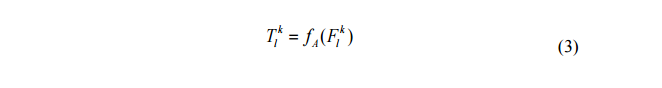Click on the above “Beginner’s Guide to Vision”, select to add “Bookmark” or “Pin“
Heavyweight content delivered promptly Image Processing| Computer Vision CV | Deep Learning | Vision Language Model VLM
This review categorizes recent innovations in CNN architectures into seven distinct categories based on spatial utilization, depth, multi-path, width, feature map utilization, channel enhancement, and attention.
Image Processing| Computer Vision CV | Deep Learning | Vision Language Model VLM
This review categorizes recent innovations in CNN architectures into seven distinct categories based on spatial utilization, depth, multi-path, width, feature map utilization, channel enhancement, and attention.
Reprinted from丨Deep Learning Matters
Deep convolutional neural networks (CNNs) are a special type of neural network that have shown the current best results on various competition benchmarks. The high performance achieved by deep CNN architectures in challenging benchmark task competitions indicates that innovative architectural concepts and parameter optimization can enhance CNN performance across various vision-related tasks.
CNNs first gained attention through LeCun’s research in 1989 on processing grid-like topological data (images and time series data). CNNs are considered one of the best techniques for understanding image content and have demonstrated the current best performance in image recognition, segmentation, detection, and retrieval tasks. The success of CNNs has attracted attention beyond academia. In the industry, companies like Google, Microsoft, AT&T, NEC, and Facebook have established research teams to explore new architectures for CNNs. Currently, most leaders in image processing competitions adopt models based on deep CNNs.
Since 2012, various innovations in CNN architecture have been proposed. These innovations can be categorized into parameter optimization, regularization, structural reorganization, etc. However, it has been observed that improvements in CNN performance are primarily attributed to the reconfiguration of processing units and the design of new modules. Since AlexNet demonstrated extraordinary performance on the ImageNet dataset, CNN-based applications have become increasingly prevalent. Similarly, Zeiler and Fergus introduced the concept of feature visualization, which changed the trend of extracting features using deep architectures (such as VGG) at simple low spatial resolutions. Today, most new architectures are built on the simple principles and homogenized topologies introduced by VGG.
On the other hand, the Google team introduced a very famous concept regarding splitting, transforming, and merging, known as the Inception module. The initial block first used the concept of intra-layer branching, allowing feature extraction at different spatial scales. In 2015, the concept of residual connections introduced by ResNet became well-known for training deep CNNs, and most subsequent networks like Inception-ResNet, WideResNet, ResNext, etc., utilize it. Similarly, architectures such as WideResNet, Pyramidal Nets, and Xception have introduced the concept of multi-layer transformations, achieving this through increased cardinality and width. Thus, the focus of research shifted from parameter optimization and connection adjustments back to network architecture design (layer structure). This has led to many new architectural concepts such as channel enhancement, spatial and channel utilization, and attention-based information processing.
