

Reprinted from | Jishi Platform
Author | Shuangqing Laoren
Source | https://zhuanlan.zhihu.com/p/550544232
In the past two months, @避暑山庄梁朝伟 (Liang Chaowei) and I, along with several classmates, conducted an attempt to apply prompt tuning to generative multimodal pre-trained models, specifically implementing it on the OFA we proposed earlier. The paper and GitHub code were just officially released yesterday, welcome to check for more details. The current version of the code is still somewhat rough, so we are maintaining it on an independent branch for prompt tuning.
https://arxiv.org/abs/2208.02532
Prompt Tuning for Generative Multimodal Pretrained Models: https://arxiv.org/abs/2208.02532
Prompt Tuning for Generative Multimodal Pretrained Models: https://arxiv.org/abs/2208.02532
https://github.com/OFA-Sys/OFA/tree/feature/prompt_tuninggithub.com/OFA-Sys/OFA/tree/feature/prompt_tuning
If you just want to know the results, I can summarize it in one sentence: “Similar to NLP, multimodal prompt tuning can achieve results comparable to fine-tuning.” If you want to know more details or my implications, feel free to scroll down to see more.
1
『Why Multimodal Prompt Tuning』
After we developed OFA, we initially thought that since OFA had already started some manual prompt work, we could continue research around the prompt route. However, we didn’t discuss this lofty question clearly, so we decided to start by integrating the capability of prompt tuning into OFA, which led to today’s article and repo update.
The prompt tuning discussed here mainly focuses on soft prompt tuning, a lightweight tuning method similar to Adapter[1], and does not involve discussions on manual prompts and in-context learning. Most previous prompt tuning work has been conducted on NLP pre-trained models, such as Tsinghua’s P-Tuning[2] and P-Tuning v2[3], Stanford’s Prefix Tuning[4], Google’s Prompt tuning[5], Tsinghua’s PPT[6], Fudan’s Black-box Tuning and v2[7, 8], etc. In the CV field, there is also VPT[9]. The multimodal field has also started doing prompt tuning, as mentioned in Liang Chaowei’s previous article.
It is not difficult to find that current multimodal prompt tuning mainly focuses on contrastive learning type pre-trained models[10, 11, 12], while we haven’t seen generative models being used. The contrastive learning method refers to CLIP[13], while generative refers to the BERT pre-training types like UNITER[14], VilBERT[15] series, and the recently popular encoder-decoder series, such as SimVLM[16], BLIP[17], OFA[18], etc. We are the first to attempt this, using OFA as an example to implement Prompt Tuning on generative multimodal pre-trained models.
2
『Prompt Tuning for Generative Multimodal Models』
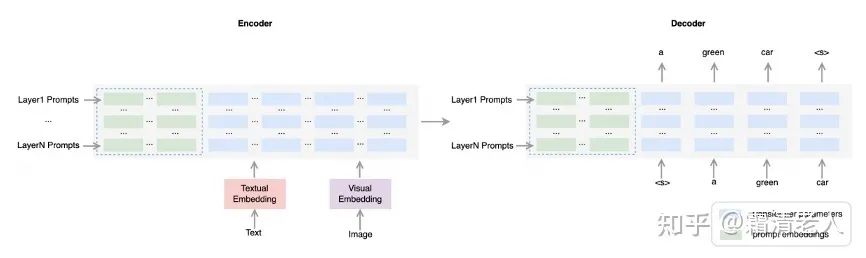
The specific implementation method is very simple, as the model diagram has already presented it clearly. Here, we chose the method of Prefix Tuning, which is also P Tuning v2. We have previously compared Google’s Prompt Tuning with P Tuning v2, and there are significant differences in stability and effectiveness, which many articles have also mentioned. Additionally, since we did not use a large model, P Tuning v2 is a more reasonable option. The difference is that we do not have parameter tuning for the classification head, as OFA is essentially a model that unifies multiple tasks into a generative mode, so the parameters we need to tune are only the Prompt embeddings added to each Transformer layer.
Implementing prompt embedding involves many detail considerations; we have analyzed a few of them. First is the method of generating prompt embeddings, the simplest way is to establish a sparse embedding matrix from which values are taken based on position IDs, but MLP layers can also be utilized. Second is the length of the prompt, which is a classic analytical issue in prompt studies. Third is the depth of the prompt; we mainly want to see if we need to add prompts at every layer.


