


In cognitive science, human brain thinking is divided into three basic modes: logical thinking, intuitive thinking, and inspirational thinking.
The neural network uses its algorithm characteristics to simulate the second mode of human brain thinking. It is a nonlinear dynamic system characterized by distributed information storage and parallel collaborative processing. Although the structure of a single neuron is simple and its function is limited, the behavior that a network system composed of a large number of neurons can achieve is indeed rich and colorful. In simple terms, it uses this algorithm to simulate human brain reasoning and verification.
Let’s briefly analyze the working process of the human brain. I carefully found a picture of the brain online that looks somewhat comfortable.
Well, it looks somewhat interesting, at least it looks more comfortable. Back in the late 19th century, a big shot named Waldege created neuron science. He said that the complex human nervous system is composed of numerous neurons, stating that the cerebral cortex includes more than 10 billion neurons, with tens of thousands per cubic millimeter. Wow… I think of typical big data. They are interconnected to form a neural network, receiving various information from the outside world through sensory organs and nerves (which we call training in neural network algorithms), transmitting it to the central nervous system, then analyzing and synthesizing the information, and finally sending control information through motor neurons (for example, when I type in my blog), thus achieving the connection between the body and the external environment.
A neuron, like other cells, includes a nucleus, cytoplasm, and cell membrane, but it also has some special features, such as many protrusions, just like the picture above, which are divided into three parts: cell body, axon, and dendrite. The cell body contains the nucleus, and the function of the protrusions is to transmit information. The dendrite serves as the input for incoming information, while the axon serves as the output end, but there is only one.
This means that a neuron has N inputs (dendrites), processes the information (in the nucleus), and has only one output (axon). Neurons connect through the dendrites of one neuron and the axon of another, simultaneously transmitting and processing information. Wow… so complicated….
Let’s take a look at the principle algorithm formula of the neural network.
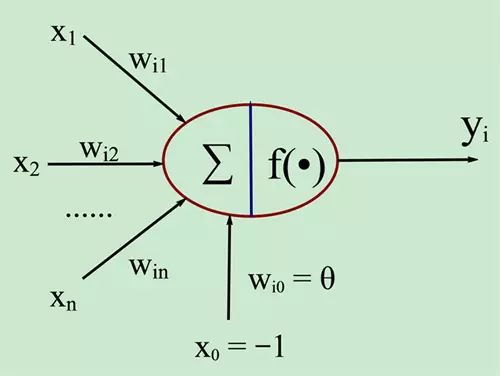
The round part in the middle is the nucleus, X1, X2, X3…Xn are the dendrites, and Yi is the axon…. Isn’t that somewhat interesting? Well… our external information is input through the dendrites of the neurons, then processed in the nucleus, and output through Yi, then to other neurons…
However, this algorithm has its own characteristics, just like human brain neurons. Every time external information is received, it continuously stimulates and adjusts itself based on the different information. For example: through constant training, athletes learn to run, and through constant practice, they learn to ride a bicycle…. The essence of these human behaviors is formed through the continuous training of hundreds of billions of brain neurons. The accumulation of these behaviors leads to the correct result orientation.
Similarly, this algorithm also continuously trains through elements X1, X2, X3…Xn, adjusting its parameters to adapt, forming a correct result orientation with the increase in training times. At this point, we can use its self-adaptive process to generate correct results, and through continuous training, it acquires learning capabilities. Of course, this algorithm only reflects certain basic characteristics of the human brain, but does not realistically describe biological systems; it is merely a simple imitation, simplification, and abstraction.
This algorithm, unlike digital computers, does not execute calculations step by step according to a program; instead, it can adapt to the environment, summarize rules, perform certain calculations, recognize or control processes, which is the origin of robots… the foundation of artificial intelligence.
