Hello everyone, today we are going to talk about an important concept in deep learning – Convolutional Neural Networks (CNN). Whether you are a programmer, a data scientist, or a friend interested in artificial intelligence, I believe that after reading this article, you will have a clear understanding of CNN.
1. What is Convolutional Neural Network?
Convolutional Neural Network (CNN) is an important algorithm in the field of deep learning, especially performing exceptionally well in computer vision tasks. In simple terms, CNN is a neural network model specifically designed for processing grid structure data (such as images). It is inspired by the structure of the visual cortex in biology, capturing local features in images through local receptive fields, and then combining them layer by layer to extract higher-level features.
2. Why Do We Need Convolutional Neural Networks?
In traditional Fully Connected Neural Networks, each neuron is connected to all neurons in the previous layer. For high-dimensional data like images, this connection method leads to a massive number of parameters, extremely high computational complexity, and a tendency to overfit. CNN significantly reduces the number of parameters and computational complexity through local connections and weight sharing, while improving the model’s generalization ability.
3. Core Components of Convolutional Neural Networks
A typical Convolutional Neural Network mainly consists of the following core components:
1. Input Layer
The input layer is the first layer of CNN, responsible for receiving raw image data or other types of grid structure data. This data can be grayscale images, color images, sound signals, etc. In image processing, the input layer usually normalizes the image so that its pixel values fall within a reasonable range (e.g., between 0 and 1).
2. Convolution Layer
The convolution layer is one of the core components of CNN, extracting features from the input data through convolution operations. The convolution operation involves applying multiple learnable filters (or convolution kernels) to the input image, each producing a feature map representing different features of the input image, such as edges, textures, etc.
- Convolution Kernel: The convolution kernel is a small matrix that slides over the input image, generating feature maps through convolution operations. The size (e.g., 3×3, 5×5) and number (i.e., the number of filters) of convolution kernels are important hyperparameters in CNN design.
- Stride: The distance the convolution kernel slides over the input image. A larger stride results in a smaller output feature map size.
- Padding: To control the output feature map size, additional pixels (usually 0) may sometimes be added to the edges of the input image.
3. Activation Function
The convolution layer is typically followed by a non-linear activation function, such as ReLU (Rectified Linear Unit). The activation function helps introduce non-linearity, enabling the network to learn complex patterns and features.
4. Pooling Layer
The pooling layer reduces the size of the feature maps through down-sampling (such as max pooling or average pooling), thereby lowering the computational load while maintaining the most important features. Pooling operations also enhance the model’s robustness to feature locations.
5. Fully Connected Layer
At the end of the network, there are usually one or more fully connected layers. Fully connected layers combine the extracted features and output the final prediction results through activation functions. Fully connected layers are often used in classification tasks to map the extracted features to category labels.
6. Normalization Layer
To speed up network training and improve stability, normalization layers, such as Batch Normalization, are often added to the network. Normalization layers can reduce internal covariate shifts, making the network easier to train.
4. Workflow of Convolutional Neural Networks
The workflow of Convolutional Neural Networks typically includes the following steps:
- Input Data Preparation: The input is usually an image or multi-channel image data. CNN normalizes the image.
- Feature Extraction: Through a series of convolution layers and activation functions, the features of the input image are gradually extracted. Early convolution layers typically extract low-level features (such as edges and textures), while subsequent layers extract higher-level features (such as shapes and object contours).
- Feature Reduction and Dimensionality Reduction: Pooling layers and normalization layers further reduce the size of the feature maps while retaining important feature information.
- Feature Mapping to Output: The extracted features are combined through fully connected layers, ultimately outputting classification results or predictions for other tasks.
