
Yunzhong from Aofeisi Quantum Bit Editor | Public Account QbitAI
NLP has been very popular in recent years and is developing particularly fast. Technologies such as BERT, GPT-3, Graph Neural Networks, and Knowledge Graphs have emerged.
We are in an era of information explosion, facing a flood of online resources and papers every day. Often, the problem we face is not a lack of resources, but rather finding the right resources and learning efficiently. However, many times you will find that you spend a lot of time on scattered content, only to discover that the efficiency is extremely low, wasting a lot of precious time. To meet everyone’s learning needs, Greedy Technology has launched the “Natural Language Processing Lifelong Upgraded Version”.
The course covers all necessary technologies from classic machine learning, text processing techniques, sequence models, deep learning, pre-trained models, knowledge graphs, and graph neural networks.
Key Point: The course will be continuously updated. For example, if a new interesting paper appears on arxiv, a technical explanation and practical application will be provided within a month. I believe this course will be your lifelong companion in the NLP field.
01 Course Outline
Part One: Basics of Machine Learning
Chapter 1: Overview of Natural Language Processing
-
The current situation and prospects of natural language processing
-
Applications of natural language processing
-
Classic tasks of natural language processing
-
Time complexity, space complexity
-
Dynamic programming
-
Greedy algorithms
-
Various sorting algorithms
-
Logistic regression
-
Maximum likelihood estimation
-
Optimization and gradient descent
-
Stochastic gradient descent
-
Understanding overfitting, preventing overfitting
-
L1 and L2 regularization
-
Cross-validation
-
Regularization and MAP estimation
Part Two: Text Processing
-
Various tokenization algorithms
-
Word normalization
-
Spelling correction, stop words
-
One-hot encoding representation
-
tf-idf and similarity
-
Distributed representation and word vectors
-
Word vector visualization and evaluation
-
Advantages and disadvantages of one-hot encoding
-
Advantages of distributed representation
-
Static word vectors and dynamic word vectors
-
SkipGram and CBOW
-
Detailed explanation of SkipGram
-
Negative Sampling
-
The role of language models
-
Markov assumption
-
UniGram, BiGram, NGram models
-
Evaluation of language models
-
Smoothing techniques for language models
Part Three: Sequence Models
-
Applications of HMM
-
Inference of HMM
-
Viterbi algorithm
-
Forward and backward algorithms
-
Detailed explanation of HMM parameter estimation
-
Directed and undirected graphs
-
Generative models and discriminative models
-
From HMM and MEMM
-
Label bias in MEMM
-
Introduction to Log-Linear models
-
From Log-Linear to LinearCRF
-
Parameter estimation of LinearCRF
Part Four: Deep Learning and Pre-training
-
Understanding neural networks
-
Various common activation functions
-
Backpropagation algorithm
-
Comparison of shallow and deep models
-
Hierarchical representation in deep learning
-
Overfitting in deep learning
-
From HMM to RNN models
-
Gradient issues in RNN
-
Gradient vanishing and LSTM
-
LSTM to GRU
-
Bidirectional LSTM
-
Bidirectional deep LSTM
-
Seq2Seq models
-
Greedy Decoding
-
Beam Search
-
Problems with long dependencies
-
Implementation of attention mechanisms
-
Contextual word vector technology
-
Hierarchical representation in image recognition
-
Hierarchical representation in text domains
-
ELMo model
-
Pre-training and testing of ELMo
-
Advantages and disadvantages of ELMo
-
Disadvantages of LSTM models
-
Overview of Transformers
-
Understanding self-attention mechanisms
-
Encoding positional information
-
Understanding the difference between Encoder and Decoder
-
Understanding the training and prediction of Transformers
-
Disadvantages of Transformers
-
Introduction to self-encoding
-
Transformer Encoder
-
Masked language models
-
BERT model
-
Different training methods for BERT
-
ALBERT
-
RoBERTa model
-
SpanBERT model
-
FinBERT model
-
Introducing prior knowledge
-
K-BERT
-
KG-BERT
-
Review of Transformer Encoder
-
GPT-1, GPT-2, GPT-3
-
Disadvantages of ELMo
-
Considering context simultaneously under language models
-
Permutation LM
-
Dual-stream self-attention mechanism
Part Five: Information Extraction and Knowledge Graphs
-
Applications and key technologies of information extraction
-
Named entity recognition
-
Common techniques for NER recognition
-
Entity unification techniques
