
MLNLP community is a well-known machine learning and natural language processing community both domestically and internationally, reaching an audience of NLP graduate students, professors, and researchers in enterprises.
The vision of the community is to promote communication and progress between the academic and industrial sectors of natural language processing and machine learning, especially for beginners.
Reprinted from | Xinzhiyuan
Editor | LRS
Text embedding (word embedding) is fundamental to the development of the natural language processing (NLP) field, allowing text to be mapped into semantic space and converted into dense vectors. It has been widely applied in various NLP tasks such as information retrieval (IR), question answering, text similarity calculation, recommendation systems, and more.
For example, in the IR field, the first stage of retrieval often relies on text embeddings for similarity calculations, recalling a small set of candidate documents from a large corpus before performing fine-grained calculations. Embedding-based retrieval is also a key component of retrieval-augmented generation (RAG), enabling large language models (LLMs) to access dynamic external knowledge without modifying model parameters.
Early text embedding learning methods like word2vec and GloVe were mostly static and could not capture the rich contextual information in natural language. With the emergence of pre-trained language models, methods like Sentence-BERT and SimCSE have learned text embeddings by fine-tuning BERT on natural language inference (NLI) datasets.
To further enhance the performance and robustness of text embeddings, state-of-the-art methods like E5 and BGE adopt more complex multi-stage training paradigms, pre-training on billions of weakly supervised text pairs before fine-tuning on several labeled datasets.
Existing multi-stage methods still have two shortcomings:
1. Constructing a complex multi-stage training pipeline requires a significant amount of engineering work to manage a large number of relevance pairs.
2. Fine-tuning depends on manually collected datasets, which are often limited by task diversity and language coverage.
3. Most existing methods use BERT-style encoders as the backbone, ignoring the latest advancements in training better LLMs and related technologies (such as context length extension).
Recently, a research team from Microsoft proposed a simple and efficient text embedding training method that overcomes the shortcomings of the above methods. It requires no complex pipeline design or manually constructed datasets, only utilizing LLMs to “synthesize diverse text data” to generate high-quality text embeddings for hundreds of thousands of text embedding tasks in nearly 100 languages, with the entire training process taking less than 1000 steps.

Paper link: https://arxiv.org/abs/2401.00368
Specifically, the researchers used a two-step prompting strategy, first prompting the LLM to brainstorm a pool of candidate tasks, and then prompting the LLM to generate data for a given task from the pool.
To cover different application scenarios, the researchers designed multiple prompting templates for each task type and combined the data generated from different templates to enhance diversity.
Experimental results show that when fine-tuning “only on synthetic data”, Mistral-7B achieved very competitive performance on the BEIR and MTEB benchmarks; when both synthetic and labeled data were used for fine-tuning, state-of-the-art (SOTA) performance could be achieved.
Enhancing Text Embeddings with Large Models
1. Synthetic Data Generation
Using state-of-the-art large language models (LLMs) like GPT-4 to synthesize data is gaining increasing attention, as it can enhance the model’s capability diversity across multiple tasks and languages, resulting in more robust text embeddings that perform well across various downstream tasks (such as semantic retrieval, text similarity calculation, clustering).
To generate diverse synthetic data, the researchers proposed a simple classification method, first categorizing the embedding tasks, and then using different prompting templates for each category of tasks.
Asymmetric Tasks
Include tasks where the query and document are semantically related but not paraphrases of each other. Based on the length of the query and document, the researchers further divided asymmetric tasks into four subcategories: short-long matching (short queries and long documents, a typical scenario in commercial search engines), long-short matching, short-short matching, and long-long matching.
For each subcategory, the researchers designed a two-step prompting template, first prompting the LLM to brainstorm a list of tasks, then generating a specific example of task definition conditions; the outputs from GPT-4 were mostly coherent and of high quality.
In preliminary experiments, the researchers also attempted to use a single prompt to generate task definitions and query-document pairs, but the data diversity was not as good as the aforementioned two-step method.
