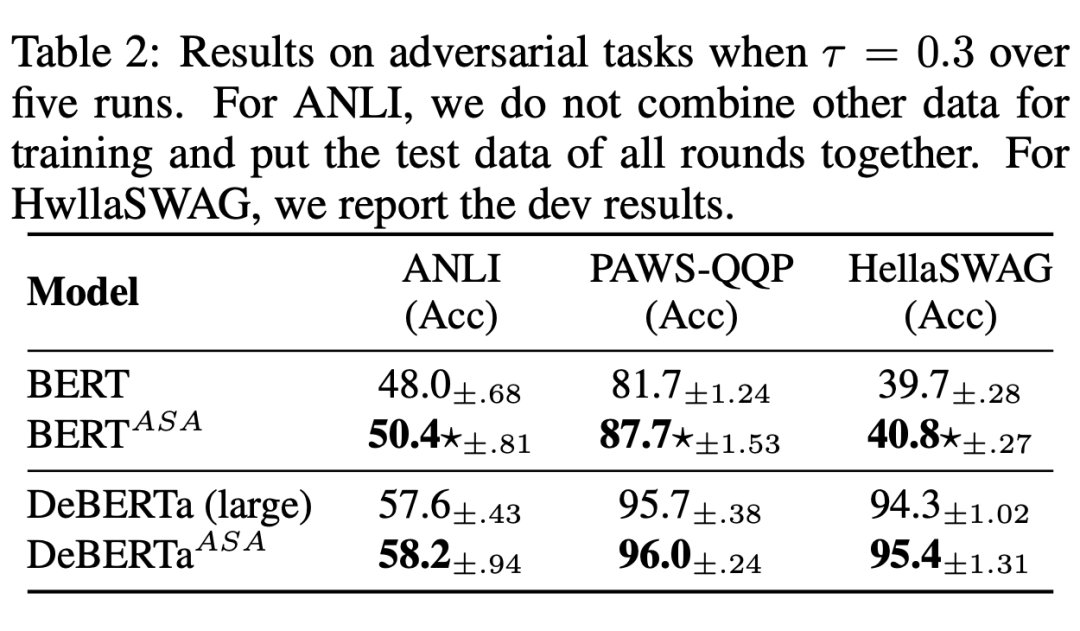
As can be seen from the table above, the models supported by ASA consistently outperform the original BERT and RoBERTa to a large extent in fine-tuning. ASA performs excellently on small-scale datasets such as STS-B and DREAM (which are generally considered easier to overfit), while still showing good improvements on larger datasets such as MNLI, QNLI, and QQP, indicating that ASA can enhance both the model’s generalization ability and its language representation capability.As shown in the table below, ASA plays a significant role in enhancing model robustness.
4.2 Analytical Experiments
1. VS. Naive SmoothingComparing ASA with other attention smoothing methods.
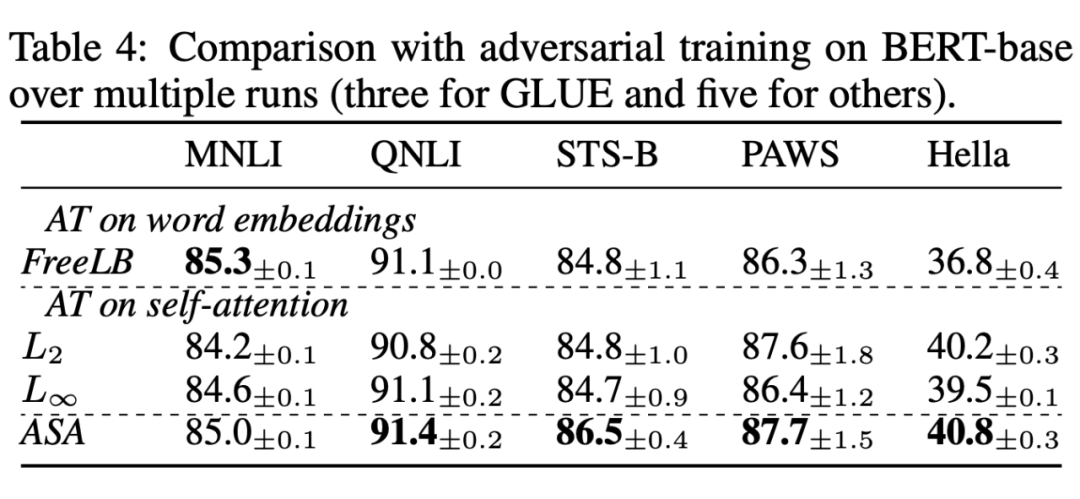
2. VS. Adversarial TrainingComparing ASA with other adversarial training methods.
4.3 Visualization
1. Why ASA Improves GeneralizationAdversarial can weaken the attention on keywords while allowing non-keywords to receive more attention. ASA prevents lazy predictions from the model but encourages it to learn from contaminated cues, thereby improving generalization ability.
