
This article is reprinted from the PaddlePaddle WeChat official account
Editor’s Note:
Written by a deep learning engineer from Baidu, this article provides a detailed overview of the eight major tasks in the field of computer vision, including: image classification, object detection, image semantic segmentation, scene text recognition, image generation, human keypoint detection, video classification, and metric learning.
This overview introduces the basic situations of these tasks, as well as current technological progress, main models, and performance comparisons. Additionally, GitHub links are provided for further learning and installation practice guidelines. Many tutorials are written in Chinese, making it very friendly.
In summary, this overview is packed with valuable information and is recommended for collection and reading.
Previous Article
Computer Vision is the science of enabling machines to “see”. More specifically, it involves using cameras and computers to replace human eyes for recognizing, tracking, and measuring targets, and processing these images into forms more suitable for human observation or instrument detection.
In a vivid analogy, it is like equipping computers with eyes (cameras) and brains (algorithms) so that they can see and perceive the environment like humans. As one of the core technologies of artificial intelligence, computer vision technology has been widely applied in fields such as security, finance, hardware, marketing, driving, and healthcare. In this previous article, we will introduce four computer vision technologies based on PaddlePaddle and their associated deep learning models.
1. Image Classification
Image classification is the task of distinguishing different categories of images based on their semantic information. It is an important foundational problem in computer vision and serves as the basis for other higher-level visual tasks such as object detection, image segmentation, object tracking, behavior analysis, and face recognition.
Image classification has a wide range of applications in many fields, such as face recognition and intelligent video analysis in security, traffic scene recognition in transportation, content-based image retrieval and automatic album classification in the internet field, and image recognition in the medical field.
Thanks to the advancements in deep learning, the accuracy of image classification has significantly improved. On the classic ImageNet dataset, commonly used models for training image classification tasks include AlexNet, VGG, GoogLeNet, ResNet, Inception-v4, MobileNet, MobileNetV2, DPN (Dual Path Network), SE-ResNeXt, ShuffleNet, etc.
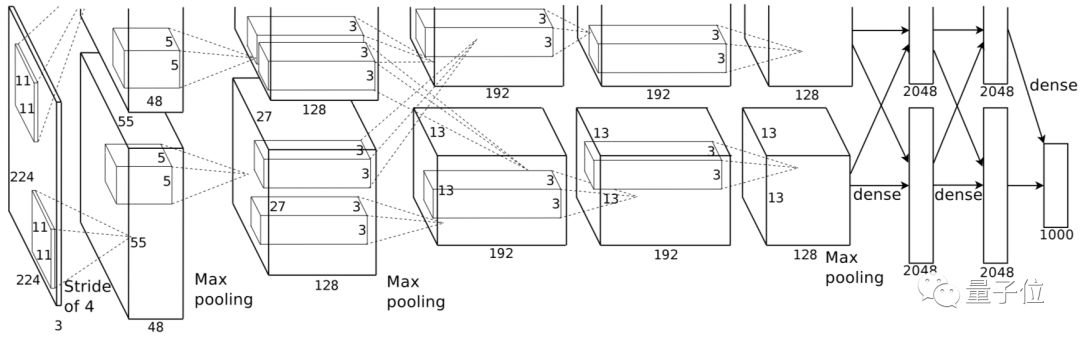
