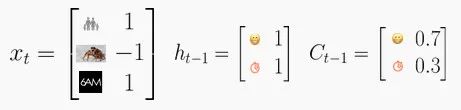Long Short-Term Memory networks (LSTM), as an improved version of Recurrent Neural Networks (RNN), not only solve the problem of RNNs being unable to handle long-distance dependencies but also address common issues in neural networks such as gradient explosion or gradient vanishing, making them very effective in processing sequential data.
What are the fundamental reasons behind their effectiveness? This article combines simple cases to help you understand five secrets about LSTMs and explains the key reasons why LSTMs are so effective.
Secret One: LSTM Was Invented Due to Severe Memory Leak in RNN
Previously, we introduced Recurrent Neural Networks (RNN) and demonstrated how to use them for sentiment analysis.
The problem with RNNs isremote memory. For example, they can predict the next word “sky” in the phrase “the clouds are in the…”, but they cannot predict the missing word in the following sentence: “She grew up in France. Now she has been in China for a few months only. She speaks fluent …”
As the gap increases, RNNs become unable to learninformation connections. In this example, recent information indicates that the next word might be the name of a language, but if we want to narrow down which language, we need to look back to the distant context for “France”. In natural language text, this issue can often arise with significant differences between the relevant information and where that information is needed. This difference is also very common in German.
Why do RNNs have huge problems withlong sequential texts? By design, RNNs take two inputs at each time step: an input vector (for example, a word in the input sentence) and a hidden state (for example, the memory representation of previous words).
The next time step of RNN uses the second input vector and the first hidden state to create the output for that time step. Therefore, to capture semantics in long sequences, we need to run RNN over multiple time steps, transforming the unfolded RNN into a very deep network.
Reading Reference:
https://towardsdatascience.com/recurrent-neural-networks-explained-ffb9f94c5e09
Long sequences are not the only troublemakers for RNNs. Like any very deep neural network, RNNs also suffer from gradient vanishing and explosion problems, requiring a lot of time for training. Many techniques have been proposed to alleviate this issue, but none have completely eliminated it. These techniques include:
-
Carefully initializing parameters
-
Using non-saturating activation functions like ReLU
-
Applying batch normalization, gradient clipping, dropout networks, etc.
-
Using truncated backpropagation through time
These methods still have their limitations. Moreover, in addition to long training times, long-running RNNs face another problem: the memory of the first input gradually fades.
After a while, there is almost no trace of the first input in the RNN’s state memory. For example, if we want to perform sentiment analysis on a long review that starts with “I love this product” but lists many factors that could make the product better, the RNN will gradually forget the positive sentiment conveyed in the first comment and will completely misinterpret the review as negative.
To solve these problems with RNNs, researchers have introduced various types of cells with long-term memory in their studies. In fact, most work that no longer uses basic RNNs is done through what are known as Long Short-Term Memory networks (LSTM). LSTMs were invented by S. Hochreiter and J. Schmidhuber.
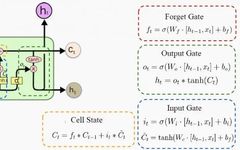
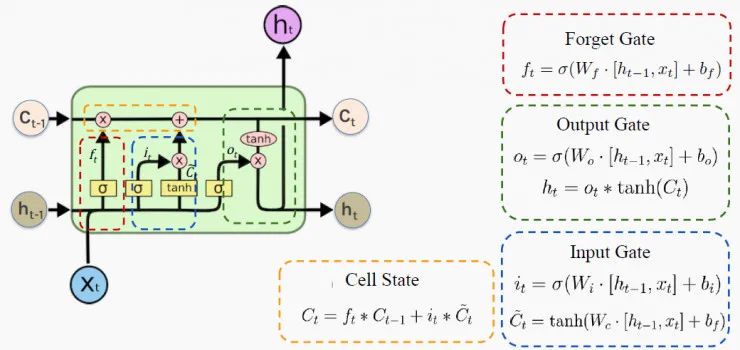
Secret Two: A Key Idea of LSTM is the “Gate”
Each LSTM cell controls what to remember, what to forget, and how to use gates to update the memory. In this way, LSTM networks solve the problems of gradient explosion or vanishing, as well as all other issues mentioned earlier!
