
Machine Heart Column
Machine Heart Editorial Team
In the past few months, with the successive releases of major works like GPT-4V, DALL-E 3, and Gemini, “the next step for AGI”—multimodal generative large models have rapidly become the focus of scholars worldwide.
Imagine, AI not only chats but also has “eyes” that can understand images, and even express itself through drawing! This means you can talk about anything with them and share images or videos, and they can respond in a richly illustrated manner.
Recently, the Shanghai Artificial Intelligence Laboratory, in collaboration with the Multimedia Laboratory of the Chinese University of Hong Kong (MMLab), Tsinghua University, SenseTime, the University of Toronto, and other institutions, jointly released a versatile and powerful open-source multimodal generative model, MM-Interleaved, which refreshes multiple tasks’ SOTA with a newly proposed multimodal feature synchronizer. It has precise understanding capabilities for high-resolution image details and subtle semantics, supports arbitrary interleaving of text and image inputs and outputs, bringing a new breakthrough in multimodal generative large models.

Paper link: https://arxiv.org/pdf/2401.10208.pdf
Project link: https://github.com/OpenGVLab/MM-Interleaved
Model link: https://huggingface.co/OpenGVLab/MM-Interleaved/tree/main/mm_interleaved_pretrain
MM-Interleaved can easily write engaging travel logs and fairy tales, accurately understand robotic operations, and even analyze the GUI interfaces of computers and mobile phones, creating beautifully styled unique images. It can even teach you how to cook, play games with you, and become a personal assistant ready to follow your commands! Without further ado, let’s look at the effects:
Effortlessly Understand Complex Multimodal Contexts
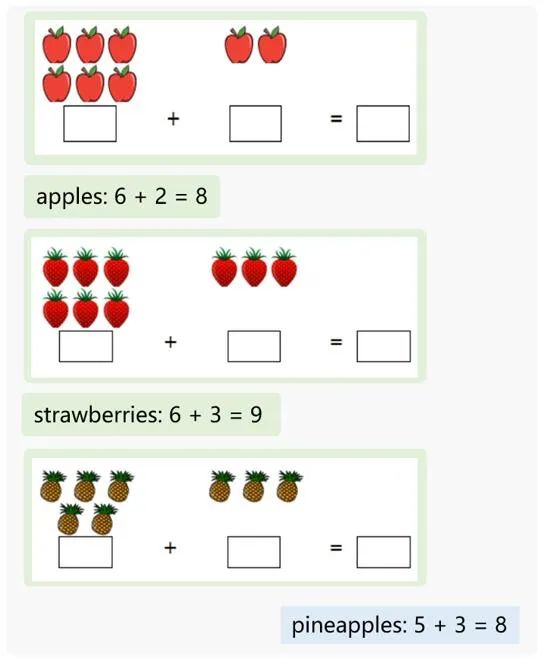
MM-Interleaved can autonomously infer and generate text responses based on the context of images and text. It can solve fruit math problems:
It can also combine common sense to infer the company corresponding to a logo image and provide an introduction:

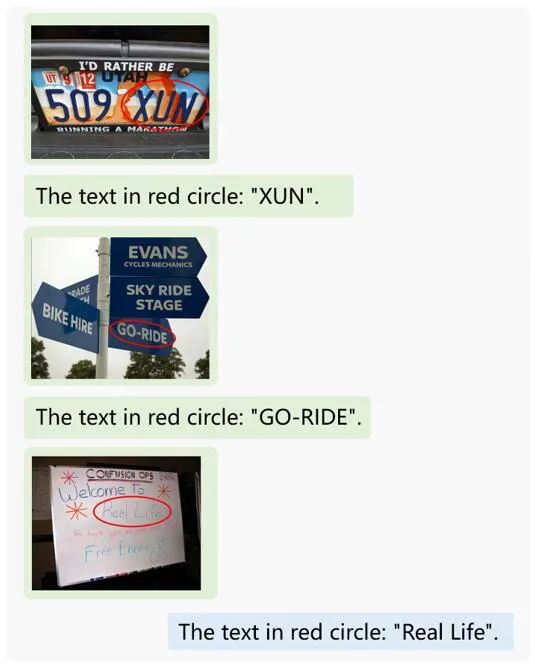
It can accurately recognize handwritten text marked with a red circle:
Moreover, the model can directly understand robotic actions represented by sequential images:

