

Large Language Models (LLMs) integrated with visual encoders have recently demonstrated remarkable performance in visual understanding tasks, leveraging their inherent ability to understand and generate human-like text for visual reasoning. Given the diversity of visual data, Multimodal Large Language Models (MM-LLMs) exhibit different variances in model design and training when understanding images, short videos, and long videos. This article focuses on the significant differences and unique challenges posed by long video understanding compared to static image and short video comprehension. Unlike static images, short videos contain continuous frames with spatial and temporal event information, while long videos consist of multiple events, covering inter-event and long-term temporal information. In this review, we aim to trace and summarize the progress of MM-LLMs from image understanding to long video comprehension.
We review the differences in various visual understanding tasks, emphasizing the challenges in long video understanding, including finer-grained spatiotemporal details, dynamic events, and long-term dependencies. Next, we detail the advancements in model design and training methods of MM-LLMs in long video understanding. Finally, we compare the performance of existing MM-LLMs in understanding different lengths of video benchmarks and discuss the future potential development directions of MM-LLMs in long video comprehension.
https://arxiv.org/abs/2409.18938
1 Introduction
Large Language Models (LLMs) have demonstrated significant versatility and capabilities in understanding and generating human-like text by expanding model size and training data (Raffel et al., 2020; Brown, 2020; Chowdhery et al., 2023; Touvron et al., 2023a). To extend these capabilities to visual understanding tasks, various methods have been proposed to combine LLMs with specific visual modality encoders, thereby endowing LLMs with visual perception capabilities (Alayrac et al., 2022; Li et al., 2023a). A single image or multiple frames are encoded as visual tokens and integrated with text tokens to assist Multimodal Large Language Models (MM-LLMs) in achieving visual understanding. For long video comprehension, MM-LLMs (Dai et al., 2023; Liu et al., 2024c) are designed to handle a large number of visual frames and diverse events, enabling applications in various real-world scenarios such as automatic analysis of sports video highlights, movies, surveillance footage, and self-perspective videos in embodied AI. For instance, a robot can learn to make coffee through long self-perspective videos, analyzing key events in the long video, including: 1) adding one to two tablespoons of coffee powder for every six ounces of water; 2) filling the coffee machine’s water tank; 3) placing coffee powder in the filter basket; 4) starting the coffee machine and waiting for it to brew coffee. Modeling long videos with complex spatiotemporal details and dependencies remains a challenging problem (Wang et al., 2023a; Mangalam et al., 2024; Xu et al., 2024b; Wu et al., 2024).
There are significant differences between long video understanding and other visual understanding tasks. Unlike static image understanding, which focuses solely on the spatial content of static images, short video understanding must also consider temporal information that varies across continuous frames within events (Li et al., 2023b; Zhang et al., 2023; Maaz et al., 2023). Furthermore, long videos (over one minute) (Wu and Krahenbuhl, 2021; Zhang et al., 2024d; Song et al., 2024a) typically consist of multiple events, with varying scenes and visual content, requiring the capture of inter-event and long-term changes for effective understanding. How to effectively balance spatial and temporal details with a limited number of visual tokens poses significant challenges for Long Video Language Models (LV-LLMs) (Song et al., 2024a; He et al., 2024; Xu et al., 2024b). Unlike short videos that contain only dozens of frames, long videos often consist of thousands of frames (Ren et al., 2024; Zhang et al., 2024d). Therefore, LV-LLMs must be able to remember and continuously learn long-range associations across minutes or even hours of video. To achieve comprehensive understanding of long videos, the advancements in model design and training of MM-LLMs deserve special attention (Fu et al., 2024a; Wu et al., 2024).
