


Author | Mandy Gu
Translator | Ma Kewei
Planner | Tina
Summary
-
Generative AI can ensure data security through data anonymization and local model deployment while effectively enhancing employee productivity.
-
Centralized management of tools that aligns with user behavior patterns is a key factor for successful implementation.
-
Adopting trend technologies such as multimodal input and open standards can maintain the forward-looking nature of AI strategies.
-
Not all attempts at generative AI will succeed; careful strategy formulation and focus on business compatibility are necessary.
-
Generative AI has evolved from initial hype to actual application, entering the “enlightenment slope” of the technology maturity curve.
On November 30, 2022, OpenAI released ChatGPT, changing the world’s perception and usage of generative artificial intelligence (GenAI). This previously niche and obscure technology has since become accessible to everyone, with the democratization of AI technology bringing about a dual leap in innovation and productivity across multiple fields and business roles.
Wealthsimple, a Canadian platform focused on financial inclusion services, is also excited about the potential of generative AI. This article is based on the author’s speech at the 2024 QCon conference in San Francisco, sharing how Wealthsimple leverages generative AI to enhance productivity and the lessons learned along the way.
Wealthsimple’s generative AI practices focus on three main directions. The first is enhancing employee productivity; this is not only the initial value realization concept of large language models (LLM) but also a key area for continued investment in the current environment.
As the infrastructure and productivity tools gradually improve, Wealthsimple began shifting its focus to the second direction: operational optimization. The core goal in this area is to create a better customer experience through LLM and generative AI.
The third major direction is the construction of an underlying LLM platform, which supports the development of the first two directions. Wealthsimple has independently developed and open-sourced an LLM gateway, with over half of the internal teams already connected and using it. They have also built a corporate-level personal identifiable information (PII) anonymization model, achieving rapid autonomous deployment of open-source LLM in their own cloud environment, and supporting hardware-accelerated model training and fine-tuning.
LLM Development History – 2023
The first thing we did in 2023 was to build the LLM gateway. When ChatGPT first became popular, there wasn’t as strong an awareness of third-party data sharing as there is now. At that time, many companies inadvertently leaked information to OpenAI, which could potentially be used to train future public models. To prevent such situations, many companies outright banned employees from using ChatGPT.
However, Wealthsimple has always believed in the value of generative AI, so we decided to build a solution that ensures security and privacy while not restricting free exploration. The core function of the initial gateway was very simple: to establish a complete auditing and tracking system that accurately records which data was sent externally, to whom, and by whom.
This gateway is open to all employees, and the workflow involves forwarding conversation content to LLM service providers like OpenAI while recording data flow throughout the process. Users can select different models to start conversations through a dropdown menu, and the production system can also interact with the model via our LLM service’s API interface, which comes with intelligent retry and fault recovery mechanisms.
After completing the gateway setup, we encountered an adoption challenge: people were reluctant to use this gateway. Wealthsimple’s core philosophy is “making the right method the simplest choice,” so we promoted adoption through a combination of soft and hard strategies, focusing more on reward mechanisms.
First, the gateway is free to use, with all API costs covered by the company. Secondly, we created a unified LLM interaction platform. Initially supporting only OpenAI and Cohere, we gradually expanded the list of service providers.
We also made significant optimizations for developer usage. Early on, when integrating with OpenAI, the stability of their servers was not ideal. To address this, we introduced intelligent retry and fault recovery mechanisms to enhance reliability, while also negotiating with OpenAI to increase our call rate limits.
While implementing the reward mechanism, we also set several soft constraints. The first was a “reminder system”: when employees directly accessed ChatGPT or other LLM service providers, they would receive a gentle prompt on Slack: “Have you heard of our LLM gateway? We recommend using it first!” We also established LLM usage guidelines, clearly requiring that all AI-related work scenarios must access through the gateway.
Although the initial gateway had a complete auditing and tracking function, it still had shortcomings in data leakage prevention. However, our long-term planning has always focused on three core aspects: security, reliability, and choice. We hope to build protective mechanisms for third-party LLM suppliers, making secure and compliant operational paths the most convenient choice.
Based on this goal, we launched our independently developed personal identifiable information (PII) anonymization model in June 2023. This model can automatically detect and mask sensitive information before data is sent to external LLM service providers. For example, the system can identify potentially sensitive personal information like phone numbers and automatically anonymize it.