The architecture of an LSTM cell is shown in the figure below:
Source: Lecture notes from Professor P. Protopapas at Harvard University (the same applies below, no further annotations)
h is the hidden state, representing short-term memory; C is the cell state, representing long-term memory; x represents input.
Gates can only perform a few matrix transformations, and activating the sigmoid and tanh functions can magically solve all RNN problems.
In the next section, we will delve into this process by observing how these cells forget, remember, and update their memory.
Let’s set up an interesting scenario to explore this diagram. Suppose you are the boss, and your employee asks for a raise. Would you agree? It depends on several factors, such as your mood at the time.
Below, we will view your brain as an LSTM cell, and of course, we do not mean to offend your intelligent brain.
Your long-term state C will affect your decision. On average, you are in a good mood 70% of the time, and you have 30% of your budget left. Therefore, your cell state is C=[0.7, 0.3].
Recently, everything has been going well for you, boosting your good mood to 100%, and you have a 100% chance of reserving an operational budget. This turns your hidden state into h=[1,1].
Today, three things happened: your child did well on a school exam, although your boss gave you a poor evaluation, you found that you still had enough time to finish your work. Therefore, today’s input is x=[1, -1, 1].
Based on this assessment, would you give your employee a raise?
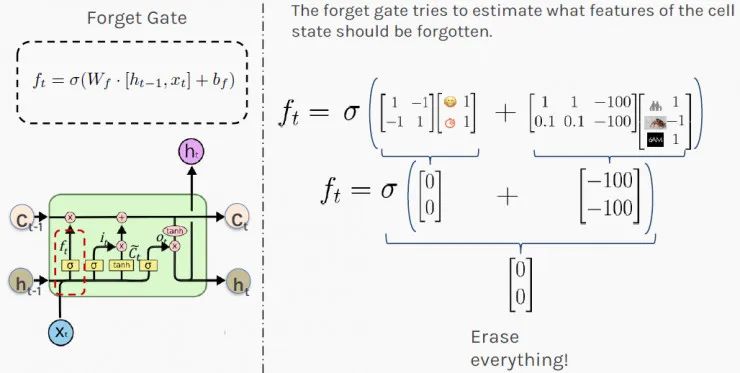
Secret Three: LSTM Forgets Using the “Forget Gate”
In the above scenario, your first step might be to figure out what happened today (input x) and what happened recently (hidden state h), both of which will affect your long-term judgment (cell state C). The “forget gate” controls the amount of memory stored from the past.
Upon receiving the request for a raise, your “forget gate” will run the following calculation f_t, the value of which will ultimately affect your long-term memory.
The weights shown in the diagram below are randomly chosen for illustrative purposes. Their values are usually computed during network training. The result [0,0] indicates to erase (completely forget) your long-term memory and not let it affect your decision today.
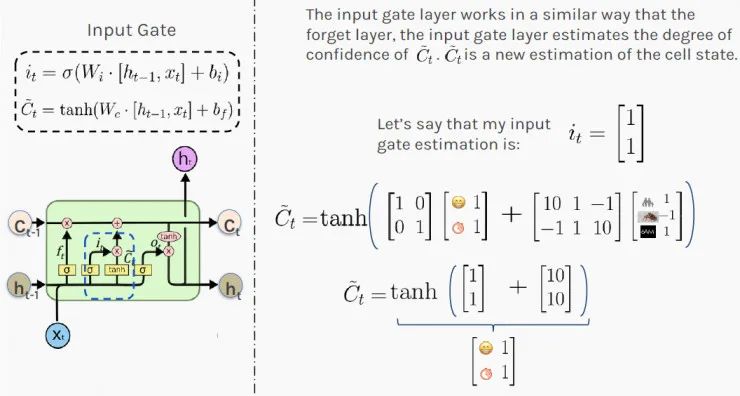
Secret Four: LSTM Remembers Using the “Input Gate”
Next, you need to decide which information from recent events (hidden state h) and today’s events (input x) should be recorded in your long-term judgment (cell state C). LSTM decides what to remember using the “input gate”.
First, you calculate the value of the input gate i_t, which falls between 0 and 1 due to the activation of the sigmoid function; next, you scale the input using the tanh activation function between -1 and 1; finally, you estimate the new cell state by adding these two results.
The result [1,1] indicates that based on recent and current information, you are 100% in a good state, and there is a high likelihood of giving the employee a raise. This is promising for your employee.
