
Originally published by Data Practitioners

The process of neural networks includes the updating of its weight matrix (Weight Matrix: WM).
Once the network training is complete, the weight matrix will be permanently fixed, and its effectiveness is evaluated based on the network’s generalization results on the test data. However, many environments continue to evolve after training is complete, and the test data may deviate from the training, exceeding the neural network’s generalization capability.
This requires human intervention to retrain or adjust the model. In contrast, a fully autonomous system should learn to update its own program based on new experiences without intervention. Especially in multi-task learning and meta-learning (learning how to learn), learning how to stay updated and fine-tune the model is crucial, as it can help the network quickly adapt to various situations and new challenges.
In the study A Modern Self-Referential Weight Matrix That Learns to Modify Itself, “Father of LSTM” Jürgen Schmidhuber and others re-examined the self-referential weight matrix proposed since the 1990s based on modern techniques for updating and generating weights, particularly utilizing mechanisms established in the context of Fast Weight Programmers (FWPs), deriving a new type of self-correcting weight matrix (self-referential WM: SRWM).
This study evaluates SRWM from three aspects:
First, the model achieves competitive performance on standard few-shot learning, demonstrating that the proposed model can effectively generate useful self-correction;
Second, the ability of SRWM to adapt to real-time changes in tasks during runtime is tested by extending the few-shot learning setup to a continuous multi-task learning setup;
Finally, it is evaluated in a multi-task reinforcement learning (RL) environment set in the ProcGen game environment, which includes procedurally generated game environments. Overall, the practical applicability and strong performance of the proposed method are demonstrated.
The new self-correcting weight matrix
The newly proposed self-correcting weight matrix (SRWM) is similar to recently proposed variants of FWPs, self-training by learning its invented key/value “training” patterns and learning rates, invoking basic programming instructions based on outer products and delta function update rules.
The specific steps are as follows:
Given the input at time t, xt∈Rdin, the SRWM Wt−1∈R(dout+2*din+1)×din will produce four variables [yt,qt,kt,βt].
Among them, yt∈Rdout is the output of the layer at the current time step, qt∈Rdin and kt∈Rdin are the query vector and key vector, and βt∈R is the self-invented learning rate based on the delta function. Similar to the terminology introduced in the original SRWM paper from the 1990s, kt∈Rdin is the corrected key vector, representing the key vector, whose current value must be corrected in the SRWM; qt∈Rdin is the query vector, which is fed back into the SRWM to retrieve a new “value” vector associated with the corrected key vector.
The overall dynamics can be simply expressed as follows:
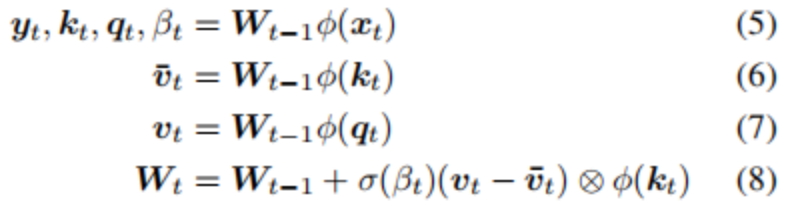
Where the value vector has dimensions:vt ∈R(dout+2*din+1). The model is shown in Figure 1.
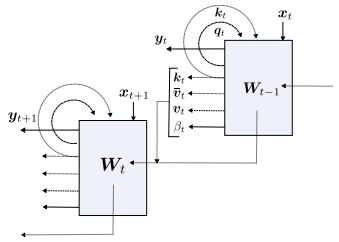
Figure 1 A “modern” self-referential weight matrix (SRWM)
Importantly, the initial value of W0 in SRWM is the only parameter in the layer that needs to be trained via gradient descent.
In practice, the output dimension of the matrix is extended from “3D+1” (dout+2*din+1) to “3D+4” (dout+2*din+4) to generate four different, self-invented time-varying learning rates βt∈R4, which are used for the computation of the four submatrices in Wt−1=[Wyt−1,Wqt−1,Wtk−1,Wβt−1], which is then used to generate yt, qt, kt and β in equation (5). To improve computational efficiency, this paper also utilizes multi-head computation in the standard Transformers model.
The aforementioned SRWM can replace any conventional weight matrix. Here, the paper primarily focuses on a model that can be obtained by replacing equations (1)-(4) in the benchmark model DeltaNet with the corresponding equations (5)-(8) in the SRWM.
The overall goal of the experiments is to evaluate the performance of the proposed SRWM on various tasks that require “good” self-modification types, thus experiments were conducted on standard supervised few-shot learning tasks and multi-task reinforcement learning in game environments.
1. Standard Few-Shot Learning
The few-shot image classification task, also known as the N-way K-shot image classification task based on a dataset containing C classes, is organized through so-called scenes.
In each scene, N different classes are randomly drawn from C classes, resulting in a dataset of N classes that are relabeled, assigning one of the N different random label indices to each class. For each of these N classes, K samples are randomly drawn. The resulting set of N×K labeled images is called the support set. The goal of the task is to predict the label of another image sampled from one of the N classes (the query image not in the support set) based on the available information in the support set.
While there are several methods to solve this problem, this paper adopts a sequential learning approach to evaluate the proposed SRWM. That is, the image/label pairs of the support set are randomly ordered to form a sequence read by a sequential processing neural network (e.g., recurrent neural network). The corresponding neural network predicts the label of the query image by encoding the support set information into its internal state. In the proposed SRWM, the model generates its own updated weights while reading the sequence of support set items, and the generated weights are used to compute the final prediction for the query image. To elaborate on this method, it is also necessary to explain how the input image/label pairs are fed into the model.
Here, the paper adopts the method used by Mishra et al., called the synchronous label setup shown in Figure 2, which is specifically designed for N-way K-shot learning. That is, the N×K items in the support set are simultaneously fed to the model along with their labels. The model only predicts the label of the (N×K+1)-th input, which is the query image without a label. Another method proposed by the paper is called the delayed label setup (as shown in Figure 3).
