
mPLUG Team Contribution QbitAI | WeChat Official Account
New SOTA in Multimodal Document Understanding!
Alibaba’s mPLUG team has released the latest open-source work mPLUG-DocOwl 1.5, proposing a series of solutions to tackle four major challenges: high-resolution image text recognition, general document structure understanding, instruction following, and external knowledge incorporation.
Without further ado, let’s take a look at the results.
Complex structured charts can be converted to Markdown format with one click:
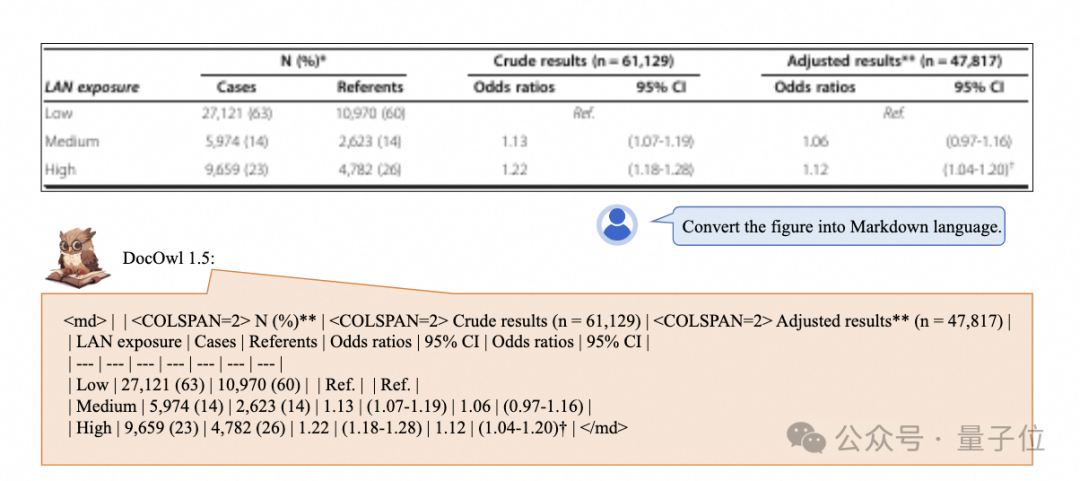
Different styles of charts are also supported:

More detailed text recognition and positioning can also be easily handled:

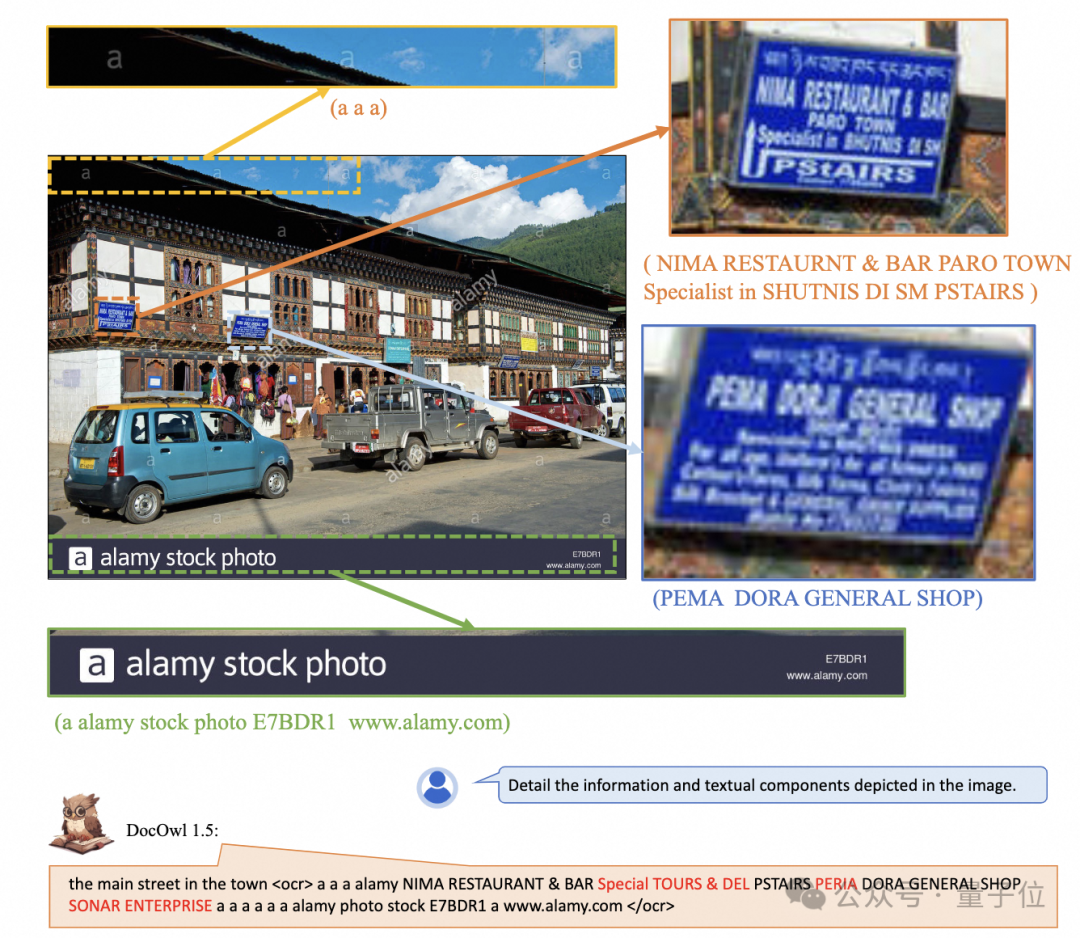
It can also provide detailed explanations for document understanding:

