
Selected from Google Research
Authors: Quoc V. Le, Mike Schuster
Translated by: Machine Heart
Contributors: Wu Pan
2016 was a year of continuous breakthroughs in artificial intelligence. This year, we experienced breakthroughs in speech recognition, the flourishing of style transfer, advancements in neural machine translation, and more. Machine Heart closely followed each announcement. As the year comes to a close, Machine Heart will review the popular articles we published over the past year. Traffic does not represent article quality, but each selected article reflects the interests of Machine Heart readers and our own values. It has been an exciting year, and we witness and reflect together.
The first article in this series of reviews focuses on the breakthrough of Google’s Neural Machine Translation, which garnered over 60,000 views at the time of statistics.
Ten years ago, we launched Google Translate, and the core algorithm behind this service was based on Phrase-Based Machine Translation (PBMT). Since then, the rapid development of machine intelligence has significantly improved our speech and image recognition capabilities, but improving machine translation remains a challenging goal.
Today, we announce the release of the Google Neural Machine Translation (GNMT) system, which utilizes the most advanced training techniques available, achieving the greatest improvement in machine translation quality to date. For detailed research results, please refer to our paper titled “Google’s Neural Machine Translation System: Bridging the Gap between Human and Machine Translation” (see end of article) [1].
A few years ago, we began using Recurrent Neural Networks (RNN) to directly learn the mapping from an input sequence (such as a sentence in one language) to an output sequence (the same sentence in another language) [2]. In contrast, PBMT breaks down the input sentence into words and phrases and translates them largely independently, while Neural Machine Translation (NMT) treats the entire input sentence as the basic unit of translation. The advantage of this approach is that it requires less engineering design compared to previous phrase-based translation systems. When first proposed, NMT achieved accuracy comparable to phrase-based translation systems on medium-sized public benchmark datasets.
Since then, researchers have proposed many techniques to improve NMT, including simulating external alignment models to handle rare words [3], using attention to align input and output words [4], and breaking words down into smaller units to tackle rare words [5,6]. Despite these advancements, NMT’s speed and accuracy have not yet met the requirements to become a production system like Google Translate. Our new paper [1] describes how we overcame many challenges to make NMT work on very large datasets and how we built a system that is now fast and accurate enough to provide better translations for Google’s users and services.
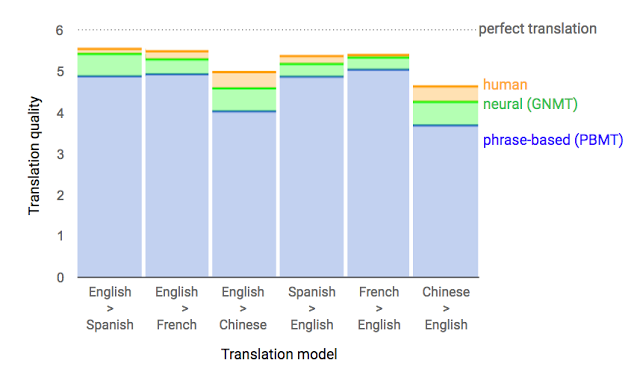
From comparative evaluation data, where human evaluators compared the translation quality of given source sentences. The score ranges from 0 to 6, where 0 means “completely meaningless translation” and 6 means “perfect translation”.