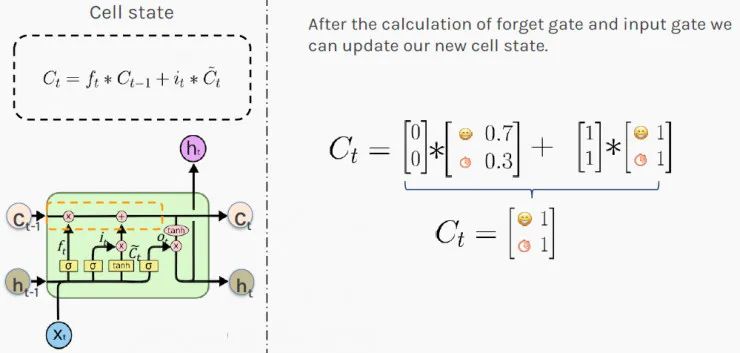
Secret Five: LSTM Uses “Cell State” to Keep Long-Term Memory
Now that you know how recent events affect your state, it’s time to update your long-term judgment based on the new theory.
When new values appear, LSTM again decides how to update its memory using gates. The new values gated will be added to the current memory. This addition operation resolves the gradient explosion or vanishing issues of simple RNNs.
LSTM calculates the new state by addition rather than multiplication. The result C_t is stored as the new long-term judgment (cell state) of the situation at hand.
The value [1,1] indicates that you generally maintain a good mood 100% of the time and have a 100% chance of having money! You are a flawless boss!
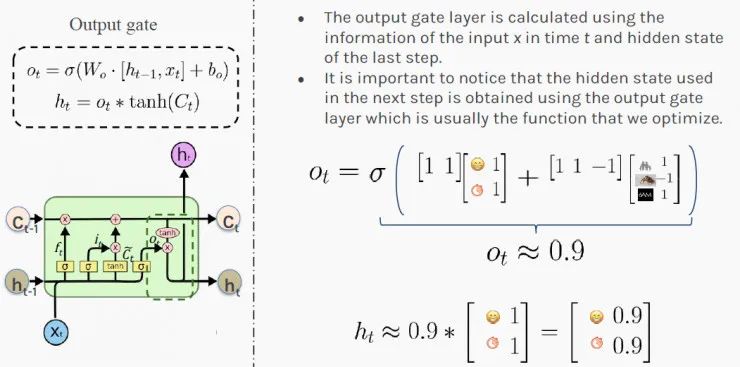
Based on this information, you can update your short-term judgment of the situation: h_t (next hidden state). The value [0.9, 0.9] indicates that you have a 90% chance of increasing the employee’s salary in the next step! Congratulations to him!
A variant of the LSTM cell is calledGated Recurrent Unit, abbreviated as GRU. GRU was proposed in a paper by Kyunghyun Cho et al. in 2014.
GRU is a simplified version of the LSTM cell, slightly faster than LSTM, and its performance seems to be comparable to LSTM, which is why it is becoming increasingly popular.
As shown above, these two state vectors are merged into one vector. A single gate controller controls both the “forget gate” and the “input gate”. If the gate controller outputs 1, the input gate opens, and the forget gate closes. If it outputs 0, the opposite is true. In other words, whenever memory needs to be stored, its storage location is first deleted.
In the diagram above, there is no output gate, and the full state vector is output at each step. However, a new gate controller has been added, which controls which part of the previous state will be presented to the main layer.
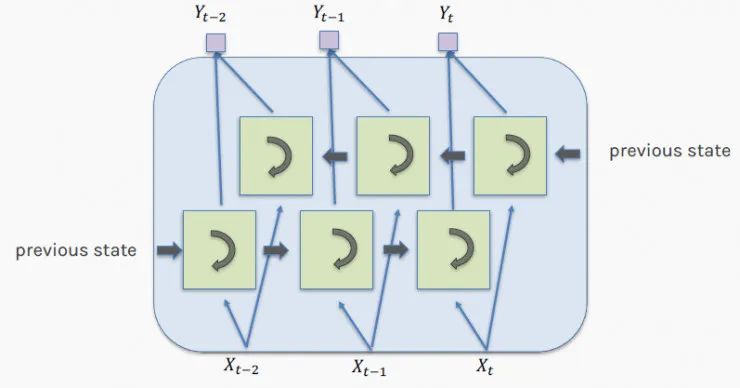
By aligning multiple LSTM cells, we can process input of sequential data, such as a sentence with four words shown in the diagram below.