It is important to note that “document understanding” is currently a crucial application scenario for large language models. There are many products on the market that assist in document reading, some primarily relying on OCR systems for text recognition, combined with LLM for text understanding, achieving good document understanding capabilities.
However, due to the diverse categories of document images, rich text, and complex layouts, it is challenging to achieve general understanding of complex images such as charts, infographics, and web pages.
Currently popular multimodal large models like QwenVL-Max, Gemini, Claude3, and GPT4V all possess strong document image understanding capabilities, but progress in open-source models in this direction has been slow.
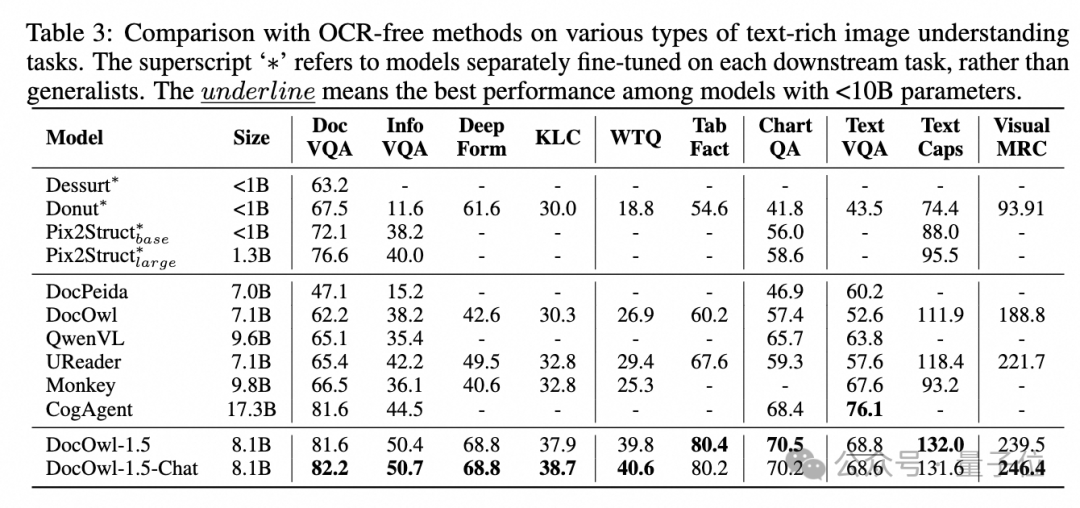
Alibaba’s new research mPLUG-DocOwl 1.5 has achieved SOTA on 10 document understanding benchmarks, improving over 10 points on 5 datasets, and surpassing the 17.3B CogAgent from Zhipu AI on some datasets, achieving an 82.2 performance on DocVQA.
