
Author: Jack Chih-Hsu Lin<br/>Translator: Chen Zhi Yan<br/>Proofreader: Wang Zi Yue<br/><br/><br/><br/>About 4600 words, recommended reading time 9 minutes.<br/>18 essential PyTorch speed-up tips: how they work and methods.

Adjusting the deep learning pipeline is like finding the right gear combination (Image source: Tim Mossholder)
Why Read This Blog?
The training/inference process of deep learning models involves multiple steps. When time and resources are limited, the faster the experimental iteration speed, the better the model’s predictive performance can be optimized. This blog collects and organizes some tips and tricks for maximizing memory efficiency and minimizing runtime in PyTorch. However, to better utilize these tips, we also need to understand how they work.
As an introduction, this blog provides a complete content list and code snippets to facilitate readers jumping to the corresponding segments and optimizing their code. After that, I have conducted detailed research on each point provided in this blog, offering code snippets for each tip while noting the corresponding device type (CPU/GPU) or model.
Content List
1. Move active data to a Solid State Drive (SSD)
2. Dataloader(dataset, num_workers=4*num_GPU)
3. Dataloader(dataset, pin_memory=True)
4. Create vectors, matrices, and tensors as torch.Tensor directly on the device running the program
5. Avoid unnecessary data transfer between CPU and GPU
6. Use torch.from_numpy(numpy_array) or torch.as_tensor(others)
7. Use tensor.to(non_blocking=True) during overlapping data transfers
8. Use PyTorch JIT to fuse element-wise operations into a single kernel
9. Set sizes of differently architected designs to be multiples of 8 for mixed precision 16-bit floating point (FP16).
10. Set batch size to be a multiple of 8 and maximize GPU memory usage
11. Use mixed precision for forward pass (but not backward pass)
12. Set gradients to None (e.g., model.zero_grad(set_to_none=True)) before optimizer updates weights
13. Gradient accumulation: update weights for other x batches to simulate a larger batch size
14. Turn off gradient calculation
-
Convolutional Neural Network (CNN) Special
15. torch.backends.cudnn.benchmark = True
16. Use channels_last memory format for 4D NCHW tensors
17. Turn off biases for convolutional layers before batch normalization
18. Use DistributedDataParallel instead of DataParallel
Code snippets related to tips 7, 11, 12, 13:

