This article is approximately 2500 words long and is recommended for a 5-minute read.
This article summarizes a knowledge-based direction paper, integrating multi-modal knowledge into multi-modal knowledge graphs.
This blog post summarizes a knowledge-based direction paper, integrating multi-modal knowledge into multi-modal knowledge graphs. From Fudan University, here’s the path:
-
Title: Multi-Modal Knowledge Graph Construction and Application: A Survey
-
Link: https://arxiv.org/abs/2202.05786v1
From Knowledge Graph to Multi-Modal Knowledge Graph
First, a knowledge graph is a large-scale semantic network where entities and concepts are nodes, and various semantic relationships between concepts are edges. This knowledge structure is widely applied; however, existing knowledge graphs appear solely in plain text without real-world connections. For example:
-
Understanding abstract concepts. A symbol “dog” should be rooted in the physical world, establishing a connection between it and a real dog is effective for understanding these abstract concepts. The author also cites examples like “Hand-in-waistcoat”.
-
Assistance with specific tasks. In relationship extraction tasks, additional images visually help distinguish attributes and relationships, such as partOf (the keyboard and screen are parts of a laptop) and colorOf (a banana is usually yellow or yellow-green, not blue). In text generation tasks, it can help generate more informative entity-level sentences (e.g., Trump is giving a speech) rather than vague concept-level descriptions (e.g., a tall blonde man is giving a speech).
Thus, multi-modal knowledge graphs (MMKG) are gradually gaining attention, and this article mainly focuses on two topics:
-
Construction. The construction of MMKG mainly has two types: one is from images to symbols, which means using KG to represent symbols to annotate images; the other is from symbols to images, which means mapping symbols in KG to images.
-
Application. The applications of MMKG can also be broadly divided into two categories: In-MMKG applications, which aim to solve quality or integration issues of MMKG itself; and Out-of-MMKG applications, referring to applying MMKG to general multi-modal tasks.
Benefits of Multi-Modal Knowledge Graphs
-
MMKG provides sufficient background knowledge to enrich the representation of entities and concepts, especially for long-tail problems, where introducing auxiliary common knowledge can enhance the representation capabilities of images and texts.
-
MMKG can understand invisible objects in images. This mainly utilizes symbolic knowledge to provide symbolic information for visually unseen objects or establish semantic relationships between visible and invisible objects.
-
MMKG supports multi-modal reasoning. With the help of external knowledge resources, the reasoning ability in VQA tasks can be enhanced.
-
MMKG typically provides multi-modal data as additional features to bridge information gaps in some NLP tasks. For instance, an image can provide sufficient information to identify whether “Rocky” is the name of a dog or a person.
Construction of Multi-Modal Knowledge Graphs
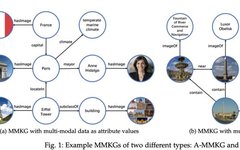
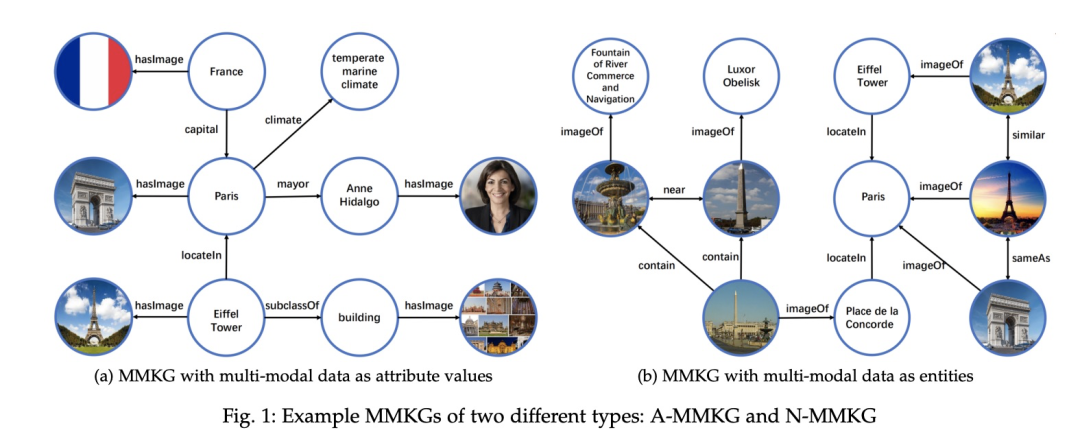
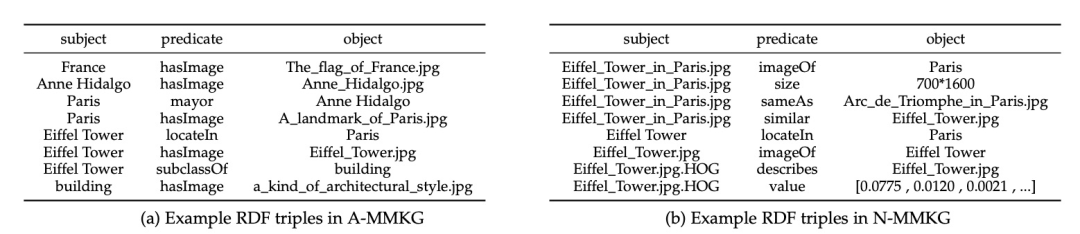
Constructing MMKG requires associating the symbolic knowledge (including entities, concepts, relationships, etc.) from ordinary KG with images. MMKG can be divided into two types: A-MMKG and N-MMKG. A stands for attribute, taking multi-modal data such as images as specific attribute values of entities or concepts, while N stands for entities, taking multi-modal data directly as entities in KGs.
