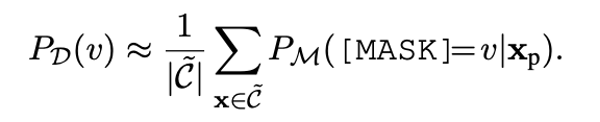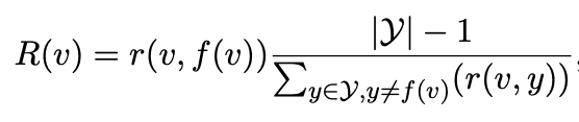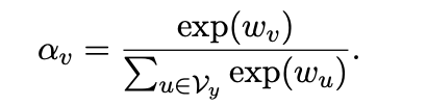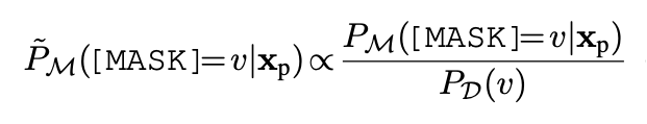Source: TsinghuaNLP, Deep Learning Natural Language Processing
This article is about 2400 words long and is recommended to be read in 5 minutes.
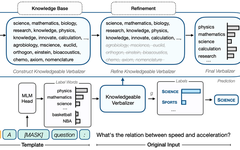
This article uses a knowledge base to expand and improve label words, achieving better text classification results.

Using Prompt Learning for text classification tasks is an emerging method that leverages pre-trained language models. In Prompt Learning, we need a label word mapping (verbalizer) to convert predictions at the [MASK] position into classification labels. For example, under the mapping {POLITICS: “politics”, SPORTS: “sports”}, the predicted scores of the pre-trained model at the [MASK] position for the label words politics/sports will be treated as the predicted scores for the labels POLITICS/SPORTS.
Manually defined or automatically searched verbalizers have drawbacks such as strong subjectivity and limited coverage. We used a knowledge base to expand and improve label words, achieving better text classification results. This also provides a reference for how to introduce external knowledge under Prompt Learning.
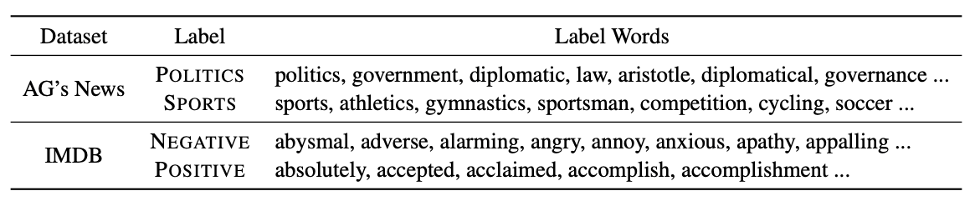
We propose using a knowledge base to expand label words, for example, through tools such as related word lists and sentiment dictionaries, based on manually defined initial label words. For instance, the mapping {POLITICS: “politics”, SPORTS: “sports”} can be expanded into the following words:
Table 1: Label words expanded based on the knowledge base.
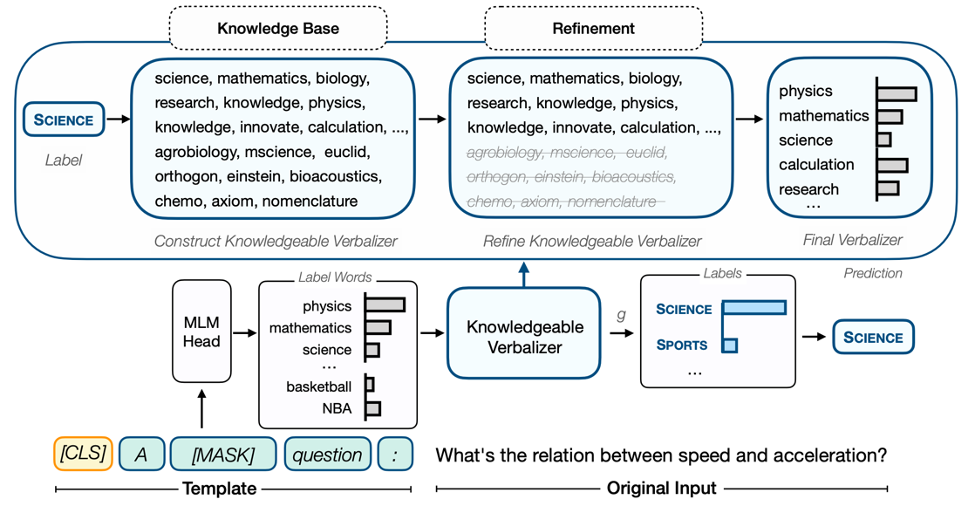
Figure 1: KPT flowchart for the question classification task.
