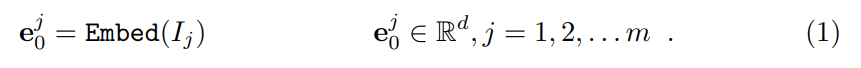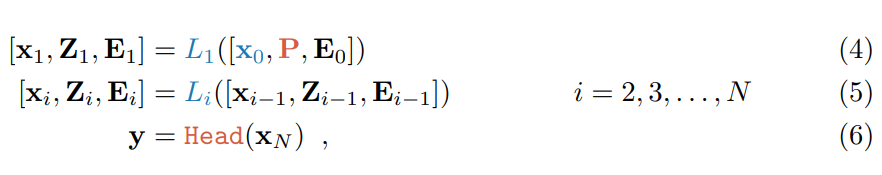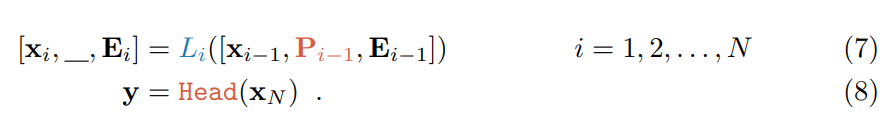Source: Machine Heart
This article is about 2000 words long and is recommended to be read in 5 minutes.
An effective solution to optimize Transformers, achieving significant improvements in downstream tasks with only a small number of additional parameters.
Researchers from Cornell University, Meta AI, and the University of Copenhagen proposed an effective solution to optimize Transformers, achieving significant improvements in downstream tasks with only a small number of additional parameters.
Recognition problems are often addressed by processing large amounts of curated or raw data through pre-trained large foundational models. This seems to be a feasible pattern: by utilizing the latest and best foundational models, significant progress can be made on multiple recognition problems.
However, in practice, there are some challenges in using these large models for downstream tasks. The most direct (and often most effective) adaptation strategy is to fully fine-tune the pre-trained model end-to-end for the task. However, this strategy requires storing and deploying a separate copy of the backbone network parameters for each task. Therefore, this method is often costly and impractical, especially since models based on the Transformer architecture are significantly larger than convolutional neural networks.
Recently, researchers from Cornell University, Meta AI, and the University of Copenhagen attempted to find the best way to adapt large pre-trained Transformer models for downstream tasks.
Paper link: https://arxiv.org/abs/2203.12119
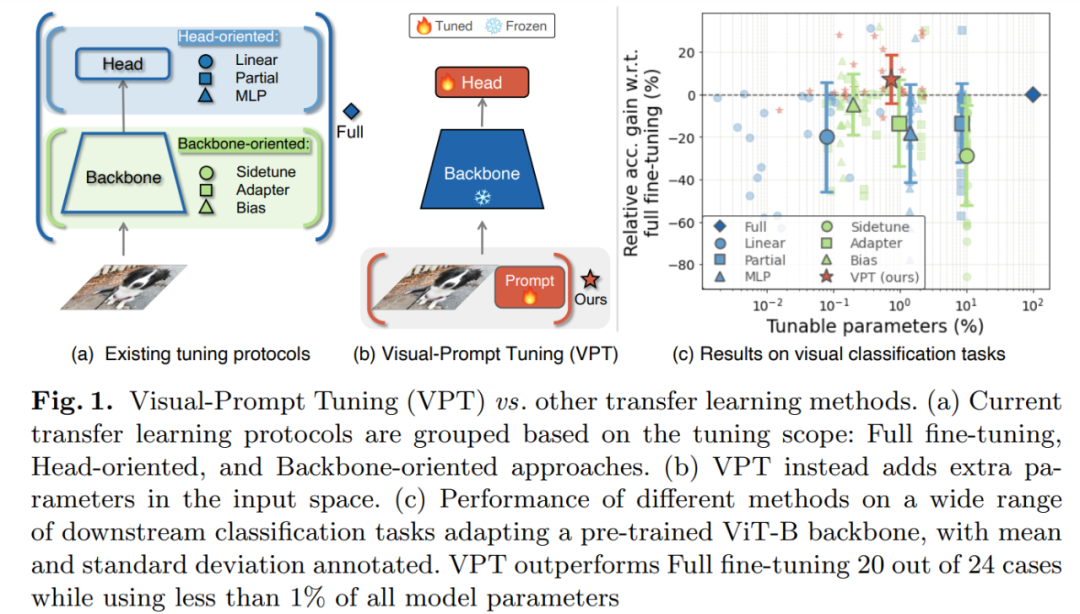
First, a simple strategy to solve this problem is to refer to the methods of convolutional networks adapting to new tasks, as shown in Figure 1 (a). A more common approach is to only fine-tune a subset of the parameters, such as the classifier head or bias term; some studies consider adding additional residual blocks (or adapters) to the backbone network. These strategies can also be applied to Transformer models. However, these strategies often do not perform as well in terms of accuracy compared to full fine-tuning.