Figure 1: PII Anonymization
However, while filling security gaps, we encountered new user experience issues. Many users reported that the anonymization model had accuracy problems, and excessive anonymization sometimes rendered the returned results worthless.
More critically, to truly leverage the value of LLM in employees’ daily work, they must be able to use non-anonymized personal information, as this data is inherently part of their work content. Therefore, we returned to the core philosophy of “making the right choice the simplest one” and began exploring self-hosted solutions for open-source LLM.
The advantage of self-hosted models is that they do not require the use of anonymization models, allowing people to send any information to these models while keeping that data within their own cloud environment. After a month of technical challenges, we ultimately built a simple self-hosted framework using the quantization framework llama.cpp, achieving private deployment of open-source LLM.
Next, we launched our first simple semantic search interface, the RAG API. We encourage developers and end users to create LLM applications that can integrate with company business scenarios based on this API and other foundational components.
Despite many users explicitly expressing the need for scenario-based implementation, theoretically this is indeed an important foundational capability of our platform, but the actual usage rate was surprisingly low. We realized that the issue might lie in user experience: the existing experimental and exploratory processes had clear gaps, making it difficult for developers to receive timely feedback when building generative AI products.
Based on this lack of feedback mechanism, we began to build a data application platform. We ultimately built an internal service platform using Python and Streamlit. We chose these two tech stacks because they are not only easy to get started with but also the most familiar technology combination for our data science team.
This platform significantly lowered the threshold for new application development and iteration. Many proof-of-concept (PoC) applications eventually evolved into larger systems. The data application platform was launched just two weeks ago and already supports seven internal applications. Two of these applications ultimately entered the production environment, continuously optimizing operational efficiency and creating a better customer experience.
As the LLM platform matures, we began to build internal tools to enhance employee productivity. The Boosterpack tool, launched at the end of 2023, is a personal smart assistant specifically designed for Wealthsimple’s business scenarios.
Users can upload documents through Boosterpack to create private or shared knowledge bases. Once created, they can use the conversation interface for intelligent Q&A. In addition to generating answers, the system will automatically attach reference links to the sources of knowledge, which is particularly useful for fact-checking or extended reading, especially in handling professional documents in the knowledge base.
LLM Development History – 2024
The end of 2023 concluded with great expectations. Throughout the year, we successively launched the LLM gateway, self-hosted models, RAG API, and data application platform, and by the end of the year, we created what we believe to be one of the most valuable internal tools. However, entering 2024, the development of AI caught us off guard.
The Gartner technology maturity curve accurately depicts the changing trajectory of expectations during the development of emerging technologies, which is particularly relevant for generative AI. In 2023, we were at the peak of expectation inflation, full of hope for the potential of LLM and eager to make a significant impact in this field. However, as we entered 2024, both our company and the entire industry became more rational: we realized that not all investments yield expected returns. This prompted us to adjust our strategy and focus more carefully on the alignment between generative AI applications and business needs, no longer blindly pursuing technological breakthroughs.
The first step on the path of LLM development in 2024 was to cut a feature that was introduced in 2023. When we launched the LLM gateway, we designed a reminder mechanism to notify employees who had not used the gateway via Slack. However, the reality was stark: the same group of people gradually became immune to the notifications after repeatedly receiving them, directly ignoring these alerts. We found that rather than relying on external reminders, it was better to guide employee behavior change through improvements within the platform itself.
We then began to increase the supported LLM service providers. The opportunity for this shift came with the release of Gemini. At that time, Gemini launched a model supporting a context window of around 1 million tokens, and we were very much looking forward to it solving many challenges previously caused by context limitations.
One of the key focuses in 2024 is to keep up with the latest industry trends. In 2023, we invested a lot of effort in ensuring our platform was equipped with the most advanced models, but soon realized that this was an endless race, as top models are updated almost every few weeks. Thus, we adjusted our strategy to focus not on a single model but on higher-dimensional trends.
Multimodal input is one of these emerging trends: no longer limited to text, users can now directly upload files or images. This trend quickly gained popularity within our company. We added multimodal functionality to the gateway, allowing end users to upload images or PDFs, and the LLM will engage in conversations based on this content. Within just a few weeks of launching this feature, nearly one-third of end users utilized the multimodal functionality at least once a week.
