
Project Introduction
Ollama is a project focused on the local deployment and running of large language models, such as Llama 2 and Mistral. This project is licensed under the MIT License and is primarily written in Go, while also integrating languages such as C, Shell, TypeScript, C++, and PowerShell. With over 33.5k stars and 2.2k forks, its influence in the technical community is evident. This project provides an important tool for developers researching artificial intelligence and big data processing.
Scan to Join the Communication Group
Get More Technical Support and Communication

Run
·macOS
Download Link
https://ollama.ai/download/Ollama-darwin.zip
·Windows
Ollama can be installed on Windows through WSL2.
·Linux & WSL2
curl https://ollama.ai/install.sh | sh·Docker
The official Ollama Docker image, ollama, is available on Docker Hub.
Quick Start
Run llama2
ollama run llama2Model Library
Ollama supports a range of open-source models available at ollama.ai/library
Here are some examples of open-source models that can be downloaded:
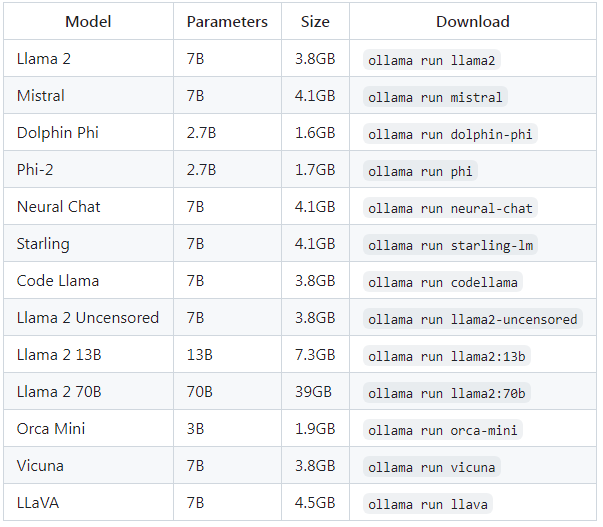
Note: Running a 7B model requires at least 8GB of RAM, a 13B model requires 16GB of RAM, and a 33B model requires 32GB of RAM.
Custom Models
· Import from GGUF
Ollama supports importing GGUF models in the Modelfile:
Create a file named Modelfile that contains a FROM directive specifying the local file path of the model to import.
FROM ./vicuna-33b.Q4_0.gguf· Create a Model in Ollama
ollama create example -f Modelfile· Run the Model
ollama run exampleCustom Prompts
Models in the Ollama library can be customized via prompts. For example, to customize the llama2 model:
ollama pull llama2Create a Modelfile:
FROM llama2
# set the temperature to 1 [higher is more creative, lower is more coherent]PARAMETER temperature 1
# set the system messageSYSTEM """You are Mario from Super Mario Bros. Answer as Mario, the assistant, only.""" Next, create and run the model:
ollama create mario -f ./Modelfileollama run mario>>> hiHello! It's your friend Mario.Command Line Interface Reference
· Create a Model
ollama create is used to create a model from a model file.
ollama create mymodel -f ./Modelfile· Pull a Model
ollama pull llama2This command can also be used to update the local model
· Delete a Model
ollama rm llama2· Copy a Model
ollama cp llama2 my-llama2· Multi-line Input
>>> """Hello,... world!... """I'm a basic program that prints the famous "Hello, world!" message to the console.· Multi-modal Model
>>> What's in this image? /Users/jmorgan/Desktop/smile.pngThe image features a yellow smiley face, which is likely the central focus of the picture.· Pass Prompts as Arguments
$ ollama run llama2 "Summarize this file: $(cat README.md)" Ollama is a lightweight, extensible framework for building and running language models on the local machine. It provides a simple API for creating, running, and managing models, as well as a library of pre-built models that can be easily used in a variety of applications.Project Links
https://github.com/ollama/ollama
For more detailed information, please join the group for discussions or check the documentation.
Follow the WeChat public account “Open Source AI Project Implementation“