

In an era flooded with fragmented reading, fewer people pay attention to the exploration and thinking behind each paper.
In this column, you will quickly get the highlights and pain points of selected papers, keeping up with the forefront of AI achievements.
Click the “Read Original” at the bottom of this article to join the community and see more of the latest paper recommendations.
The paper notes recommended in this issue come from PaperWeekly community user @Zsank.This paper uses non-saturating activation functions like Relu to make the network more robust, capable of processing very long sequences (over 5000 time steps) and building very deep networks (21 layers were used in experiments). It achieves better results than LSTM in various tasks.
If you are interested in this work, click “Read Original” at the bottom to view the original paper.
About the Author: Mai Zhensheng, a master’s student at the School of Data Science and Computer at Sun Yat-sen University, focusing on natural language processing and question-answer systems.
■ Paper | Independently Recurrent Neural Network (IndRNN): Building A Longer and Deeper RNN
■ Link | https://www.paperweekly.site/papers/1757
■ Source Code | https://github.com/batzner/indrnn
Paper Highlights
Traditional RNNs suffer from gradient vanishing/explosion issues due to parameter sharing over time. While LSTM/GRU address the gradient vanishing/explosion problem within layers, gradients still decay between layers, making it difficult to build deep networks with LSTM/GRU. Additionally,LSTM/GRU struggle to capture longer temporal information.
Moreover, traditional RNNs have inter-connected neurons within layers, making it difficult to reasonably interpret neuron behavior.
Based on these issues, the paper proposes IndRNN, which highlights:
1. Decoupling neurons within RNN layers to make them independent, enhancing neuron interpretability.
2. Ordered lists can use non-saturating activation functions like Relu to solve the gradient vanishing/explosion problems within and between layers, while also being robust.
3. Ordered lists can handle longer sequence information than LSTM.
Model Introduction
The model introduced in the paper is quite simple. Before introducing the model, let’s review the knowledge related to RNN gradients.
RNN Gradient Issues
First, let’s look at the computation of RNN hidden states:
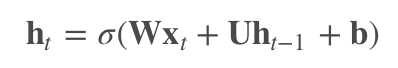
Let the objective function at time T be J, then the gradient calculation at time t during backpropagation is:
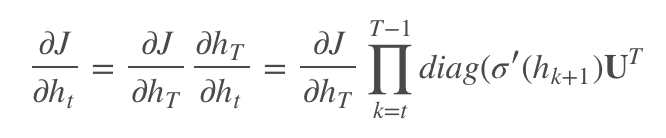
Where diag(σ′(hk+1)) is the Jacobian matrix of the activation function. It can be seen that the gradient calculation of RNN depends on the product of the diagonal matrix diag(σ′(hk+1))U^T, which requires computing the n-th power of this diagonal matrix.
-
If any diagonal element is less than 1, the n-th product will approach 0;
-
If any diagonal element is greater than 1, the n-th product will approach infinity.
The two commonly used activation functions in RNNs, tanh has a derivative of 1−tanh², with a maximum value of 1, and approaches 0 at both ends; sigmoid has a derivative of sigmoid(1−sigmoid), with a maximum value of 0.25, and approaches 0 at both ends.
It can be seen that the derivatives of both activation functions are mostly less than 1. Therefore, most elements of the diagonal matrix formed by multiplying them with the recurrent weight coefficients are less than 1 (there may be cases equal to 1, but none greater than 1), resulting in exponential decay of the gradient during the product operation, i.e., the “gradient vanishing” phenomenon. This corresponds to the first case.
In contrast, using the Relu function in RNN, since Relu has a constant derivative of 1 for x > 0, if any element in U is greater than 1, the resulting diagonal matrix will have elements greater than 1, causing the gradient explosion phenomenon during the product operation. This corresponds to the second case.