In fact, since the SNAIL model proposed by Mishra et al. is a transformer-like model (where standard feedforward blocks are replaced by 1D convolutions), it serves as the benchmark model for this paper’s experiments, and the TADAM method proposed by Oreshkin et al. is also introduced into the benchmark model.
However, the paper notes that TADAM is a method specifically designed for few-shot learning, which differs from the model in this paper and SNAIL, as SNAIL is a general sequential processing neural network applicable beyond few-shot learning.
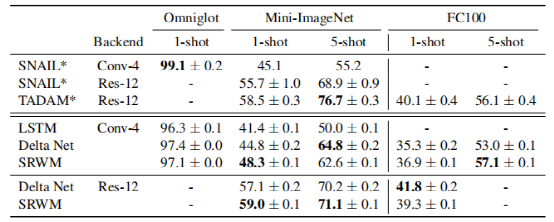
Figure 2 Synchronous label setup for N-way K-shot learning. The correct labels are input together with the corresponding inputs for the first N×K items. Only the label for the (NK+1)-th unlabeled input is predicted.
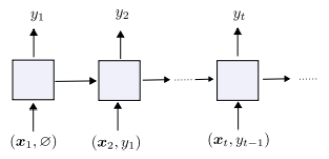
Figure 3 Delayed label setup. The correct labels are input at the next step corresponding to the inputs. Predictions are made at each step.
The final performance is directly influenced by the choice of visual feature extractor, which uses visual models to convert input images into a compact feature vector, which is then provided to the sequential processing module.
Here, the paper presents results using two popular feature extractors: Conv-4 and Res-12 on these benchmark models. The results are shown in Table 1.
Overall, the proposed SRWM performs well. Compared to the general SNAIL model, SRWM achieves competitive performance on Mini-ImageNet2, independent of the visual backend (Conv-4 or Res12).
DeltaNet and SRWM exhibit similar performance. This is a satisfactory result as it shows that a single self-correcting WM (rather than separate slow and fast networks) remains competitive in this single-task scenario.
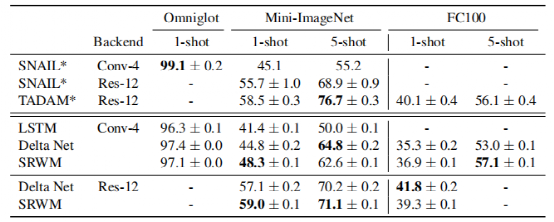
Table 1 Single-task, 5-way, few-shot classification test accuracy (%) using Conv4 or Res-12 visual feature extractors on Omniglot, Mini-ImageNet, and FC100.
The paper finds that while TADAM performs better than SRWM on 5-shot Mini-ImageNet, its performance on 1-shot, 5-shot FC100, and 1-shot Mini-ImageNet is comparable to SRWM. Although SRWM is a very general method, its overall performance is highly competitive, indicating the effectiveness of the proposed self-correcting weight matrix (the main goal of this experiment).
2. Continuous Multi-Task Adaptability
This section tests its adaptability on tasks that need to adapt to environmental changes in real-time. The paper made two modifications to the above few-shot learning.
First, the model is trained on N-way K-shot classification without using synchronous label setup (Figure 2), but rather in a delayed label setup as shown in Figure 3. Here, the model makes predictions by receiving an input image that needs to be classified and the correct label of the previous input (thus the label delivery is moved/delayed by one time step). This setup facilitates the evaluation of the model on a continuous flow of predictions/solutions. Secondly, by concatenating two image sequences from two different datasets (Omniglot and Mini-ImageNet), a sequence of images to be predicted is constructed. The model first receives a flow of images from one dataset, and at some point, the dataset suddenly changes to simulate environmental changes. The model must learn to adapt to this shift during the continuous execution of the program without human intervention.
Note that the goal of the paper is to construct a task that requires adapting to sudden changes during the model’s operation. This differs from the goal of continuous few-shot learning, which is to perform meta-learning on multiple few-shot learning tasks consecutively.
Therefore, the paper experiments in a 5-way classification setup, concatenating segments of Omniglot and Mini-ImageNet, where each segment contains up to 15 examples per class.
The connection order of each batch is alternating, and the length of the training segments is randomly cropped. Regardless of the model type, the paper finds that training models in the delayed label setup is more challenging than in the synchronous label setup. The paper observes that in many configurations, the model gets stuck in a suboptimal behavior where it learns to improve zero-shot class average accuracy (evidently by learning an unused label for a new class that first appears in the output sequence), but fails to learn correctly at each step in the feedback. The most critical hyperparameter identified by the paper is a sufficiently large batch size.
Finally, the paper successfully trained the DeltaNet benchmark model and SRWM on this continuous adaptive task. Figure 4 shows how the testing accuracy of SRWM changes with the increase of inputs. In this testing setup, the model starts receiving a series of samples from the Omniglot dataset. At the 74th generation, the task changes; at this point, the model must classify images sampled from the Mini-ImageNet dataset. This change leads to a significant drop in the model’s accuracy, as the model does not know which class the new data points belong to, but it can effectively adapt and begin learning the second task. Table 2 compares DeltaNet and SRWM. Although they perform similarly on the first part of the Omniglot-based testing sequence, SRWM achieves higher accuracy on the second part sampled from Mini-ImageNet, demonstrating its rapid adaptability.
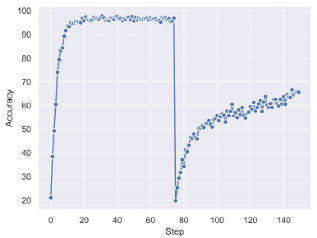
Figure 4 Testing accuracy (%) based on SRWM, as a function of the number of forwarding steps in a continuous multi-task adaptation setup (Section 4.2). Data points are provided to the model in a delayed label manner (Figure 3). Data points are sampled from Omniglot until the 74th step (accuracy drops), and then sampled from Mini-ImageNet.
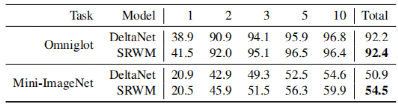
Table 2 Overall accuracy and instance-level accuracy (%) of continuous multi-task few-shot learning experiments (Section 4.2). For instance-level accuracy, the column k∈{1,2,3,5,10} indicates the correct prediction percentage of the k-th instance in each class. In the testing scenario, the model is first required to learn to predict Omniglot and Mini-ImageNet. The Conv4 backend is used for both models.
3. Multi-task Reinforcement Learning (RL)
Finally, the paper evaluates the proposed model in multi-task RL using procedurally generated ProcGen game environments. The corresponding setup is shown in Figure 5.
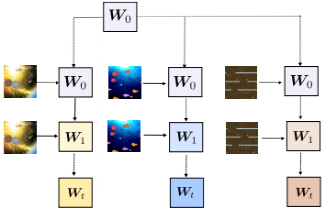
Figure 5 Illustration of multi-task RL. The initial weight matrix W0 is the same for all tasks and scenarios. The effective weight matrix is a function of the input stream for specific tasks/events.