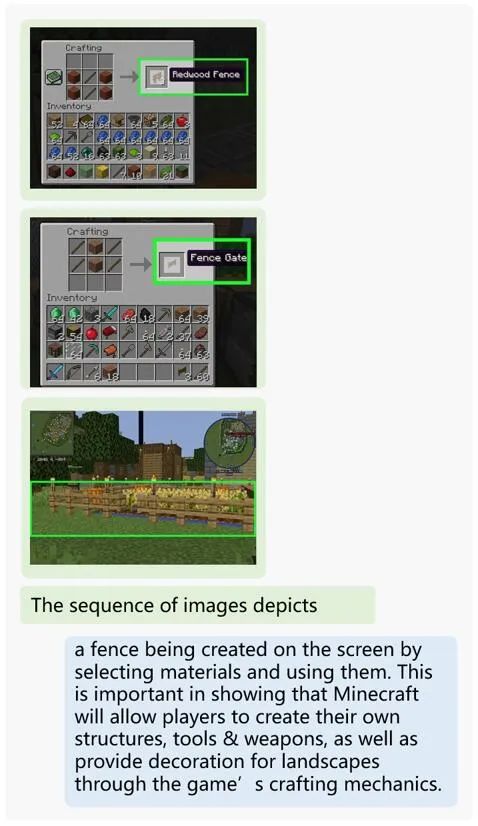
And game operations like how to build a fence in Minecraft:
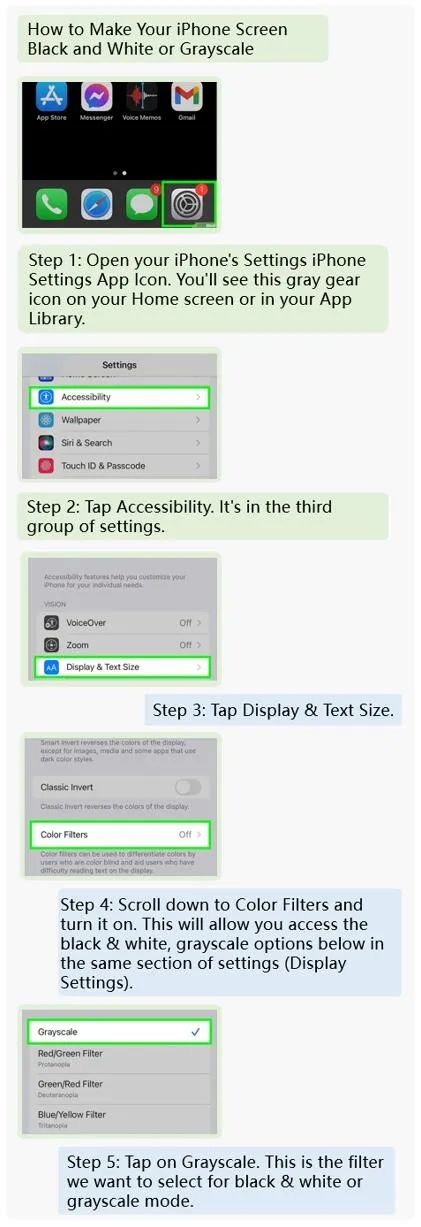
It can even guide users step-by-step on how to configure grayscale on a mobile UI:
And accurately locate that little plane hidden in the back:

Unlimited Creativity in Generating Images of Different Styles
The MM-Interleaved model can also excel in various complex image generation tasks. For example, generating a silhouette of a grand piano based on a detailed description provided by the user:

Or when users specify the objects or styles that the generated image should contain in various forms, the MM-Interleaved framework can easily handle it.
For example, generating a watercolor-style elephant:

Generating a cat’s painting in the style of a dog:

A wooden house among sunflower flowers:

And intelligently inferring the corresponding style when generating images of ocean waves.
Image Generation with Spatial Consistency
Even more surprisingly, MM-Interleaved also has the capability to generate images based on input segmentation maps and corresponding text descriptions while ensuring that the generated images maintain spatial consistency with the segmentation maps.

This feature not only showcases the model’s outstanding performance in image-text generation tasks but also provides users with a more flexible and intuitive operational experience.
Autonomously Generate Illustrated Articles
Additionally, by simply providing a brief introduction, MM-Interleaved can autonomously continue writing, generating semantically coherent articles that are richly illustrated and cover a variety of topics.
Whether it’s a fairy tale about a rose:

A tutorial guide on making apple juice:

Or a scene from a cartoon:
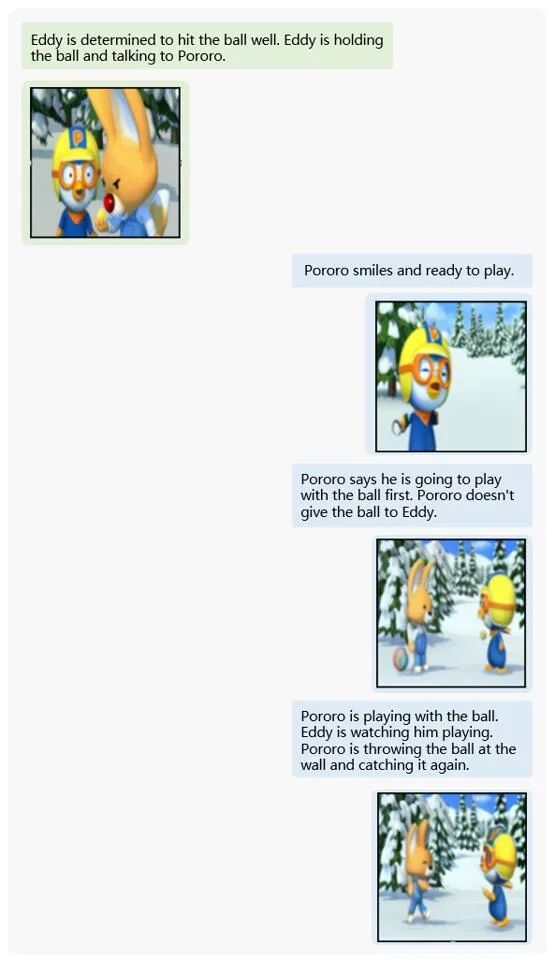
The MM-Interleaved framework demonstrates exceptional creativity. This makes the MM-Interleaved framework an intelligent collaborator with unlimited creativity, capable of helping users easily create engaging illustrated works.
MM-Interleaved aims to solve the core problems in training multimodal large models with interleaved image and text, proposing a brand new end-to-end pre-training framework through in-depth research.
Models trained based on MM-Interleaved not only perform excellently on multiple zero-shot multimodal understanding tasks with fewer parameters and without using private data but also lead the latest research efforts both domestically and internationally, such as Flamingo and Emu2.
Furthermore, through supervised fine-tuning, it achieves superior overall performance on various downstream tasks like Visual Question Answering (VQA), image captioning, referring expression comprehension, segment-to-image generation, and visual storytelling.
The pre-trained weights of the model and the corresponding code implementation have been open-sourced on GitHub.
Multimodal Feature Synchronizer and New End-to-End Training Framework
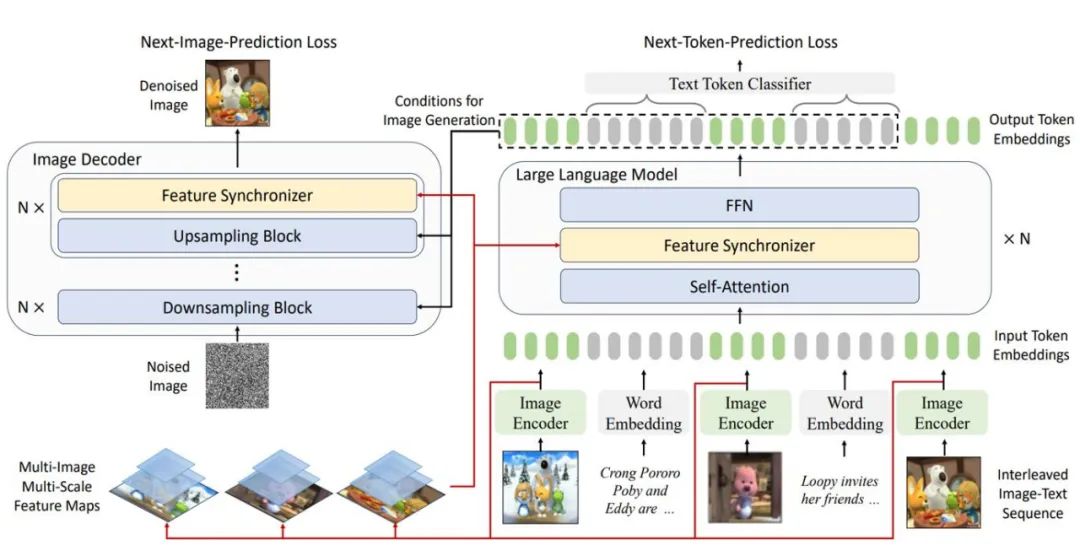
MM-Interleaved proposes a brand new end-to-end training framework specifically for interleaved image-text data.