Solutions
Gated Functions (LSTM/GRU)
The purpose of introducing gating is to change the product of the activation function derivatives into addition. For example, in LSTM:
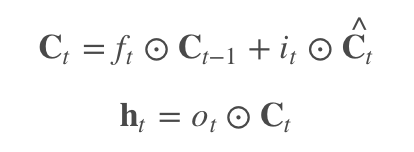
During backpropagation, there are two hidden states:
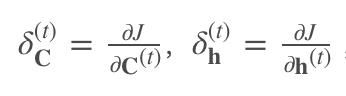
Where only C(t) participates in backpropagation:
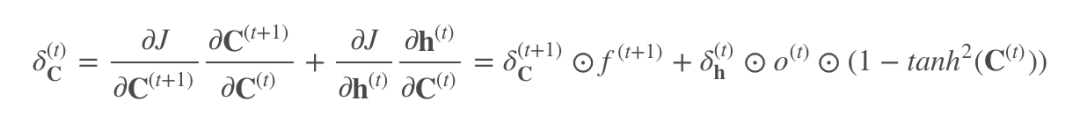
The term after the plus sign is the derivative of tanh, where the term before the plus sign controls the degree of gradient decay. When f=1, even if the subsequent term is very small, the gradient can still be effectively passed to the previous time step; when f=0, the signal from the previous time step has no effect on this moment, thus it can be 0.
Although gated functions effectively alleviate the gradient vanishing problem, it is still unavoidable when processing very long sequences. Nevertheless, LSTM/GRU has performed well in existing NLP tasks.The main issue with the gated functions proposed in the paper is that the presence of gates prevents parallel computation and increases computational complexity.
Moreover, in multi-layer LSTMs, since the tanh function is still used, the gradient vanishing between layers remains unresolved (primarily due to the influence of
Initialization (IRNN)
Hinton proposed using Relu as an activation function in RNNs in 2015. The drawbacks of using Relu as an activation function in RNNs have been previously explained. To address this issue, IRNN initializes the weight matrix to the identity matrix and sets the bias to 0 (hence the I in IRNN stands for Identity Matrix).
Since then, improvements based on IRNN have been proposed, such as initializing the weight matrix to a positive definite matrix or adding regularization terms. However, IRNN is very sensitive to the learning rate and is prone to gradient explosion when the learning rate is high.
Gradient Clipping
In backpropagation, there is a gradual process before gradient vanishing/explosion occurs. Gradient clipping means that during this gradual process, a set number of steps is artificially defined to be passed, i.e., the diagonal matrix product is set to multiply a few times, then forcibly brought back to normal value levels before proceeding with gradient descent. This method is effective for addressing gradient issues, but it involves human factors, and the forcibly returned value may not be accurate. Is there a more elegant way?
IndRNN
To solve the gradient vanishing/explosion problem, IndRNN introduces Relu as the activation function and makes neurons within layers independent. With slight modifications to the RNN equations, it becomes IndRNN:
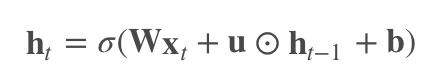
The weight coefficients change from matrix U to vector u. ⊙ represents the element-wise product of matrices. This means that at time t, each neuron only receives the current input and its state from t-1 as input.
In contrast, in traditional RNNs, at time t, each neuron receives the states of all neurons from the previous time step as input. Therefore, each neuron in IndRNN can independently process a spatial pattern, making visualization feasible. Now let’s look at the gradient issue:
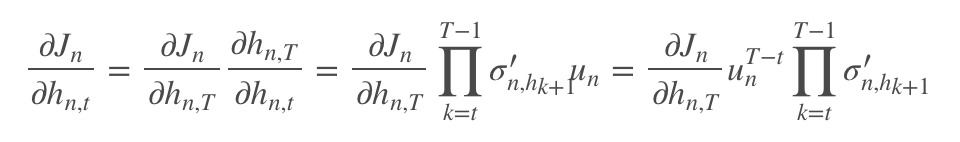
Compared to the gradient of traditional RNN, the product operation is no longer a matrix operation, but rather separates the derivative of the activation function from the recurrent weight coefficients, making it logical to use Relu as the activation function. Thus, the gradient problem is perfectly solved (the author provides detailed derivations in the paper).