In general, time and memory usage can be optimized through three key measures. First, minimize I/O (input/output) as much as possible, binding the model pipeline to computation (math-limited or compute-bound), rather than bound to I/O (bandwidth-limited or memory-bound), fully utilizing the GPU’s strengths to accelerate computation; second, stack processes as much as possible to save time; third, maximize memory usage efficiency to save memory. Achieving greater batch sizes through memory savings can further save time. By doing these three points, we can have more time to iterate models faster, thus improving model performance.
1. Move Active Data to SSD
Different machines have different types of hard drives, such as HDD and SSD. It is recommended to move the active data used in the project to an SSD (or a hard drive with better I/O) for faster speeds.
2. Asynchronous Data Loading and Augmentation
Setting num_workers=0 will cause the program to execute data loading only before training or after the training process is complete. For I/O and large data augmentation, setting num_workers > 0 will help speed up this process. Experiments found that for GPUs, the best performance is when num_workers = 4*num_GPU. While the experimental results are thus, you can also test the num_workers that suit your machine best. It is important to note that the higher the num_workers, the greater the memory overhead, which is entirely expected, as more copies of data are stored in memory.
3. Use Pinned Memory to Reduce Data Transfers
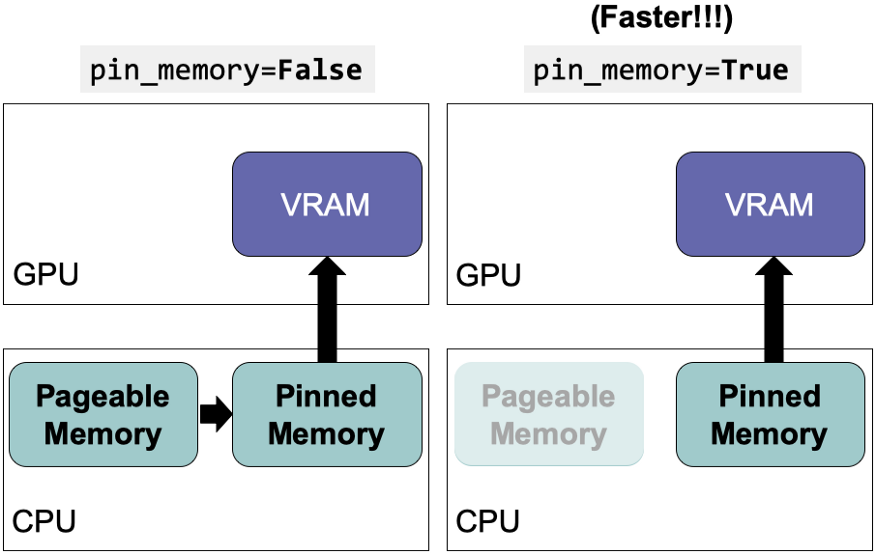
Setting pin_memory=True skips the data transfer from “paginable memory” to “pinned memory” (Image provided by the author, inspired by this image)
The GPU cannot access data directly from the CPU’s pageable memory. Setting pin_memory=True allocates pinned memory for the data on the CPU host and saves the time of transferring data from pageable storage to pinned memory (i.e., locked pageable memory). This setting can be combined with num_workers=4*num_GPU.
4. Create Vectors, Matrices, Tensors as torch.Tensor Directly on the Running Device
When PyTorch needs to use torch.Tensor data, the first attempt should be to create them on the device where they will be run. Do not use native Python or NumPy to create data and then convert them to torch.Tensor. In most cases, if you intend to use them in the GPU, create them directly on the GPU.

The only syntactical difference is that random number generation in NumPy requires an extra random number, for example, np.random.rand() compared to torch.rand(). Many other functions have corresponding functions in NumPy:
5. Avoid Unnecessary Data Transfers Between CPU and GPU
As mentioned in the advanced concepts, minimize I/O as much as possible, pay attention to the following commands:
6. Use torch.from_numpy(numpy_array) and torch.as_tensor(others) Instead of torch.tensor, torch.tensor()
If both the source device and target device are CPUs, then torch.from_numpy and torch.as_tensor will not create data copies. If the source data is a NumPy array, using torch.from_numpy(numpy_array) will be faster. If the source data is a tensor with the same data type and device type, then torch.as_tensor(others) can avoid copying data where applicable. Others can be a Python list, tuple, or torch.tensor. If the source device and target device are different, then it is recommended to use the seventh point.

7. Use tensor.to(non_blocking=True) When Overlapping Data Transfer and Kernel Execution
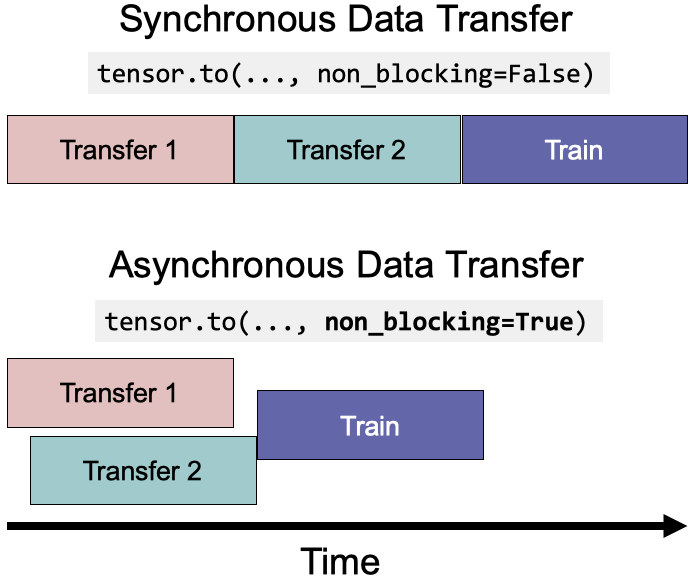
Overlapping data transfer can reduce runtime. (Image provided by the author)
Essentially, non_blocking=True reduces execution time through asynchronous data transfer.
8. Fuse Element-wise Operations into a Single Kernel with PyTorch JIT
Element-wise operations, including general mathematical operations (see the example list), are often memory-bound, and PyTorch JIT automatically fuses adjacent element-wise operations into a single kernel to save multiple memory reads and writes. (Pretty amazing, right?) For a vector of size one million, the gelu function can speed up by 4 times by fusing 5 kernels into 1. More examples of PyTorch JIT optimization can be found here and here.