This study’s researchers explored a completely different route. They did not modify or fine-tune the pre-trained Transformer itself but instead modified the input to the Transformer. Inspired by the latest advances in prompt methods, the researchers proposed a simple and effective new method to apply Transformer models to downstream visual tasks (Figure 1 (b)), namely Visual Prompt Tuning (VPT).
The VPT method introduces a small number of task-specific learnable parameters only in the input space while keeping the entire pre-trained Transformer backbone network fixed during downstream training. In practice, these additional parameters are simply added to the input sequence of each layer of the Transformer and updated along with the linear head during fine-tuning.
The study used a pre-trained ViT backbone network to complete 24 different downstream recognition tasks, and VPT outperformed all other transfer learning baselines, even surpassing full fine-tuning methods in 20 cases, while using only a very small number of parameters (less than 1% of the backbone network parameters).
Experimental results show that VPT has unique advantages. In NLP, prompt methods can only perform comparably to full fine-tuning methods in some specific cases. VPT is particularly effective in small data environments and maintains its advantages across various data scales. Additionally, VPT is competitive in the scaling and design of Transformers. In summary, VPT is one of the most effective methods for adapting to the growing visual backbone networks.
VPT introduces a small number of learnable parameters into the input space of the Transformer while keeping the backbone network fixed during downstream training. The overall framework is shown in Figure 2.
For a Vision Transformer (ViT) with N layers, the input image is divided into m fixed-size patches {I_j ∈ R^{3×h×w} | j ∈ N, 1 ≤ j ≤ m}. Here, h and w are the height and width of the image patches. Next, each patch is first embedded into a d-dimensional latent space with positional encoding:
Where E_i = {e^j_i ∈ R^d | j ∈ N, 1 ≤ j ≤ m} represents the set of image patch embeddings and also serves as the input to the (i+1)th Transformer layer L_(i+1). Along with an additional learnable classification token ([CLS]), the entire ViT can be expressed as:
x_i ∈ R^d represents the embedding of [CLS] in the input space of L_(i+1). [・,・] indicates fusion (stacking) and concatenation along the sequence length dimension, i.e., [x_i , E_i ] ∈ R^{(1+m)×d}. Each layer L_i consists of multi-head self-attention (MSA), feedforward networks (FFN), as well as LayerNorm and residual connections. A neural classification head is used to map the final layer’s [CLS] embedding x_N to the predicted class probability distribution y.
Given a pre-trained Transformer model, this study introduces p dimensions of continuous embeddings of size d into the input space after the embedding layer, i.e., prompts. During fine-tuning, only the task-specific prompts are updated, while the Transformer backbone remains unchanged. Depending on the number of Transformer layers involved, the researchers proposed two variants, VPT-shallow and VPT-deep, as shown in Figure 2.
VPT-Shallow: *prompts are only inserted into the first Transformer layer L_1. Each prompt is a learnable d-dimensional vector. The set of p prompts is represented as P = {p_k ∈ R^d | k ∈ N, 1 ≤ k ≤ p}, and the shallow-prompted ViT is:
Where Z_i ∈ R^{p×d} represents the features computed at the i-th Transformer layer, [x_i , Z_i , E_i ] ∈ R^{(1+p+m)×d}.
As shown in Figure 2, the variables marked in orange and blue represent learnable and fixed parameters, respectively. It is worth noting that for ViT, the position of x_N relative to the prompts remains unchanged because they are inserted after positional encoding; for example, [x_0, P, E_0] and [x_0, E_0, P] are mathematically equivalent. This also applies to VPT-Deep.
VPT-Deep: prompts are introduced into the input space of every Transformer layer. For the (i+1)th layer L_(i+1), the set of learnable prompts for input is represented as P_i = {p ^k_i ∈ R^d | k ∈ N, 1 ≤ k ≤ m}. The ViT for VPT-Deep is:
The storage of visual prompts: VPT has significant advantages when multiple downstream tasks are present, requiring only the learned prompts and classification heads to be stored for each task while reusing the original copy of the pre-trained Transformer model, which significantly reduces storage costs. For example, given a ViT-Base with 86 million parameters (d = 768), 50 VPT-Shallow and VPT-Deep produce additional p × d = 50 × 768 = 0.038M and N × p × d = 0.46M parameters, respectively, accounting for only 0.04% and 0.53% of all ViT-Base parameters.