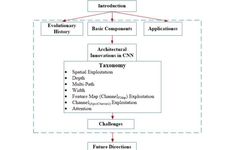
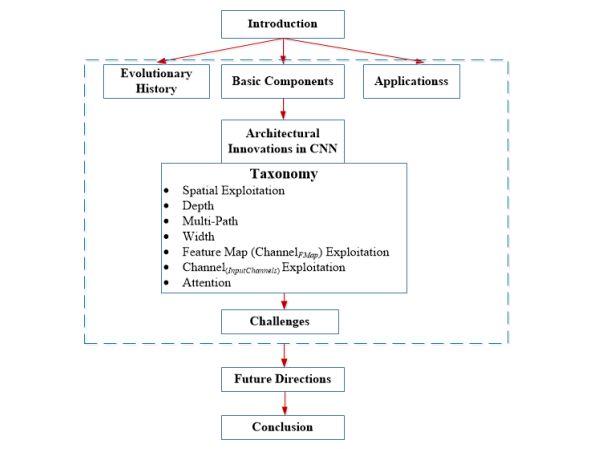
The structure of this article is as follows:
Figure 1: Structure of the article
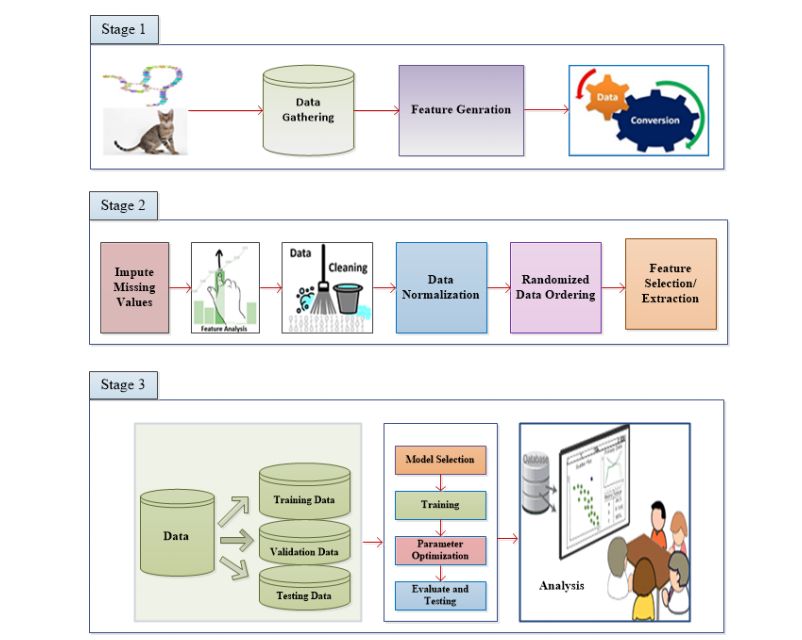
Figure 2: Basic layout of a typical pattern recognition (PR) system. The PR system is divided into three stages: Stage 1 is related to data mining, Stage 2 performs preprocessing and feature selection, while Stage 3 is based on model selection, parameter tuning, and analysis. CNNs have good feature extraction capabilities and strong discriminative abilities, thus they can be used in the feature extraction/generation and model selection stages within a PR system.
Architectural Innovations in CNNs
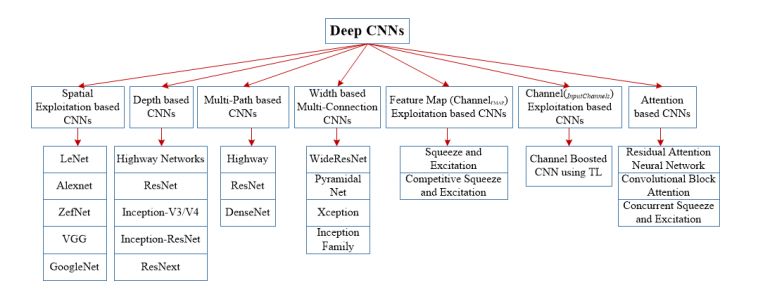
Since 1989, there have been many different improvements in CNN architectures. All innovations in CNNs are achieved through a combination of depth and spatial considerations. Based on the type of architectural modifications, CNNs can be roughly categorized into seven types: CNNs based on spatial utilization, depth, multi-path, width, channel enhancement, feature map utilization, and attention. The classification of deep CNN architectures is shown in Figure 3.
Figure 3: Classification of deep CNN architectures
CNNs Based on Spatial Utilization
CNNs have a large number of parameters, such as the number of processing units (neurons), the number of layers, filter sizes, strides, learning rates, and activation functions. Because CNNs consider the neighborhood of input pixels (locality), different sizes of filters can be used to explore different levels of correlation. Therefore, in the early 2000s, researchers utilized spatial transformations to enhance performance and also assessed the impact of different filter sizes on network learning rates. Different sizes of filters encapsulate different levels of granularity; generally, smaller filters extract fine-grained information while larger filters extract coarse-grained information. Thus, by adjusting filter sizes, CNNs can perform well on both coarse and fine details.