9 & 10. Set Batch Sizes of All Different Architectures to be Multiples of 8
To maximize GPU computing efficiency, it is best to ensure that differently architected designs (including input and output sizes/dimensions/channel sizes and batch sizes of neural networks) are multiples of 8, or even powers of 2 (e.g., 64, 128, and 256). When the matrix dimensions align to multiples of powers of 2, the tensor cores of Nvidia GPUs will achieve optimal performance in matrix multiplication. Matrix multiplication is the most commonly used operation and usually the bottleneck of computation, so ensuring that the dimensions of tensors/matrices/vectors can be divided by powers of 2 (e.g., 8, 64, 128, and up to 256) is crucial.
Experiments show that setting output dimensions and batch sizes to multiples of 8 (i.e., 33712, 4088, 4096) can increase computation speed by 1.3 to 4 times compared to setting output dimensions and batch sizes to numbers that are not divisible by 8 (for example, output dimension 33708, batch size 4084 and 4095). Moreover, the speed increase also depends on the type of computation (e.g., forward pass or gradient computation) and cuBLAS version. Particularly, if you work in natural language processing, you should check the output dimensions (usually referring to vocabulary size).
Using multiples greater than 256 does not provide more benefits, but it is also harmless. The output dimension and batch size settings are also related to cuBLAS, cuDNN versions, and GPU architectures. The requirements for matrix dimensions and tensor cores can be found here. Since PyTorch AMP primarily uses FP16, which is a multiple of 8, it is generally recommended to use multiples of 8. If you have a more advanced GPU, like the A100, you can choose multiples of 64. If using AMD GPU, refer to the relevant AMD documentation.
In addition to setting batch sizes to multiples of 8, it is also necessary to maximize the batch size until it reaches the memory limit of the GPU. This way, you can spend less time completing an epoch.
11. Use Mixed Precision in Forward Pass, Not in Backward Pass
Some operations do not require the precision of 64-bit or 32-bit floating points. Therefore, setting operations to lower precision can save memory and speed up execution time. For various applications, Nvidia reports that using mixed precision with tensor core GPUs can speed up by 3.5 to 25 times.
It is worth noting that generally, the larger the matrix, the higher the speed increase from mixed precision. In large neural networks (like BERT), experiments have shown that mixed precision can speed up training by 2.75 times and reduce memory usage by 37%. New GPU devices with Volta, Turing, Ampere, or Hopper architectures (such as T4, V100, RTX 2060, 2070, 2080, 2080Ti, A100, RTX 3090, RTX 3080, and RTX 3070) can benefit more from mixed precision because they have tensor core architecture, giving them a performance advantage over CUDA cores.

