Source: DeepHub IMBA
This article is approximately 1200 words long and is recommended for a 5-minute read.
In this article, we will introduce the PyOD package and provide detailed code examples.
Outlier detection is a key task in various fields. PyOD, which stands for Python Outlier Detection, simplifies the process of identifying outliers in multivariate datasets. In this article, we will introduce the PyOD package and provide detailed code examples.
Introduction to PyOD
PyOD provides a wide range of algorithms for outlier detection, suitable for both supervised and unsupervised scenarios. Whether dealing with labeled or unlabeled data, PyOD offers a variety of techniques to meet specific needs. One of PyOD’s standout features is its user-friendly API, making it accessible for both beginners and experienced practitioners.
Example 1: kNN
We start with a simple example using the k-nearest neighbors (kNN) algorithm for outlier detection.
First, import the necessary modules from PyOD.
from pyod.models.knn import KNN
from pyod.utils.data import generate_data
from pyod.utils.data import evaluate_print
We generate synthetic data with a predefined outlier rate to simulate outliers.
contamination = 0.1 # percentage of outliers
n_train = 200 # number of training points
n_test = 100 # number of testing points
X_train, X_test, y_train, y_test = generate_data(
n_train=n_train, n_test=n_test, contamination=contamination)
Initialize the kNN detector, fit it to the training data, and obtain outlier predictions.
clf_name = 'KNN'
clf = KNN()
clf.fit(X_train)
Evaluate the performance of the trained model on the training and testing datasets using ROC and Precision @ Rank n metrics.
print("\nOn Training Data:")
evaluate_print(clf_name, y_train, clf.decision_scores_)
print("\nOn Test Data:")
evaluate_print(clf_name, y_test, clf.decision_function(X_test))
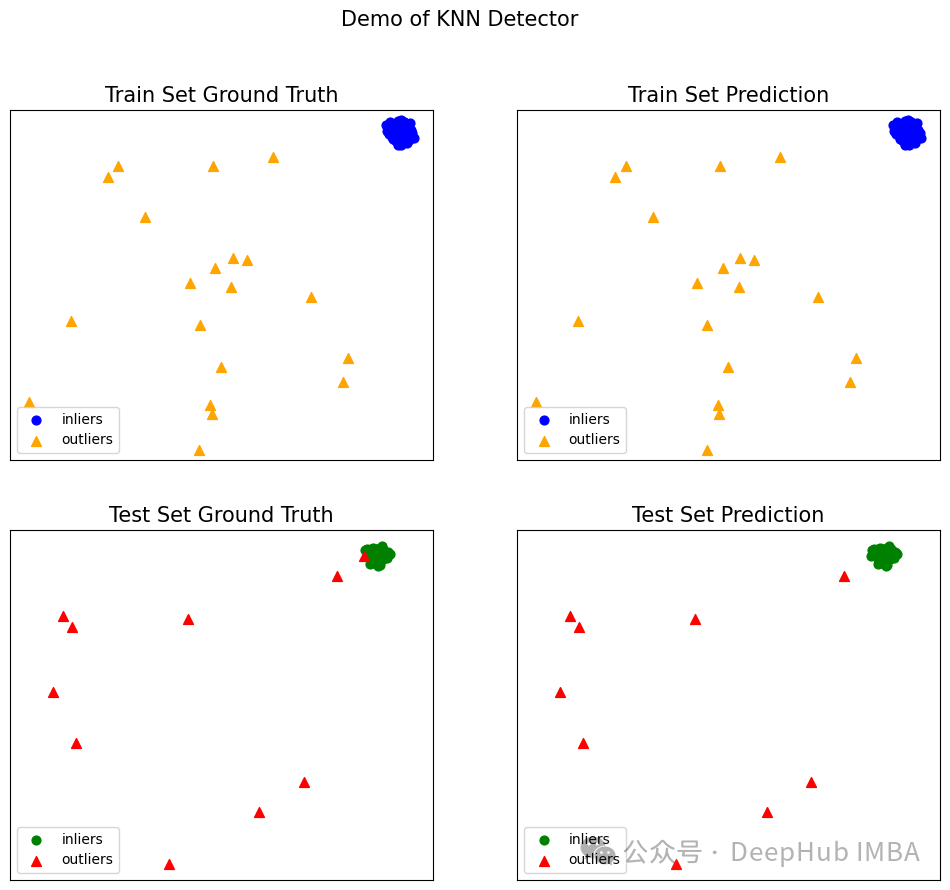
Finally, visualize the outlier detection results using the built-in visualization functionality.
from pyod.utils.data import visualize
visualize(clf_name, X_train, y_train, X_test, y_test, clf.labels_,
clf.predict(X_test), show_figure=True, save_figure=False)
This is a simple usage example.
Example 2: Model Ensemble
Outlier detection can sometimes be affected by model instability, especially in unsupervised cases. Therefore, PyOD provides model ensemble techniques to improve robustness.
import numpy as np
from sklearn.model_selection import train_test_split
from scipy.io import loadmat
from pyod.models.knn import KNN
from pyod.models.combination import aom, moa, average, maximization, median
from pyod.utils.utility import standardizer
from pyod.utils.data import generate_data
from pyod.utils.data import evaluate_print
X, y = generate_data(train_only=True) # load data
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.4)
# standardizing data for processing
X_train_norm, X_test_norm = standardizer(X_train, X_test)
n_clf = 20 # number of base detectors
# Initialize 20 base detectors for combination
k_list = [10, 20, 30, 40, 50, 60, 70, 80, 90, 100, 110, 120, 130, 140,
150, 160, 170, 180, 190, 200]
train_scores = np.zeros([X_train.shape[0], n_clf])
test_scores = np.zeros([X_test.shape[0], n_clf])
print('Combining {n_clf} kNN detectors'.format(n_clf=n_clf))
for i in range(n_clf):
k = k_list[i]
clf = KNN(n_neighbors=k, method='largest')
clf.fit(X_train_norm)
train_scores[:, i] = clf.decision_scores_
test_scores[:, i] = clf.decision_function(X_test_norm)
# Decision scores have to be normalized before combination
train_scores_norm, test_scores_norm = standardizer(train_scores,
test_scores)
# Combination by average
y_by_average = average(test_scores_norm)
evaluate_print('Combination by Average', y_test, y_by_average)
# Combination by max
y_by_maximization = maximization(test_scores_norm)
evaluate_print('Combination by Maximization', y_test, y_by_maximization)
# Combination by median
y_by_median = median(test_scores_norm)
evaluate_print('Combination by Median', y_test, y_by_median)
# Combination by aom
y_by_aom = aom(test_scores_norm, n_buckets=5)
evaluate_print('Combination by AOM', y_test, y_by_aom)
# Combination by moa
y_by_moa = moa(test_scores_norm, n_buckets=5)
evaluate_print('Combination by MOA', y_test, y_by_moa)
If the above code prompts an error, you need to install the combo package.
pip install combo
Conclusion
As we can see, using PyOD for outlier detection is very convenient, from basic kNN outlier detection to model ensemble, PyOD provides a comprehensive integration that allows us to easily and efficiently handle outlier detection tasks.
Finally, refer to the documentation and official website of PyOD at https://pyod.readthedocs.io/en/latest/