Recently, while reading some materials about RAG systems, I discovered an interesting phenomenon: the relevance issue of RAG is far more complex than we imagine. Whether from the perspective of data retrieval or the understanding of relevance by large models, the performance of RAG is filled with challenges and opportunities.
Today, I would like to share my thoughts with everyone, hoping to bring some inspiration. Please feel free to discuss if there are any inaccuracies.
1. RAG and Relevance: Not Just Vector Embeddings
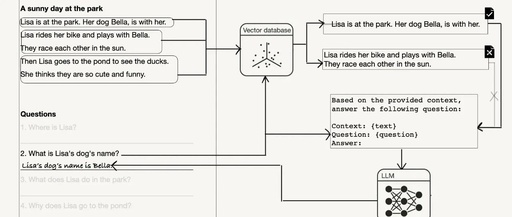
When we talk about RAG, many people immediately think of vector embeddings and similarity measurements. Indeed, vector embeddings play an important role in RAG, but relevance does not solely depend on these technologies. In fact, traditional database queries and text searches are often sufficient to solve problems. While vector embeddings are powerful, they are not omnipotent. 
For example, suppose you are developing a healthcare application based on LLM. You might find that information related to “using LLM to build healthcare software” in the vector space might include “AI for diagnosing diseases” and “AI for video game development”. Although this information appears “similar” in the vector space, it actually lacks crucial connections. This is why we need to rethink the definition of relevance.
In fact, we have been using databases and text searches for decades, and they have worked quite well. Most of the time, querying data in traditional ways is simpler and more straightforward. Vector embeddings certainly have their uses, but to be honest, often you do not need such complex technology — the data you want is not hard to find.
So the question arises: what if the data is really hard to find? Is it time to use vectorDB? The answer is: yes and no. Because what you are really facing at that point is the issue of relevance.
2. Relevance: Beyond Surface Similarities
Relevance is not just superficial similarity. It involves deeper contextual understanding, “information useful to humans is also helpful to LLM”. Therefore, we need to build a system that can understand context and provide genuinely useful information, rather than merely relying on vector similarity.
Research has found that adding irrelevant documents can sometimes even improve the accuracy of RAG systems. This sounds a bit counterintuitive, but the logic behind it is that irrelevant documents might somehow “activate” the model’s reasoning capabilities, helping it better understand the problem. However, this does not mean we can add irrelevant documents indiscriminately. Differentiating between relevant and irrelevant information remains a core challenge for RAG systems.
