1. What is RAG?
Retrieval-Augmented Generation (RAG) refers to optimizing the output of large language models to enable them to reference authoritative knowledge bases outside of the training data sources before generating responses. Large Language Models (LLMs) are trained on vast amounts of data, using billions of parameters to generate raw outputs for tasks like answering questions, translating languages, and completing sentences. Building on the already powerful capabilities of LLMs, RAG extends their functionality to access internal knowledge bases specific to a domain or organization, all without the need to retrain the model. This is an economical way to improve LLM outputs, keeping them relevant, accurate, and practical in various contexts.
Why is Retrieval-Augmented Generation Important?
LLMs are a key artificial intelligence (AI) technology that powers intelligent chatbots and other natural language processing (NLP) applications. The goal is to create bots that can answer user questions across various environments by cross-referencing authoritative knowledge sources. Unfortunately, the nature of LLM technology introduces unpredictability into LLM responses. Additionally, LLM training data is static, introducing a cutoff date for the knowledge it possesses. Known challenges faced by LLMs include:
-
Providing false information when there is no answer.
-
Providing outdated or generic information when users need specific current responses.
-
Generating responses based on non-authoritative sources.
-
Producing inaccurate responses due to term confusion, where different training sources use the same terms to discuss different things.
You can think of a large language model as an overly enthusiastic new employee who refuses to keep up with current events but always confidently answers every question. Unfortunately, this attitude can negatively impact user trust, which is not what you want your chatbot to emulate! RAG is one approach to addressing some of these challenges. It redirects LLMs to retrieve relevant information from authoritative, pre-determined knowledge sources. Organizations can better control the generated text output, and users can gain insights into how the LLM generates responses.
How Does Retrieval-Augmented Generation Work?
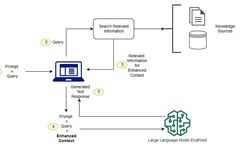
Without RAG, the LLM takes user input and creates responses based on the information it has been trained on or what it already knows. RAG introduces an information retrieval component that extracts information from new data sources based on user input. Both the user query and relevant information are provided to the LLM. The LLM uses the new knowledge along with its training data to create better responses. The following sections outline the process.
Creating External Data
New data outside the original training dataset of the LLM is referred to as external data. It can come from multiple data sources such as APIs, databases, or document repositories. Data may exist in various formats, such as files, database records, or long texts. Another AI technique known as embedding language models converts the data into numerical representations and stores it in a vector database. This process creates a knowledge base that a generative AI model can understand.
Retrieving Relevant Information
The next step is to perform a relevance search. The user query is converted into a vector representation and matched against the vector database. For example, consider an intelligent chatbot that can answer HR questions for an organization. If an employee searches for “How many vacation days do I have?”, the system will retrieve the vacation policy document and the employee’s past vacation records. These specific documents will be returned because they are highly relevant to the employee’s input. Relevance is calculated and established using mathematical vector calculations and representations.
Enhancing LLM Prompts
Next, the RAG model enhances the user input (or prompt) by adding the retrieved relevant data in context. This step utilizes prompt engineering techniques to effectively communicate with the LLM. Enhanced prompts allow the large language model to generate accurate answers to user queries.
Updating External Data
The next question might be—what if the external data is outdated? To maintain current information for retrieval, documents should be updated asynchronously, along with updating the document’s embedding representations. This can be done through automated real-time processes or regular batch updates. This is a common challenge in data analytics—change management can be performed using various data science methods. The diagram below illustrates the conceptual workflow of using RAG with LLMs.

2. What is LangChain?
LangChain is a framework for developing applications powered by language models. It primarily has two capabilities:
-
It can connect LLM models with external data sources.
-
It allows interaction with LLM models.
LLM Model: Large Language Model
3. Code Engineering
Experimental Purpose
Utilize LangChain to implement RAG applications.