Deep CNN architectures are based on the assumption that as depth increases, the network can better approximate the target function through a large number of nonlinear mappings and improved feature representations. The depth of the network plays an important role in the success of supervised learning. Theoretical studies have shown that deep networks can represent specific types of 20 functions exponentially more efficiently than shallow networks. In 2001, Csáji demonstrated the universal approximation theorem, stating that a single hidden layer is sufficient to approximate any function, but this requires an exponential number of neurons, which typically leads to computational infeasibility. In this regard, Bengio and elalleau argued that deeper networks have the potential to maintain the performance capacity of the network at a lower cost. In 2013, Bengio et al. empirically demonstrated that for complex tasks, deep networks are more efficient both computationally and statistically. The best-performing Inception and VGG in the 2014 ILSVR competition further illustrate that depth is an important dimension in regulating the learning capacity of networks.
Once features are extracted, the location of extraction becomes less critical as long as its approximate position relative to other locations is preserved. Pooling or downsampling (such as convolution) is an interesting local operation. It summarizes similar information near the receptive field and outputs the main response within that local area. As the output of convolution operations, feature patterns may appear at different locations in the image.
Training deep networks is quite challenging, which has also been a theme of much recent deep network research. Deep CNNs provide efficient computation and statistics for complex tasks. However, deeper networks may encounter performance degradation or gradient vanishing/explosion issues, which are often caused by increased depth rather than overfitting. The gradient vanishing problem not only leads to higher test error but also higher training error. To train deeper networks, the concept of multi-path or cross-layer connections has been proposed. Multi-path or shortcut connections systematically link one layer to another by skipping some intermediate layers to allow specific information flow across layers. Cross-layer connections segment the network into several blocks. These paths also attempt to address the gradient vanishing problem by allowing lower layers to access gradients. Various types of shortcut connections, such as zero padding, projection-based, dropout, and 1×1 connections, have been used for this purpose.
Activation functions are decision functions that help learn complex patterns. Choosing the appropriate activation function can accelerate the learning process. The activation function for convolutional feature maps is defined by equation (3).
CNNs Based on Width with Multi-connections
From 2012 to 2015, the focus of network architecture was on the power of depth and the importance of multi-channel regulatory connections in network regularization. However, the width of the network is just as important as its depth. By parallelly using multiple processing units within a layer, multilayer perceptrons gain the advantage of mapping complex functions on perceptrons. This indicates that width is an important parameter defining learning principles, just as depth is. Lu et al. and Hanin & Sellke have recently shown that neural networks with linear rectified activation functions need to be sufficiently wide to maintain universal approximation properties as depth increases. Moreover, if the maximum width of the network does not exceed the input dimension, classes of continuous functions on compact sets cannot be well approximated by networks of arbitrary depth. Thus, multilayer stacking (increasing layers) may not increase the representational capacity of neural networks. An important issue related to deep architectures is that some layers or processing units may not learn useful features. To address this issue, research has shifted focus from deep and narrower architectures to shallower and wider architectures.
CNNs Developed Based on Feature Maps (Channel Feature Maps)
CNNs are known for their hierarchical learning and automatic feature extraction capabilities in MV tasks. Feature selection plays a crucial role in determining the performance of classification, segmentation, and detection modules. The performance of classification modules in traditional feature extraction techniques is limited by the singularity of features. Compared to traditional techniques, CNNs use multi-stage feature extraction to extract different types of features based on the assigned input (referred to as feature maps in CNNs). However, some feature maps have little or almost no object discriminative power. A large feature set has a noise effect that can lead to overfitting in the network. This indicates that, in addition to network engineering, the selection of specific category feature maps is crucial for improving the network’s generalization performance. In this section, feature maps and channels will be used interchangeably, as many researchers have replaced the term feature maps with channels.
CNNs Based on Channel (Input Channel) Utilization
Image representation plays an important role in determining the performance of image processing algorithms. A good representation of an image can define prominent features from compact codes. In different studies, various types of traditional filters have been used to extract different levels of information from single-type images. These different representations are used as inputs to models to enhance performance. CNNs are excellent feature learners that can automatically extract discriminative features based on the problem. However, the learning of CNNs relies on input representation. If the input lacks diversity and class-defining information, the performance of CNNs as discriminators will be affected. Therefore, the concept of auxiliary learners has been introduced into CNNs to enhance the input representation of the network.