3. Data Volume vs. Effect: The Double-Edged Sword of RAG Systems
The experiments mentioned by QAnything gave me new insights into the data volume issue of RAG systems. Does more data always mean better performance? This question seems simple, but the answer is not so straightforward.  In the experiment of Higher Education Encyclopedia Q&A, researchers found that as the data volume increased, the performance of the RAG system did not improve linearly. After the first batch of data was added, the Q&A accuracy rate was 42.6%, and with the addition of the second batch of data, the accuracy rate increased to 60.2%. However, after the third batch of data was added, the accuracy rate dropped sharply by 8 percentage points. This indicates that massive data does not always lead to better performance and may instead cause retrieval degradation issues.
In the experiment of Higher Education Encyclopedia Q&A, researchers found that as the data volume increased, the performance of the RAG system did not improve linearly. After the first batch of data was added, the Q&A accuracy rate was 42.6%, and with the addition of the second batch of data, the accuracy rate increased to 60.2%. However, after the third batch of data was added, the accuracy rate dropped sharply by 8 percentage points. This indicates that massive data does not always lead to better performance and may instead cause retrieval degradation issues. 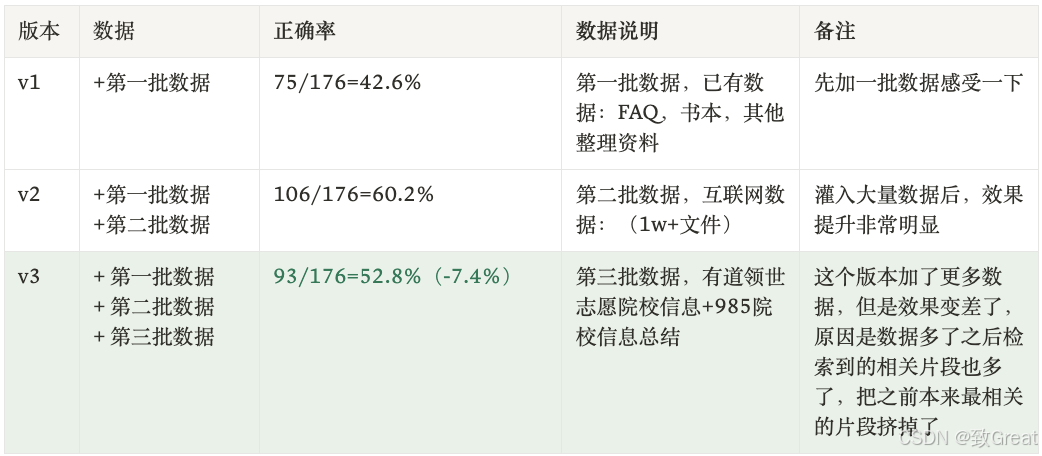
3.1 Retrieval Degradation: Similarity ≠ Relevance
In the experiment, a typical example is the question: “How is Dalian Medical University?” Before adding the third batch of data, the system could answer correctly, but after adding the third batch of data, the system incorrectly returned information related to “Dalian University of Technology”. This is because the third batch of data contained sentences related to “Dalian University of Technology”, which are very similar in the vector space to “Dalian Medical University”, but are actually not relevant. 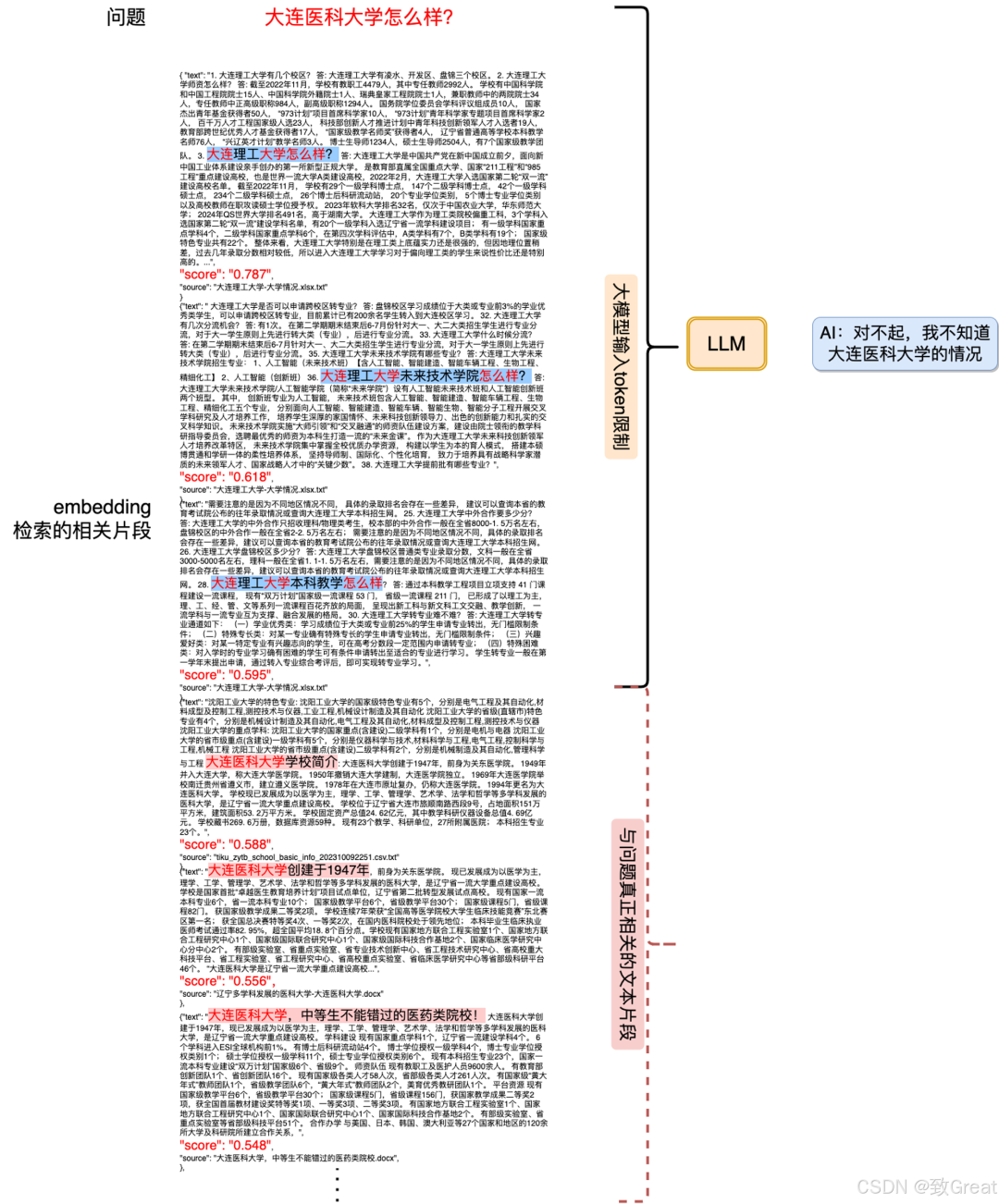
The core contradiction of semantic retrieval is: similarity ≠ relevance. RAG systems need to select the most relevant segments within the limited LLM input tokens. If the retrieved segments are similar but not relevant, it will lead to incorrect answers. Therefore, optimizing the retrieval mechanism to ensure that the most relevant segments are selected is a key challenge in the design of RAG systems.