△ AlexNet
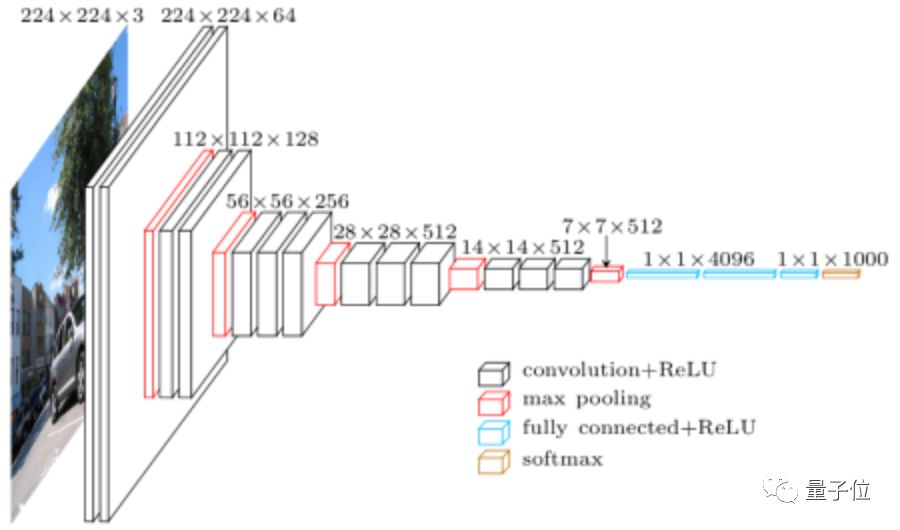
△ VGG
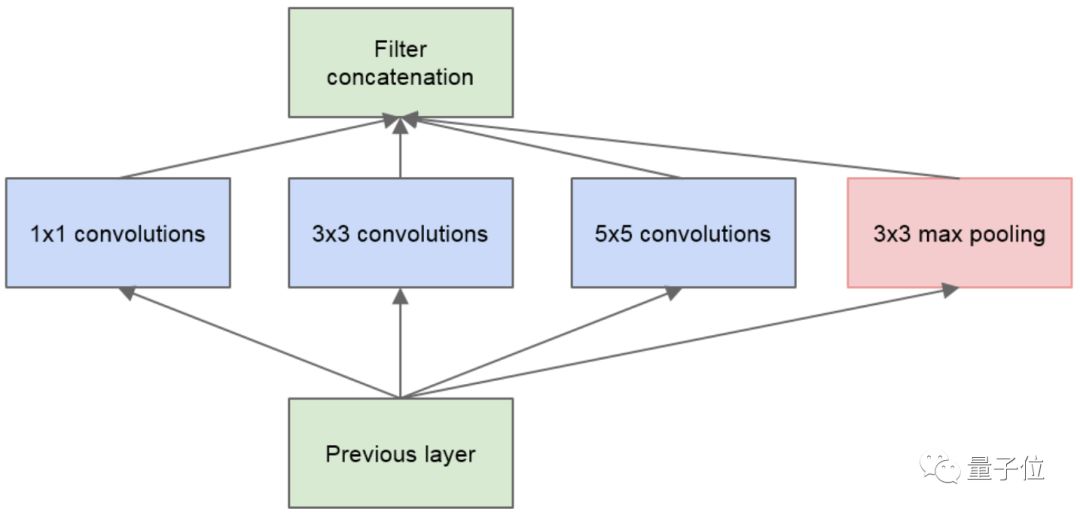
△ GoogLeNet
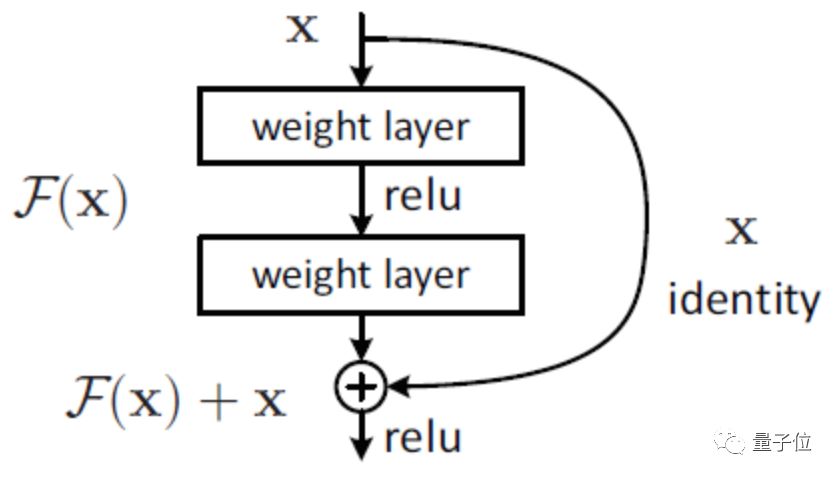
△ ResNet
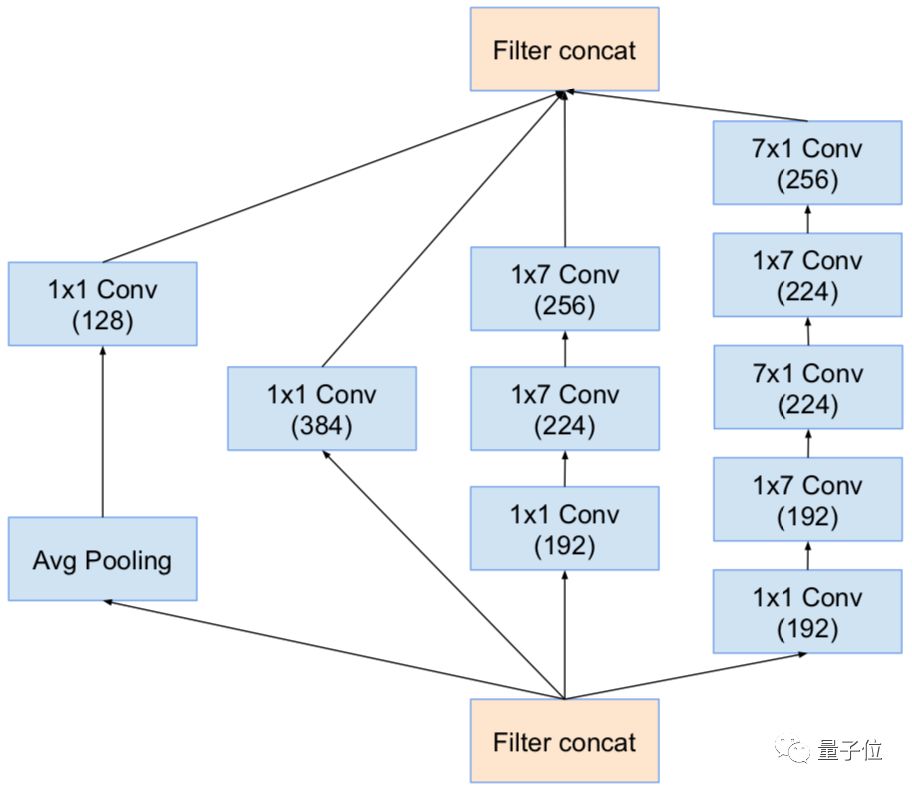
△ Inception-v4
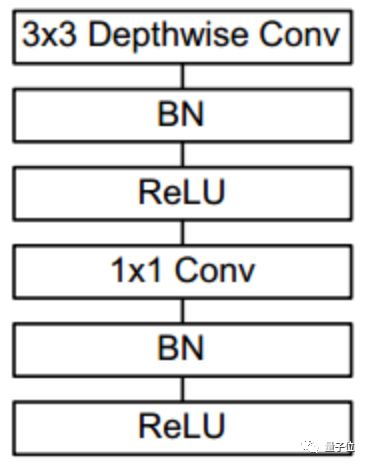
△ MobileNet
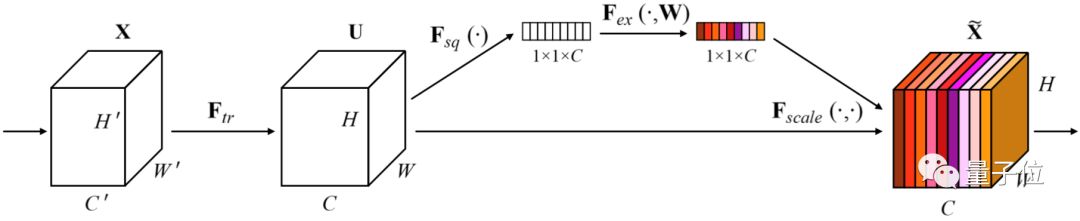
△ SE-ResNeXt
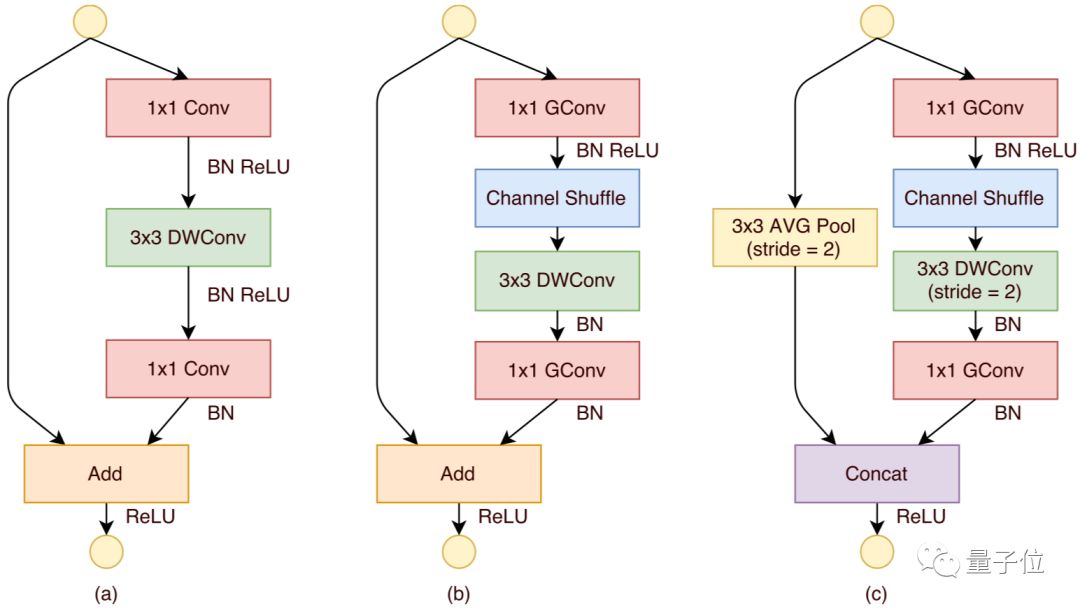
△ ShuffleNet
The models vary in structure and complexity, resulting in different accuracy rates. The table below lists the top-1/top-5 validation accuracy rates of different models on the ImageNet 2012 dataset.
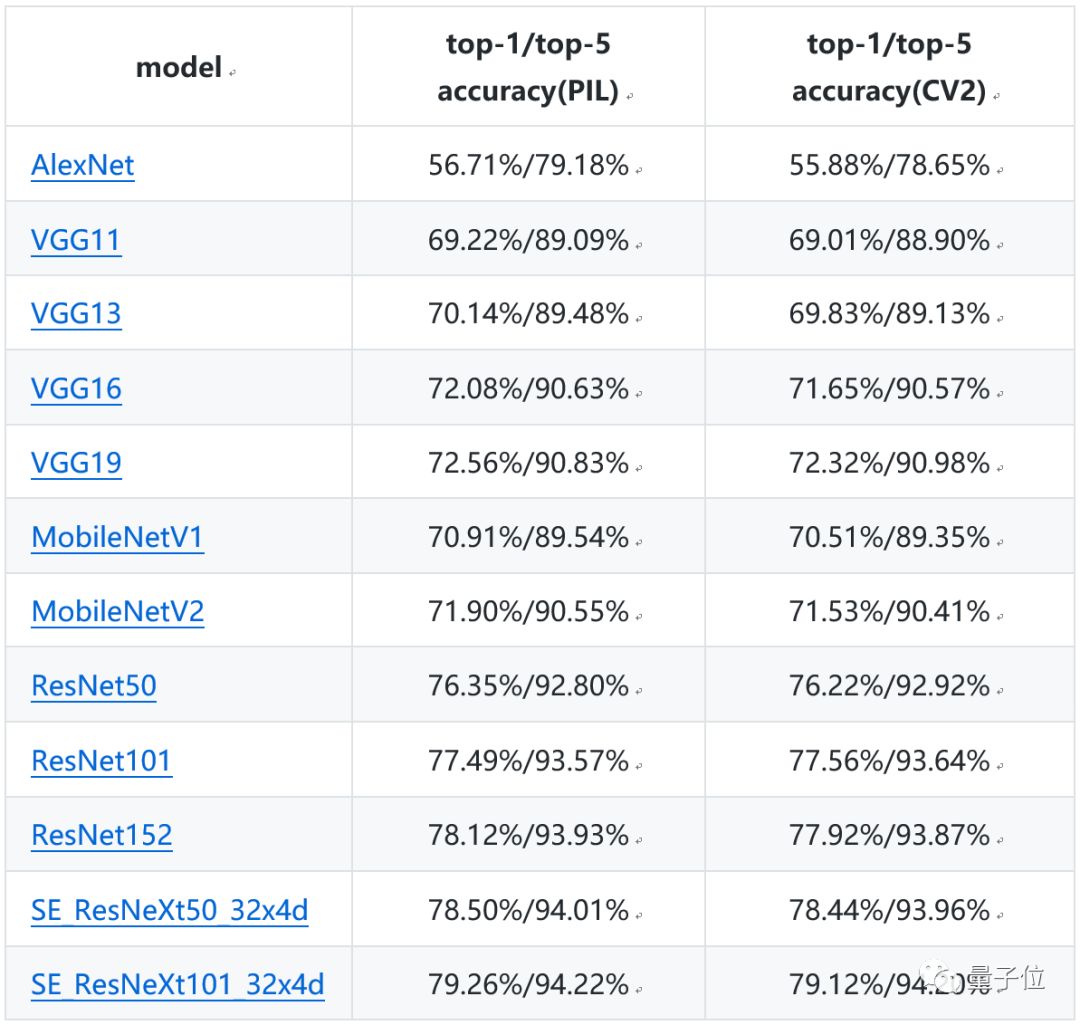 △ Image Classification Model Evaluation Results
△ Image Classification Model Evaluation Results
On our GitHub page, we provide downloads for the above training models, along with detailed instructions on how to use PaddlePaddle Fluid for image classification tasks, including installation, data preparation, model training, evaluation, and more. A tool is also provided for converting Caffe models into PaddlePaddle Fluid model configurations and parameter files.
The link to the above page is here:
https://github.com/PaddlePaddle/models/blob/develop/fluid/PaddleCV/image_classification

2. Object Detection
The goal of the object detection task is to identify all target locations in a given image or video frame and specify the category of each target.
For humans, object detection is a very simple task. However, what computers “see” are numbers encoded from images, making it difficult to decode high-level semantic concepts like humans or objects appearing in an image or video frame, and even more challenging to locate the targets within the image.
Moreover, since targets can appear anywhere in an image or video frame, and their shapes can vary widely, along with the diverse backgrounds of images or video frames, many factors make object detection a challenging problem for computers.
In the object detection task, we mainly introduce how to train general object detection models based on PASCAL VOC and MS COCO datasets, including SSD models, PyramidBox models, and R-CNN models.
• SSD Model, Single Shot MultiBox Detector, is a single-stage object detector. Unlike two-stage detection methods, single-stage object detection does not perform region proposal but directly regresses the target’s bounding box and classification probabilities from the feature map. SSD employs this single-stage detection idea and improves it: detecting targets of corresponding scales on feature maps of different scales, making it one of the newer and more effective detection algorithms in the field of object detection, characterized by fast detection speed and high accuracy.
