
Hong Kong University of Science and Technology & Southern University of Science and Technology & Huawei Noah’s Ark Lab | WeChat Official Account QbitAI
Fine-tuning can make general large models more adaptable to specific industry applications.
However, researchers have now found that:
Performing “multi-task instruction fine-tuning” on multimodal large models may lead to “learning more but making more mistakes” due to conflicts between different tasks, resulting in decreased generalization ability.

△Task conflicts exist in multimodal instruction fine-tuning
For example, a multimodal question-answering task may require responses to be as concise and accurate as possible, while a document understanding task may conversely require the large model to provide detailed descriptions.
The significant differences in data distribution for different downstream task instruction fine-tuning make it difficult for a large model to achieve optimal performance across multiple downstream tasks.
How can this problem be solved?
A joint research team from Hong Kong University of Science and Technology, Southern University of Science and Technology, and Huawei Noah’s Ark Lab, inspired by the open-source large model Mixtral-8×7B using MoE (Mixture of Experts), proposed using sparse expert models to create multimodal large models with better generalization performance and stronger understanding capabilities for downstream tasks.

Let’s look at the specific details.
Task Conflicts Exist in Multimodal Instruction Fine-Tuning
To verify the impact of different types of task data on model performance in multimodal instruction fine-tuning, researchers divided the data as follows:
-
VQA (Visual Question Answering): VQAv2, OKVQA, A-OKVQA, OCRVQA,
-
Captioning: COCO Caption, Web CapFilt, TextCaps,
-
Full (All Data): VQA, Captioning, LLaVA-150k, VQG (Visual Question Generation, based on VQA data).
Based on the above data, researchers fine-tuned InstructBLIP using LoRA, obtaining three expert models, and conducted zero-shot testing and evaluation on other data (Flickr30k – Image Description, GQA/SciQA/IconQA/TextVQA, etc., different types of visual question answering, HM/VSR, etc., multimodal classification or reasoning tasks).
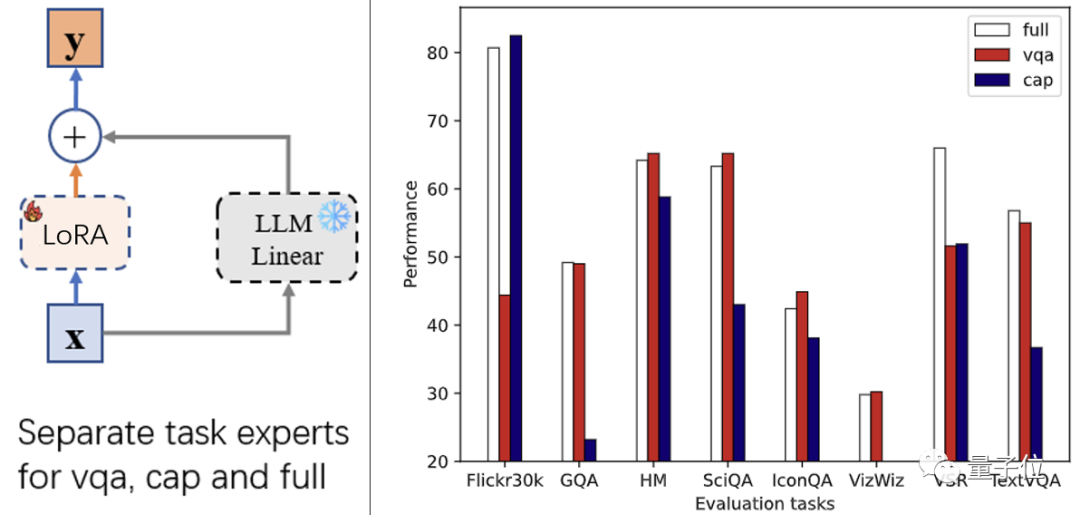
As shown in the above figure (right), it can be seen that using full data in instruction fine-tuning does not yield the best results; instead, only three downstream tasks (GQA, VSR, TextVQA) performed best under the full data expert.
This indicates that for most tasks, introducing data from other tasks during instruction fine-tuning may actually reduce model performance; task conflicts exist in multimodal instruction fine-tuning.