4. How to Define and Measure Relevance?
So, how do we define relevance? This is a complex question. “How Easily do Irrelevant Inputs Skew the Responses of Large Language Models?” mentions some interesting experiments where researchers constructed different types of information (such as irrelevant information, partially relevant irrelevant information, and relevant but misleading irrelevant information) to test large models’ sensitivity to relevance.
For example, irrelevant information might be unrelated to the topic of the question but is retrieved due to a high similarity score. Partially relevant irrelevant information contains some overlapping information with the topic of the question but does not provide an answer to the question. These experiments indicate that the understanding of relevance by large models is not entirely consistent with traditional retrieval systems. We need more refined methods to measure and optimize relevance. This paper has the following experimental conclusions:
-
Large models are more easily misled by semantically highly relevant but irrelevant information. -
As the amount of irrelevant information increases, the ability of large models to identify truly relevant information decreases. -
The robustness of large models against irrelevant information varies with the format of the question. For example, free-format questions (like open-ended Q&A) are usually more robust than multiple-choice QA formats. In multiple-choice QA formats, the model may choose irrelevant answers due to interference from options. This indicates that the way questions are designed can also affect the model’s judgment of relevance.
Based on the above challenges, we can optimize the measurement of relevance from the following aspects:
4.3.1 Combining Multidimensional Scoring
Although traditional vector similarity scoring (like cosine similarity) is useful, it is not sufficient to fully measure relevance. We can combine the following multidimensional scoring:
-
Semantic Similarity Scoring: Based on the similarity of vector embeddings. -
Context Matching Scoring: Based on whether the information can answer the core of the question. -
Task Objective Scoring: Based on whether the information helps achieve a specific task.
4.3.2 Introducing Human Feedback
Human feedback is an important basis for measuring relevance. By having humans evaluate the results returned by the model, we can better understand which information is truly relevant. For example, the following evaluation metrics can be designed:
-
Usefulness Scoring: Does the result help accomplish the task? -
Accuracy Scoring: Does the result accurately answer the question? -
Relevance Scoring: Is the result truly relevant to the question?
4.3.3 Optimizing Prompt Engineering
The experimental conclusions mention that CoT (Chain-of-Thought) prompting and instruction-enhanced prompting have limited effects on improving the model’s discriminative ability and may even have side effects. Therefore, we need to design prompts more carefully to help the model better understand tasks and context. For example:
-
Clarifying Task Objectives: Clearly tell the model the task it needs to accomplish in the prompt. -
Filtering Irrelevant Information: Include instructions to “ignore irrelevant information” in the prompts, but this needs to be combined with other optimization methods.
4.3.4 Dynamically Adjusting Retrieval Strategies
The retrieval strategy of RAG systems needs to be dynamically adjusted based on tasks and data. For example:
-
Hierarchical Retrieval: Conduct coarse-grained retrieval first, followed by fine-grained filtering. -
Multi-Round Retrieval: Gradually narrow the retrieval range through multiple interactions to improve relevance.
5. The Temporality of RAG: Advantage or Disadvantage?
Another key feature of RAG is its temporality. The results of RAG are temporary and disappear after each request. This may sound a bit annoying, but in reality, temporality provides important advantages for real-time applications. It allows us to isolate data to specific conversations, making it easier to prevent data leakage.
Of course, temporality also brings some challenges. We need to continuously reinject data into the context, which places higher demands on the design and performance of the system. But overall, temporality is a unique advantage of RAG systems, especially in scenarios requiring high security and privacy protection.
6. Optimizing the Data Side: Not Just “More is Better”
The Qnything experiment reminds us that optimizing the data side is not simply about “more is better”. While increasing the data volume can expand the knowledge coverage, it may also introduce noise, leading to retrieval degradation. Therefore, data deduplication, dirty data handling, and precise matching of data with questions are all important factors to consider when optimizing RAG systems.
6.1 Data Quality vs. Data Quantity
In RAG systems, data quality is more important than data quantity. High-quality data can significantly enhance system performance, while low-quality or redundant data may lead to decreased system performance. Therefore, before increasing the data volume, we need to ensure the relevance and accuracy of the data.
6.2 Rapid Iteration vs. Stability
If more data leads to better results, we could optimize the system through rapid iteration. However, experimental results show that increasing data volume does not always lead to performance improvements. Therefore, we need to continuously monitor the system’s performance during the iteration process to ensure that each data update brings positive improvements.
7. Future Directions for RAG
We are in the early stages of AI and LLM development, much like early web applications. The standards we establish now will determine how future AI applications are developed. Therefore, we need to approach tools like RAG with a more thoughtful perspective, rather than simply viewing them as a one-size-fits-all solution.
By focusing on the subtle distinctions of relevance and temporality, we can create systems that provide better and more accurate results. Now is the time to establish best practices for RAG.
8. References
-
“Revisiting Document Relevance in the Eyes of Large Models under the RAG Paradigm: Also Reading Large Model Fine-Tuning for Document Layout Analysis” -
“RAG Systems: Does More Data Mean Better Performance?”