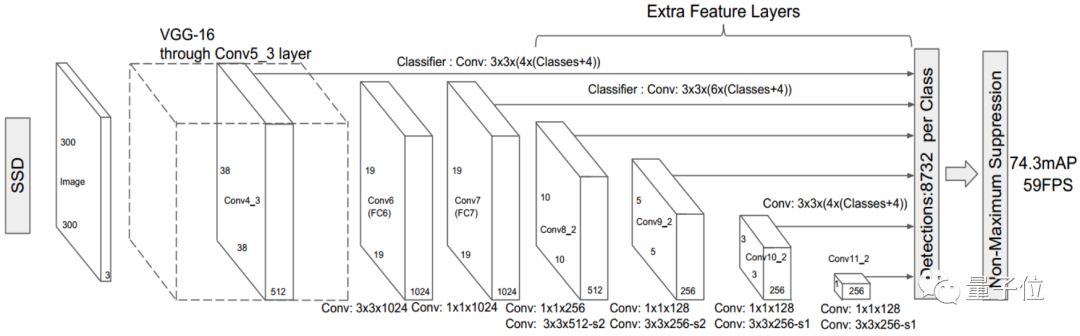
△ SSD Object Detection Model Structure
 △ SSD Object Detection Visualization
△ SSD Object Detection Visualization
 △ Object Detection SSD Model Evaluation Results
△ Object Detection SSD Model Evaluation Results
On GitHub, we provide a more detailed introduction on how to download, train, and use this model.
The link is here:
https://github.com/PaddlePaddle/models/blob/develop/fluid/PaddleCV/object_detection
• PyramidBox Model, developed by Baidu, is a face detection model that employs a context-assisted single-shot face detection method, capable of detecting small, blurry, and partially occluded faces in uncontrolled environments. The model achieved first place on the WIDER Face dataset in March 2018.
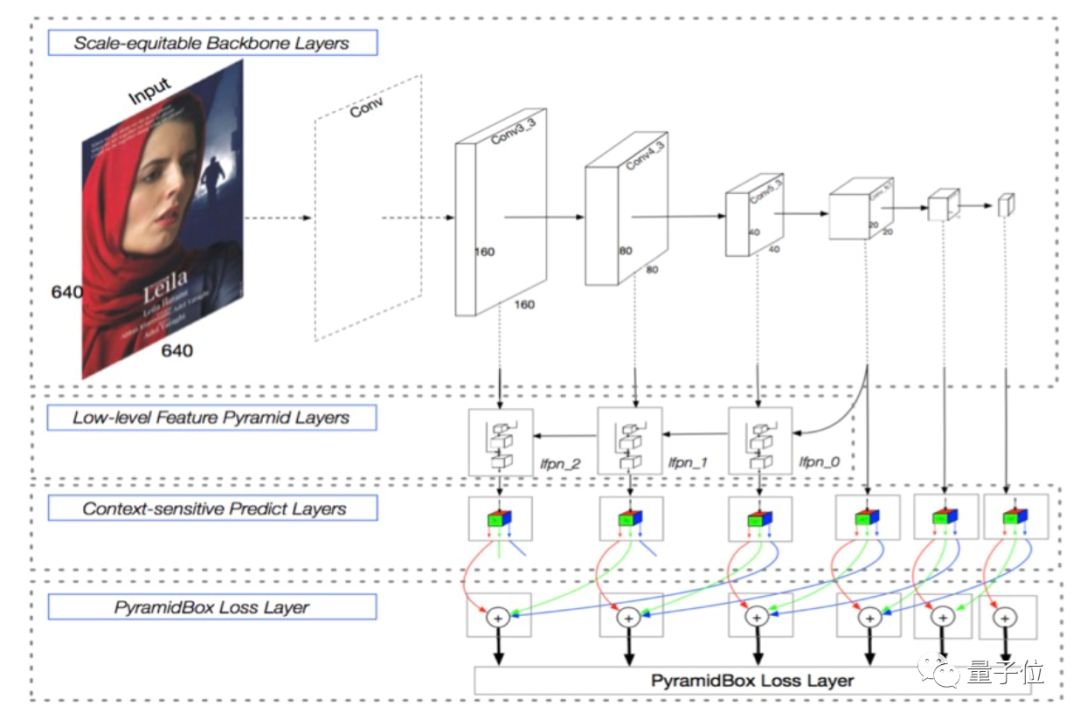 △ Pyramidbox Face Detection Model
△ Pyramidbox Face Detection Model

△ Pyramidbox Prediction Visualization
 △ PyramidBox Model Evaluation Results
△ PyramidBox Model Evaluation Results
If you want to learn more about this model, the link is here (and it is fully in Chinese):
https://github.com/PaddlePaddle/models/tree/develop/fluid/PaddleCV/face_detection
• R-CNN Series Models, Region-based Convolutional Neural Network (R-CNN) series models are typical two-stage object detectors. Compared to traditional region extraction methods, RPN networks in R-CNN significantly improve the efficiency of region extraction by sharing convolutional layer parameters and proposing high-quality candidate regions. Faster R-CNN and Mask R-CNN are classic models in the R-CNN series.
Faster R-CNN integrates candidate region generation, feature extraction, classification, and location refinement into a unified deep network framework, greatly improving the running speed.
Mask R-CNN adds a segmentation branch to the original Faster R-CNN model to obtain mask results, achieving decoupling of mask and category prediction, making it a classic instance segmentation model.
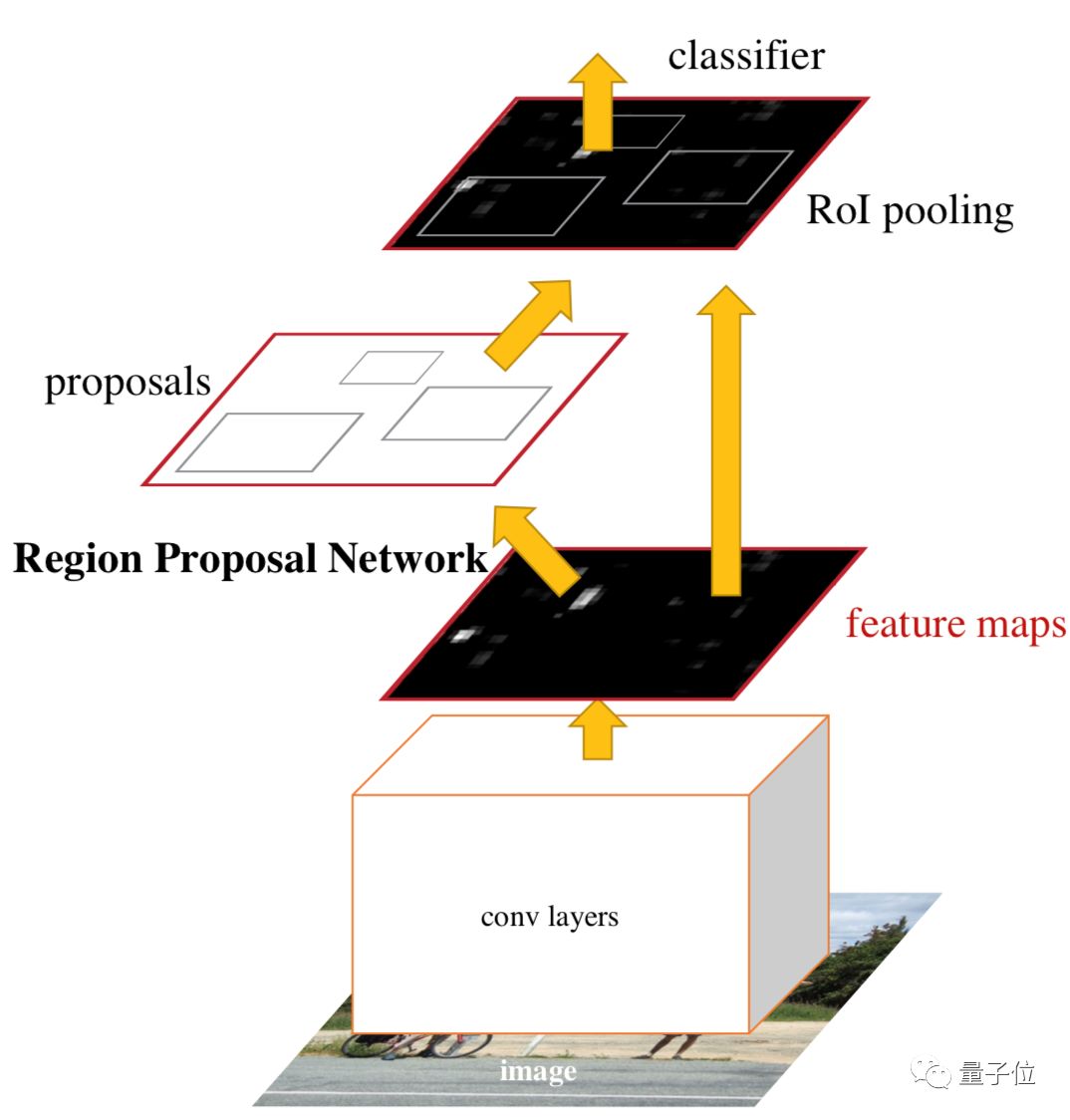 △ Faster R-CNN Structure
△ Faster R-CNN Structure
 △ Faster R-CNN Prediction Visualization
△ Faster R-CNN Prediction Visualization
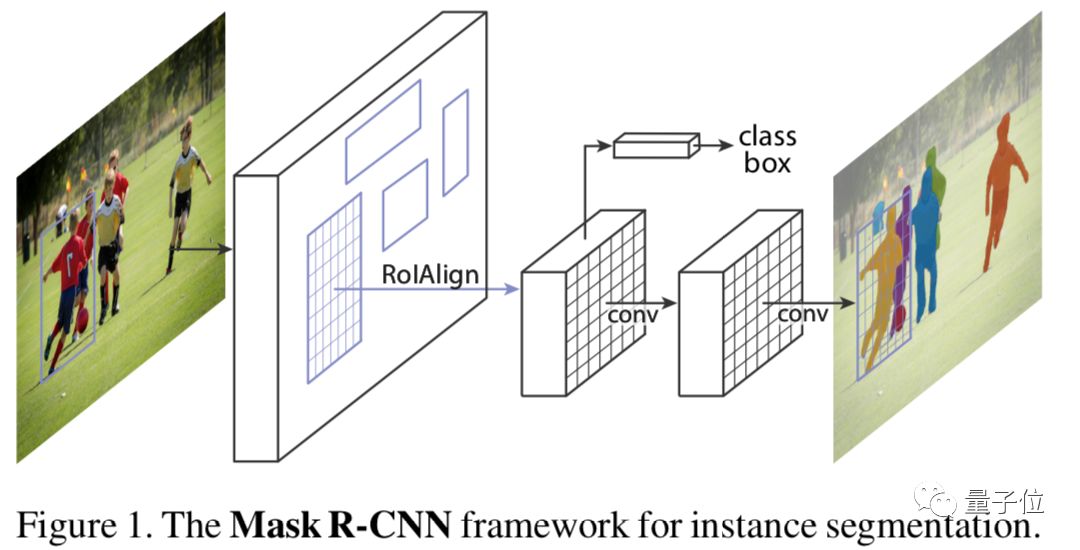 △ Mask R-CNN Structure
△ Mask R-CNN Structure
△ Mask R-CNN Prediction Visualization
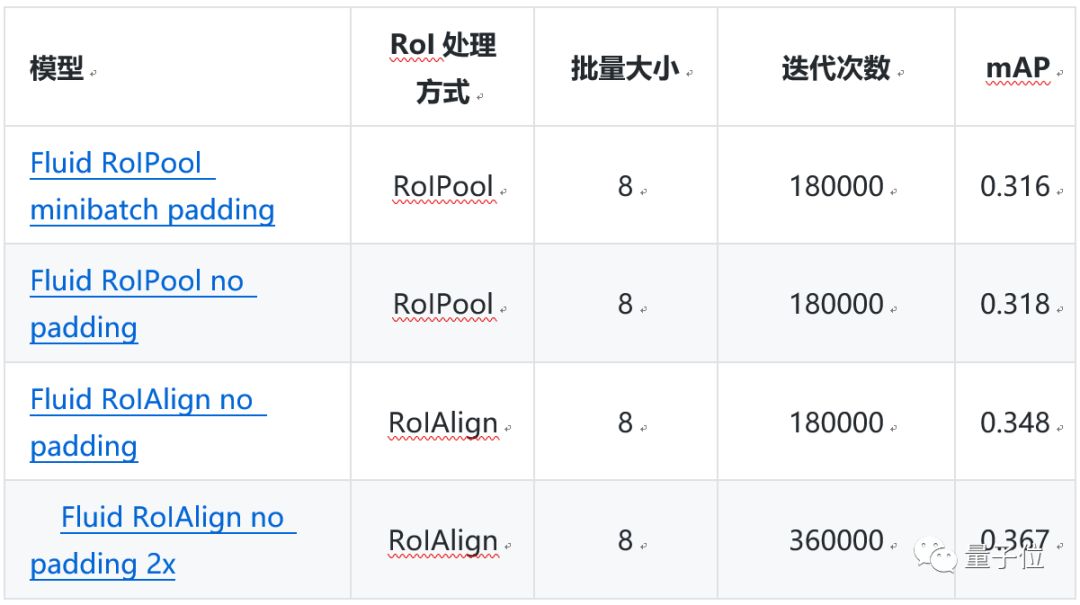 △ Faster R-CNN Evaluation Results
△ Faster R-CNN Evaluation Results
 △ Mask R-CNN Evaluation Results
△ Mask R-CNN Evaluation Results