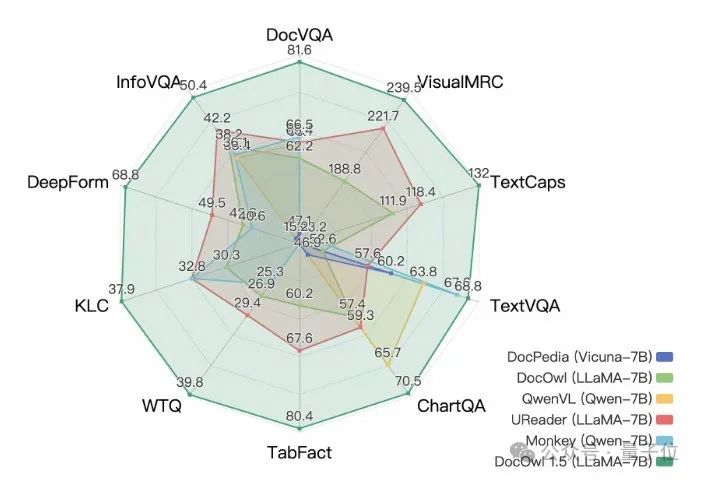
In addition to having the ability to answer simple questions based on benchmarks, through fine-tuning with a small amount of detailed explanation (reasoning) data, DocOwl 1.5-Chat can also provide detailed explanations in the multimodal document field, showing great application potential.
The Alibaba mPLUG team began researching multimodal document understanding in July 2023, releasing mPLUG-DocOwl, UReader, mPLUG-PaperOwl, and mPLUG-DocOwl 1.5 in succession, and open-sourcing a series of document understanding large models and training data.
This article analyzes the key challenges and effective solutions in the field of “multimodal document understanding” based on the latest work mPLUG-DocOwl 1.5.
Challenge 1: High-Resolution Image Text Recognition
Unlike general images, the characteristics of document images include diverse shapes and sizes, which can encompass A4-sized document images, short and wide table images, long and narrow mobile webpage screenshots, and casually taken scene images, resulting in a wide distribution of resolutions.
Mainstream multimodal large models often directly scale the size of images when encoding, for example, mPLUG-Owl2 and QwenVL scale to 448×448, and LLaVA 1.5 scales to 336×336.
Simply scaling document images can lead to blurry and distorted text that is difficult to recognize.
To handle document images, mPLUG-DocOwl 1.5 continues the cropping approach from its predecessor UReader, as shown in Figure 1:
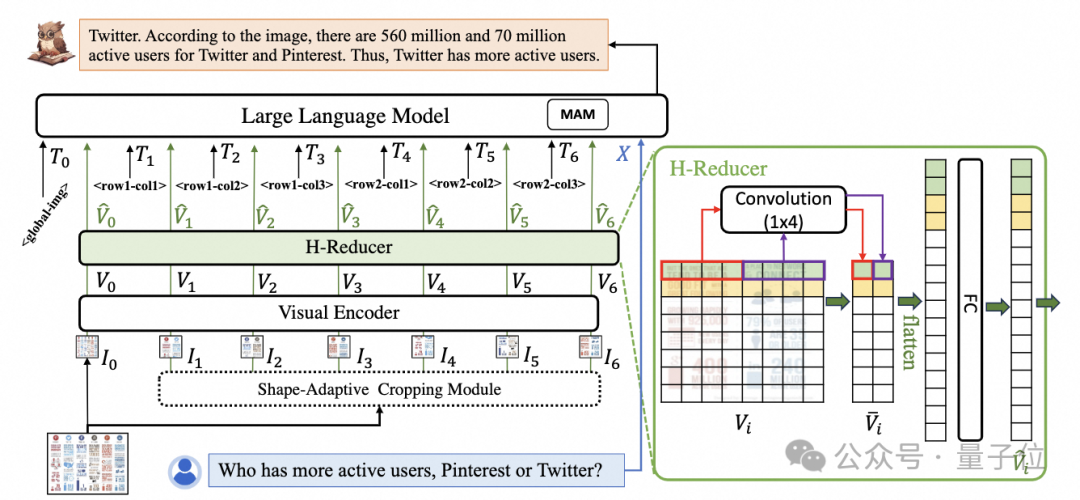
△ Figure 1: DocOwl 1.5 Model Structure
UReader was the first to propose obtaining a series of sub-images through a parameter-free shape-adaptive cropping module (Shape-adaptive Cropping Module) based on existing multimodal large models. Each sub-image is encoded using a low-resolution encoder, and finally, the language model connects the semantics of the sub-images directly.