The interconnection between neurons relies on inter-layer interactions. This means that neurons in the next layer will receive outputs from all neurons in the previous layer as input (similar to a fully connected layer).
The author proves in the paper that two layers of IndRNN are equivalent to a single layer with a linear activation function and a diagonalizable matrix as the recurrent weight of a traditional RNN.
IndRNN can achieve multi-layer stacking. In a multi-layer stacking structure, since inter-layer interactions are fully connected, improvements can be made, such as changing the fully connected method to CNN connections, or introducing BN, residual connections, etc.
Experimental Introduction
The experimental section first conducts tests on three common tasks for evaluating RNN models, to verify the long-term memory capabilities of IndRNN and the feasibility of training deep networks, as a validation experiment. Then, predictions are made on the skeleton action recognition task, as an experimental experiment.
Adding Problem
Task Description: Input two sequences, the first sequence consists of uniformly sampled numbers between (0,1), and the second sequence is of the same length, with only two numbers being 1 and the rest being 0, requiring the output to be the sum of the two numbers in the first sequence corresponding to the two 1s in the second sequence.
The lengths of the experimental sequences are 100, 500, and 1000, using MSE as the objective function.
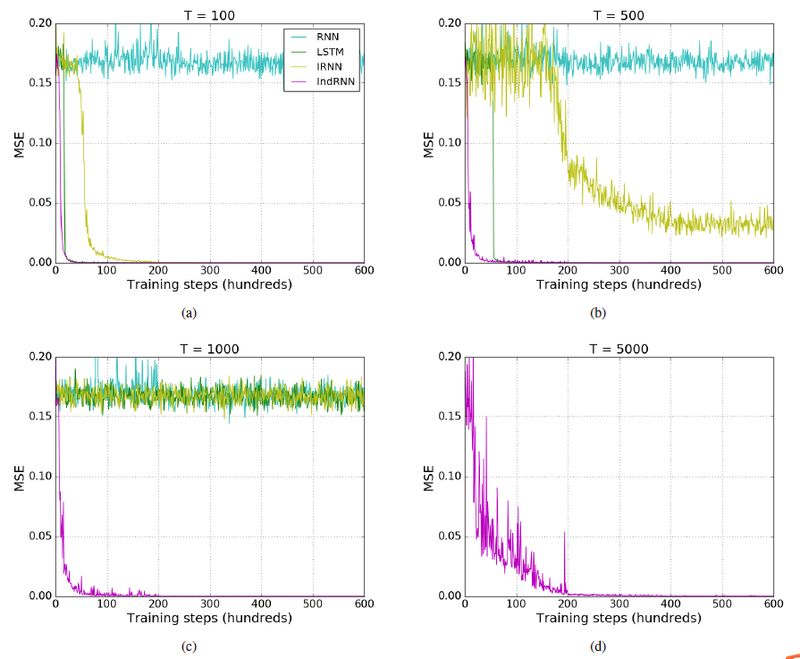
The experimental results show that both IRNN and LSTM can only process medium-length sequences (500-1000 steps), while IndRNN can easily handle sequence data spanning 5000 steps.
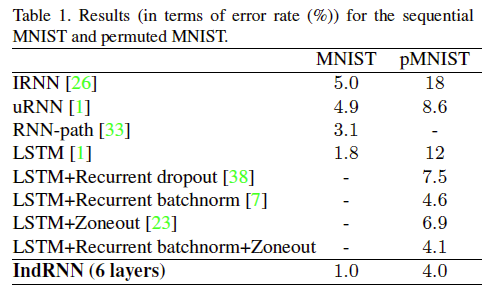
Sequential MNIST Classification
Task Description: Input a string of pixel data from MINIST for classification. The pMINIST increases the difficulty on the MINIST task: the pixel data is permuted.