Similarly, if you want to further learn about R-CNN installation, preparation, training, etc., you can go to the following link:
https://github.com/PaddlePaddle/models/tree/develop/fluid/PaddleCV/rcnn
3. Image Semantic Segmentation
Image semantic segmentation, as the name suggests, involves grouping or segmenting image pixels based on their semantic meaning.
Image semantics refer to the understanding of the content of an image, such as what objects are present and what actions are being performed. Segmentation refers to labeling each pixel in the image to indicate its category. In recent years, this has been applied in autonomous driving technology to segment street scenes for avoiding pedestrians and vehicles, as well as in medical image analysis for assisting in diagnosis.
The segmentation task is mainly divided into instance segmentation and semantic segmentation. Instance segmentation is a combination of object detection and semantic segmentation, with the previously mentioned Mask R-CNN being one of the classic network structures for instance segmentation. In the image semantic segmentation task, we mainly introduce ICNet, which balances accuracy and speed, and DeepLab’s latest and most effective DeepLab v3+.
• DeepLab v3+, the latest work in the DeepLab semantic segmentation series, merges multi-scale information through an encoder-decoder structure while retaining the original dilated convolution and ASPP layers. Its backbone network uses the Xception model, improving the robustness and operational speed of semantic segmentation, achieving a new state-of-the-art performance of 89.0 mIoU on the PASCAL VOC 2012 dataset.
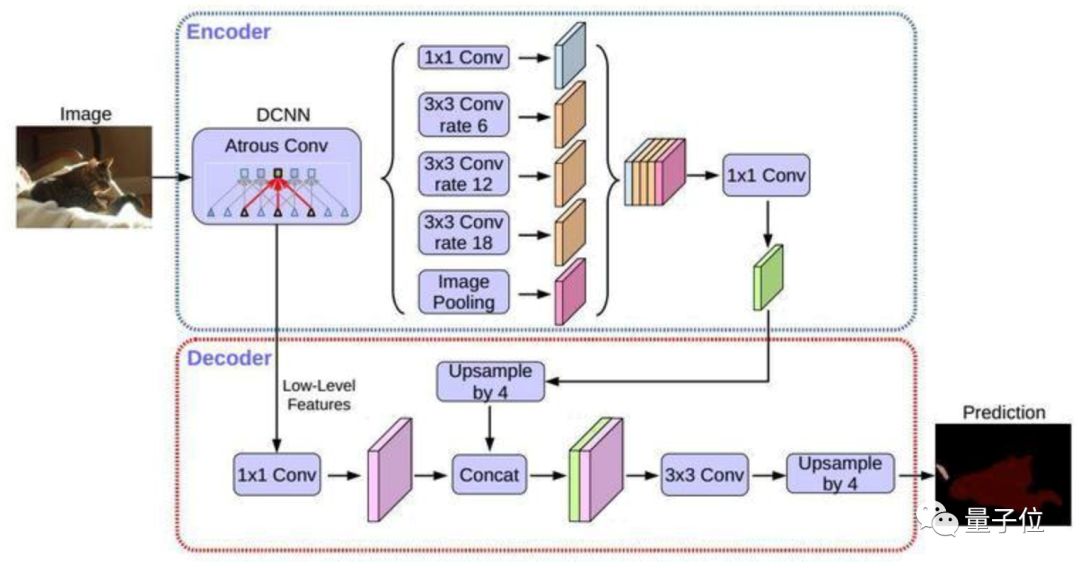 △ DeepLab v3+ Basic Structure
△ DeepLab v3+ Basic Structure
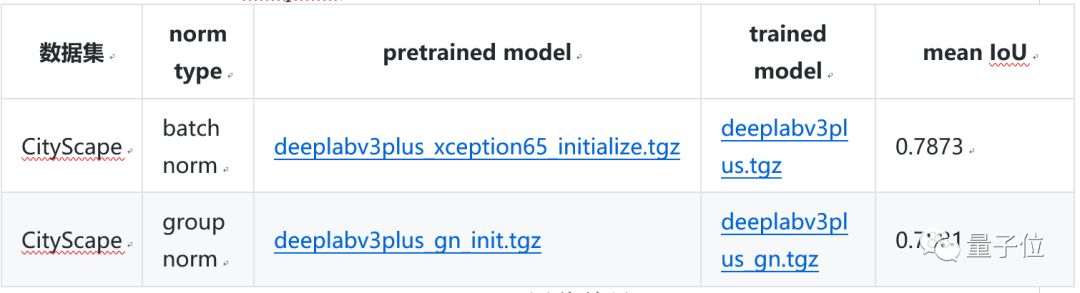
△ DeepLab v3+ Evaluation Results
As usual, the GitHub link is here (in Chinese):
https://github.com/PaddlePaddle/models/tree/develop/fluid/PaddleCV/deeplabv3%2B
• ICNet, Image Cascade Network, is primarily used for real-time semantic segmentation of images. The main idea is to transform the input image into different resolutions and use sub-networks of different computational complexities to process inputs of different resolutions, then combine the results. ICNet consists of three sub-networks, where the high-complexity network processes low-resolution inputs and the low-complexity network processes high-resolution inputs, achieving a balance between accuracy on high-resolution images and efficiency of low-complexity networks.