pom.xml
<?xml version="1.0" encoding="UTF-8"?><project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd"> <parent> <groupId>org.springframework.boot</groupId> <artifactId>spring-boot-starter-parent</artifactId> <version>3.2.1</version> <relativePath/> <!-- lookup parent from repository --> </parent> <modelVersion>4.0.0</modelVersion><artifactId>rag</artifactId><properties> <java.version>17</java.version> <langchain4j.version>0.23.0</langchain4j.version> </properties><dependencies> <dependency> <groupId>org.springframework.boot</groupId> <artifactId>spring-boot-starter-web</artifactId> </dependency> <dependency> <groupId>org.springframework.boot</groupId> <artifactId>spring-boot-starter-thymeleaf</artifactId> </dependency> <dependency> <groupId>org.springframework.boot</groupId> <artifactId>spring-boot-devtools</artifactId> <scope>runtime</scope> </dependency> <dependency> <groupId>dev.langchain4j</groupId> <artifactId>langchain4j</artifactId> <version>${langchain4j.version}</version> </dependency> <dependency> <groupId>dev.langchain4j</groupId> <artifactId>langchain4j-open-ai</artifactId> <version>${langchain4j.version}</version> </dependency> <dependency> <groupId>dev.langchain4j</groupId> <artifactId>langchain4j-embeddings</artifactId> <version>${langchain4j.version}</version> </dependency> <dependency> <groupId>dev.langchain4j</groupId> <artifactId>langchain4j-embeddings-all-minilm-l6-v2</artifactId> <version>${langchain4j.version}</version> </dependency> <dependency> <groupId>org.projectlombok</groupId> <artifactId>lombok</artifactId> <optional>true</optional> </dependency> <dependency> <groupId>org.springframework.boot</groupId> <artifactId>spring-boot-starter-test</artifactId> <scope>test</scope> </dependency> </dependencies><build> <plugins> <plugin> <groupId>org.springframework.boot</groupId> <artifactId>spring-boot-maven-plugin</artifactId> <configuration> <excludes> <exclude> <groupId>org.projectlombok</groupId> <artifactId>lombok</artifactId> </exclude> </excludes> </configuration> </plugin> </plugins> </build></project>Controller
package com.et.rag.controller;import com.et.rag.service.SBotService;import lombok.RequiredArgsConstructor;import org.springframework.http.ResponseEntity;import org.springframework.stereotype.Controller;import org.springframework.web.bind.annotation.GetMapping;import org.springframework.web.bind.annotation.PostMapping;import org.springframework.web.bind.annotation.RequestBody;@Controller@RequiredArgsConstructorpublic class SBotController { private final SBotService sBotService; @GetMapping public String home() { return "index"; } @PostMapping("/ask") public ResponseEntity<String> ask(@RequestBody String question) { try { return ResponseEntity.ok(sBotService.askQuestion(question)); } catch (Exception e) { return ResponseEntity.badRequest().body("Sorry, I can't process your question right now."); } }}Service
package com.et.rag.service;import dev.langchain4j.chain.ConversationalRetrievalChain;import lombok.RequiredArgsConstructor;import lombok.extern.slf4j.Slf4j;import org.springframework.stereotype.Service;@Service@RequiredArgsConstructor@Slf4jpublic class SBotService { private final ConversationalRetrievalChain chain; public String askQuestion(String question) { log.debug("======================================================"); log.debug("Question: " + question); String answer = chain.execute(question); log.debug("Answer: " + answer); log.debug("======================================================"); return answer; }}EmbeddingStoreLoggingRetriever