This cropping strategy maximizes the utilization of existing universal visual encoders (e.g., CLIP ViT-14/L) for document understanding, greatly reducing the cost of retraining high-resolution visual encoders. The shape-adaptive cropping module is shown in Figure 2:

△ Figure 2: Shape-Adaptive Cropping Module.
Challenge 2: General Document Structure Understanding
For document understanding that does not rely on OCR systems, recognizing text is a basic capability. Achieving semantic understanding and structural understanding of document content is crucial. For example, understanding table content requires understanding the correspondence between headers and rows and columns; understanding charts requires understanding the diverse structures of line charts, bar charts, pie charts, etc.; understanding contracts requires understanding diverse key-value pairs such as dates and signatures.
mPLUG-DocOwl 1.5 focuses on solving the general document structure understanding capability through model structure optimization and enhanced training tasks, achieving significantly stronger general document understanding capabilities.
In terms of structure, as shown in Figure 1, mPLUG-DocOwl 1.5 abandons the visual language connection module Abstractor from mPLUG-Owl/mPLUG-Owl2, adopting an H-Reducer based on “convolution + fully connected layers” for feature aggregation and alignment.
Compared to the Abstractor based on learnable queries, H-Reducer retains the relative positional relationships between visual features, better transmitting document structure information to the language model.
Compared to the MLP that retains the length of visual sequences, H-Reducer significantly reduces the number of visual features through convolution, allowing the LLM to understand high-resolution document images more efficiently.
Considering that most document images have horizontally aligned text, with coherent semantics in the horizontal direction, H-Reducer employs a 1×4 convolution shape and stride. In the paper, the authors demonstrated through sufficient comparative experiments the superiority of H-Reducer in structural understanding and that 1×4 is a more universal aggregation shape.
In terms of training tasks, mPLUG-DocOwl 1.5 has designed a unified structure learning (Unified Structure Learning) task for all types of images, as shown in Figure 3:
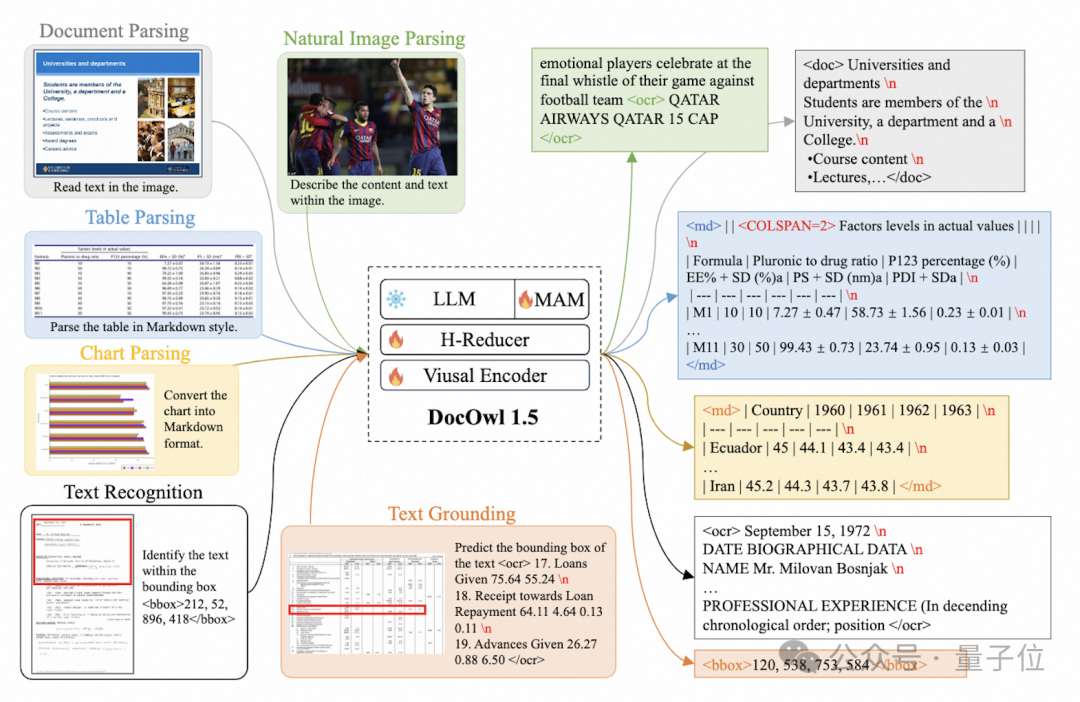
△ Figure 3: Unified Structure Learning
Unified Structure Learning includes both global image text parsing and multi-granularity text recognition and positioning.
In the global image text parsing task, for document images and webpage images, using spaces and line breaks can most universally represent the structure of text; for tables, the authors introduced special characters to represent multiple rows and columns based on Markdown syntax, balancing the simplicity and universality of table representation; for charts, considering that charts are visual representations of tabular data, the authors also adopted Markdown-style tables as the parsing target for charts; for natural images, semantic descriptions and scene text are equally important, thus adopting the form of image descriptions combined with scene text as the parsing target.