Table 3 shows the aggregated normalized scores.
Compared to the benchmark model, the performance improvement of SRWM is particularly significant in the Bigfish and Starpilot environments. The paper conducts a separate study on these two cases. As shown in the table, the paper compares the aforementioned multi-task training with expert training conducted for 50M steps in a single environment.
In Starpilot, the paper observes that the self-correcting mechanism shows improvement even in single-task cases. The Bigfish case is more interesting: in the expert training case, models with and without self-correcting capabilities perform similarly. However, the self-correcting model achieves better scores in multi-task settings, where the performance of the benchmark model significantly declines. This validates the ability of SRWM to adapt to each environment in multi-task scenarios.
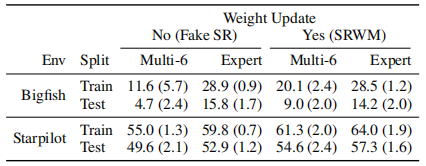
Table 4 Comparison of multi-task and expert training model performance. Raw scores obtained in the simple distribution of ProcGen.
As an ablation study, the paper trains and evaluates SRWM by resetting weight updates after each fixed time span (the length of the backpropagation span). Compared to models without self-correction (Table 3) that fail to leverage the SRWM mechanism, this model scores 28.5 (1.2) and 16.1 (2.2) on training and testing branches, respectively.
Across the three experiments, it is demonstrated that the proposed SRWM is practical and performs well in supervised few-shot learning, multi-task reinforcement learning, and procedurally generated game environments. It is hoped that the results of this paper will encourage further research on self-correcting neural networks.
https://arxiv.org/abs/2202.05780
Long press the QR code to follow more media matrices from CAAI

Official WeChat

Member Number

English Official WeChat