-
Entity disambiguation techniques
-
Coreference resolution
-
Applications of relation extraction
-
Rule-based methods
-
Supervised learning methods
-
Bootstrap methods
-
Distant supervision methods
-
Applications of syntactic parsing
-
Introduction to CFG
-
From CFG to PCFG
-
Evaluating parse trees
-
Finding the best parse tree
-
CKY algorithm
-
From syntactic parsing to dependency grammar parsing
-
Applications of dependency grammar parsing
-
Dependency grammar parsing based on graph algorithms
-
Transition-based dependency grammar parsing
-
Use cases for dependency grammar
-
The importance of knowledge graphs
-
Entities and relationships in knowledge graphs
-
Unstructured data and constructing knowledge graphs
-
Designing knowledge graphs
-
Application of graph algorithms
Part Six: Model Compression and Graph Neural Networks
-
The importance of model compression
-
Overview of common model compression techniques
-
Matrix decomposition-based compression techniques
-
Distillation-based compression techniques
-
Bayesian model-based compression techniques
-
Model quantization
-
Representation of graphs
-
Graphs and knowledge graphs
-
Common algorithms about graphs
-
Deepwalk and Node2vec
-
TransE graph embedding algorithm
-
DSNE graph embedding algorithm
-
Review of Convolutional Neural Networks
-
Designing convolution operations in graphs
-
Information propagation in graphs
-
Graph Convolutional Networks
-
Classic applications of Graph Convolutional Networks
-
From GCN to GraphSAGE
-
Regression of attention mechanisms
-
Detailed explanation of GAT models
-
Comparison of GAT and GCN
-
Handling heterogeneous data
-
Node Classification
-
Graph Classification
-
Link Prediction
-
Community Mining
-
Recommendation Systems
-
Future developments of Graph Neural Networks

02 Some Cases in the Course
|
|
| 2. Implement Word2Vec word vectors from scratch |
| 3. Use SkipGram for recommendations |
| 4. Implement HMM model from scratch |
| 5. Implement a part-of-speech classifier based on Linear-CRF |
| 6. Implement deep learning backpropagation algorithm from scratch |
| 7. Implement AI programs to help write code |
| 8. Implement AI programs to help write articles |
|
|
| 10. Knowledge graph learning based on KG-BERT |
| 11. Risk control system based on knowledge graph |
| 12. Personalized teaching based on knowledge graph |
| 13. Compress Transformer using distillation algorithms |
| 14. Implement social recommendations using GCN |
| 15. Fake news detection based on GAT |
| (The remaining 20+ cases are collapsed, please consult for complete details…) |
03 Some Project Assignments in the Course
-
Chinese word segmentation technology
-
One-hot encoding, tf-idf
-
Distributed representation and Word2Vec
-
BERT vectors, sentence vectors
-
Process of building a Q&A system
-
Vector representation of text
-
FastText
-
Inverted index
-
Recall and ranking in Q&A systems
-
Named entity recognition
-
Feature engineering
-
Evaluation criteria
-
Overfitting
-
Common technologies for chatbot systems
-
Framework for casual chat systems
-
Data processing techniques
-
Use of BERT
-
Use of Transformer
-
Use of medical terminology
-
Understanding user intent from queries
-
Extracting key entities from queries
-
Transforming into query statements
-
Introduction to text summarization generation
-
Keyword extraction techniques
-
Graph neural network-based summarization generation
-
Extraction techniques based on generative methods
-
Evaluation of text summarization quality
04 Some Papers to Read in the Course
| Topic | Paper Title |
| Machine Learning | XGBoost: A Scalable Tree Boosting System |
| Machine Learning | Regularization and Variable Selection via the Elastic Net |
| Word Vectors | Evaluation methods for unsupervised word embeddings |
| Word Vectors | Evaluation methods for unsupervised word embeddings |
| Word Vectors | GloVe: Global Vectors for Word Representation |
| Word Vectors | Deep Contextualized Word Representations |
| Word Vectors | Attention is All You Need |
| Word Vectors | BERT: Pretraining of Deep Bidirectional Transformers for Language Understanding |
| Word Vectors | XLNet: Generalized Autoregressive Pretraining for Language Understanding |
| Word Vectors | KG-BERT: BERT for Knowledge Graph Completion |
| Word Vectors | Language Models are Few-shot Learners |
| Graph Learning | Semi-supervised Classification with Graph Convolutional Networks |
| Graph Learning | Graph Attention Networks |
| Graph Learning | GraphSAGE: Inductive Representation Learning on Large Graphs |