After that, we can map the predicted probabilities from multiple words to a specific label through a many-to-one mapping.
However, since the knowledge base is not tailored for the pre-trained model, label words expanded from the knowledge base may contain a lot of noise. For example, the word movement expanded from SPORTS may have a high correlation with POLITICS, causing confusion; or the word machiavellian (meaning unscrupulous in the pursuit of power) expanded from POLITICS may be predicted poorly due to its low frequency, or even be broken down into multiple tokens, losing the meaning of the word itself.
Therefore, we propose three fine-tuning methods and one calibration method.
01. Frequency Fine-Tuning
We utilize the output probabilities of the pre-trained model M for label words v as the prior probabilities of the label words to estimate their prior occurrence frequencies. We remove label words with lower frequencies.
Formula 1: Frequency Fine-Tuning. C represents the corpus.
02. Relevance Fine-Tuning
Some label words are not very relevant to the label, and some label words may confuse different labels. We use the idea of TF-IDF to assign each label word an importance score for a specific category.
Formula 2: Relevance Fine-Tuning, r(v,y) is the relevance between a label word v and label y, similar to the TF term. The right side term is similar to the IDF term, where we want this term to be large, meaning that v has a small relevance with its non-corresponding classes.
03. Learnable Fine-Tuning
In few-shot experiments, we can assign a learnable weight to each label word, thus the importance of each label word becomes:
Formula 3: Learnable label word weights.
04. Context-Based Calibration
In zero-shot experiments, the prior probabilities of different label words may differ significantly, for example, the prediction for basketball may naturally be larger than for fencing, which can diminish the impact of many niche label words. We use calibration to balance this effect.
Formula 4: Context-Based Calibration, the denominator is the prior probability in Formula 1.
Using the above fine-tuning methods, the label words expanded from our knowledge base can be effectively utilized.
Table 2: Zero-Shot Text Classification Task.
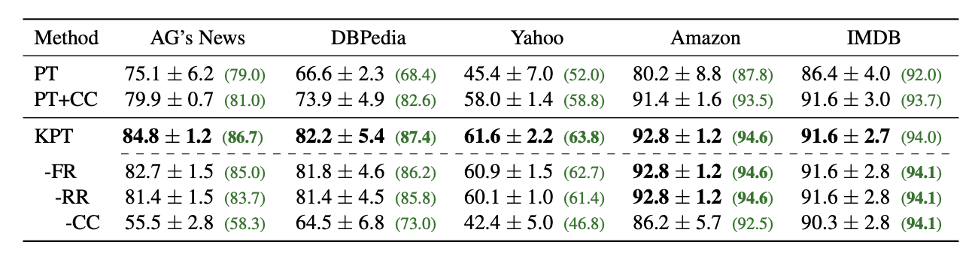
As shown in Table 2, in zero-shot scenarios compared to ordinary Prompt templates, performance has improved significantly by 15 points. Compared to the addition of label word fine-tuning, there is at most an 8-point improvement. Our proposed frequency fine-tuning and relevance fine-tuning methods are also useful.