Symmetric Tasks
Mainly include queries and documents that have similar semantics but different surface forms. The study explored two application scenarios: monolingual semantic text similarity (STS) and dual-text retrieval, designing two different prompting templates for each scenario tailored to their specific goals. Due to the simplicity of the task definitions, the brainstorming step can be omitted.
To further enhance the diversity of the prompts and the synthetic data, the researchers included several placeholders in each prompt board, randomly sampling at runtime, for example, “{query_length}” representing sampling from the set “{fewer than 5 words, 5-10 words, at least 10 words}”.
To generate multilingual data, the researchers sampled the value of “{language}” from the language list of XLM-R, giving higher resource languages more weight; any generated data that did not conform to the predefined JSON format would be discarded during parsing; duplicates would also be removed based on precise string matching.
2. Training
Given a relevant query-document pair, a new instruction q_inst is generated from the original query q+, where “{task_definition}” is a placeholder for a one-sentence description of the embedding task.
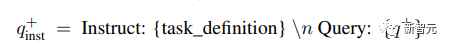
For the generated synthetic data, the outputs of the brainstorming step are used; for other datasets, such as MS-MARCO, the researchers manually created task definitions and applied them to all queries in the dataset without modifying any instruction prefixes on the file end.
In this way, document indexing can be pre-built, and tasks can be customized by only changing the query end.
Given a pre-trained LLM, an [EOS] token is appended to the end of the query and document, then fed into the LLM to obtain query and document embeddings by retrieving the last layer [EOS] vector.
Standard InfoNCE loss is then used to calculate the loss for batch negatives and hard negatives.
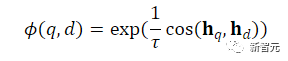
Where ℕ represents the set of all negatives, and Φ(q,d) is used to calculate the matching score between the query and document, with t being a temperature hyperparameter, fixed at 0.02 during the experiments.
Experimental Results
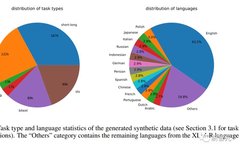
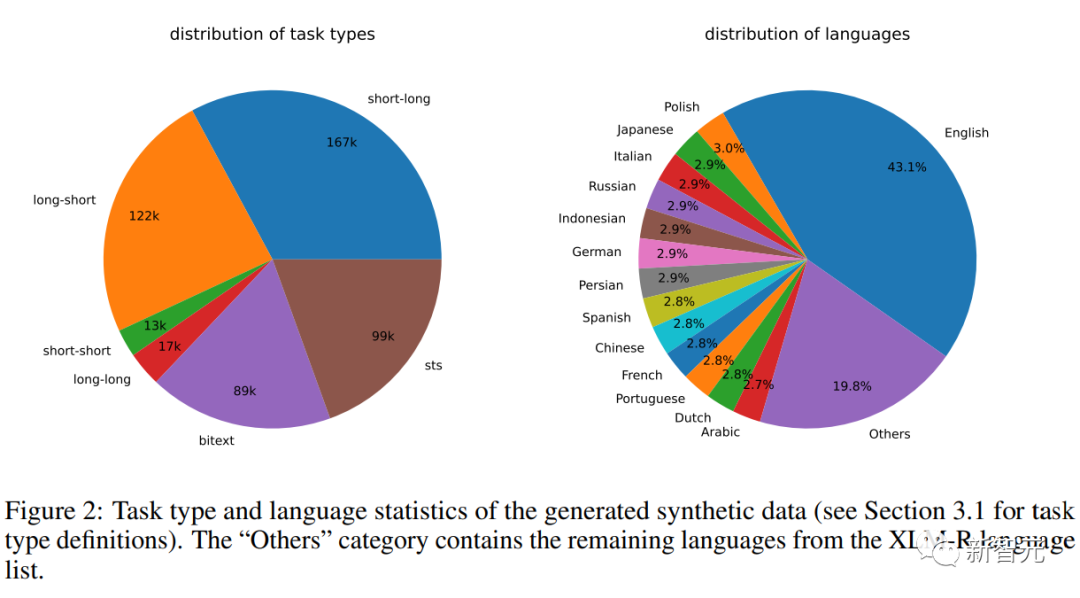
Synthetic Data Statistics
The researchers used Azure OpenAI services to generate 500k samples, containing 150k unique instructions, with 25% generated by GPT-3.5-Turbo and the rest by GPT-4, consuming a total of 180 million tokens.