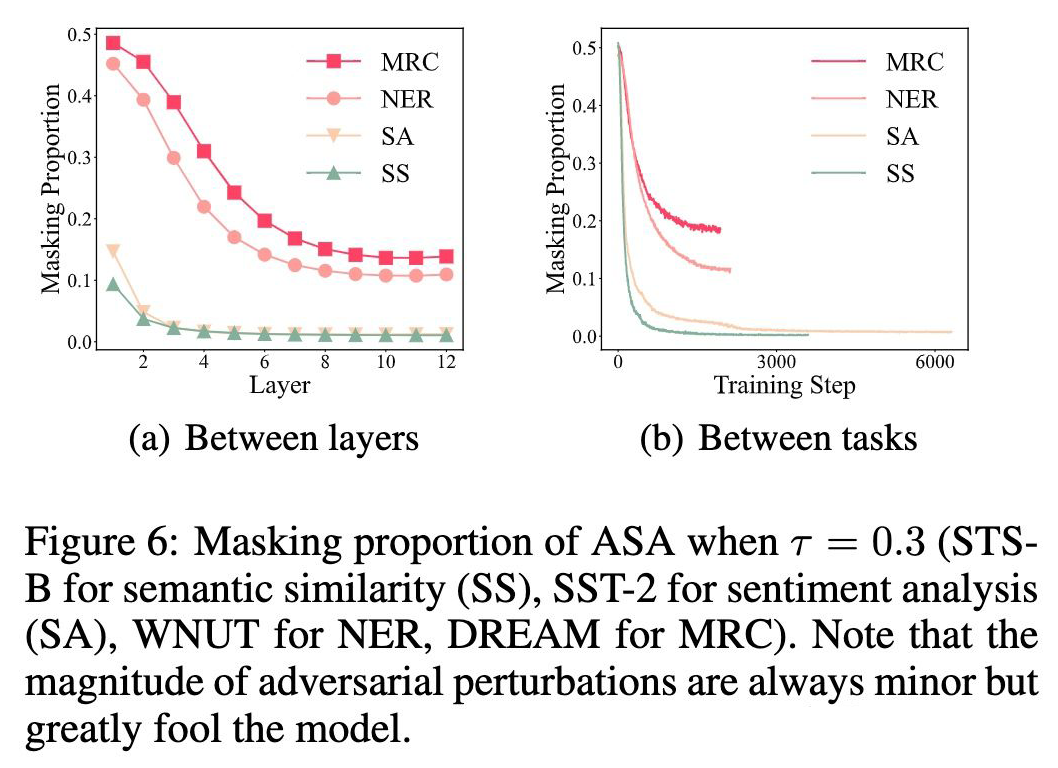
2. Bottom Layers are More VulnerableIt can be seen that the proportion of masking decreases from the lower layers to the higher layers, with a higher masking proportion indicating greater vulnerability of the layer.
Conclusion
This paper presents the Adversarial Self-Attention mechanism (ASA) to improve the generalization and robustness of pre-trained language models. Extensive experiments demonstrate that the proposed method can enhance the model’s robustness during both pre-training and fine-tuning phases.·
📝 Paper interpretation submissions allow your article to be seen by more people from different backgrounds and directions, preventing it from sinking into oblivion and perhaps increasing citations~ Submit by adding “submission” in the WeChat remarks below.
Recent Articles
Which conference to submit to: EMNLP 2022 or COLING 2022?
A new and easy-to-use unified model based on Word-Word relationships for NER
Alibaba + Peking University | The magical effect of simple masking on gradients
ACL’22 | Kuaishou + CAS proposed a data augmentation method: Text Smoothing
For submissions or learning exchanges, please note:Nickname-School (Company)-Direction, join the DL&NLP discussion group.
There are many directions:Machine Learning, Deep Learning, Python, Sentiment Analysis, Opinion Mining, Syntactic Parsing, Machine Translation, Human-Machine Dialogue, Knowledge Graphs, Speech Recognition, etc..
Remember to note!
It is not easy to organize, so please give it a look!