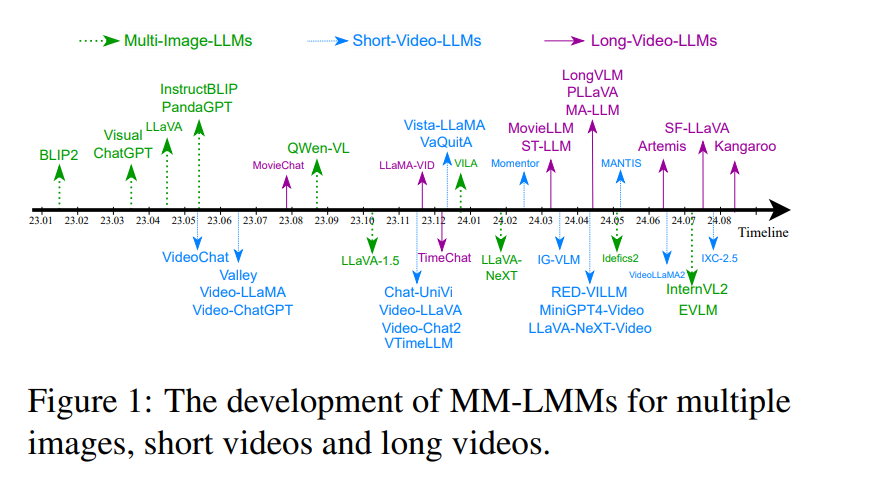
We summarize the comparison of MM-LLMs in image, short video, and long video understanding in Figure 2. In addition to the inheritance and development relationship discussed above between long video understanding and other visual understanding tasks, LV-LLMs are also built on the progress of multimodal models for multiple images and short videos, sharing similar visual encoders, LLM backbones, and cross-modal connector structures. To effectively address the emerging challenges in long video understanding tasks, LV-LLMs have designed more efficient long video-level connectors that not only bridge cross-modal representations but also compress visual tokens to a manageable number (Li et al., 2023c; Zhang et al., 2024d). Additionally, temporal awareness modules are often introduced to enhance LV-LLMs’ ability to capture temporal information (Qian et al., 2024). For pre-training and instruction tuning, video-text pairs and video instruction data are crucial for MM-LLMs to process images and videos with shared spatial awareness and reasoning capabilities (Li et al., 2023b). Long video training datasets are particularly important for temporal cross-modal semantic alignment and capturing long-term associations, which are critical for LV-LLMs (Song et al., 2024b). Our review will provide a comprehensive summary of advancements in model design and training methods, tracing the evolution of MM-LLMs from image understanding to long video comprehension.
Recent reviews on visual understanding tasks often adopt a singular perspective, either examining MM-LLMs from a global viewpoint (Yin et al., 2023; Zhang et al., 2024a) or focusing on image or video understanding tasks from a local perspective (Zhang et al., 2024b; Nguyen et al., 2024). While these works have extensively reviewed the research topic, they have not discussed the inheritance and development relationships between different tasks and methods. Moreover, existing reviews on video understanding tasks (Tang et al., 2023) tend to focus on general video understanding rather than the more challenging long video understanding tasks. Long videos exceeding one minute are widely used in education, entertainment, transportation, and other fields, requiring robust models for comprehensive automatic understanding (Apostolidis et al., 2021). Our work is one of the earliest to summarize and discuss the research on long video understanding tasks from a developmental perspective.
The structure of this review is as follows: First, we find that long video understanding tasks are more complex compared to image and short video understanding tasks (Section 2.1), and in Section 2.2, we summarize the unique challenges of long video understanding. Next, we detail the progress of MM-LLMs from the perspectives of model architecture (Section 3) and training methods (Section 4), focusing on the implementation of LV-LLMs in comprehensive long video understanding. Then, we compare the performance of video LLMs in understanding benchmarks from seconds to minutes (Section 5.1) and from minutes to hours (Section 5.2), providing insights into the existing research achievements of LV-LLMs. Finally, we discuss the future research directions in the field of long video understanding in Section 6 to advance this research area.

2 Long Video Understanding
Due to the inherent differences between long video understanding and image or short video understanding, including the various events present in multi-frame and dynamic scenes, long video understanding tasks pose additional challenges in visual comprehension.