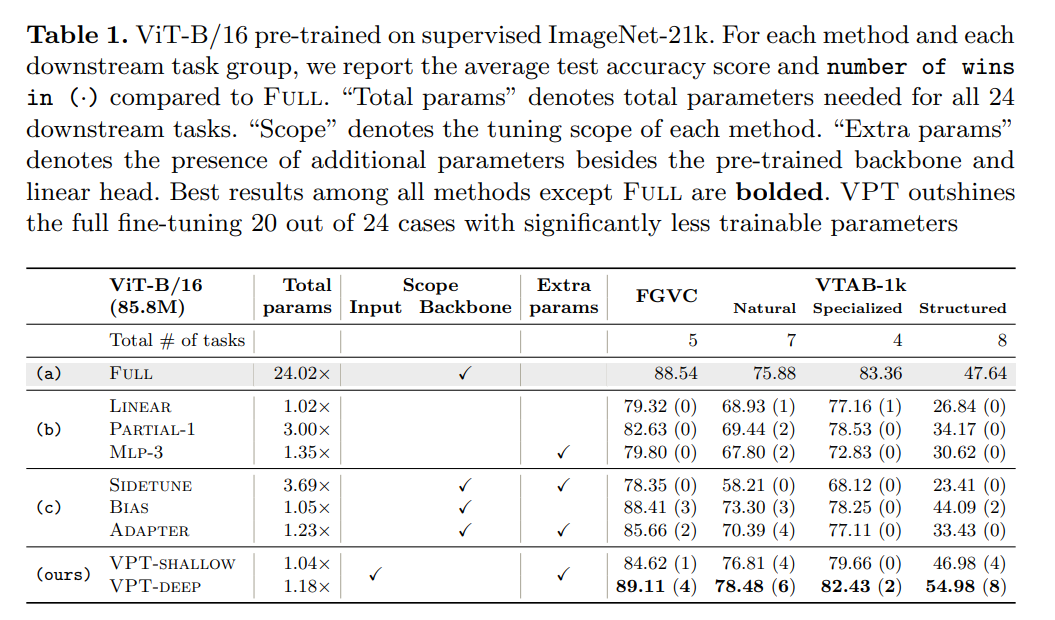
Table 1 shows the results of fine-tuning the pre-trained ViT-B/16 on 4 different groups of downstream tasks, comparing VPT with 7 other tuning methods. We can see:
-
VPT-Deep outperformed all other methods in 3 of the 4 problem categories (20 out of 24 tasks) (Table 1 (a)), while significantly reducing the total number of model parameters used (1.18× vs 24.02×). It is evident that VPT is a promising method for adapting larger Transformers in visual tasks.
-
VPT-Deep outperformed all other parameter tuning methods across all task groups (Table 1 (b,c)), indicating that VPT-deep is the best fine-tuning strategy in storage-constrained environments.
-
Although slightly inferior to VPT-deep, VPT-shallow still performs better than the head-oriented methods in (Table 1 (b)). If storage constraints are severe, VPT-shallow is a suitable choice for deploying multi-task fine-tuned models.
Figure 3 shows the average task results of each method across different training data scales. VPT-deep outperformed other baselines across various data scales.