5. Example of Convolutional Neural Networks
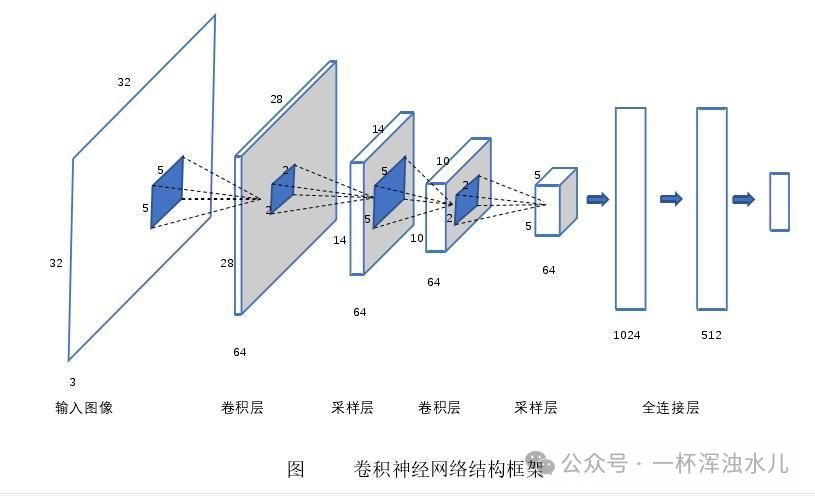
To better understand the working principle of Convolutional Neural Networks, let’s look at a specific example. Suppose we have a 32×32 grayscale image (single channel) and we want to build a simple CNN for handwritten digit recognition (like the MNIST dataset).
1. Input Layer
The input layer receives this 32×32 grayscale image and flattens it into a 784 (32*32) dimensional vector. However, in practical applications, we usually maintain the spatial structure of the image, meaning the input layer size is 32x32x1.
2. Convolution Layer (CONV1)
We use 6 convolution kernels of size 5×5 for convolution operations with a stride of 1 and no padding. Each convolution kernel generates a feature map, resulting in an output size of (32-5+1)x(32-5+1)=28×28, with a total of 6 feature maps, meaning the output size is 28x28x6.
3. Activation Function (ReLU)
Apply the ReLU activation function to the output of the convolution layer to introduce non-linearity.
4. Pooling Layer (POOL1)
Perform max pooling on the output of ReLU with a pooling window of 2×2 and a stride of 2. Therefore, the output size is (28/2)x(28/2)=14×14, with the number of channels remaining unchanged, resulting in an output size of 14x14x6.
5. Convolution Layer (CONV2)
We use 16 convolution kernels of size 5×5 for convolution operations with a stride of 1 and no padding. Each convolution kernel generates a feature map, resulting in an output size of (14-5+1)x(14-5+1)=10×10, with a total of 16 feature maps, meaning the output size is 10x10x16.
6. Activation Function (ReLU)
Apply the ReLU activation function again to the output of the convolution layer.
7. Pooling Layer (POOL2)
Perform max pooling on the output of ReLU with a pooling window of 2×2 and a stride of 2. Thus, the output size is (10/2)x(10/2)=5×5, with the number of channels remaining unchanged, resulting in an output size of 5x5x16.
8. Fully Connected Layer (FC1)
Flatten the output of the pooling layer into a one-dimensional vector, i.e., 5x5x16=400 dimensions. Then connect to a fully connected layer, assuming there are 120 neurons.
9. Activation Function (ReLU)
Apply the ReLU activation function to the output of the fully connected layer.
10. Fully Connected Layer (FC2)
Connect to another fully connected layer, assuming there are 84 neurons.
11. Output Layer
Finally, connect to a fully connected layer with an output size of 10 (corresponding to the 10 digits 0-9). Use the softmax activation function to convert the output into a probability distribution.
6. Application Scenarios of Convolutional Neural Networks
Convolutional Neural Networks perform exceptionally well in various computer vision tasks, including but not limited to:
- Image Classification: Such as image classification tasks in the ImageNet Large Scale Visual Recognition Challenge (ILSVRC).
- Object Detection: Algorithms like R-CNN, YOLO, and SSD that locate and identify multiple objects in images.
- Image Segmentation: Networks like U-Net and SegNet that accurately segment different parts of an image.
- Face Recognition: CNNs are highly effective in facial feature extraction and are widely used in face recognition systems.
- Natural Language Processing: Although CNNs are primarily used for image processing, they have also been successfully applied in natural language processing tasks, such as text classification and sentiment analysis.
7. Conclusion
As a shining gem in the field of deep learning, Convolutional Neural Networks have achieved great success in various domains such as computer vision and natural language processing. Through this introduction, I believe you now have a preliminary understanding of CNN. In the future, as technology continues to evolve, the application prospects for CNN will be even broader. If you are interested in CNN, why not try it out yourself? I believe you will gain a deeper understanding and insights.