2.1 Visual Reasoning and Understanding
Visual reasoning requires models to understand and interpret visual information and combine multimodal perception with commonsense understanding (Johnson et al., 2017; Chen et al., 2024c). There are three main types of visual reasoning tasks: Visual Question Answering (VQA), Visual Captioning (VC) or Description (VD), and Visual Dialogue (VDia). VQA (Antol et al., 2015; Zakari et al., 2022) involves generating natural language answers based on input visual data and accompanying questions. VC and VD systems (Vinyals et al., 2015; Sharma et al., 2018; Li et al., 2019) generate concise natural language sentences to summarize the main content of visual data or produce detailed and comprehensive descriptions of visual data. VDia (Das et al., 2017; Qi et al., 2020) involves multi-turn dialogue around visual content, consisting of a series of question-answer pairs.
Image Understanding. As shown in Figure 3(a), image understanding tasks involve various visual reasoning tasks for a single image, such as image captioning and image-centered question answering (Sharma et al., 2018; Mathew et al., 2021; Changpinyo et al., 2022; Li et al., 2023a; Chen et al., 2024a). These tasks focus solely on spatial information, including coarse-grained understanding of global visual content (Ordonez et al., 2011; Sohoni et al., 2020) and fine understanding of local visual details (Wei et al., 2021; Liu et al., 2024b; Peng et al., 2024).
Short Video Understanding. Unlike image understanding tasks that involve only static visual data, short video understanding also incorporates temporal information from multi-frame visual data (Xu et al., 2016; Bain et al., 2021; Li et al., 2023b, 2024e). In addition to spatial reasoning (Ranasinghe et al., 2024), temporal reasoning within events and spatiotemporal reasoning across frames are crucial for short video understanding (Huang et al., 2018; Lin et al., 2019; Diba et al., 2023).
Long Video Understanding. Long videos typically span several minutes or even hours, often containing multiple events, and compared to short videos, long videos encompass richer spatial content and temporal variations (Mangalam et al., 2024; Li et al., 2024f; Song et al., 2024a,b). As summarized in Figure 3(c), long video understanding involves not only spatial and temporal reasoning within events but also inter-event reasoning and long-term reasoning across different video events (Wu et al., 2019; Wu and Krahenbuhl, 2021; Wang et al., 2023a; Zhou et al., 2024; Fang et al., 2024).
2.2 Challenges of Long Video Understanding
Long videos present new challenges for comprehensive visual understanding compared to images and short videos, specifically as follows:
Rich Fine-Grained Spatiotemporal Details. Long videos cover a wide range of subjects, scenes, and activities, containing various details such as objects, events, and attributes (Fu et al., 2024a; Wu et al., 2024). Compared to static images and short videos with similar multi-frames, these details are richer, making long video understanding more challenging. For example, fine-grained spatial question answering can be introduced in any frame, while temporal question answering can be introduced between or within frames in long video reasoning tasks (Song et al., 2024a). Multimodal LLMs for long video understanding must capture all relevant fine-grained spatiotemporal details across minutes or even hours of video frames while using a limited number of visual tokens.
Dynamic Events in Scene Transitions and Content Changes. Long videos often contain various dynamic events, with significant scene and content changes (Wu et al., 2024). These events may be semantically related and temporally coordinated based on the order of occurrence (Bao et al., 2021), or they may exhibit significant semantic differences due to plot twists (Papalampidi et al., 2019). Inter-event reasoning involves multiple events with different visual information, which is crucial for accurate content understanding (Cheng et al., 2024a; Qian et al., 2024). For multimodal LLMs, distinguishing semantic differences and maintaining semantic consistency across different events is particularly important for long video understanding.
Long-Term Associations and Dependencies. Long videos often contain actions and events that span long periods. Capturing long-term dependencies and understanding how different parts of the video relate to each other over long periods is a challenge (Wu et al., 2019). LLMs designed for images or short videos often cannot relate current events to past or future events that are far removed in time (Wu and Krahenbuhl, 2021) and cannot make long-term decisions (Wang et al., 2024b).

3 Progress in Model Architecture
In this section, we discuss the progress of Multimodal Large Language Models (MM-LLMs) from image-target models to long video-target models from the perspective of model architecture. As shown in Figure 4, MM-LLMs for images, short videos, and long videos share similar structures, including visual encoders, LLM backbones, and intermediary connectors. Unlike image-level connectors in image-target MM-LLMs, video-level connectors play a key role in integrating cross-frame visual information. In Long Video LLMs (LV-LLMs), designing connectors is more challenging, requiring effective compression of large amounts of visual information and combining temporal knowledge to manage long-term associations.