We found that the most common application scenario was when employees encountered issues with internal tools. For developers, receiving screenshots of error messages is a counterproductive pattern; they prefer to receive error information in text format directly.
While humans lack patience for this form of communication, LLM can easily handle it. Soon, we observed a change in how people communicated, as the multimodal input feature of LLM made sending screenshots of information extremely simple.
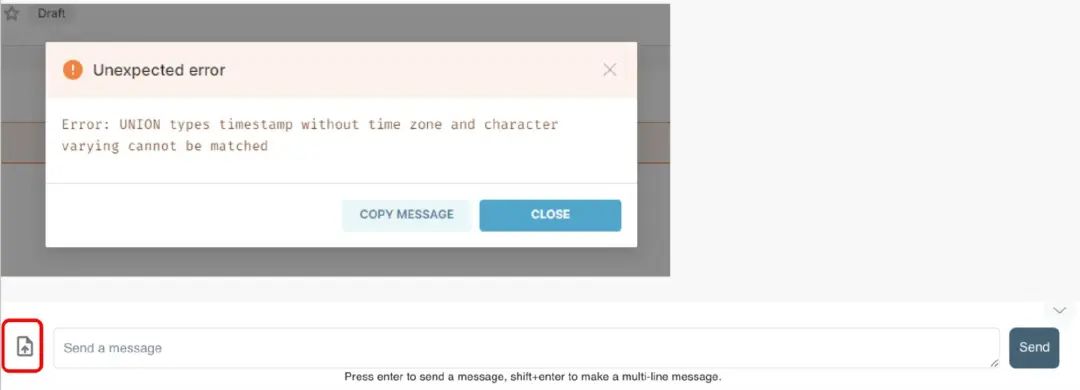
Figure 2: Sending Error Message Screenshots to LLM
Figure 2 shows an employee encountering an error message while using a BI tool; this error is not difficult to handle. If you ask the LLM, “I always encounter this error message when refreshing the MySQL data dashboard, what does it mean?” the LLM will provide a fairly detailed diagnostic analysis of the problem (see Figure 3).
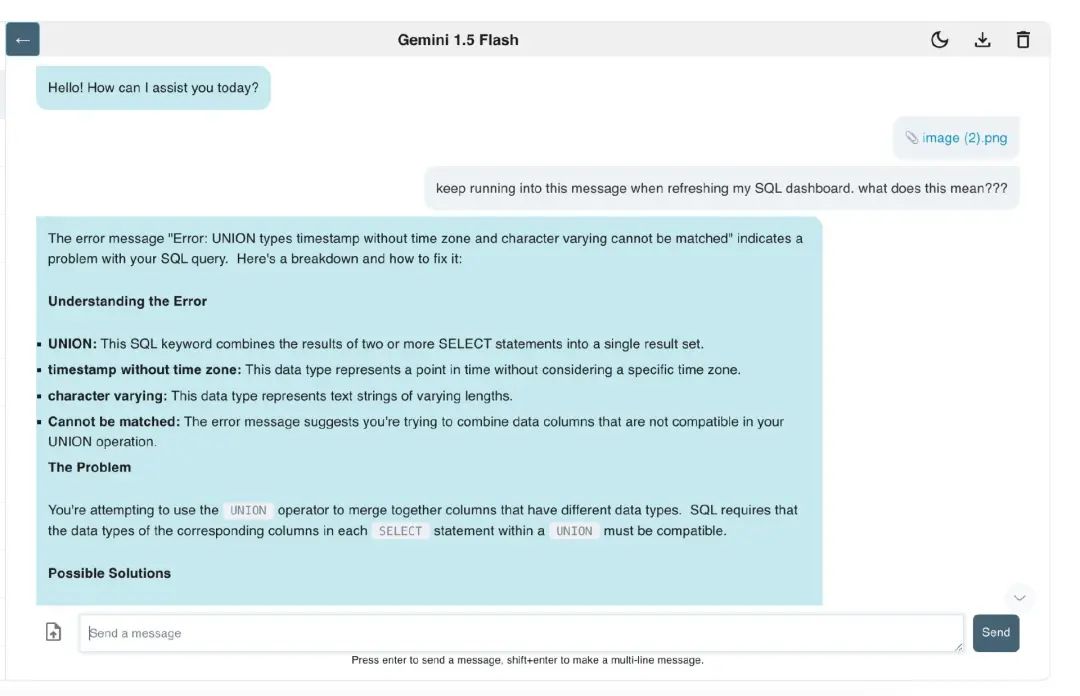
Figure 3: LLM Analyzing an Error Message
After supporting multimodal input, the next significant update for our platform was integrating Amazon Bedrock. Bedrock is a managed service provided by AWS for interfacing with foundational large language models and supports large-scale deployment and fine-tuning. We found that Bedrock’s capabilities highly overlap with many of the capabilities we built internally.