The following figure illustrates the main predicates of the two types, such as hasImage in A-MMKG and sameAs in N-MMKG.
Regarding construction, as mentioned above, there are mainly two methods:
(1) from images to symbols, which annotates symbols in KG on images;
(2) from symbols to images, which annotates corresponding symbols in KG on images.
Figure a illustrates the first method of constructing by labeling images, while figure b illustrates the popular datasets for the second method, symbol grounding.
From Images to Symbols: Labeling Images
This can be supervised by manually annotated datasets, where humans draw bounding boxes and label images or image regions with given tags. A system can also be built for this, divided into three sub-tasks: visual entity/concept extraction, visual relationship extraction, and visual event extraction.
-
The purpose of visual entity/concept extraction is to detect and locate target visual objects in images, then mark these objects with entity/concept symbols from KG, commonly using object detection and visual localization;
-
The purpose of visual relationship extraction is to identify semantic relationships between detected visual entities/concepts in images, then label them with relationships from KG, often using rule-based, statistical, or more fine-grained methods;
-
The purpose of the event extraction task is to predict the event type.
From Symbols to Images: Symbol Grounding
This mainly seeks suitable images to represent symbols already existing in traditional KG. Compared to image labeling methods, this approach is more widely used in MMKG construction and is generally divided into several processes: entity localization, concept localization, and relationship localization.
-
For finding entity images, basing on encyclopedias or searches is a common method.
-
For concepts, whether the concept can be visualized and how to select representative and diverse images from a large number of pictures is an important topic;
-
For relationship localization, image-text matching or image matching would be a good choice.
The author discusses the challenges and future optimization opportunities encountered in these two areas in detail; interested readers can refer to the original text. Meanwhile, how to effectively apply these well-constructed MMKGs is also crucial.
Applications of Multi-Modal Knowledge Graphs
Application tasks are mainly divided into in-KG and out-of-KG. In-MMKG applications refer to tasks conducted within MMKG itself, such as link prediction, triple classification, entity classification, entity alignment, etc. These tasks have been extensively discussed in KG, so this blog post will not elaborate further.
Out-of-MMKG refers to broader downstream tasks, such as multi-modal entity recognition and linking, visual question answering, image-text matching, multi-modal generation tasks, and multi-modal recommender systems.
-
Multi-modal Entity Recognition and Linking. Images can provide necessary complementary information for entity recognition. This mainly utilizes image knowledge in MMKG in two ways: 1) providing target entities that should be linked; 2) learning distributed representations for each multi-modal data and then using it to measure relevance.
-
Visual Question Answering. MMKG can provide knowledge about the question entities and their relationships in images, leading to deeper visual content understanding, while structured symbolic knowledge in MMKG can offer a clearer way to conduct reasoning and predict final answers.
-
Image-Text Matching. MMKG can leverage relationships between multi-modal entities to extend more visual and semantic concepts. Additionally, MMKG can help construct scene graphs, introducing information-related knowledge between visual concepts to further enhance image representation.
-
Multi-modal Generation Tasks. Including image tagging, image captioning, and visual storytelling, the conceptual knowledge in MMKG can significantly improve the representation capabilities of images, demonstrating strength in resolving ambiguity, unseen objects, and vocabulary size.
-
Multi-modal Recommender System. Utilizing external MMKG to obtain richly semantic item representations, even personalized representations are entirely feasible; this is very effective in KG in Recommendation, and extending it to multi-modal forms may further enhance efficacy.
Open Issues in Multi-Modal Knowledge Graphs
The author mainly raises the following future open issues:
-
Grounding Complex Symbolic Knowledge. Apart from the basics of entities, concepts, and relationships, some downstream applications require complex symbolic knowledge, such as a path in KG or a subgraph involving multiple relationships. In many cases, the compound semantics of multiple relationships are implicitly expressed and may change over time.
-
Quality Control. Large-scale MMKGs may contain errors, missing facts, or outdated facts, so accuracy, completeness, consistency, freshness, and image quality may need to be discussed.
-
Efficiency. The construction efficiency of MMKG poses significant challenges, such as NEIL requiring about 350K CPU hours to collect 400K visual instances for 2273 objects, while in a typical KG, this number may rise to billions of instances. If expanded to video data, this scalability issue will continue to amplify. Beyond constructing MMKG, the online application requirements for MMKG will also be higher.