Due to the vast design space of neural network algorithms, we will only analyze the principles of Microsoft’s neural network algorithm here. In Microsoft’s neural network algorithm, we can simplify it to the image below:
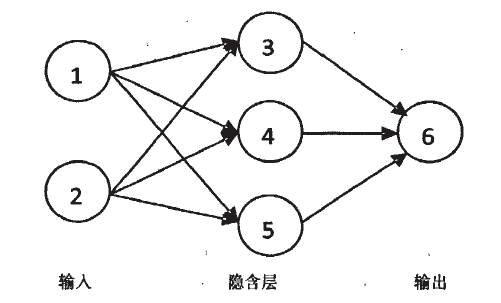
Microsoft’s neural network uses a “multilayer perceptron” network consisting of up to three layers of neurons: input layer, optional hidden layer, and output layer.
Input Layer:Input neurons define all input attribute values and probabilities of the data mining model.
Hidden Layer:Hidden neurons receive inputs from input neurons and provide outputs to output neurons. The hidden layer is where various input probabilities are assigned weights. Weights indicate the relevance or importance of a particular input to the hidden neuron. The greater the weight assigned to the input, the more important the input value. This process can be described as a learning process. Weights can be negative, indicating that the input suppresses rather than promotes a particular outcome.
Output Layer:Output neurons represent the predictable attribute values of the data mining model.
Data flows from input through the intermediate hidden layer to output. The entire process is a forward propagation of data and information, with the data value at the nodes in the back layer coming from the front nodes it is connected to, then the data is weighted and undergoes certain function calculations to obtain new values, continuing to propagate to the next layer of nodes. This process is called forward propagation.
When a node’s output is incorrect, meaning it differs from the expected outcome, the neural network must automatically “learn”. The subsequent layer nodes adjust their “trust” level towards the previous layer nodes (the only thing that changes is the connection weights) by reducing the weights as a form of punishment. If the node output is rough, we need to check which input nodes influenced this error, reduce the weights of the connections leading to the erroneous nodes, punish these nodes while increasing the weights of the nodes that made correct suggestions. For those punished nodes, the same method is applied to punish their preceding nodes until reaching the input nodes. This process is called feedback.
Our learning process is to repeat the above-described flow, obtaining input values through forward propagation and learning through feedback. When all data in the training set has been processed once, it is called a training cycle. After training, the neural network model is obtained, which contains the rules of the corresponding values in the training set and the changes influenced by the predicted values.
In each neuron in the hidden layer, there are complex functions, all of which are nonlinear functions, and similar to the basic transmission characteristics of biological neural networks. These functions are called activation functions, which means that slight changes in input values can sometimes produce large changes in output.
Of course, the functions used in Microsoft’s neural network algorithm are as follows:
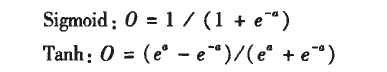
Where a is the input value, and O is the output value.
For processing backpropagation, calculating errors, and updating weights, the error function used by the output layer is cross-entropy.
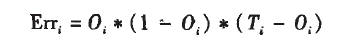
In the above formula, Oi is the output of output neuron i, and Ti is the actual value of that output neuron based on the training sample.
The error of the hidden neuron is calculated based on the errors of the next layer’s neurons and their relevant weights. The formula is:
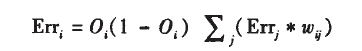
Where Oi is the output of output neuron i, and this unit has j outputs to the next layer. Erri is the error of neuron i, and Wij is the weight between these two neurons.
Once the error for each neuron is calculated, the next step is to adjust the weights in the network using the following method.
Where l is a number in the range of 0-1, called the learning function.
In fact, the activation functions applied in the above functions are quite simple. Those interested can conduct detailed research and formula derivation; we are only providing a brief analysis and listing algorithm characteristics.
Through the above principle analysis, we understand that the neural network algorithm is divided into three layers: input layer, hidden layer, and output layer, where the hidden layer is optional. In Microsoft’s neural network algorithm, if it does not go through the hidden layer, the input will be transmitted directly from the nodes in the input layer to the nodes in the output layer.
