
Introduction to CNN (Convolutional Neural Network)
A convolutional neural network is a deep learning algorithm specifically designed for processing images and videos. It takes images as input, extracts and learns features from the images, and classifies them based on the learned features.
The inspiration for this algorithm comes from a part of the human brain, namely the visual cortex. The visual cortex is responsible for processing visual information from the outside world. It has different layers, each with its own function, meaning each layer extracts some information from the image or any visual input, and finally combines all the information received from each layer to interpret or classify the image/visual input.
Similarly, CNNs have various filters, each extracting some information from the image, such as edges and different types of shapes (vertical, horizontal, circular), and then combining all these to recognize the image.
Now, the question might be: why can’t we use artificial neural networks for the same purpose? This is because ANN has some disadvantages:
- The computational load for training large-size images and different types of image channels is too high for ANN models.
- It cannot capture all the information from images, while CNN models can capture the spatial dependencies of images.
- Another reason is that artificial neural networks are very sensitive to the position of objects in images, meaning if the position or location of the same object changes, it cannot classify correctly.
Components of CNN (Convolutional Neural Network)
The CNN model works in two steps: feature extraction and classification
Feature extraction is the stage where various filters and layers are applied to the image to extract information and features, which are then passed to the next stage, classification, where they are classified based on the target variable of the problem.
A typical CNN model is as follows:
- Input layer
- Convolutional layer + Activation function
- Pooling layer
- Fully connected layer
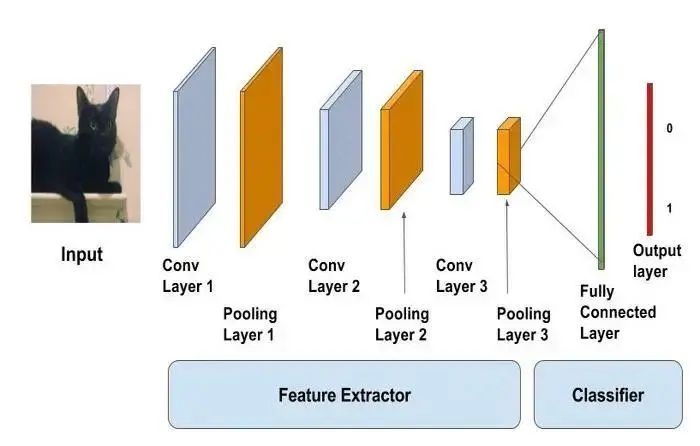
Complete Process:
Step 1: Import Required Packages
import torch
import torch.nn as nn
import torch.utils.data as Data
from torch.autograd import Variable
import torchvision # A visual processing toolkit for pytorch (needs to be installed separately)
- Main packages in PyTorch
- torch.nn: Contains subpackages for building neural network modules and extensible classes.
- torch.autograd: Subpackage that supports all differentiable tensor operations in PyTorch.
- torch.nn.functional: A functional interface that includes typical operations for building neural networks, such as loss functions, activation functions, and convolution operations.
- torch.optim: Contains subpackages for standard optimization operations (like SGD and Adam).
- torch.utils: A toolkit that contains utility classes for datasets and data loaders, making data preprocessing easier.
- torchvision: A package that provides access to popular datasets, model architectures, and computer vision image transformations.
Step 2: Data Preprocessing
First, let’s discuss the reason for converting data into tensors
- The significance of tensors: Tensors in PyTorch are analogous to arrays in Numpy or DataFrames in Pandas; they are the most fundamental data structure in the entire framework.
- The distinction of tensors: Tensors differ from ordinary data structures as they have a crucial feature—automatic differentiation—and they represent a multi-dimensional matrix that can also be utilized on GPUs for accelerated computation.
- There are three very important classes for handling datasets in PyTorch: Dataset, Dataloader, and Sampler, all of which are modules (classes) under the torch.utils.data package.
- Dataloader is the data loading class, which is a further wrapper for Dataset and Sampler, used for actually reading data; it can be understood as the true practitioner of this work.
About Datasets in torchvision
- All the packaged datasets in torchvision.datasets are subclasses of torch.utils.data.Dataset and can be loaded using torch.utils.data.DataLoader. For example, the datasets.MNIST class has the following parameters and usage:
CLASS torchvision.datasets.MNIST(
root: str,
train: bool = True,
transform: Optional[Callable] = None,
target_transform: Optional[Callable] = None,
download: bool = False
)
- root (string): Indicates the root directory of the dataset, where subdirectories MNIST/processed/training.pt and MNIST/processed/test.pt exist (essentially specifying the location for the downloaded files).
- train (bool, optional): If True, creates the dataset from training.pt; otherwise, from test.pt.
- download (bool, optional): If True, downloads the dataset from the internet and places it in the root directory. If the dataset has already been downloaded, it will not download again.
- transform (callable, optional): A transformation function that receives a PIL image and returns the transformed version of the image (essentially converting the image or numpy array into a tensor).
- target_transform (callable, optional): A transformation function that receives the target and transforms it.
What is Variable?
- A variable is a wrapper around a tensor. In neural networks, it is often necessary to backpropagate these, so each node needs to be connected together as a computation graph; the data format of a tensor is like a spark, but it cannot converge together; once it becomes a variable, it can slowly spread.
Code Analysis
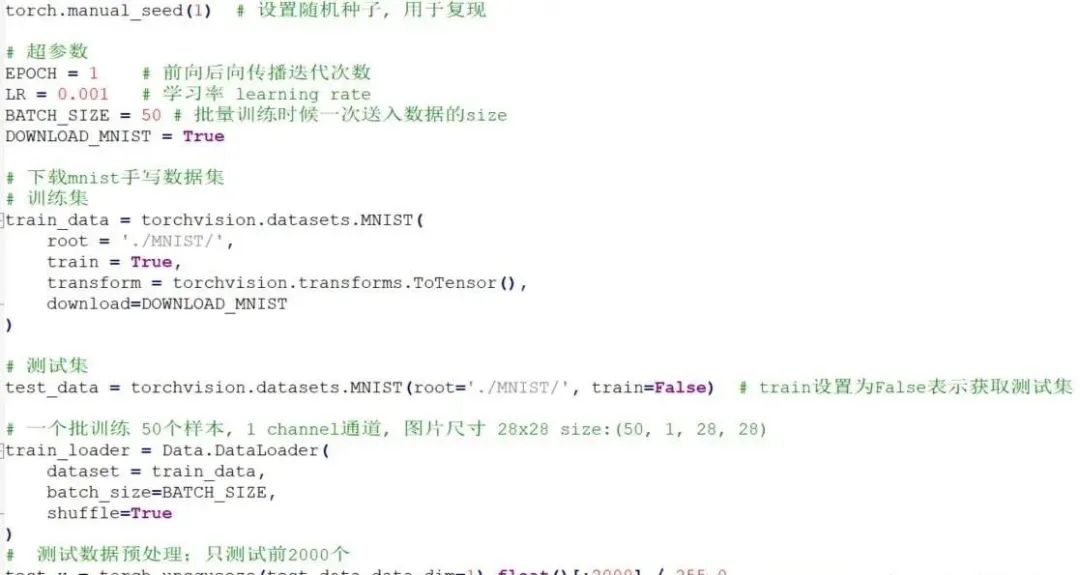
- Data.DataLoader: Loads data
- shuffle: Indicates whether to shuffle the order of the data.
- torch.unsqueeze: My personal understanding is that it changes the shape of the data; here it is used to