LSTM units are typically arranged hierarchically, so the output of each unit serves as the input for other units. In this case, we have two layers, each with four cells. This way, the network becomes richer and captures more dependencies.
RNNs, LSTMs, and GRUs are used to analyze numerical sequences. Sometimes, it also makes sense to analyze sequences in reverse order.
For example, in the sentence “The boss told the employee that he needs to work harder,” even though “he” appears at the beginning, it refers to the employee mentioned at the end of the sentence.
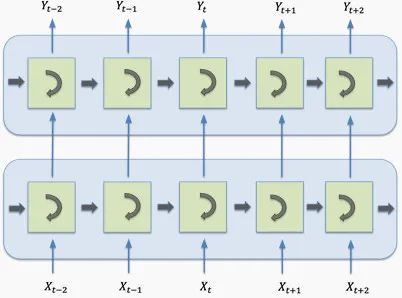
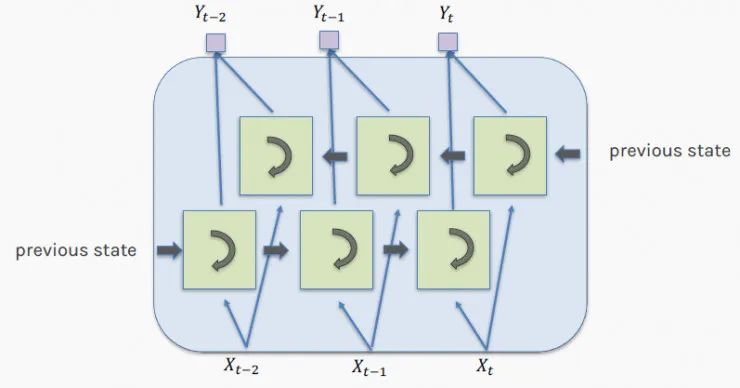
Therefore, the order of analyzing the sequence needs to be reversed or combined with forward and backward sequences. The diagram below describes this bidirectional architecture:
The diagram below further illustrates the bidirectional LSTM. The network at the bottom receives the sequence in its original order, while the top network receives the same input in reverse order. These two networks do not necessarily have to be identical. Importantly, their outputs are merged for the final prediction.
Want to Know More Secrets?
As we just mentioned, LSTM cells can learn to identify important inputs (the role of the input gate), store that input in the long-term state, learn to retain it when needed (the role of the forget gate), and learn to extract it when necessary.
LSTMs have transformed the paradigm of machine learning, now providing services to billions of users through some of the world’s most valuable publicly traded companies like Google, Amazon, and Facebook.
Since mid-2015, LSTMs have greatly improved voice recognition on over 4 billion Android phones.
Since November 2016, LSTMs have been applied in Google Translate, greatly enhancing machine translation.
Facebook performs over 4 billion LSTM-based translations daily.
Since 2016, nearly 2 billion iPhones have been equipped with LSTM-based Siri.
Amazon’s Alexa also answers questions based on LSTM.
If you want to know more about LSTMs and GRUs, you can read this animated article by Michael Nguyen:
https://towardsdatascience.com/illustrated-guide-to-lstms-and-gru-s-a-step-by-step-explanation-44e9eb85bf21
For those who enjoy building LSTM models from scratch, this article may be useful:
https://towardsdatascience.com/illustrated-guide-to-lstms-and-gru-s-a-step-by-step-explanation-44e9eb85bf21
Next, I will provide a method for implementing LSTM networks in practice using Python.
1. Sentiment Analysis: A Benchmark
https://towardsdatascience.com/sentiment-analysis-a-benchmark-903279cab44a
Attention-based sequence-to-sequence models and Transformers have surpassed LSTMs, achieving remarkable results in Google’s machine translation and OpenAI’s text generation recently.
2. Practical Guide to Attention Mechanism for NLU Tasks
https://towardsdatascience.com/practical-guide-to-attention-mechanism-for-nlu-tasks-ccc47be8d500
Using BERT, FastText, TextCNN, Transformer, Se2seq, etc., comprehensive text classification can be implemented, which can be found in the GitHub repository:
https://github.com/brightmart/text_classification
Or you can check out this tutorial on BERT:
https://towardsdatascience.com/bert-for-dummies-step-by-step-tutorial-fb90890ffe03