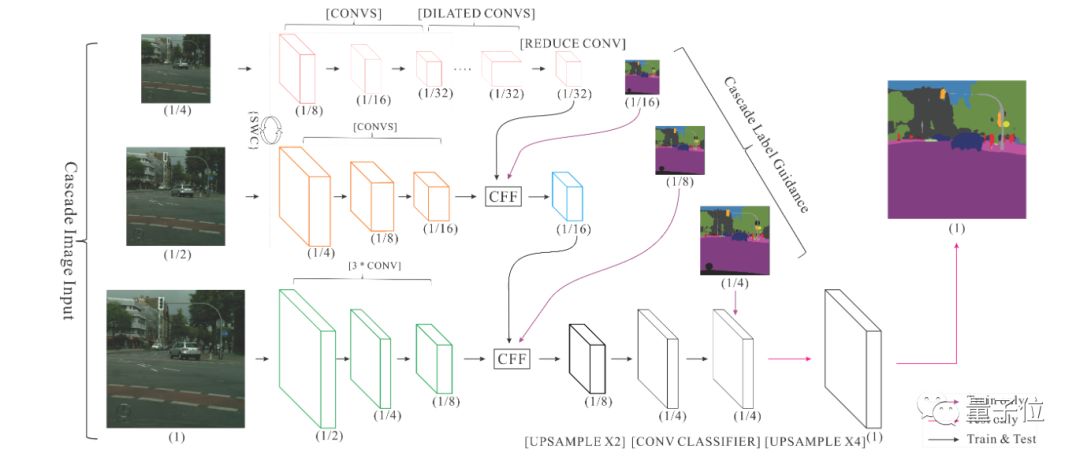 △ ICNet Network Structure
△ ICNet Network Structure
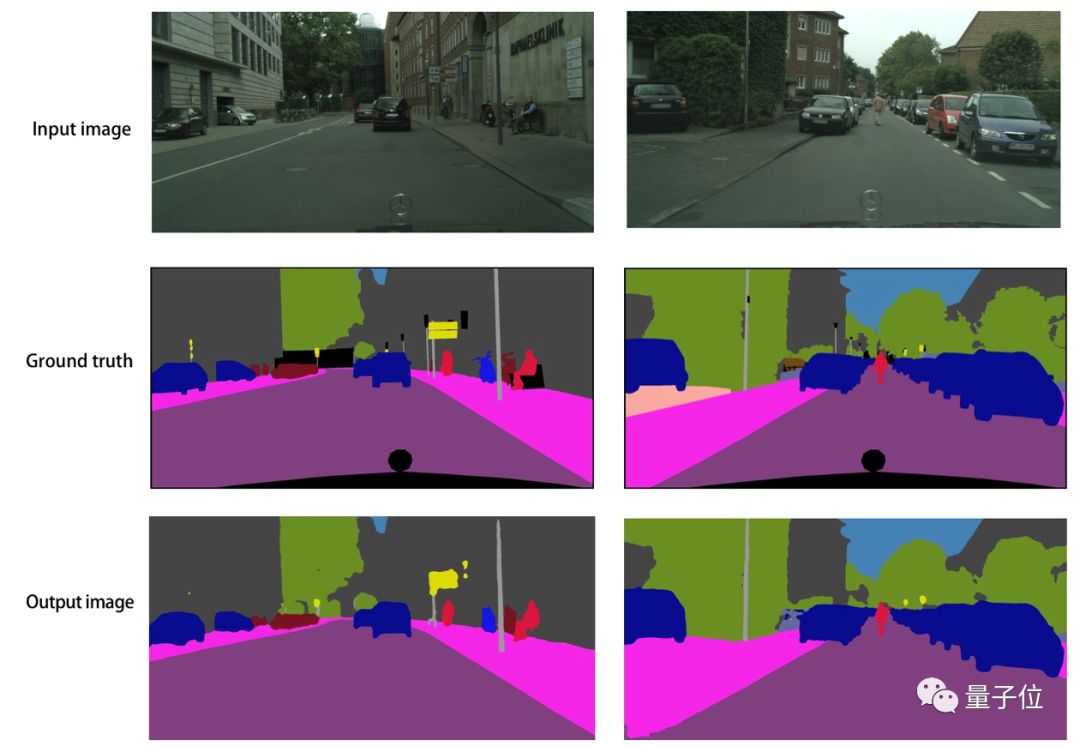 △ ICNet Visualization
△ ICNet Visualization
 △ ICNet Evaluation Results
△ ICNet Evaluation Results
The link for further hands-on practice is here (also in Chinese):
https://github.com/PaddlePaddle/models/tree/develop/fluid/PaddleCV/icnet
4. Scene Text Recognition
Many scene images contain rich text information that plays an important role in understanding the content of the image, greatly aiding people’s cognition and understanding of scene images. Scene text recognition is the process of converting image information into text sequences under complex backgrounds, low resolutions, diverse fonts, and arbitrary distributions. It can be considered a special translation process: translating image input into natural language output. The development of scene text recognition technology has also facilitated the emergence of new applications, such as automatically recognizing text in road signs to help street view applications obtain more accurate address information.
In the scene text recognition task, we introduce how to combine CNN-based image feature extraction with RNN-based sequence translation techniques, eliminating the need for manually defined features and avoiding character segmentation. Instead, automatically learned image features are used to complete character recognition. Here, we mainly introduce the CRNN-CTC model and a sequence-to-sequence model based on the attention mechanism.
• CRNN-CTC Model adopts a CNN+RNN+CTC architecture, using convolutional layers to extract feature sequences from input images, RNN for predicting the label (true value) distribution from the feature sequences obtained from the convolutional layer, and CTC for converting the label distribution from the RNN into the final recognition result through deduplication and integration operations.
• Attention Mechanism-Based Sequence-to-Sequence Model proposes a text recognition method based on the attention mechanism, which does not require detection and directly inputs images for recognition. This is particularly useful for scenes with a small number of character categories, such as license plate recognition and extraction of main keywords from natural scene images. It also does not require the text to be arranged in a single line; it can handle double and multi-line arrangements. During training, there is no need for text box annotations, making data collection much more convenient.
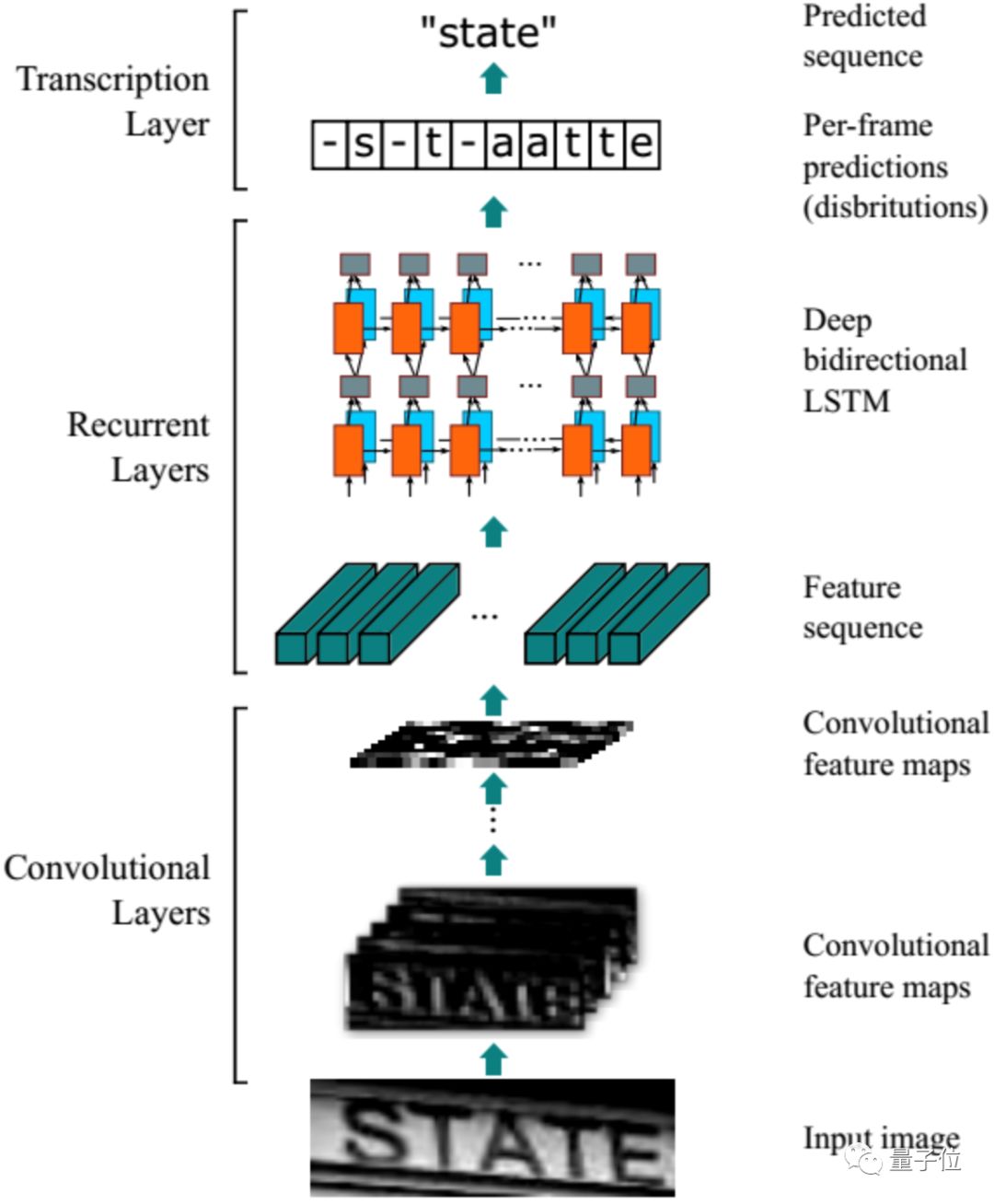
△ CRNN-CTC Model Structure
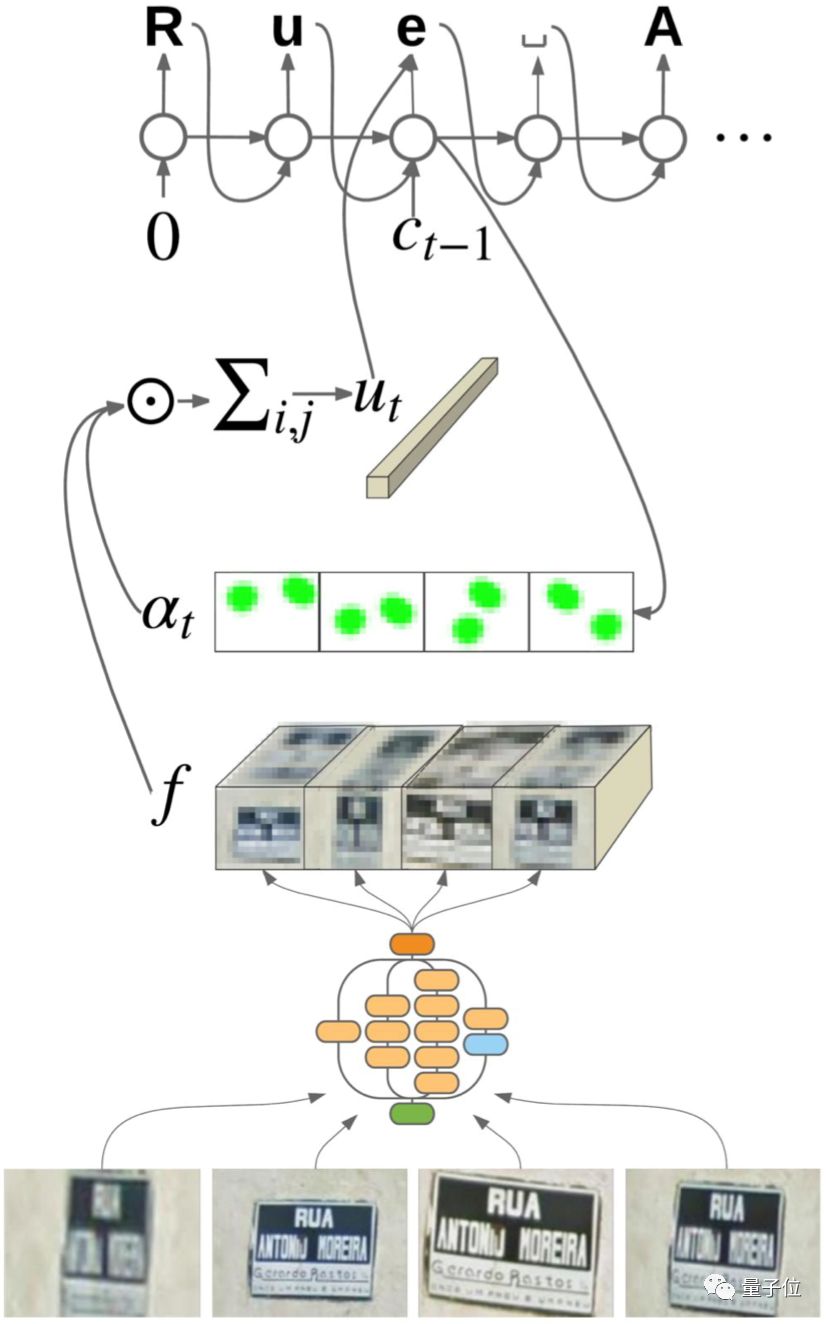
△ Attention Mechanism-Based Sequence-to-Sequence Model Structure