The main language is English, covering a total of 93 languages; for 75 low-resource languages, there are approximately 1k samples per language on average.
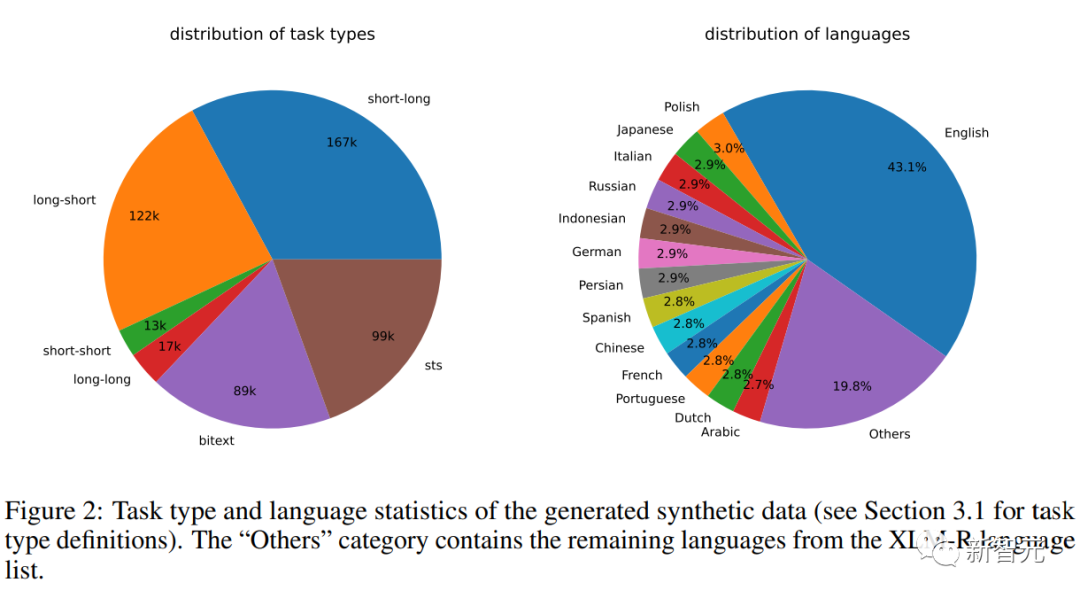
In terms of data quality, the researchers found that some outputs from GPT-3.5-Turbo did not strictly follow the criteria set in the prompting templates; however, the overall quality was still acceptable, and preliminary experiments also demonstrated the benefits of using this data subset.
Model Fine-Tuning and Evaluation
The researchers fine-tuned the pre-trained Mistral-7B using the above loss for 1 epoch, following the training method of RankLLaMA, and using LoRA with a rank of 16.
To further reduce GPU memory requirements, techniques like gradient checkpointing, mixed precision training, and DeepSpeed ZeRO-3 were employed.
In terms of training data, both the generated synthetic data and 13 public datasets were used, resulting in approximately 1.8 million samples after sampling.
To ensure a fair comparison with previous works, the researchers also reported results when the only labeled supervision was the MS-MARCO document ranking dataset, and evaluated the model on the MTEB benchmark.