On the other hand, it was observed in the experiments that the two expert models for VQA and Captioning achieved better performance in their respective tasks compared to the full data expert. This approach seems to solve the task conflict issue, but it has the following limitations:
-
Knowledge from different training tasks cannot be shared among task experts;
-
Training data needs to be manually divided, which is difficult when there are many types of training data;
-
When new tasks arise, it requires manual judgment to determine which task expert to use.
To address the above limitations, the research team proposed utilizing a sparse expert model (MoE), where different experts handle different tasks and designed a method for data division to assign similar tasks to the same expert.
Sparse Expert Multimodal Large Model Based on Instruction Clustering
Dividing Data through Instruction Clustering

In large visual-language models (LVLM), this paper defines instructions as all text inputs, such as the text from C1-C4 in the above figure (left).
These instructions describe the intent and requirements of the tasks. Therefore, the authors used Kmeans to cluster all instructions into 64 categories.
As shown in the above figure (right), the clustering information of instructions can effectively represent the task types of the data. This approach saves the cost of manually dividing the data.
Routing Mixed LoRA Experts Based on Instruction Clustering Information
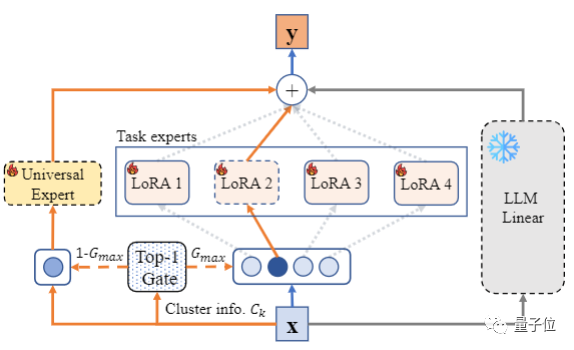
Similar to the previous task experts, the output of the model at this layer is also generated by the frozen LLM linear layer and the fine-tuned LoRA.
The difference is that here, the routing of mixed LoRA is performed using the clustering information of the data instructions. Specifically, for the model input, its routing information can be calculated as follows:
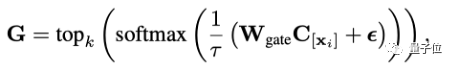
Where topk() (considering the case of k=1) keeps the top k maximum items unchanged and sets the others to 0, C is the learnable category embedding representation, C[xi] represents the clustering representation corresponding to instruction xi, and Wgate is the linear parameter for routing.
General Experts Enhance Model Generalization
Experiments found that the aforementioned instruction clustering LoRA experts indeed alleviated the issue of task conflicts, but since an expert may have only seen a portion of the tasks, the overall model’s generalization to downstream tasks was reduced.
Therefore, the research team proposed using general experts to learn instruction generalization capabilities from all data.
Unlike MoE, in addition to the task expert selected through top1, this method also activates a general expert fixedly, allowing this expert to learn from all instruction data.
Thus, the output of the model at this layer is the weighted sum of the original frozen parameters W of LLM, task expert We, and general expert Wu.
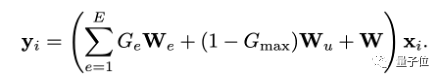
With this design, the collaboration between task experts and general experts enhances the model’s performance on tasks similar to the training set while ensuring the model’s generalization ability to new tasks.
Experimental Results
This paper follows the experimental scenarios of InstructBLIP (data usage, evaluation standards, training details) and performs instruction fine-tuning on 13 training datasets (including VQA, Captioning, VQG, etc.) and evaluates on 11 test datasets (there is no overlap between training and test datasets).