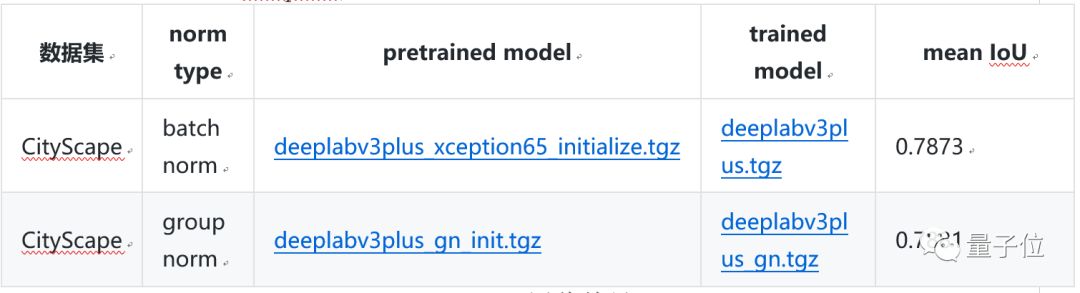 △ OCR Model Evaluation Results
△ OCR Model Evaluation Results
The GitHub link is here (friendly in Chinese):
https://github.com/PaddlePaddle/models/tree/develop/fluid/PaddleCV/ocr_recognition
Next Article
In the previous article, we introduced how computer vision technology helps computers extract, analyze, and understand key information from single or multiple images in the four basic task scenarios of image classification, object detection, image semantic segmentation, and scene text recognition. Nowadays, video is becoming increasingly important in people’s lives, and with the maturation of technology, breakthroughs in computer vision technology are shifting from “seeing” static image recognition to “understanding” video.
Next, we will explore deep learning models related to image generation, human keypoint detection, and video classification based on PaddlePaddle.
1. Image Generation
Image generation refers to generating target images based on input vectors. The input vectors can be random noise or user-specified condition vectors. Specific application scenarios include: handwriting generation, face synthesis, style transfer, image restoration, super-resolution reconstruction, etc. Current image generation tasks are primarily achieved using Generative Adversarial Networks (GANs).
Generative Adversarial Networks (GANs) consist of two sub-networks: a generator and a discriminator. The generator takes random noise or condition vectors as input and outputs the target image. The discriminator is a classifier that takes an image as input and outputs whether the image is real or not. During training, the generator and discriminator improve their capabilities through continuous adversarial training.
In the image generation task, we mainly introduce how to use DCGAN and Conditional GAN for generating handwritten digits, as well as CycleGAN for style transfer.
• Conditional GAN, as the name suggests, is a generative adversarial model with conditional constraints. It introduces additional condition variables in both the generative and discriminative modeling, guiding the generator in data generation. Conditional GAN improves unsupervised GANs into supervised models, providing guidance for subsequent work.
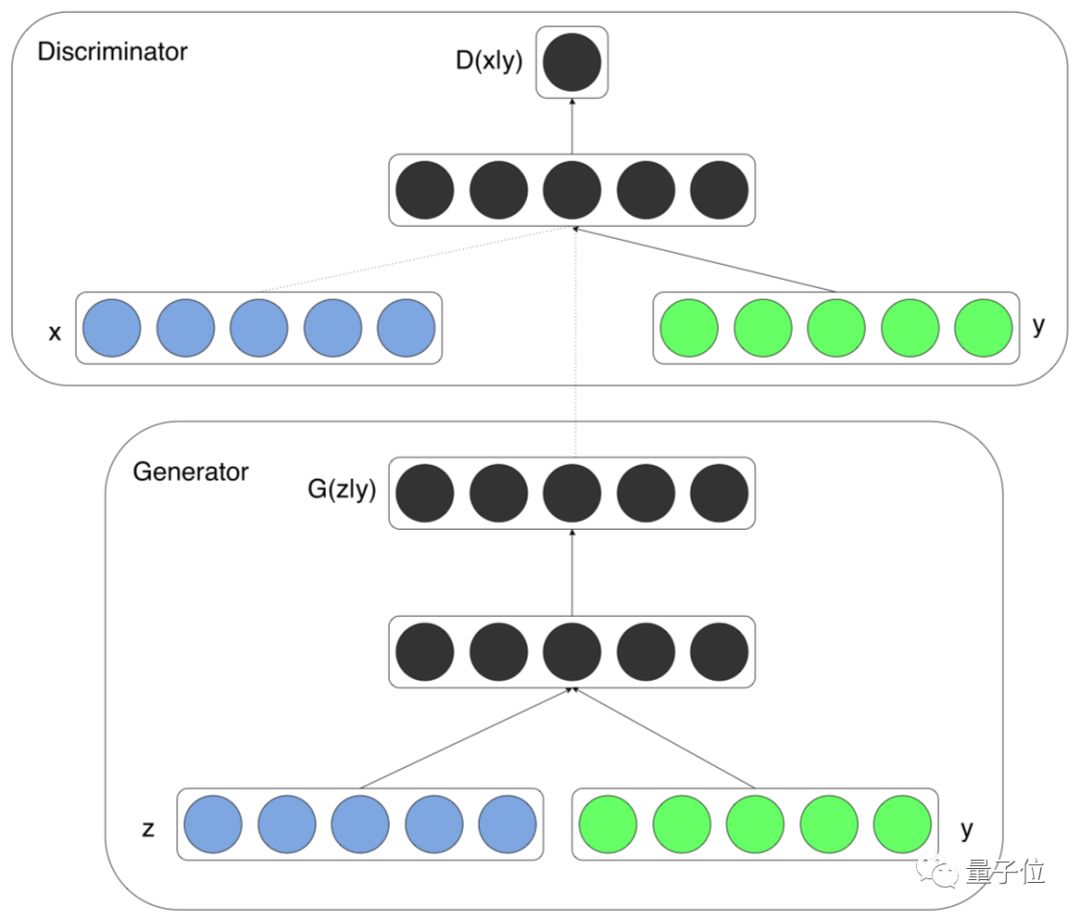 △ Conditional GAN Structure
△ Conditional GAN Structure
 △ Conditional GAN Prediction Effect
△ Conditional GAN Prediction Effect
Link (in Chinese):
https://github.com/PaddlePaddle/models/tree/develop/fluid/PaddleCV/gan/c_gan
• DCGAN was proposed to bridge the gap between supervised and unsupervised learning by combining CNN and GAN, achieving good results in unsupervised learning.