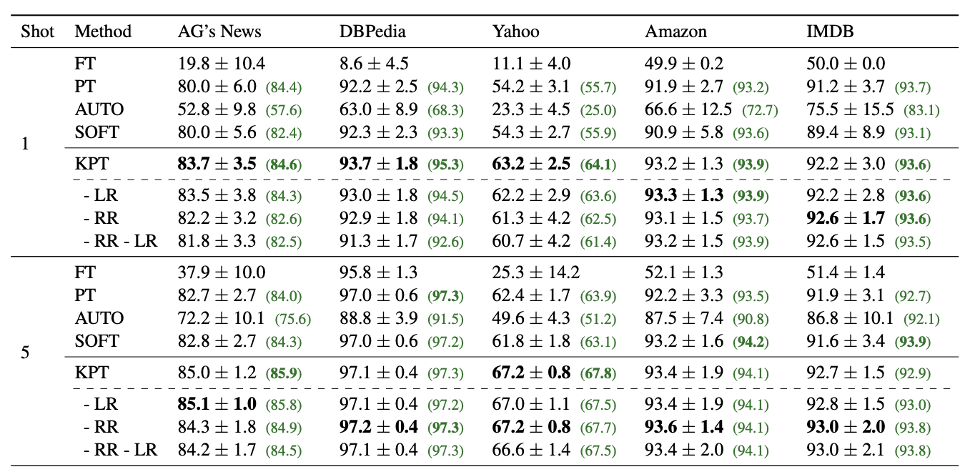
Table 3: Few-Shot Text Classification Task.
As shown in Table 3, in few-shot scenarios, our proposed learnable fine-tuning combined with relevance fine-tuning also shows significant improvement. AUTO and SOFT are both automatic label word optimization methods, where SOFT initializes with manually defined label words. It can be seen that the effects of these two methods are not as good as KPT.
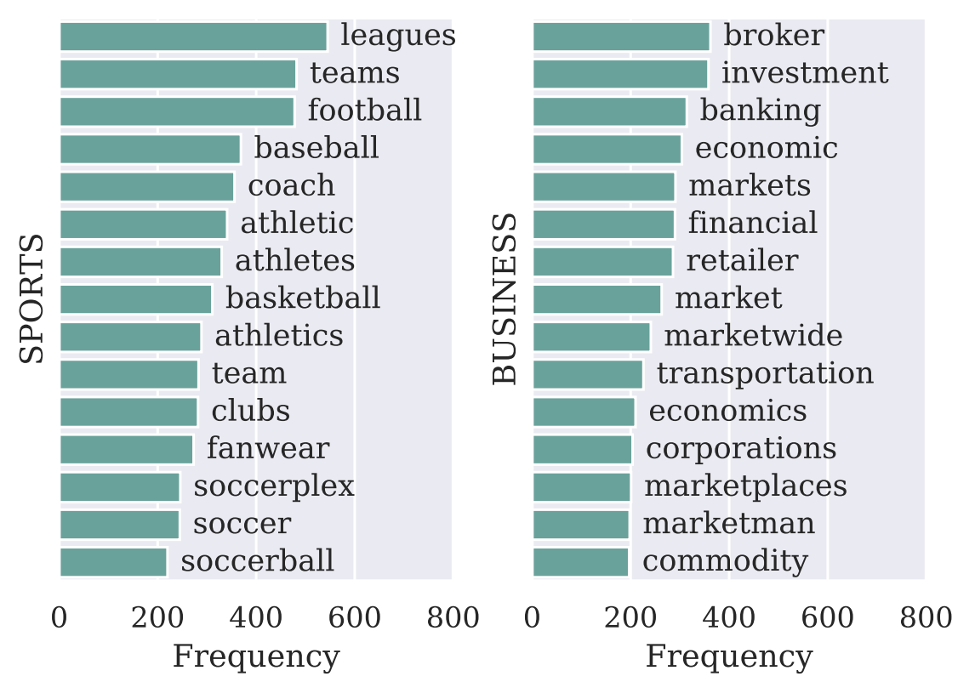
Figure 2: Contribution of knowledge base expanded label words for predictions in SPORTS and BUSINESS categories.
The visualization of label words indicates that each sentence may rely on different label words for predictions, fulfilling our expectation of increasing coverage.
The recently popular field of Prompt Learning, in addition to template design, the design of verbalizers is also an important link to bridge MLM and downstream classification tasks. Our proposed knowledge base expansion is intuitive and effective. It also provides some reference for how to introduce external knowledge in the utilization of pre-trained models.
Paper Link:
https://arxiv.org/abs/2108.02035
Code Repository:
https://github.com/thunlp/KnowledgeablePromptTuning
Editor: Yu Tengkai