In fact, we considered Bedrock back in 2023, but at that time, the choice was to develop in-house, aiming to build technical confidence and experience in large-scale deployment through practice.
2024 marks a shift in our strategy regarding “in-house development vs. procurement.” We are indeed leaning more towards procurement, but with two prerequisites: first, security and privacy assurance; second, cost and time to market.
After adopting Bedrock, we shifted our focus to the external API within the LLM gateway. The structural design of the API, which was not thoroughly considered during its launch, ultimately caused us significant headaches. Since OpenAI’s API specifications have become the industry standard today, we encountered many challenges during integration. We had to rewrite a large amount of LangChain and other library code due to the incompatibility between our API structure and OpenAI’s.
In September 2024, we spent time releasing version 2 of the API, this time fully adhering to OpenAI’s API specifications. We recognized that as the generative AI industry matures, choosing the right standards and integration methods is crucial.
Lessons Learned
Over the past few years, we have gained many experiences and a deeper understanding of how people use these tools.
There is a strong correlation between generative AI and productivity enhancement. Through surveys and user research, we found that almost everyone who has used LLM believes it significantly improves or enhances work efficiency.
Our internal usage scenarios mainly focus on three categories:
-
Programming Support: Nearly half of the usage scenarios are related to debugging, code generation, or general programming support.
-
Content Creation and Optimization: Including “help me write something,” “adjust the writing style of this text,” “continue this content,” and so on.
-
Information Retrieval: The main usage scenarios involve retrieval or document parsing.
We have also gained many insights into user behavior. One of our biggest takeaways this year is that as LLM tools mature, the greatest value can only be realized when tools are integrated into work scenarios; cross-platform information migration significantly reduces work efficiency. The experience of needing to switch between different platforms to use generative AI is very frustrating. We also observed that even with an increasing number of available tools, most people still stick to using just one tool.
At the end of 2023, we thought Boosterpack would fundamentally change the way people use generative AI. However, this was not the case. Although initial adoption rates and use cases were quite good, we actually created two different AI usage scenarios for users, negatively impacting adoption rates and productivity.
We also recognized the need to be more cautious in selecting tool development and to pay more attention to integration between tools. Regardless of how users express their needs, their actual usage patterns often surprise us.
Current Status and Future of Generative AI
Wealthsimple’s enthusiasm for LLM remains strong. Among the various tools we provide, the daily message volume exceeds 2,200; nearly one-third of employees are active users weekly, and the monthly active user ratio is slightly above half. The adoption rates and engagement levels of these tools are quite impressive, and the feedback we receive indicates that they indeed enhance employee work efficiency.
More importantly, the experiences and foundations we have built in enhancing employee productivity have paved the way for creating a better customer experience. These internal tools lay the groundwork for the scaled development and deployment of generative AI, and they also give us more confidence in seeking new opportunities to serve our customers.
Looking back at the Gartner technology maturity curve, in 2023 we were at the peak of expectation inflation, while in 2024 we experienced a rational adjustment. Looking ahead to 2025, I believe we are steadily advancing towards the “enlightenment slope.” Despite the ups and downs of the past two years, we remain full of expectations and confidence for the developments in the coming year.
Disclaimer: This article is translated by InfoQ, and reproduction without permission is prohibited.
Today’s Recommended ArticlesDid Musk Get “Slapped in the Face”? A 150-Year-Old Man Receives Social Security, Is It the Programmer’s Youngster Who Doesn’t Understand COBOL? Free and Useful But Always “Server Busy”? Google AI Expert: After DeepSeek “Conquers” Silicon Valley, What Other Concerns Remain? “How Much Does It Cost to Hire an Employee in a Big Company? ByteDance Gave a Reference Price: 82.668 Million Yuan”? More than a dozen models can’t beat one DeepSeek? Ultraman angrily merges GPT and O series, marking the end of the non-thinking chain model era!