Different levels of abstraction play an important role in defining the discriminative capacity of neural networks. Moreover, selecting context-relevant features is also crucial for image localization and recognition. In the human visual system, this phenomenon is called attention. Humans observe scenes in hurried glances and pay attention to contextually relevant parts. In this process, humans not only focus on selected areas but also infer different interpretations about objects in that position. Thus, it helps humans grasp visual structures better. Similar interpretative capabilities have been added to neural networks like RNNs and LSTMs. The aforementioned networks utilize attention modules to generate sequential data and weight it based on the occurrence of new samples in previous iterations. Various researchers have incorporated the attention concept into CNNs to improve representation and overcome computational limitations of data. The attention concept helps make CNNs smarter, enabling them to recognize objects even in cluttered backgrounds and complex scenes.
Paper: A Survey of the Recent Architectures of Deep Convolutional Neural Networks
Paper link: https://arxiv.org/abs/1901.06032
Abstract: Deep convolutional neural networks (CNNs) are a special type of neural network that have shown the current best results on various competition benchmarks. The powerful learning ability of deep CNNs is primarily realized through multiple nonlinear feature extraction stages that can automatically learn hierarchical representations from data. The availability of large datasets and improvements in hardware processing units have accelerated the research on CNNs, and very interesting deep CNN architectures have recently been reported. Recently, the high performance achieved by deep CNN architectures in challenging benchmark task competitions indicates that innovative architectural concepts and parameter optimization can enhance CNN performance across various vision-related tasks. In view of this, different ideas regarding CNN design have been explored, such as using different activation functions and loss functions, parameter optimization, regularization, and reconfiguration of processing units. However, the main improvements in representational capacity have been achieved through the reconfiguration of processing units. In particular, the idea of using blocks instead of layers as structural units has gained significant appreciation. This review categorizes recent innovations in CNN architectures into seven distinct categories, based on spatial utilization, depth, multi-path, width, feature map utilization, channel enhancement, and attention. Additionally, this article covers a fundamental understanding of the components of CNNs and reveals the current challenges faced by CNNs and their applications.
Download 1: Chinese Tutorial on OpenCV-Contrib Extension Module
Reply with "OpenCV Extension Module Chinese Tutorial" in the background of the "Beginner's Guide to Vision" public account to download the first Chinese version of the OpenCV extension module tutorial available online, covering over twenty chapters including extension module installation, SFM algorithms, stereo vision, object tracking, biological vision, super-resolution processing, etc.
Download 2: 52 Lectures of Python Vision Practical Projects
Reply with "Python Vision Practical Projects" in the background of the "Beginner's Guide to Vision" public account to download 31 vision practical projects including image segmentation, mask detection, lane line detection, vehicle counting, eyeliner addition, license plate recognition, character recognition, emotion detection, text content extraction, facial recognition, etc., to help quickly learn computer vision.
Download 3: 20 Lectures of OpenCV Practical Projects
Reply with "20 Lectures of OpenCV Practical Projects" in the background of the "Beginner's Guide to Vision" public account to download 20 practical projects based on OpenCV, achieving advanced learning of OpenCV.
Discussion Group
Welcome to join the reader group of the public account to communicate with peers. Currently, there are WeChat groups on SLAM, 3D vision, sensors, autonomous driving, computational photography, detection, segmentation, recognition, medical imaging, GANs, algorithm competitions, etc. (these will gradually be subdivided in the future). Please scan the WeChat number below to join the group, and note: "Nickname + School/Company + Research Direction", for example: "Zhang San + Shanghai Jiao Tong University + Vision SLAM". Please follow the format for notes; otherwise, you will not be approved. After successful addition, you will be invited to enter the relevant WeChat group based on research direction. Please do not send advertisements in the group; otherwise, you will be removed from the group. Thank you for your understanding~