package com.et.rag.retriever;import dev.langchain4j.data.segment.TextSegment;import dev.langchain4j.retriever.EmbeddingStoreRetriever;import dev.langchain4j.retriever.Retriever;import lombok.RequiredArgsConstructor;import lombok.extern.slf4j.Slf4j;import java.util.List;/** * EmbeddingStoreLoggingRetriever is a logging-enhanced for an EmbeddingStoreRetriever. * <p> * This class logs the relevant TextSegments discovered by the supplied * EmbeddingStoreRetriever for improved transparency and debugging. * <p> * Logging happens at INFO level, printing each relevant TextSegment found * for a given input text once the findRelevant method is called. */@RequiredArgsConstructor@Slf4jpublic class EmbeddingStoreLoggingRetriever implements Retriever<TextSegment> { private final EmbeddingStoreRetriever retriever; @Override public List<TextSegment> findRelevant(String text) { List<TextSegment> relevant = retriever.findRelevant(text); relevant.forEach(segment -> { log.debug("======================================================="); log.debug("Found relevant text segment: {}", segment); }); return relevant; }}Components
Initializing documents
package com.et.rag.configuration;import dev.langchain4j.data.document.Document;import dev.langchain4j.data.document.UrlDocumentLoader;import org.springframework.context.annotation.Bean;import org.springframework.context.annotation.Configuration;import java.util.List;import static com.et.rag.constant.Constants.SPRING_BOOT_RESOURCES_LIST;@Configurationpublic class DocumentConfiguration { @Bean public List<Document> documents() { return SPRING_BOOT_RESOURCES_LIST.stream() .map(url -> { try { return UrlDocumentLoader.load(url); } catch (Exception e) { throw new RuntimeException("Failed to load document from " + url, e); } }) .toList(); }}Initializing LangChain
package com.et.rag.configuration;import com.et.rag.retriever.EmbeddingStoreLoggingRetriever;import dev.langchain4j.chain.ConversationalRetrievalChain;import dev.langchain4j.data.document.Document;import dev.langchain4j.data.document.splitter.DocumentSplitters;import dev.langchain4j.data.segment.TextSegment;import dev.langchain4j.model.embedding.AllMiniLmL6V2EmbeddingModel;import dev.langchain4j.model.embedding.EmbeddingModel;import dev.langchain4j.model.input.PromptTemplate;import dev.langchain4j.model.openai.OpenAiChatModel;import dev.langchain4j.retriever.EmbeddingStoreRetriever;import dev.langchain4j.store.embedding.EmbeddingStore;import dev.langchain4j.store.embedding.EmbeddingStoreIngestor;import dev.langchain4j.store.embedding.inmemory.InMemoryEmbeddingStore;import lombok.RequiredArgsConstructor;import lombok.extern.slf4j.Slf4j;import org.springframework.beans.factory.annotation.Value;import org.springframework.context.annotation.Bean;import org.springframework.context.annotation.Configuration;import java.time.Duration;import java.util.List;import static com.et.rag.constant.Constants.PROMPT_TEMPLATE_2;@Configuration@RequiredArgsConstructor@Slf4jpublic class LangChainConfiguration { @Value("${langchain.api.key}") private String apiKey; @Value("${langchain.timeout}") private Long timeout; private final List<Document> documents; @Bean public ConversationalRetrievalChain chain() { EmbeddingModel embeddingModel = new AllMiniLmL6V2EmbeddingModel(); EmbeddingStore<TextSegment> embeddingStore = new InMemoryEmbeddingStore<>(); EmbeddingStoreIngestor ingestor = EmbeddingStoreIngestor.builder() .documentSplitter(DocumentSplitters.recursive(500, 0)) .embeddingModel(embeddingModel) .embeddingStore(embeddingStore) .build(); log.info("Ingesting Spring Boot Resources ..."); ingestor.ingest(documents); log.info("Ingested {} documents", documents.size()); EmbeddingStoreRetriever retriever = EmbeddingStoreRetriever.from(embeddingStore, embeddingModel); EmbeddingStoreLoggingRetriever loggingRetriever = new EmbeddingStoreLoggingRetriever(retriever); /*MessageWindowChatMemory chatMemory = MessageWindowChatMemory.builder() .maxMessages(10) .build();*/ log.info("Building ConversationalRetrievalChain ..."); ConversationalRetrievalChain chain = ConversationalRetrievalChain.builder() .chatLanguageModel(OpenAiChatModel.builder() .apiKey(apiKey) .timeout(Duration.ofSeconds(timeout)) .build() ) .promptTemplate(PromptTemplate.from(PROMPT_TEMPLATE_2)) //.chatMemory(chatMemory) .retriever(loggingRetriever) .build(); log.info("Spring Boot knowledge base is ready!"); return chain; }}application.yaml