3.1 Visual Encoders and LLM Backbones
MM-LLMs, including image-target and video-target models, typically use similar visual encoders to extract visual information. The LLM backbone was also relatively common in early MM-LLM methods, while existing LV-LLMs tend to use long-context LLMs in their implementations.
Visual Encoders. Pre-trained visual encoders are responsible for capturing visual knowledge from raw visual data. As shown in Table 1, image encoders such as CLIP-ViT-L/14 (Radford et al., 2021), EVA-CLIP-ViT-G/14 (Sun et al., 2023), OpenCLIP-ViT-bigG/14 (Cherti et al., 2023), and SigLIP-SO400M (Zhai et al., 2023) are widely used in LLMs for image and video targets. Recent work (Li et al., 2024a) indicates that visual representations (including image resolution, size of visual tokens, and pre-trained visual resources) are more important than the size of the visual encoder.
LLM Backbone. LLMs are the core module in visual understanding systems, inheriting reasoning and decision-making attributes. Compared to closed-source LLMs such as GPT-3/4 (Brown, 2020; Achiam et al., 2023) and Gemini-1.5 (Reid et al., 2024), more open-source LLMs are commonly used for implementing visual LLMs. These open-source LLMs include Flan-T5 (Chung et al., 2024), LLaMA (Touvron et al., 2023b,c; Dubey et al., 2024), Vicuna (Chiang et al., 2023), QWen (Bai et al., 2023a), Mistral (Jiang et al., 2023), Openflamingo (Awadalla et al., 2023), Yi (Young et al., 2024), and InternLM (Team, 2023; Cai et al., 2024). The strength of the LLM is often associated with the multimodal capabilities of visual LLMs (Li et al., 2024b,a). This means that for LLMs of the same size, models with stronger language capabilities perform better; while for models of different sizes of the same LLM, larger models typically yield better multimodal performance. Furthermore, long-context LLMs support learning from more data by extending context lengths to thousands of tokens (Yang et al., 2024). Recent LV-LLMs effectively transfer the long-context understanding capabilities of LLMs to the visual modality (Zhang et al., 2024d).
3.2 Modal Interfaces
Connectors between visual encoders and LLMs serve as modal interfaces that map visual features into the language feature space. Given the diversity of visual data sources, these connectors can be categorized into image-level, video-level, and long video-level connectors.
Image-Level Connectors. Image-level connectors are used to map image features into language space to handle raw visual tokens, and they are widely used in MM-LLMs for both image and video targets. These connectors can be divided into three categories: The first category directly uses single-layer linear layers (Liu et al., 2024c) or multi-layer perceptrons (MLP) (Liu et al., 2024a) to map image features into language embedding space. However, this method of retaining all visual tokens does not apply to visual understanding tasks involving multiple images. To address the limitations of retaining all visual tokens, the second category adopts pooling-based methods, including spatial pooling (Maaz et al., 2023), adaptive pooling (Xu et al., 2024a), semantic similar token merging (Jin et al., 2024), and adjacent token averaging (Zhang et al., 2024e; Li et al., 2024c). The third category leverages cross-attention or Transformer-based structures, such as Q-Former (Li et al., 2023a) and Perceiver Resampler (Jaegle et al., 2021), for compressing image features. Q-Former is a lightweight Transformer structure that uses a set of learnable query vectors to extract and compress visual features. Many visual LLMs (Dai et al., 2023; Li et al., 2023b; Ma et al., 2023a; Liu et al., 2024e) follow BLIP-2, selecting Q-Former-based connectors. Other visual LLMs (Ma et al., 2023b; Jiang et al., 2024) choose to use Perceiver Resampler to reduce computational burden by extracting patch features.