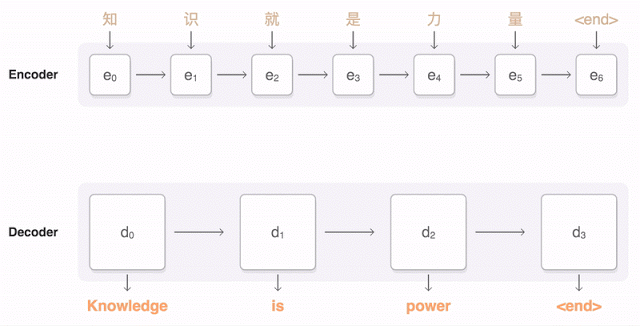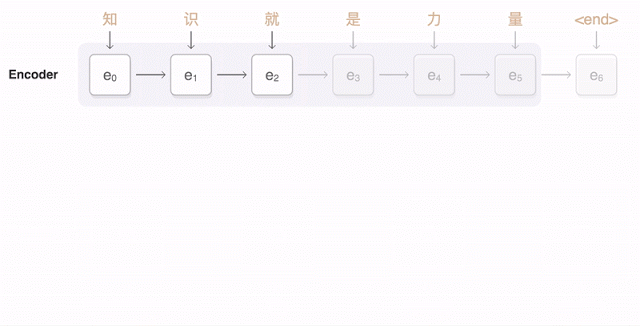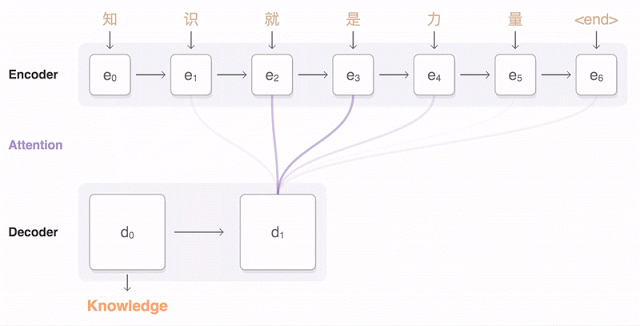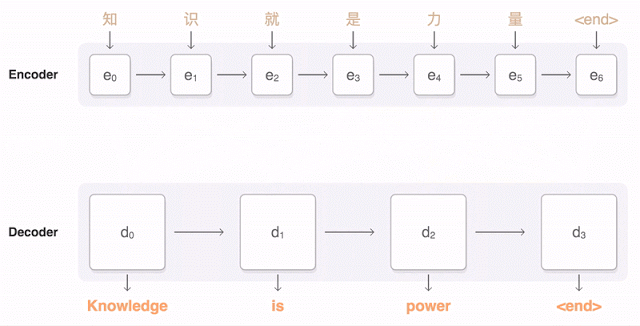
The following visualization illustrates how GNMT translates a Chinese sentence into an English sentence. First, the network encodes the words of the Chinese sentence into a list of vectors, where each vector represents the meaning of all the words read so far (“Encoder”). Once the entire sentence is read, the decoder starts working—generating one word of the English sentence at a time (“Decoder”). To generate the correct word at each step, the decoder pays close attention to the weight distribution of the encoded Chinese vectors most relevant to generating the English word (“Attention”), with the transparency of the blue links indicating the decoder’s attention level to an encoded word.
Using human-evaluated side-by-side comparisons as a standard, the translations produced by the GNMT system achieved significant improvements compared to previous phrase-based production systems. With the help of bilingual human evaluators, we measured samples from Wikipedia and news sites and found that GNMT reduced translation errors by over 55%-85% across multiple major language pairs.

Our system produced a translation case, with the input sentence sampled from a news site. This address (https://drive.google.com/file/d/0B4-Ig7UAZe3BSUYweVo3eVhNY3c/view?usp=sharing) contains more random samples of input sentence translations from news sites and books.
Today, in addition to releasing this research paper, we also announce that GNMT has been deployed in production for a very challenging language pair (Chinese-English) translation. Now, the Chinese-English translation in both the mobile and web versions of Google Translate is 100% utilizing GNMT machine translation—approximately 18 million translations daily. The production deployment of GNMT uses our open-source machine learning toolkit TensorFlow and our Tensor Processing Units (TPU), which provide sufficient computational power to deploy these powerful GNMT models while meeting the strict latency requirements of the Google Translate product. Chinese to English translation is one of over 10,000 language pairs supported by Google Translate, and in the coming months, we will continue to expand our GNMT to many more language pairs.
Machine translation is far from fully solved. GNMT still makes some significant errors that human translators would never make, such as omitting words and incorrectly translating proper nouns or rare terms, and translating sentences individually without considering the context of their paragraphs or pages. We have more work to do to provide better service for our users. However, GNMT represents a major milestone. We hope to celebrate it with many researchers and engineers who have contributed to this research direction over the past few years—whether from Google or the broader community.