langchain: api: # "demo" is a free API key for testing purposes only. Please replace it with your own API key. key: demo # key: OPEN_API_KEY # API call to complete before it is timed out. timeout: 30index.html
<!DOCTYPE html><html lang="en" xmlns="http://www.w3.org/1999/xhtml"><head> <meta charset="UTF-8"> <meta name="viewport" content="width=device-width, initial-scale=1"> <title>Spring Boot Doc Bot</title> <link href="https://cdn.jsdelivr.net/npm/[email protected]/dist/css/bootstrap.min.css" rel="stylesheet"> <link rel="stylesheet" href="https://cdnjs.cloudflare.com/ajax/libs/font-awesome/5.15.3/css/all.min.css"></head><body><nav class="bg-dark text-white py-3"> <div class="text-center d-flex justify-content-center align-items-center"> <img src="/logo.png" alt="Logo" style="width:60px; margin-right: 10px;"> <h2 style="margin: 0;">Welcome to Spring Boot Documentation Bot</h2> </div></nav><div class="container mt-5"> <div class="row"> <div class="col-md-8 offset-2"> <h3 class="text-center mb-3">Ask your Spring related queries here!</h3> <form> <div class="mb-3"> <label for="questionInput" class="form-label">Question</label> <input type="text" class="form-control" id="questionInput" name="question" placeholder="Enter your question" required> </div><div class="mb-3 text-center"> <button id="submitBtn" type="button" class="btn btn-primary">Ask!</button> <button id="clearBtn" type="button" class="btn btn-secondary">Clear</button> </div></form> </div> </div><div class="row my-5"> <div class="col-md-8 offset-md-2"> <label for="answerBox" class="form-label"><h5>Answer</h5></label> <div class="position-relative my-3"> <textarea class="form-control" rows="10" id="answerBox" disabled></textarea> <a href="#" class="position-absolute top-0 end-0 m-2" id="copyBtn"> <i class="far fa-copy"></i> </a> </div> </div> </div></div><script src="https://code.jquery.com/jquery-3.7.1.min.js"></script><script> $(document).ready(function () { $("#submitBtn").click(function () { let questionValue = $("#questionInput").val(); if (!questionValue) { alert('Please enter your question'); return; } $("#answerBox").val('Please wait... fetching answer...'); $.ajax({ type: "POST", url: "/ask", data: JSON.stringify({ question: $("#questionInput").val() }), //contentType: "application/json; charset=utf-8", dataType: "text", success: function (data) { //console.log(typeof data); //console.log(data); $("#answerBox").val(data); }, error: function (errMsg) { alert(errMsg); } }); }); $("#clearBtn").click(function () { $("#questionInput").val(''); $("#answerBox").val(''); }); document.getElementById("copyBtn").addEventListener("click", function() { var copyText = document.getElementById("answerBox"); copyText.select(); copyText.setSelectionRange(0, 99999); document.execCommand("copy"); alert("Copied: " + copyText.value); }); });</script></body></html>Just some key code, for all code please refer to the code repository below.
Code Repository
-
https://github.com/Harries/springboot-demo(dag)
4. Testing
Start the Spring Boot application and visit http://127.0.0.1:8080/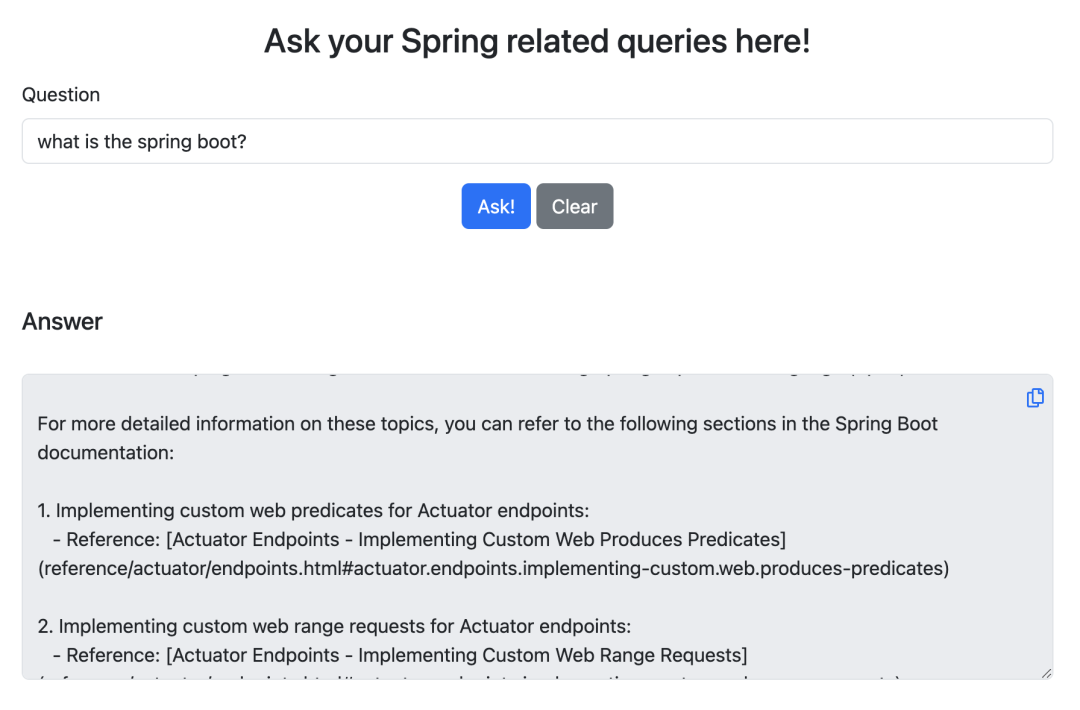
5. References
-
https://github.com/miliariadnane/spring-boot-doc-rag-bot
-
https://aws.amazon.com/cn/what-is/retrieval-augmented-generation/
-
https://github.com/liaokongVFX/LangChain-Chinese-Getting-Started-Guide
-
http://www.liuhaihua.cn/archives/711424.html