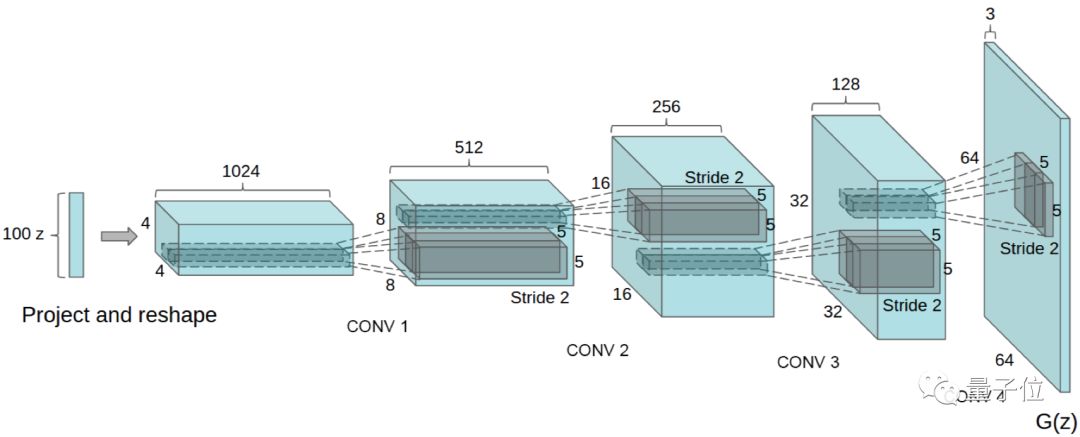 △ DCGAN Structure
△ DCGAN Structure

△ DCGAN Prediction Effect
Link (in Chinese):
https://github.com/PaddlePaddle/models/tree/develop/fluid/PaddleCV/gan/c_gan
• CycleGAN transforms one type of image into another. Traditional GANs generate in one direction, while CycleGAN generates mutually, consisting of two mirror-symmetric GANs, forming a cyclic network, hence the name Cycle. Style transfer tasks generally require paired images with the same content in two domains as training data. The innovation of CycleGAN lies in its ability to transfer image content from the source domain to the target domain without paired training data.
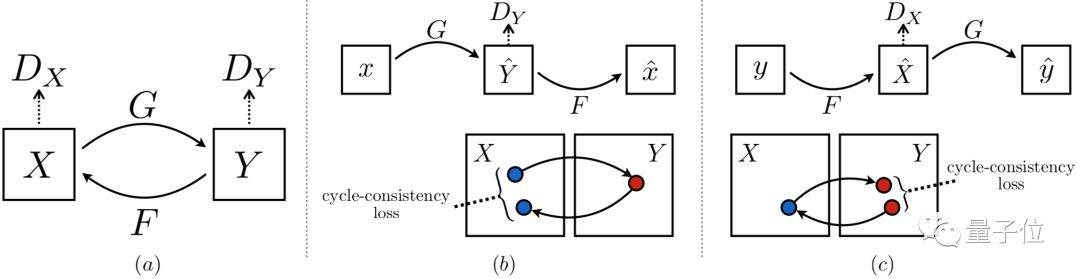 △ CycleGAN Structure
△ CycleGAN Structure
 △ CycleGAN Prediction Visualization
△ CycleGAN Prediction Visualization
Link (in Chinese):
https://github.com/PaddlePaddle/models/tree/develop/fluid/PaddleCV/gan/cycle_gan
2. Human Keypoint Detection
Human keypoint detection identifies human motion and behavior through the combination and tracking of key human nodes, which is crucial for describing human posture and predicting human behavior. It serves as the foundation for many computer vision tasks, such as action classification, abnormal behavior detection, and autonomous driving, and provides new interaction methods for games and videos.
In the human keypoint detection task, we mainly introduce the runner-up solution from the coco2018 keypoint detection project with a simple network structure.
• Simple Baselines for Human Pose Estimation in Fluid is the runner-up solution for the coco2018 keypoint detection project. It does not involve elaborate techniques, merely inserting a few deconvolution layers into ResNet to expand low-resolution feature maps to the original image size, generating the heatmap needed for predicting keypoints. It does not involve any feature fusion, and the network structure is very simple, yet it achieves state-of-the-art performance.

△ Video Demo: Bruno Mars – That’s What I Like [Official Video]

△ Simple Baselines for Human Pose Estimation in Fluid Evaluation Results
GitHub link:
https://github.com/PaddlePaddle/models/tree/develop/fluid/PaddleCV/human_pose_estimation
3. Video Classification
Video classification is the foundation of video understanding tasks. Unlike image classification, the classification object is no longer a still image, but a video object composed of multiple frames, containing audio data and motion information. Therefore, understanding videos requires obtaining more contextual information; it is necessary to understand what each frame is and what it contains, while also knowing the contextual relationships between different frames.
Video classification methods mainly include those based on convolutional neural networks, recurrent neural networks, or a combination of both.
In the video classification task, we mainly introduce several mainstream leading models in the video classification direction, among which Attention LSTM, Attention Cluster, and NeXtVLAD are popular feature sequence models, while TSN and StNet are two end-to-end video classification models.
The Attention LSTM model is fast and accurate, NeXtVLAD is the best single model in the second YouTube-8M competition, and TSN is a classic solution based on 2D-CNN. Attention Cluster and StNet are models developed by Baidu, published at CVPR2018 and AAAI2019 respectively, and were used in the first place model in the Kinetics600 competition.
• Attention Cluster model is the best sequence model in the ActivityNet Kinetics Challenge 2017, processing extracted RGB, Flow, and Audio data through Attention Clusters with Shifting Operation.
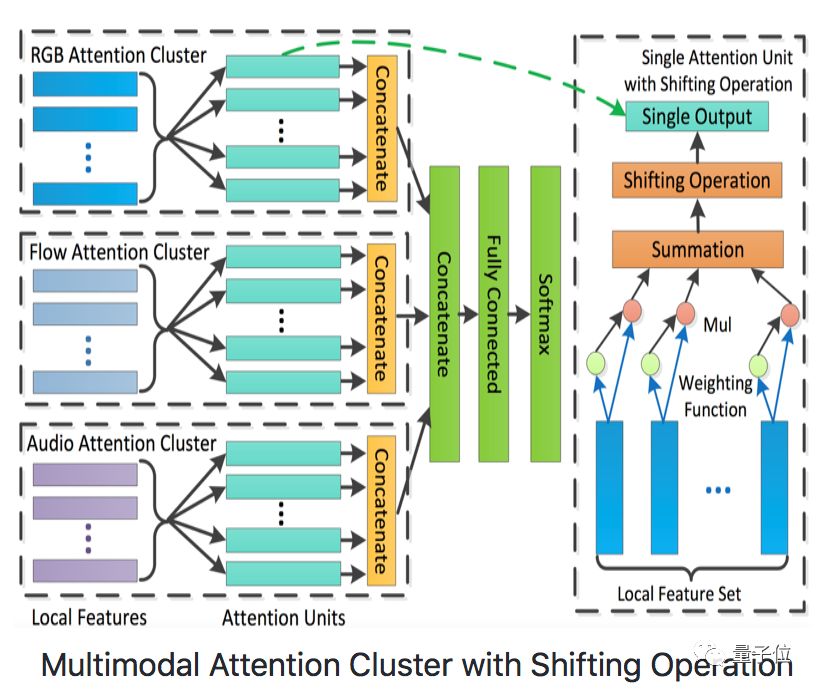 △ Attention Cluster Model Structure
△ Attention Cluster Model Structure
Attention LSTM model employs a bidirectional long short-term memory network (LSTM) to sequentially encode the features of all frames in the video. Unlike traditional methods that directly use the output of the last moment of LSTM, this model adds an Attention layer, giving each moment’s hidden state output an adaptive weight, and then linearly weighting to obtain the final feature vector.
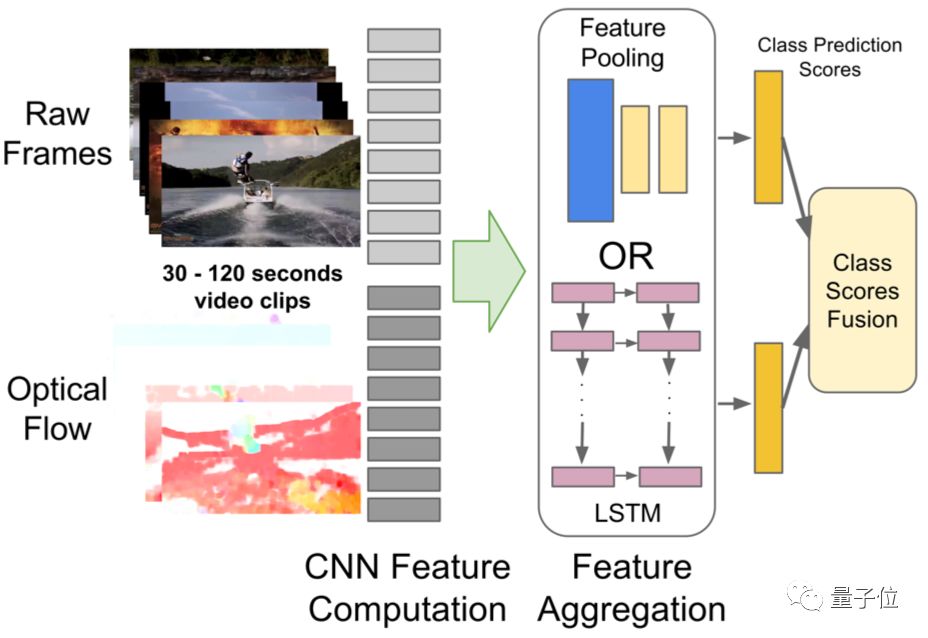 △ Attention LSTM Model Structure
△ Attention LSTM Model Structure
• NeXtVLAD Model is the best single model in the second YouTube-8M video understanding competition, providing a method to convert and compress frame-level video features into feature vectors for classifying large video files. Its basic premise is to group high-dimensional features based on the NetVLAD model, aggregating temporal information by introducing an attention mechanism, thereby achieving high accuracy while using fewer parameters.