Video-Level Connectors. Video-level connectors are used to extract continuous visual data and further compress visual features. Compared to image-level connectors in image-target MM-LLMs, video-level connectors are particularly important in video-target MM-LLMs, including LV-LLMs. Some methods directly concatenate image tokens before inputting them into LLMs, making them sensitive to the number of frame images (Dai et al., 2023; Lin et al., 2023). Similar structures used for token compression in image-level connectors can be adapted for video-level interfaces, such as pooling and Transformer-based structures. Pooling along the temporal sequence dimension is a direct way to reduce redundancy in temporal information (Maaz et al., 2023; Song et al., 2024a). Transformer-based methods, such as Video Q-Former (Zhang et al., 2023; Ma et al., 2023a; Ren et al., 2024) and Video Perceiver (Wang et al., 2023b), reduce data complexity while extracting video features. Additionally, 3D convolution-based methods can extract and compress visual data from both spatial and temporal dimensions (Cheng et al., 2024b; Liu et al., 2024d).
Long Video-Level Connectors. Connectors specifically designed for long video LLMs consider two special factors: efficient visual information compression for processing long video data and time-aware design to retain temporal information.
Effectively compressing visual information requires not only reducing the number of input visual tokens to an acceptable level but also retaining the complete spatiotemporal details contained in long videos. Videos contain two types of data redundancy: spatial data redundancy within frames and spatiotemporal data redundancy between frames (Li et al., 2022; Chen et al., 2023a). On one hand, spatial data redundancy occurs when pixels within frames are the same at the regional level, leading to inefficiency when representing redundant visual frames through complete visual token representation. To reduce spatial video data redundancy, the LLaVA-Next series of methods (Zhang et al., 2024e; Li et al., 2024d; Liu et al., 2024b; Li et al., 2024c) merge adjacent frame patch tokens, while Chat-UniVi (Jin et al., 2024) merges similar frame patch tokens. On the other hand, spatiotemporal data redundancy includes pixel redundancy between frames and motion redundancy (Pourreza et al., 2023), in which these redundant video frames exhibit similar semantic information. To reduce spatiotemporal video redundancy, MovieChat (Song et al., 2024a) and MALMM (He et al., 2024) merge similar frame features before inputting them into LLMs. Retaining more video spatiotemporal details while reducing redundant information is crucial for accurate long video reasoning (Diba et al., 2023). To balance global and local visual information and support more frame inputs, SlowFast-LLaVA (Xu et al., 2024b) employs a slow path with low frame rates to extract features while retaining more visual tokens and a fast path with high frame rates to focus on motion cues through larger spatial pooling strides.
Additionally, time-related visual data can effectively manage the inherent spatiotemporal information of long videos (Hou et al., 2024). Time-aware designs can enhance the temporal capturing ability of video-related LLMs, which is particularly beneficial for long video understanding. VTimeLLM (Huang et al., 2024a) and InternLM-XComposer-2.5 (IXC-2.5) (Zhang et al., 2024c) both use frame indices to enhance temporal relationships. The difference lies in their approaches: VTimeLLM learns temporal information by training decoding texts that include frame indices, while IXC-2.5 encodes frame indices along with the frame image context. TimeChat (Ren et al., 2024) and Momentor (Qian et al., 2024) inject temporal information directly into frame features to capture fine-grained temporal information. Specifically, TimeChat designs a time-aware frame encoder to extract visual features at the frame level and add corresponding timestamp descriptions, while Momentor utilizes a time-aware module for continuous time encoding and decoding, injecting temporal information into frame features.
Conclusion
This article summarizes the progress of visual LLMs from images to long videos. Based on the analysis of the differences between image understanding, short video understanding, and long video understanding tasks, we identify the key challenges of long video learning. These challenges include capturing more fine-grained spatiotemporal details in dynamic continuous events and compressing long-term dependencies in visual information amid scene transitions and content changes. Next, we introduce the advances in model architecture and training from image LLMs to long video LLMs, aiming to enhance understanding and reasoning capabilities for long videos. Subsequently, we review multiple benchmarks of different lengths and compare the performance of various methods in video understanding. This comparison provides insights into future research directions for long video understanding. Our paper is the first to focus on the development and improvement of long video LLMs to enhance long video understanding research. We hope this research can promote advancements in LLMs in the field of long video understanding and reasoning.

Scan the QR code to add the assistant on WeChat