The Google Brain team and the Google Translate team both participated in this project. Nikhil Thorat and Big Picture also assisted with the visualization work for this project.
-
Paper: Google’s Neural Machine Translation System: Bridging the Gap between Human and Machine Translation

Abstract: Neural Machine Translation (NMT) is an end-to-end learning method for automatic translation that aims to overcome the shortcomings of traditional phrase-based translation systems. Unfortunately, it is well known that the training and inference computational costs of NMT systems are very high. Additionally, most NMT systems struggle with rare words. These issues hinder the application of NMT in practical deployment and services, as both accuracy and speed are critical in real-world applications. In this result, we propose GNMT—Google’s Neural Machine Translation system to attempt to address many of these issues. Our model consists of a deep LSTM network with 8 encoders and 8 decoders, which employs attention and residual connections. To enhance parallelism and reduce training time, our attention mechanism connects the lower layers of the decoder to the top layers of the encoder. To accelerate the final translation speed, we use low-precision computation during inference. To improve handling of rare words, we decompose words into a finite set of common sub-word units (components of words) that serve as both input and output. This approach balances the flexibility of “character”-delimited models and the efficiency of “word”-delimited models, enabling natural handling of rare word translations and ultimately improving the overall accuracy of the system. Our beam search technique utilizes a length normalization process and a coverage penalty that encourages the generation of output sentences likely to cover all words in the source sentence. On the WMT’ 14 English-French and English-German benchmarks, GNMT achieves results comparable to the current best results. Through human comparative evaluation on a separate simple sentence set, it reduced translation errors by an average of 60% compared to Google’s already production-deployed phrase-based system.
References:
[1] Google’s Neural Machine Translation System: Bridging the Gap between Human and Machine Translation, Yonghui Wu, Mike Schuster, Zhifeng Chen, Quoc V. Le, Mohammad Norouzi, Wolfgang Macherey, Maxim Krikun, Yuan Cao, Qin Gao, Klaus Macherey, Jeff Klingner, Apurva Shah, Melvin Johnson, Xiaobing Liu, Łukasz Kaiser, Stephan Gouws, Yoshikiyo Kato, Taku Kudo, Hideto Kazawa, Keith Stevens, George Kurian, Nishant Patil, Wei Wang, Cliff Young, Jason Smith, Jason Riesa, Alex Rudnick, Oriol Vinyals, Greg Corrado, Macduff Hughes, Jeffrey Dean. Technical Report, 2016.
[2] Sequence to Sequence Learning with Neural Networks, Ilya Sutskever, Oriol Vinyals, Quoc V. Le. Advances in Neural Information Processing Systems, 2014.
[3] Addressing the rare word problem in neural machine translation, Minh-Thang Luong, Ilya Sutskever, Quoc V. Le, Oriol Vinyals, and Wojciech Zaremba. Proceedings of the 53th Annual Meeting of the Association for Computational Linguistics, 2015.
[4] Neural Machine Translation by Jointly Learning to Align and Translate, Dzmitry Bahdanau, Kyunghyun Cho, Yoshua Bengio. International Conference on Learning Representations, 2015.
[5] Japanese and Korean voice search, Mike Schuster, and Kaisuke Nakajima. IEEE International Conference on Acoustics, Speech and Signal Processing, 2012.
[6] Neural Machine Translation of Rare Words with Subword Units, Rico Sennrich, Barry Haddow, Alexandra Birch. Proceedings of the 54th Annual Meeting of the Association for Computational Linguistics, 2016.
Further Reading:
Interview | After the Release of Google’s Neural Network Translation System, We Talked with Engineers from Google Brain
Deep Dive | Layer by Layer Analysis: What is the Neural Network Architecture Behind Google’s Machine Translation Breakthrough?
Major Update | Google’s Neural Machine Translation Breakthrough: Achieving High-Quality Multilingual Translation and Zero-Shot Translation (with Paper)
© This article is a translation by Machine Heart, please contact this public account for authorization to reproduce..
✄————————————————
Join Machine Heart (Full-time Reporter/Intern): [email protected]
Submissions or Coverage Requests: [email protected]
Advertising & Business Cooperation: [email protected]