Tensor core NVIDIA architectures support different precisions (Image provided by the author; data source)
It is important to note that the H100 with Hopper architecture is expected to be released in Q3 2022, which will support FP8 (8-bit floating point). PyTorch AMP may also support FP8 (current v1.11.0 does not support FP8).
In practice, it is necessary to find an optimal balance between model precision and speed. The model performance is not only related to algorithms, data, and problem types but also mixed precision can indeed lower the model performance.
PyTorch easily distinguishes mixed precision from the automatic mixed precision (AMP) package. The default floating point type in PyTorch is 32-bit floating point. AMP saves memory and time by using 16-bit floating points for some operations (e.g., matmul, linear, conv2d, etc., see complete list). At the same time, AMP uses 32-bit floating points for some operations (e.g., mse_loss, softmax, etc., see complete list). Furthermore, for some operations (e.g., add, see complete list), AMP processes the widest input data type. For instance, if one variable is a 32-bit floating point and another variable is a 16-bit floating point, the addition result will be a 32-bit floating point.
autocast automatically applies various precisions to different operations. Since “loss” and “gradient” are computed with 16-bit floating point precision, the gradient calculation may discard them when they are too small. GradScaler first multiplies the loss by a scaling factor, computes the gradient using the scaled loss, and then scales the gradient back before the optimizer updates weights to prevent the gradient from becoming zero. If the scaling factor is too large or too small, causing the result to appear as Inf or NaN, the scaler will update the scaling factor in the next iteration.

It is also possible to use automatic casting in the renderer of the forward pass function.

12. Set Gradients to None Before Optimizer Updates Weights
By using model.zero_grad() or optimizer.zero_grad(), setting gradients to zero will update all parameters and gradients during the memset read/write operation. However, setting gradients to None will not execute memset and only update gradients during write operations. Therefore, setting gradients to None is faster.

13. Gradient Accumulation: Update Weights for Each x Batch to Simulate a Larger Batch Size
This technique suggests accumulating gradients from more data samples to make the gradient estimates more accurate, thereby bringing the weights closer to local/global minima. This is particularly useful when the batch is small (due to GPU memory limitations or the large amount of sample data).

14. Turn Off Gradient Calculation for Inference and Validation
Essentially, if you only need to compute the model’s output, then there is no need for gradient calculation during inference and validation steps. PyTorch uses an intermediate memory buffer for operations where requires_grad=True. Therefore, if it is known that no gradient-related operations are needed, gradient calculation can be disabled during inference and validation to save resources.

15. Set torch.backends.cudnn.benchmark = True
Setting torch.backends.cudnn.benchmark=True before the training loop can accelerate computation. Since cuDNN algorithms perform differently when computing convolution kernels of different sizes, the auto-tuner finds the best algorithm by running a benchmark (the current algorithms include these, these, and these). It is recommended to enable this setting when the input size does not change frequently. If the input size changes frequently, the auto-tuner needs to benchmark too often, which may affect performance. It can accelerate forward propagation by 1.27 times and backward propagation by 1.70 times (reference).
16. Use Channels_Last Memory Format for 4D NCHW Tensors
 4D NCHW is reorganized into NHWC format (Image inspired by the author’s picture)
Using channels_last memory format saves images in a pixel-to-pixel manner, making this format the most dense memory format. The original 4D NCHW tensor clusters each channel (red/gray/blue) together in memory. After conversion, x=x.to(memory_format=torch.channels_last), the data is reorganized in memory to NHWC (channels_last format). At this point, each pixel of the RGB layers is closer together. This NHWC format can achieve speed increases of 8% to 35% compared to AMP’s 16-bit floating point.
Currently, it is still in the testing phase and only supports 4D NCHW tensors and certain models (e.g., alexnet, mnasnet family, mobilenet_v2, resnet family, shufflenet_v2, squeezenet1, vgg, see complete list). But it is certain that it will become a standard optimization.
4D NCHW is reorganized into NHWC format (Image inspired by the author’s picture)
Using channels_last memory format saves images in a pixel-to-pixel manner, making this format the most dense memory format. The original 4D NCHW tensor clusters each channel (red/gray/blue) together in memory. After conversion, x=x.to(memory_format=torch.channels_last), the data is reorganized in memory to NHWC (channels_last format). At this point, each pixel of the RGB layers is closer together. This NHWC format can achieve speed increases of 8% to 35% compared to AMP’s 16-bit floating point.
Currently, it is still in the testing phase and only supports 4D NCHW tensors and certain models (e.g., alexnet, mnasnet family, mobilenet_v2, resnet family, shufflenet_v2, squeezenet1, vgg, see complete list). But it is certain that it will become a standard optimization.

