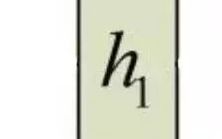
Click on the above “Visual Learning for Beginners“, select to add to favorites or pin.
Important content delivered in real-time
LSTM stands for Long Short-Term Memory, a type of recurrent neural network (RNN) that can handle sequential data and is widely used in fields such as natural language processing and speech recognition. Compared to the original RNN, LSTM solves the gradient vanishing problem and can handle long sequence data, making it the most popular RNN variant today.
Assuming our model inputs each word of a sentence sequentially, we need to classify the words. For example, consider two sentences: (1) “arrive Beijing on November 2nd,” where “Beijing” is the destination; (2) “leave Beijing on November 2nd,” where “Beijing” is the departure location. If we use a standard neural network, when the input is ‘Beijing’, the output will be fixed. However, we want ‘Beijing’ to be recognized as a destination when preceded by ‘arrive’ and as a departure location when preceded by ‘leave’. This is where LSTM comes in handy, as it can remember historical information. When it reads ‘Beijing’, LSTM knows whether it was preceded by ‘arrive’ or ‘leave’, allowing it to make different judgments based on historical context, leading to different outputs even with the same input.
A standard neuron has one input and one output, as shown in the figure:
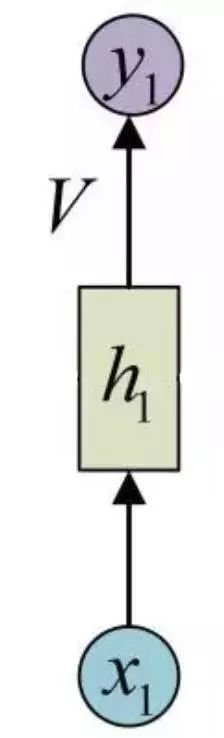
For the neuron h1, the input is x1, and the output is y1. LSTM replaces the standard neuron with an LSTM unit.
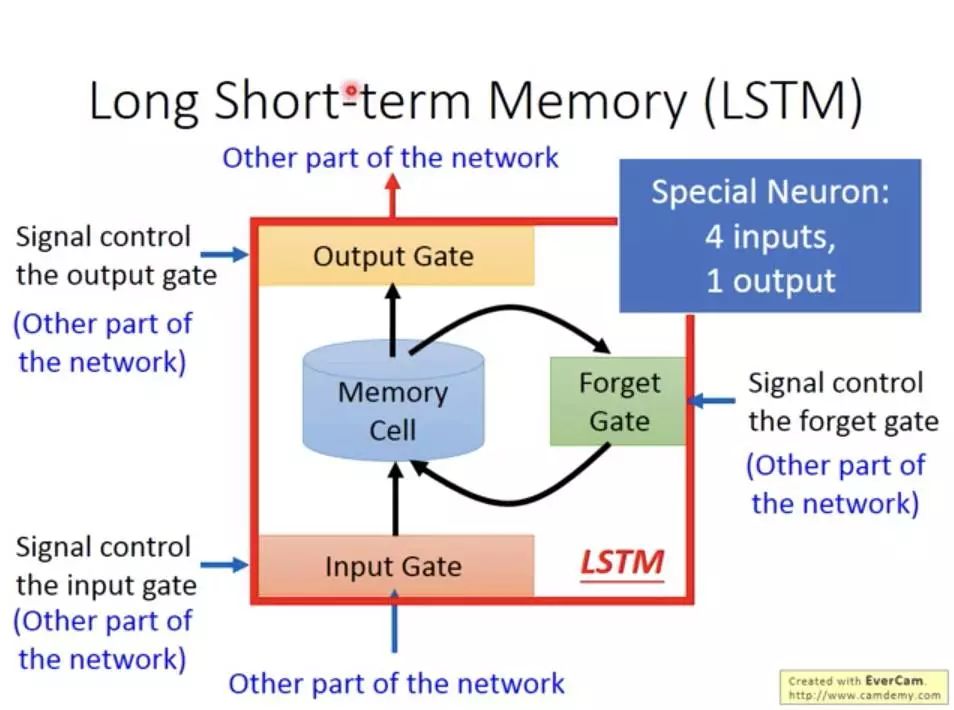
From the figure, we can see that LSTM has four inputs: input (model input), forget gate, input gate, and output gate. Therefore, compared to standard neural networks, LSTM has four times the number of parameters. These three gate signals are real numbers between 0 and 1, where 1 means fully open and 0 means closed. The forget gate determines whether the memory from the previous moment will be retained. When the forget gate is open, the previous memory is preserved; when it is closed, the previous memory is cleared. The input gate determines how much of the current input is retained, as not all input information at every moment is equally important. When the input is completely useless, the input gate is closed, meaning the current input information is discarded. The output gate determines how much of the current memory information will be output immediately; when the output gate is open, everything is output, and when it is closed, the current memory information is not output.