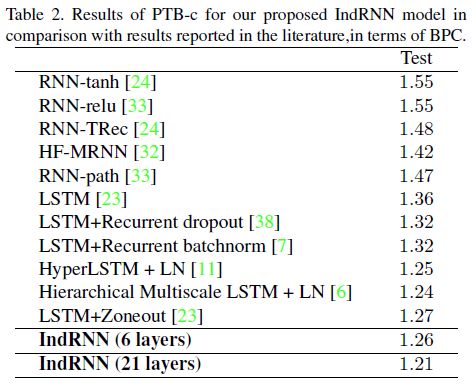
Language Modeling
Task Description: Evaluate the language model on the character-level PTB dataset. In this task, to verify that IndRNN can construct deep networks, the paper provides training and results for a 21-layer IndRNN.
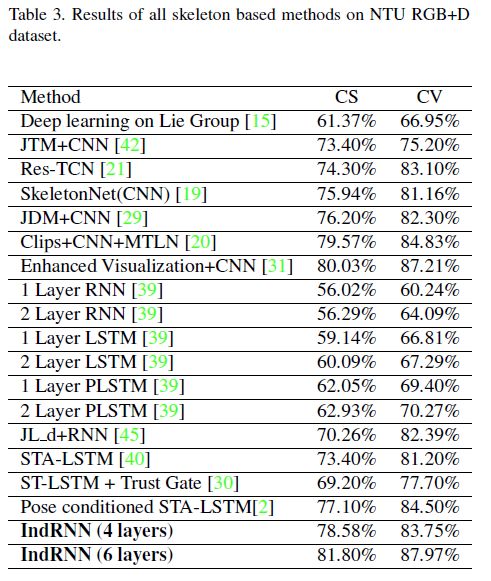
Skeleton Based Action Recognition
Task Description: Used the NTU RGB+D database, which is currently the largest skeleton-based action recognition database.
Personal Insights
The idea of making neurons independent within layers, although seemingly simple, is truly not easy to conceive. This paper provides a new perspective for understanding RNNs and makes it feasible to interpret the behavior of individual RNN neurons. Additionally, the use of the Relu function also makes the stacking structure of RNNs possible.
From the experimental results, it is evident that the performance improvement brought by IndRNN is significant. However, one point is that the Relu function may output 0, which in sequence data means discarding all previous historical information. Would it be better to switch to Leaky Relu?
This article is recommended by the AI academic community PaperWeekly, which currently covers research directions such as natural language processing, computer vision, artificial intelligence, machine learning, data mining, and information retrieval. Click “Read Original” to join the community immediately!
Click the title to see more paper interpretations:
-
CycleGAN: Change Image Style at Will
-
GAN-based Font Style Transfer
-
Confidence-based Knowledge Graph Representation Learning Framework
-
New Attention Model for Document-Level Question Answering Tasks

 #Submission Channel#
#Submission Channel#
Submission Guidelines | Let Your Writing Be Seen by Many, Many, Many People
I am an Easter egg
Unlock New Features: Popular Job Recommendations!
PaperWeekly Mini Program has been upgraded
Today arXiv√ You Might Like√Popular Jobs√
Finding full-time or internship positions is no problem
Unlocking Method
1. Scan the QR code below to open the mini program
2. Log in with your PaperWeekly community account
3. After logging in, you can unlock all features
Job Posting
Please add the assistant WeChat (pwbot02) for consultation
Long press to identify the QR code and use the mini program
*Click “Read Original” to register

About PaperWeekly
PaperWeekly is an academic platform that recommends, interprets, discusses, and reports on cutting-edge AI papers. If you research or work in the AI field, feel free to click “Community” in the WeChat public account backend, and the assistant will bring you into the PaperWeekly community group.

▽ Click | Read Original | View Original Paper