| Graph Learning | Node2Vec: Scalable Feature Learning for Networks |
| Collapsed | Other dozens of articles…… |
05 Who is the Course Suitable For?
-
Undergraduates/Master’s/PhD students in related engineering and science majors who wish to work in NLP after graduation
-
Those who want to delve into the AI field, preparing for research or studying abroad
-
Those who wish to systematically learn knowledge in the NLP field
-
Currently engaged in IT-related work, wanting to work on NLP-related projects in the future
-
Currently engaged in AI-related work, hoping to keep up with the times and deepen their understanding of technology
-
Those who wish to keep up with cutting-edge technologies
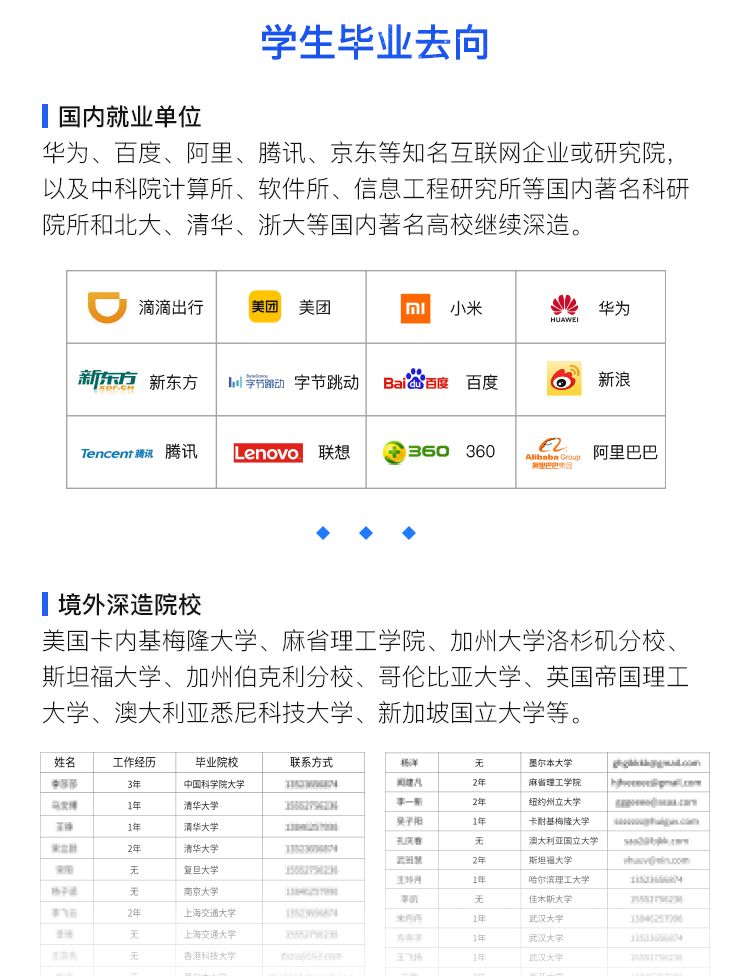
06 Registration Notice