With the above knowledge, deriving the LSTM formulas is straightforward. In the figure, 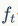 represents the forget gate,
represents the forget gate, 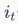 represents the input gate, and
represents the input gate, and  represents the output gate. C is the memory cell that stores memory information.
represents the output gate. C is the memory cell that stores memory information. 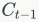 represents the memory information from the previous moment,
represents the memory information from the previous moment, 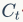 represents the current memory information, and h is the output of the LSTM unit.
represents the current memory information, and h is the output of the LSTM unit.
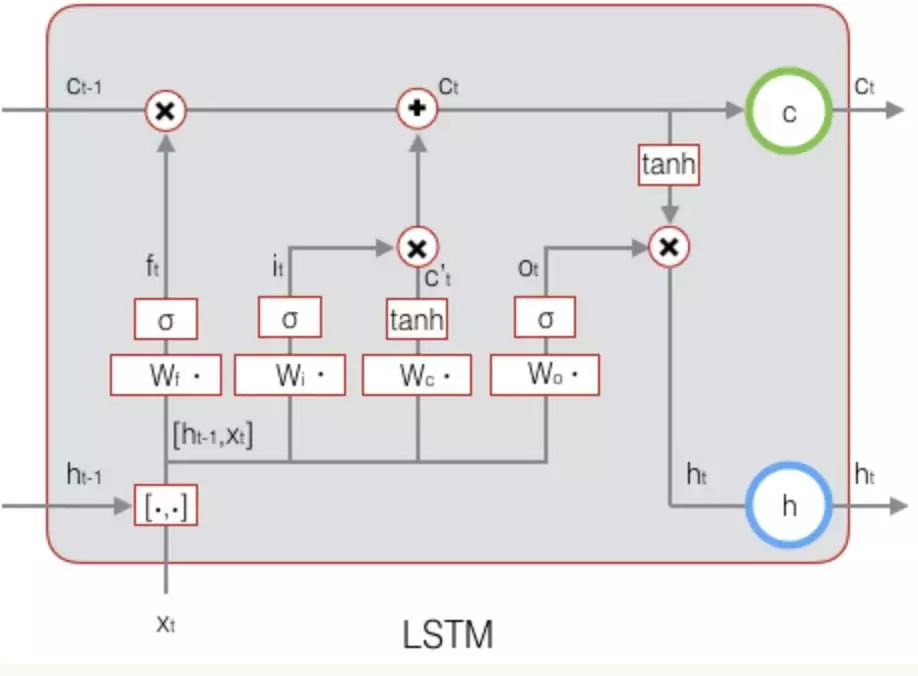
Forget gate calculation:
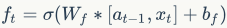
The 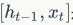 here means concatenating two vectors. The sigmoid function is mainly used to obtain a number between 0 and 1, which acts as the control signal for the forget gate.
here means concatenating two vectors. The sigmoid function is mainly used to obtain a number between 0 and 1, which acts as the control signal for the forget gate.
Input gate calculation:
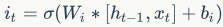
Current input:
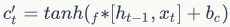
Updating current memory information:

From this formula, we can see that the previous memory information 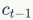 through the forget gate
through the forget gate 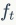 , and the current input
, and the current input 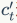 through the input gate
through the input gate 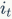 are combined to update the current memory information
are combined to update the current memory information 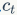 .
.
Input gate calculation:
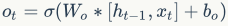
The output of LSTM is determined by the output gate and the current memory information:

Thus, we understand the forward computation process of LSTM. With the LSTM forward propagation algorithm, deriving the backpropagation algorithm is easy. Using gradient descent to iteratively update all parameters, the key point is to calculate the partial derivatives of all parameters based on the loss function, which will not be detailed here.
Although LSTM has a complex structure, it is not difficult to master once the various parts and their relationships are clarified. In practical use, algorithm libraries such as Keras and PyTorch can be utilized, but understanding the LSTM model structure is still necessary.
-
https://zybuluo.com/hanbingtao/note/581764
-
http://www.cnblogs.com/pinard/p/6519110.html
-
http://blog.echen.me/2017/05/30/exploring-lstms/
Group Chat
Welcome to join the public account reader group to communicate with peers. Currently, there are WeChat groups for SLAM, 3D vision, sensors, autonomous driving, computational photography, detection, segmentation, recognition, medical imaging, GAN, algorithm competitions, etc. (to be gradually subdivided in the future), please scan the WeChat number below to join the group, with the note: “Nickname + School/Company + Research Direction”, for example: “Zhang San + Shanghai Jiao Tong University + Visual SLAM”. Please do not send advertisements in the group, or you will be removed, thank you for your understanding~