17. Turn Off Biases for Convolutional Layers Before Batch Normalization
Mathematically, the bias effect will be canceled out by the average subtraction of batch normalization, which is very effective in saving model parameters, reducing runtime, and lowering memory consumption.

18. Use DistributedDataParallel Instead of DataParallel
For multi-GPU, even with just one node, it always prefers DistributedDataParallel because DistributedDataParallel adopts multi-process, creating a process for each GPU to bypass the Python Global Interpreter Lock (GIL), thus speeding up execution.
#GPU #DistributedOptimizations #SaveTime
Summary
This article created a content list and provided 18 PyTorch code snippets. Then, it explained how they work, covering data loading, data operations, model architecture, training, inference, CNN-specific optimizations, and distributed computing. After deeply understanding how they work, one can find general guidelines applicable to deep learning modeling in any deep learning framework.
I hope you enjoy a more efficient PyTorch and learn new knowledge!
If you have any comments or suggestions, please leave comments or other suggestions in the comment section. Thank you for taking the time to read.
I hope our deep learning pipeline can soar like a rocket 😀 (Image by Bill Jelen)
Sincere thanks to Katherine Prairie
Optimize PyTorch Performance for Speed and Memory Efficiency (2022)
Original Link:
https://medium.com/towards-data-science/optimize-pytorch-performance-for-speed-and-memory-efficiency-2022-84f453916ea6
Chen Zhi Yan, graduated from Beijing Jiaotong University with a master’s degree in Communication and Control Engineering. He has served as an engineer at Great Wall Computer Software and Systems Company and Datang Microelectronics Company. He is currently a technical support at Beijing Wuyi Chaoqun Technology Co., Ltd. He is engaged in the operation and maintenance of intelligent translation teaching systems and has accumulated certain experience in artificial intelligence deep learning and natural language processing (NLP). In his spare time, he enjoys translation and creative writing, with translated works including: IEC-ISO 7816, Iraq Oil Engineering Project, New Fiscal Taxation Declaration, etc. His Chinese-to-English work “New Fiscal Taxation Declaration” was officially published in GLOBAL TIMES. He hopes to join the translation volunteer group of THU Data Party in his spare time to communicate and share with everyone and make progress together.
Translation Team Recruitment Information
Job Content: Requires a meticulous heart to translate selected foreign articles into fluent Chinese. If you are an international student in data science/statistics/computer science, or working overseas in related fields, or confident in your foreign language skills, you are welcome to join the translation team.
What You Can Get: Regular translation training to improve volunteers’ translation skills and enhance understanding of the frontiers of data science. Friends overseas can keep in touch with the development of technical applications in China. The academic-industry-research background of THU Data Party provides good development opportunities for volunteers.
Other Benefits: Data scientists from well-known companies and students from prestigious universities such as Peking University, Tsinghua University, and overseas will become your partners in the translation team.
Click on the end of the article “Read the Original” to join the Data Party team~
Reprint Notice
If you need to reprint, please indicate the author and source prominently at the beginning (Transferred from: Data Party ID: DatapiTHU), and place a prominent QR code for Data Party at the end of the article. For articles with original identification, please send [Article Title – Public Account Name and ID to be Authorized] to the contact email to apply for whitelist authorization and edit as required.
After publication, please provide the link feedback to the contact email (see below). Unauthorized reprints and adaptations will be pursued legally.
Click“Read the Original” to embrace the organization