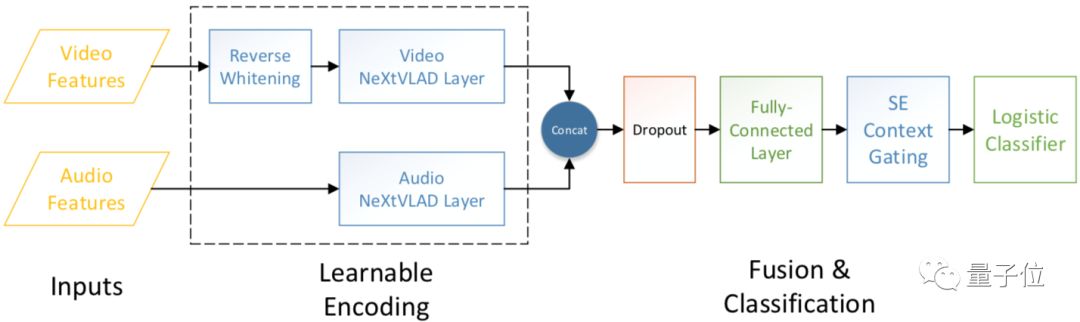 △ NeXtVLAD Model Structure
△ NeXtVLAD Model Structure
• StNet Model is the foundational network framework that won the ActivityNet Kinetics Challenge 2018, proposing the concept of “super-image” and performing 2D convolution on the super-image to model local spatiotemporal correlations in videos. Additionally, it models the global spatiotemporal dependencies of videos through a temporal modeling block and finally uses a temporal Xception block to model the extracted feature sequence over long time periods.
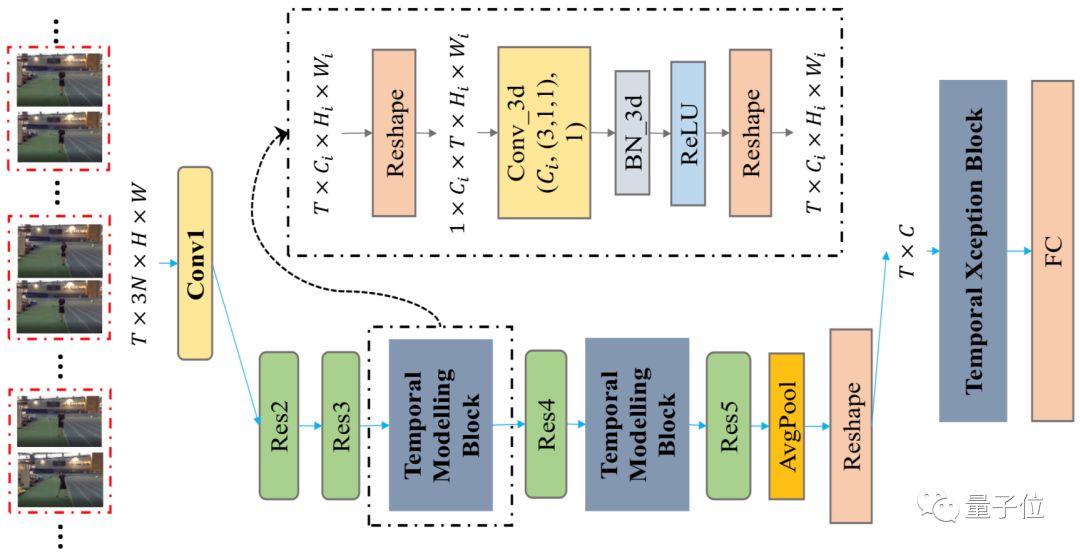 △ StNet Model Structure
△ StNet Model Structure
• Temporal Segment Network (TSN) is a classic 2D-CNN based solution in the video classification field, primarily addressing the long-term behavior judgment problem in videos. It replaces dense sampling with sparse sampling of video frames, capturing global information while eliminating redundancy and reducing computational load. Finally, the features of each frame are averaged to obtain the overall features of the video for classification.
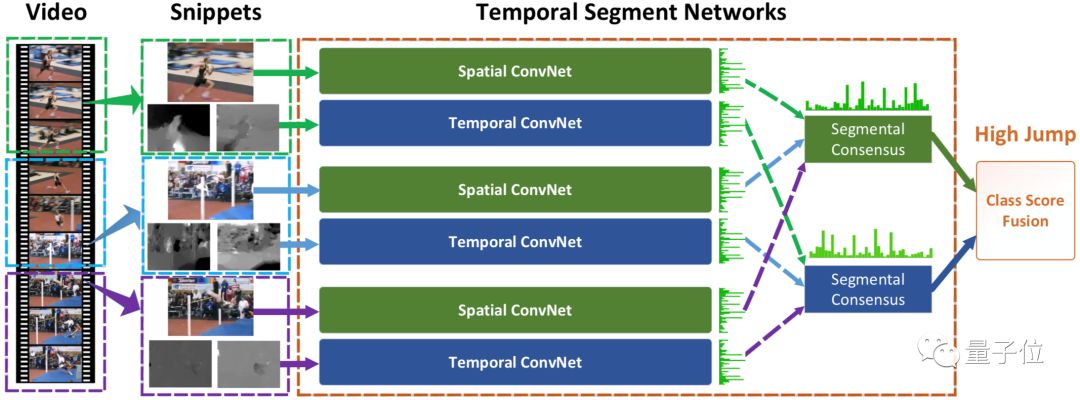 △ TSN Model Structure
△ TSN Model Structure
 △ Video Classification Model Evaluation Results Based on YouTube-8M Dataset
△ Video Classification Model Evaluation Results Based on YouTube-8M Dataset
 △ Video Classification Model Evaluation Results Based on Kinetics Dataset
△ Video Classification Model Evaluation Results Based on Kinetics Dataset
For more details, you can visit GitHub, fully in Chinese. The link is:
https://github.com/PaddlePaddle/models/tree/develop/fluid/PaddleCV/video
4. Metric Learning
Metric learning, also known as distance metric learning or similarity learning, analyzes the relationships and comparisons between objects by learning the distances between them. It is widely applied in practical problems to assist in classification and clustering, and is also widely used in image retrieval, face recognition, and other fields.
Previously, different tasks required selecting suitable features and manually constructing distance functions. However, metric learning can autonomously learn distance functions tailored for specific tasks. The combination of metric learning and deep learning has achieved better performance in fields such as face recognition/verification, human re-identification (human Re-ID), and image retrieval. In this task, we mainly introduce deep metric learning models based on Fluid, including triplet and quadruplet loss functions.
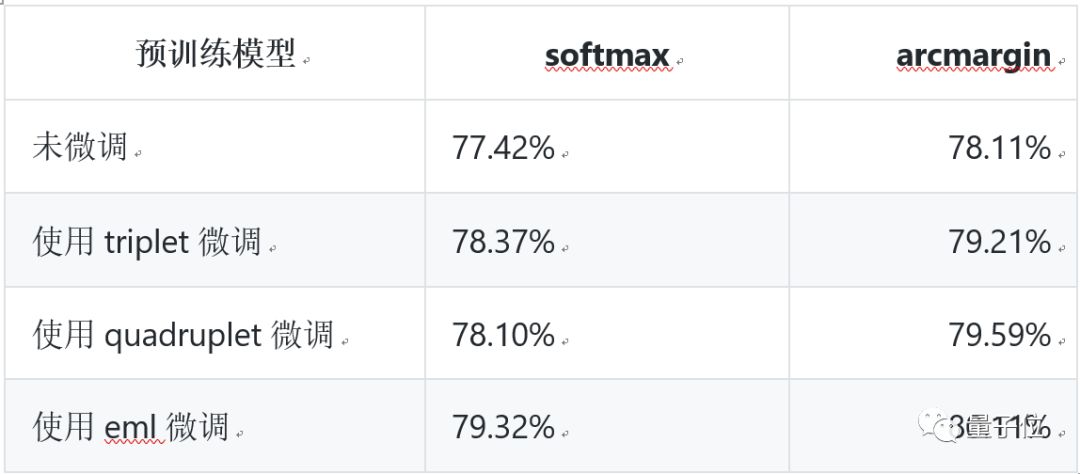 △ Metric Learning Model Evaluation Results
△ Metric Learning Model Evaluation Results
The GitHub page provides guidance on installation, preparation, training, and more. The link is:
https://github.com/PaddlePaddle/models/tree/develop/fluid/PaddleCV/metric_learning
The author is a contracted writer for NetEase News – NetEase Account “Each Has Its Attitude”
— End —

The Quantum Bit AI community is beginning recruitment. The Quantum Bit community consists of AI discussion groups, AI+ industry groups, and AI technology groups. We welcome students interested in AI to reply with the keyword “WeChat group” in the dialogue interface of the Quantum Bit public account (QbitAI) to obtain group joining methods. (The technology group and AI+ industry group require approval, and the review is strict, please understand)
Quantum Bit is recruiting editors/reporters, with the workplace located in Zhongguancun, Beijing. We look forward to talented and passionate students joining us! For details, please reply with the word “Recruitment” in the dialogue interface of the Quantum Bit public account (QbitAI).

Quantum Bit QbitAI · Contracted Author for Toutiao Account
վ’ᴗ’ ի Tracking new dynamics in AI technology and products