This framework supports multi-scale image features as input, does not impose any additional constraints on the intermediate features of images and text, but directly adopts the self-supervised training objective of predicting the next text token or the next image, achieving a single-stage unified pre-training paradigm.
Compared to previous methods, MM-Interleaved not only supports interleaved generation of text and images but also efficiently captures more detailed information in images.
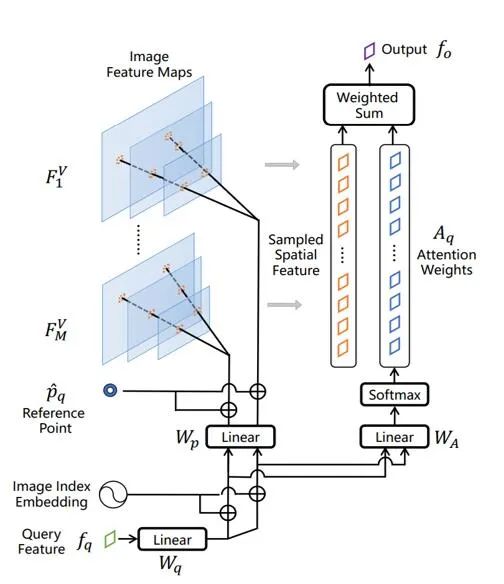
Additionally, a key implementation of MM-Interleaved includes a general multimodal feature synchronizer (Multi-modal Feature Synchronizer).
This synchronizer can dynamically inject fine-grained features of multiple high-resolution images into the multimodal large model and image decoder, achieving cross-modal feature synchronization during the decoding generation of text and images.
This innovative design injects new vitality into the development of multimodal large models.
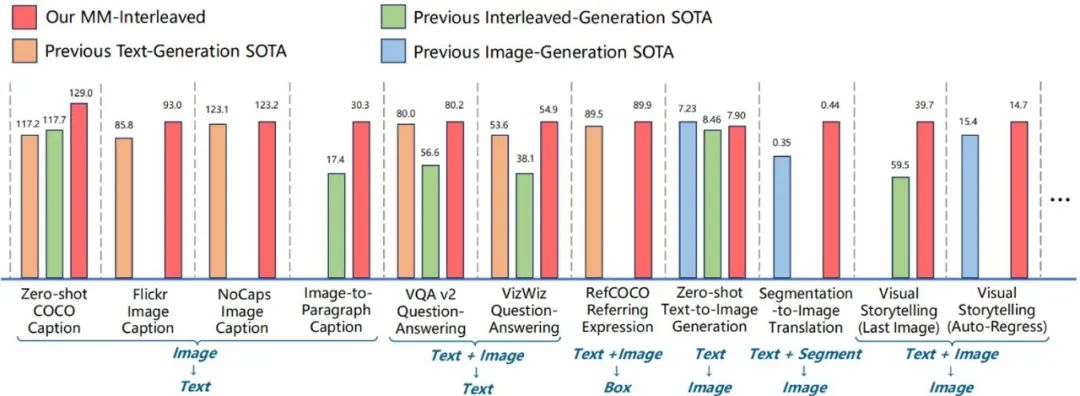
Leading Performance Across Multiple Tasks
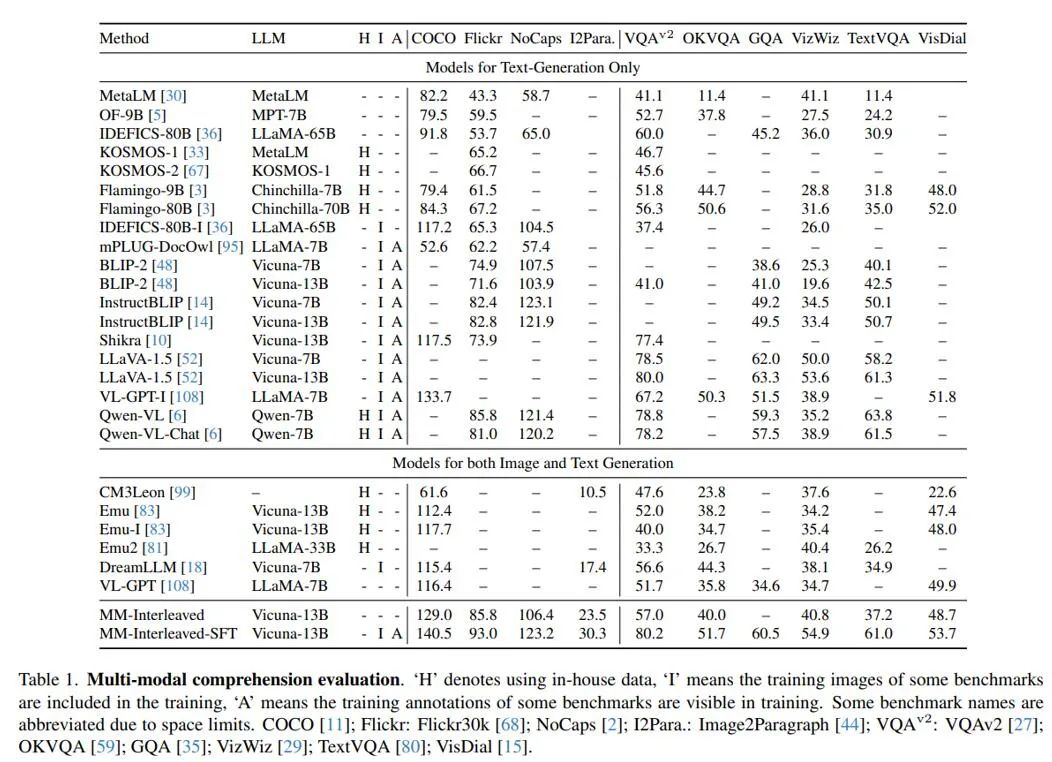
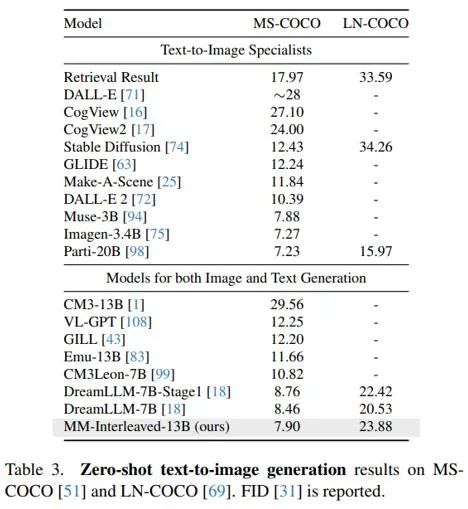
As shown in Tables 1 and 3, MM-Interleaved achieves outstanding performance in zero-shot multimodal understanding and generation tasks. This achievement not only demonstrates the powerful capabilities of this framework but also highlights its strong versatility in addressing diverse tasks.
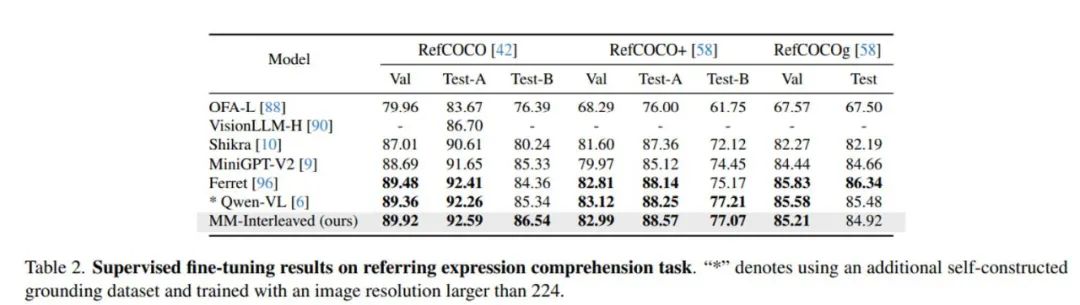

Tables 2 and 4 showcase the experimental results of MM-Interleaved after further fine-tuning, with excellent performance in multiple downstream tasks such as referring expression comprehension, segment-to-image generation, and interleaved generation of text and images.
This indicates that MM-Interleaved not only performs excellently during the pre-training phase but also maintains a leading position after fine-tuning for specific tasks, thereby providing reliable support for the widespread application of multimodal large models.
Conclusion
The emergence of MM-Interleaved marks a crucial step towards achieving comprehensive end-to-end unified modeling and training in the development of multimodal large models.
This framework’s success is reflected not only in its outstanding performance during the pre-training phase but also in its comprehensive performance across various specific downstream tasks after fine-tuning.
Its unique contribution lies not only in demonstrating powerful multimodal processing capabilities but also in opening up broader possibilities for the open-source community to build a new generation of multimodal large models.
MM-Interleaved also provides new ideas and tools for future processing of interleaved image-text data, laying a solid foundation for achieving smarter and more flexible image-text generation and understanding.
We look forward to seeing this innovation bring more surprises to applications in various fields.

© THE END
For reprints, please contact this public account for authorization.
For submissions or inquiries: [email protected]