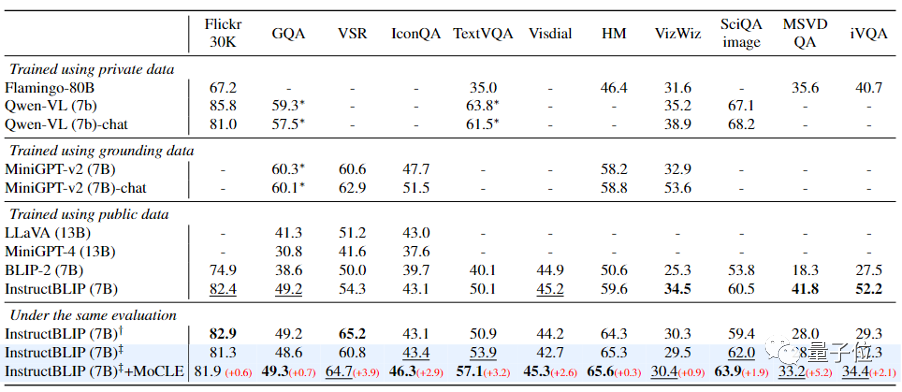
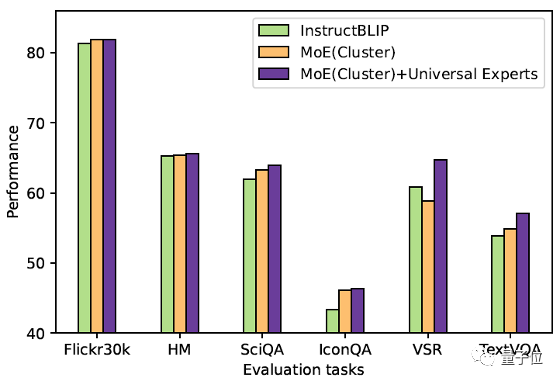
As shown in the table above, after introducing the method proposed in this article (MoCLE), InstructBLIP has improved compared to the baseline model across all downstream tasks, with particularly significant improvements in VSR, IconQA, TextVQA, and MSVD-QA.
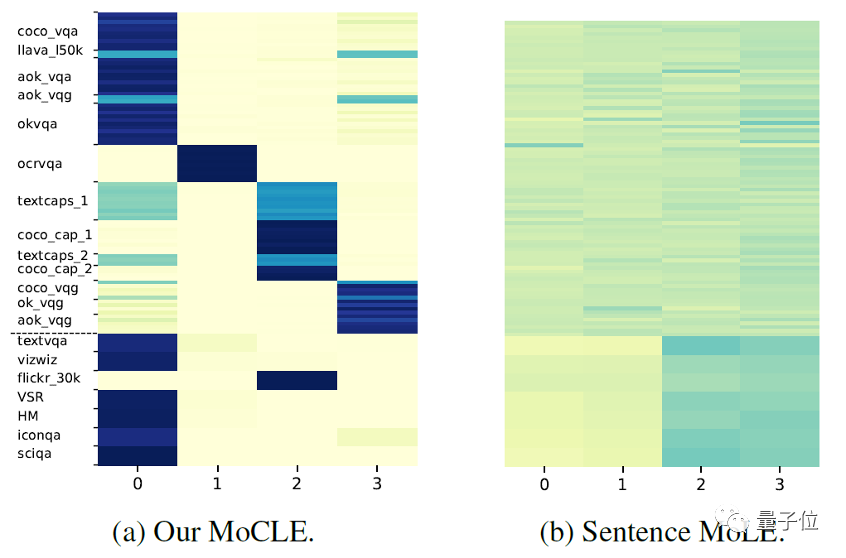
The above figure visualizes the routing results of the mixed LoRA experts at a certain layer of LLM under different data, where the dashed line indicates training and test data. (a) and (b) respectively show the results of using instruction clustering information and average representation of instruction tokens as routing.
It can be seen that when routing using instruction clustering information, the data shows differentiation among experts. For example, expert 0 mainly handles VQA-related tasks, while expert 2 mainly handles Captioning-related tasks, effectively achieving differentiation among experts. On the other hand, when using average representation of instruction tokens as conditions, different tasks have similar activations for experts, showing no differentiation.
The research team believes that the combination of sparse expert multimodal large models + general expert modules alleviates conflicts between tasks while ensuring the sparse model’s generalization ability, making multimodal large models more effective in adapting to different downstream industry applications.
This is the first work to combine LoRA and sparse expert models (MoE) in multimodal large model instruction fine-tuning to alleviate task conflicts and maintain model generalization capabilities. This work confirms its effectiveness in addressing complex downstream tasks and opens new avenues for the application and development of multimodal large models.
Paper link:https://arxiv.org/abs/2312.12379
— The End —
Click here👇 to follow me, and remember to star it~
One-click triple connection “Share”, “Like” and “View”
Daily updates on cutting-edge technological advancements~