To be honest, the experimental results were completely as expected and did not exceed expectations. We mainly used base and large model sizes, with approximately 180M and 470M parameters, respectively. The experiments primarily focused on the multimodal understanding and multimodal generation tasks we commonly performed before, including the RefCOCO series object localization tasks, MSCOCO Image Captioning, and the classic VQA. After conducting this batch of experiments, the general conclusion is that on the base model, it is clear that prompt tuning falls short compared to fine-tuning by a noticeable margin, typically around 4-5 points. However, for the large model, the situation is different; except for VQA, it can achieve results comparable to fine-tuning. In addition, we also compared it with bitfit and adapter, which we tuned as much as possible, but still fell slightly short compared to prompt tuning.
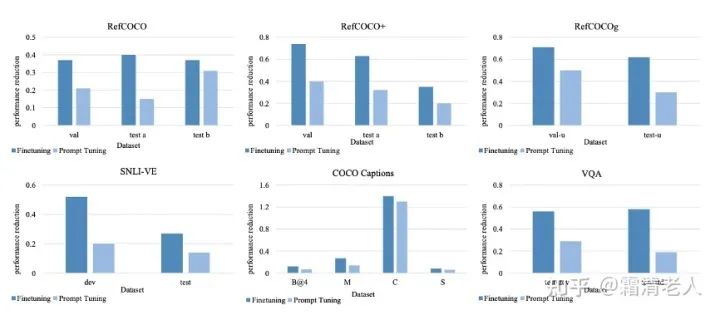
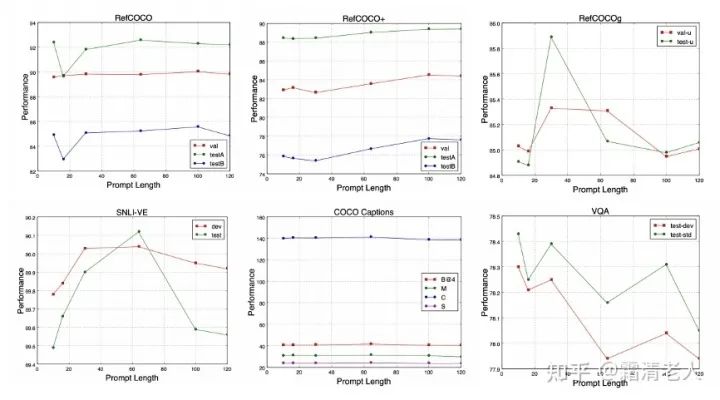
In addition to effectiveness, we also wanted to see if there were any interesting points to explore, so we conducted experiments on adversarial attacks. From the experimental results, prompt tuning indeed has advantages in this area. This aligns with my intuition, as the parameters obtained through large-scale pre-training are frozen, making them relatively more robust. Other discussions are more empirical and differ somewhat from NLP. The overall trend is that the longer the prompt, the better, but in these tasks, we found that if the prompt is too long, it may not only fail to improve but could also lead to a drop, and there isn’t any solid discussion on this; we can only blindly recommend 64, although other articles have discussed similar issues. As for where to place the prompt and how many layers to use, we conducted a simplified version of the analysis, and the result is: “all layers > encoder layers > decoder layers”; from the perspective of placing prompts, focusing on the lower layers is prioritized.

However, the question arises: logically speaking, if it doesn’t drop significantly, why not completely replace fine-tuning with prompt tuning? Many people have been advocating this over the years. But in fact, not everyone in the NLP field has opted for this replacement. We discussed an aspect that is not very favorable, which is the training efficiency issue. Typically, we compare single-step performance, calculating metrics like tokens/s, and find that prompt tuning is indeed faster than fine-tuning. But what about its wall time? At least we haven’t seen others discuss this. This depends on the task; since our model has been unified, many of these downstream tasks have been encountered before, such as Captions and VQA, where the pre-training already has a considerable amount of this type of data, prompt tuning then has some performance advantages. However, if the tasks are relatively rare or have not been seen at all, then prompt tuning can actually be slower than fine-tuning. Another issue is the stability of training; this is something we commonly see in NLP experiments where hyperparameters need almost grid search, while multimodal is relatively better. At least in these experiments, using a stable and relatively large learning rate yielded good results. Interested readers can check our appendix.
3
『In Conclusion』
What I want to say is that this approach seems to have potential; I even think that what we are doing in multimodal is more promising than those methods in NLP. However, the fundamental issue of cost-effectiveness still needs to be addressed. If we can’t have both, we need either to be significantly faster without dropping much or to be significantly better. Another aspect is to leverage its memory-saving advantages to achieve practical applications. On one hand, it does save memory during the training phase, as the number of parameters that need to be optimized is indeed less; on the other hand, its storage also becomes very convenient. Imagine a scenario of edge-cloud collaboration, where the user’s side only stores their respective prompts, while the cloud stores a shared large model—it sounds great. But how to implement this, in what scenarios it will work, and what problems will arise must be figured out through trial and error.