Input Layer Characteristics: If the input layer has discrete values, the input neurons usually represent a single state of the input attribute. If the input data contains null values, the missing values are also included. Discrete input attribute values with more than two states will generate an input neuron. If there are null values, an additional input neuron will be automatically generated to handle null values. A continuous input attribute will generate two input neurons: one for the missing state and one for the continuous attribute itself. Input neurons can provide input to one or more neurons.
Hidden Layer Characteristics: Hidden neurons receive input from input neurons and provide output to output neurons. Activation functions are available for use to change the threshold.
Output Layer Characteristics: Output neurons usually represent a single predicted state of the predictable attributes for discrete input attributes, including missing null values.
If the mining model includes one or more attributes used solely for prediction, the algorithm will create a single network representing all these attributes. If the mining model includes one or more attributes used for both input and prediction, the algorithm will build a network for each attribute.
For input attributes and predictable attributes with discrete values, each input or output neuron represents a single state. For input attributes and predictable attributes with continuous values, each input or output neuron represents the range and distribution of that attribute value.
The algorithm provider maintains the actual known values of each case in the data set and compares them with the network’s predictions through a process called “batch learning” to iteratively compute the entire network and adjust the input weights. After processing the entire case set, the algorithm will check the predicted values and actual values for each neuron. The algorithm will calculate the error degree (if any) and adjust the weights associated with the neural input, and through a “backpropagation” process, return from the output neurons to the output neurons. Then, the algorithm repeats this process for the entire case set. After all these layers of sedimentation, our algorithm grows from a clueless “infant” to an “adult”, and this result is the tool we use for exploration and prediction.
Neural network research covers a wide range, beyond the scope of this article, and reflects the characteristics of interdisciplinary technology fields. Research work focuses on the following areas:
(1) Biological Prototype Research. Researching the biological prototype structure and functional mechanisms of neural cells, neural networks, and nervous systems from the perspectives of physiology, psychology, brain science, pathology, and other biological sciences.
(2) Establishing Theoretical Models. Based on biological prototype research, establishing theoretical models of neurons and neural networks, including conceptual models, knowledge models, physicochemical models, mathematical models, etc.
(3) Network Model and Algorithm Research. Constructing specific neural network models based on theoretical model research to achieve computer simulation or prepare hardware, including research on network learning algorithms. This work is also referred to as technical model research.
(4) Artificial Neural Network Application Systems. Based on the network model and algorithm research, utilizing artificial neural networks to form actual application systems, such as completing certain functions of signal processing or pattern recognition, constructing expert systems, making robots, etc.
Wow…. this is beyond the scope of my coding level. If anyone is interested in the above, you can continue to delve deeper; just playing around can lead to promotions and wealth, and a worry-free life……
Returning to the main topic, let’s look at the applications of our Microsoft Neural Network Analysis Algorithm in the field of data mining:
-
Marketing and promotion analysis, such as evaluating the success of direct mail promotions or a radio advertising campaign.
-
Predicting stock fluctuations, exchange rate changes, or other frequently changing financial information based on historical data.
-
Analyzing manufacturing and industrial processes.
-
Text mining.
-
Any predictive model analyzing complex relationships between multiple inputs and relatively few outputs.
In fact, its application scenarios are the most extensive. For example, when we receive a pile of data and have no clue about a target, Microsoft’s neural network analysis algorithm is the best application scenario as it utilizes the characteristics of the “human brain” to discover useful information in the vast sea of data. For instance, when the boss throws the company’s database at you… asking you to analyze why the company isn’t making money… or what reasons lead to the lack of profitability… this is when the algorithm should come into play.
However, it has been found that this algorithm is particularly popular in “text mining” and is fully utilized in Microsoft, such as the current: Microsoft Xiaoice, various platforms’ voice recognition, and even a proud company like Apple is slowly succumbing to the charm of this algorithm.