Main Results
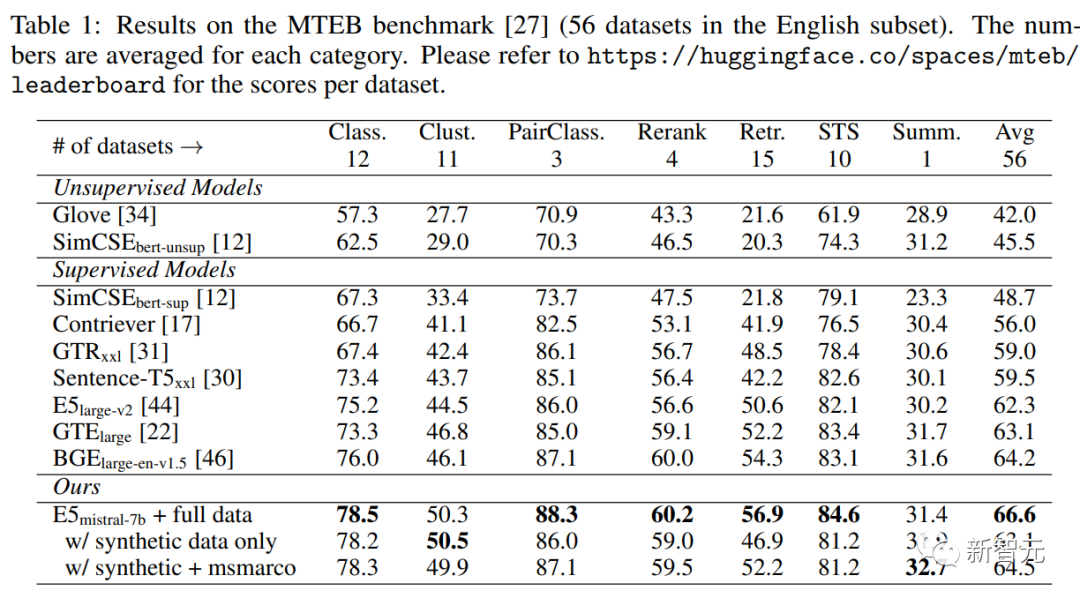
The table below shows that the model “E5mistral-7B + full data” obtained the highest average score on the MTEB benchmark, surpassing the previous state-of-the-art model by 2.4 points.
In the “w/ synthetic data only” setting, no labeled data was used for training, yet the performance remained highly competitive.
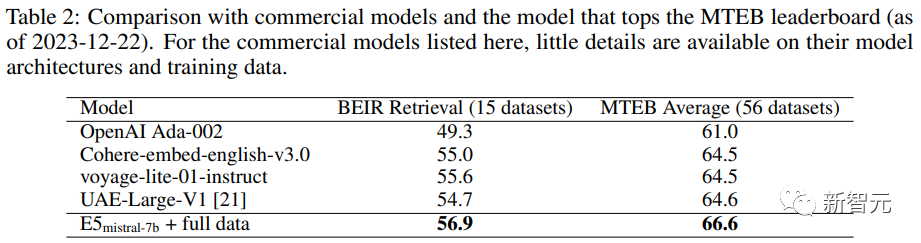
The researchers also compared several commercial text embedding models, but due to the lack of transparency and documentation of these models, a fair comparison could not be made.
However, in the retrieval performance comparison on the BEIR benchmark, the trained model significantly outperformed current commercial models.
Multilingual Retrieval
To evaluate the model’s multilingual capability, the researchers conducted an evaluation on the MIRACL dataset, which contains manually annotated queries and relevance judgments in 18 languages.
The results showed that the model exceeded mE5-large on high-resource languages, especially performing better in English; however, for low-resource languages, the model was still not ideal compared to mE5-base.
The researchers attributed this to the fact that Mistral-7B was primarily pre-trained on English data, predicting that multilingual models could use this method to bridge this gap.
References:
https://arxiv.org/abs/2401.00368

Scan the QR code to add the assistant on WeChat
About Us