Related Literature
-
Houlsby, N., Giurgiu, A., Jastrzebski, S., Morrone, B., De Laroussilhe, Q., Gesmundo, A., … & Gelly, S. (2019, May). Parameter-efficient transfer learning for NLP. In_International Conference on Machine Learning_(pp. 2790-2799). PMLR. -
Liu, X., Zheng, Y., Du, Z., Ding, M., Qian, Y., Yang, Z., & Tang, J. (2021). GPT understands, too.arXiv preprint arXiv:2103.10385. -
Liu, X., Ji, K., Fu, Y., Du, Z., Yang, Z., & Tang, J. (2021). P-tuning v2: Prompt tuning can be comparable to fine-tuning universally across scales and tasks.arXiv preprint arXiv:2110.07602. -
Li, X. L., & Liang, P. (2021, August). Prefix-Tuning: Optimizing Continuous Prompts for Generation. In_Proceedings of the 59th Annual Meeting of the Association for Computational Linguistics and the 11th International Joint Conference on Natural Language Processing (Volume 1: Long Papers)_(pp. 4582-4597). -
Lester, B., Al-Rfou, R., & Constant, N. (2021, November). The Power of Scale for Parameter-Efficient Prompt Tuning. In_Proceedings of the 2021 Conference on Empirical Methods in Natural Language Processing_(pp. 3045-3059). -
Gu, Y., Han, X., Liu, Z., & Huang, M. (2022, May). PPT: Pre-trained Prompt Tuning for Few-shot Learning. In_Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers)_(pp. 8410-8423). -
Sun, T., Shao, Y., Qian, H., Huang, X., & Qiu, X. (2022). Black-box tuning for language-model-as-a-service.arXiv preprint arXiv:2201.03514. -
Sun, T., He, Z., Qian, H., Huang, X., & Qiu, X. (2022). BBTv2: Pure Black-Box Optimization Can Be Comparable to Gradient Descent for Few-Shot Learning.arXiv preprint arXiv:2205.11200. -
Jia, M., Tang, L., Chen, B. C., Cardie, C., Belongie, S., Hariharan, B., & Lim, S. N. (2022). Visual prompt tuning.arXiv preprint arXiv:2203.12119. -
Zhou, K., Yang, J., Loy, C. C., & Liu, Z. (2022). Learning to prompt for vision-language models.International Journal of Computer Vision, 1-12. -
Zhou, K., Yang, J., Loy, C. C., & Liu, Z. (2022). Conditional prompt learning for vision-language models. In_Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition_(pp. 16816-16825). -
Rao, Y., Zhao, W., Chen, G., Tang, Y., Zhu, Z., Huang, G., … & Lu, J. (2022). Denseclip: Language-guided dense prediction with context-aware prompting. In_Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition_(pp. 18082-18091). -
Radford, A., Kim, J. W., Hallacy, C., Ramesh, A., Goh, G., Agarwal, S., … & Sutskever, I. (2021, July). Learning transferable visual models from natural language supervision. In_International Conference on Machine Learning_(pp. 8748-8763). PMLR. -
Chen, Y. C., Li, L., Yu, L., El Kholy, A., Ahmed, F., Gan, Z., … & Liu, J. (2020, August). Uniter: Universal image-text representation learning. In European conference on computer vision (pp. 104-120). Springer, Cham. -
Lu, J., Batra, D., Parikh, D., & Lee, S. (2019). Vilbert: Pretraining task-agnostic visiolinguistic representations for vision-and-language tasks. Advances in neural information processing systems, 32. -
Wang, Z., Yu, J., Yu, A. W., Dai, Z., Tsvetkov, Y., & Cao, Y. (2021, September). SimVLM: Simple Visual Language Model Pretraining with Weak Supervision. In_International Conference on Learning Representations_. -
Li, J., Li, D., Xiong, C., & Hoi, S. (2022). Blip: Bootstrapping language-image pre-training for unified vision-language understanding and generation.arXiv preprint arXiv:2201.12086. -
Wang, P., Yang, A., Men, R., Lin, J., Bai, S., Li, Z., … & Yang, H. (2022). Unifying architectures, tasks, and modalities through a simple sequence-to-sequence learning framework.arXiv preprint arXiv:2202.03052.
Technical Communication Group Invitation

Scan the QR code to add the assistant on WeChat
About Us