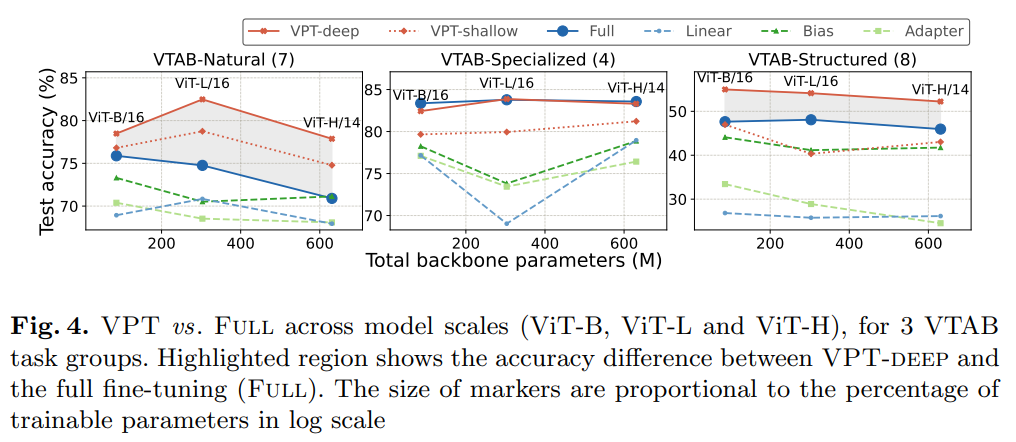
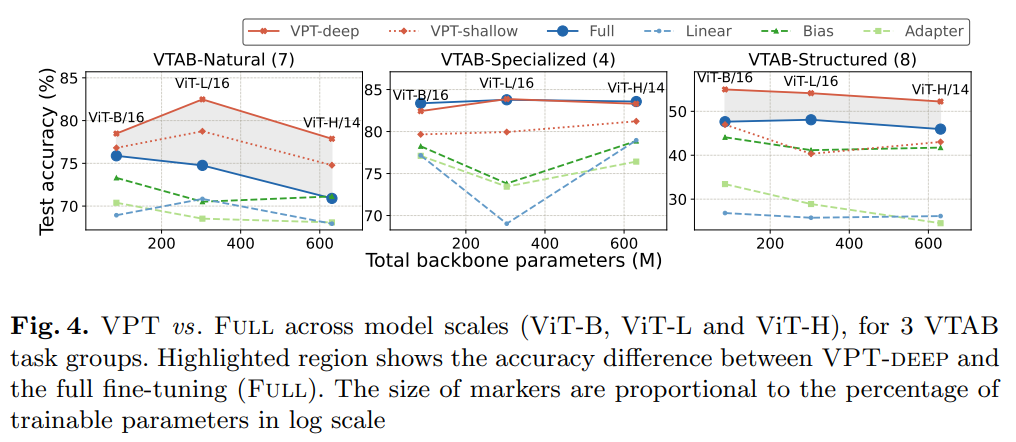
Figure 4 shows the performance of VTAB-1k under three different backbone scales: ViT-Base/Large/Huge, where VPT-deep significantly outperformed Linear and VPT-shallow.
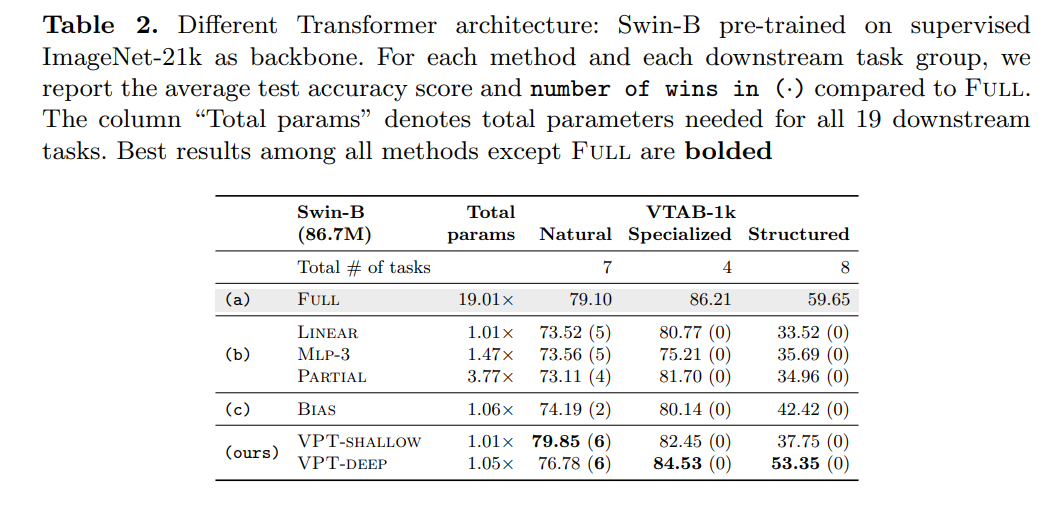
Additionally, the researchers extended VPT to Swin, using MSA in local shifted windows and merging patch embeddings at deeper levels. For simplicity and generality, the researchers implemented VPT in the most straightforward way: prompts were used in local windows and ignored during the patch merging phase.
As shown in Table 2, the study conducted experiments on ImageNet-21k supervised pre-trained Swin-Base. Although in this case, Full generally produced the highest accuracy (with a high total parameter cost), VPT still outperformed other fine-tuning methods for three subsets of VTAB.