In the “text recognition and positioning” task, to better fit document image understanding, the authors designed four granularities of text recognition and positioning: words, phrases, lines, and blocks, with bounding boxes represented by discretized integer numbers ranging from 0-999.
To support unified structure learning, the authors constructed a comprehensive training set DocStruct4M, covering different types of images such as documents/webpages, tables, charts, and natural images.
After unified structure learning, DocOwl 1.5 possesses structured parsing and text positioning capabilities for multimodal document images.

△ Figure 4: Structured Text Parsing
As shown in Figures 4 and 5:

△ Figure 5: Multi-Granularity Text Recognition and Positioning
Challenge 3: Instruction Following
“Instruction Following” requires the model to execute different tasks based on basic document understanding capabilities according to user instructions, such as information extraction, question answering, image description, etc.
Continuing the approach of mPLUG-DocOwl, DocOwl 1.5 unifies multiple downstream tasks into the form of instruction-question answering, obtaining a generalist model in the document domain through multi-task joint training after unified structure learning.
In addition, to enable the model to provide detailed explanations, mPLUG-DocOwl previously attempted to introduce pure text instruction fine-tuning data for joint training, which had some effect but was not ideal.
In DocOwl 1.5, the authors constructed a small amount of detailed explanation data (DocReason25K) based on the questions from downstream tasks using GPT3.5 and GPT4V.
By jointly training with downstream document tasks and DocReason25K, DocOwl 1.5-Chat can achieve better results on benchmarks:
△ Figure 6: Document Understanding Benchmark Evaluation
And also provide detailed explanations:

△ Figure 7: Detailed Explanation of Document Understanding
Challenge 4: Incorporating External Knowledge
Due to the richness of information in document images, understanding often requires additional knowledge, such as specialized terms and their meanings in specific fields.
To explore how to incorporate external knowledge for better document understanding, the mPLUG team has proposed mPLUG-PaperOwl in the field of academic papers, constructing a high-quality dataset for analyzing paper charts, M-Paper, which involves 447k high-definition paper charts.
This dataset provides context for the charts in papers as a source of external knowledge and designs “outlines” (outline) as control signals for chart analysis, helping the model better grasp user intent.
Based on UReader, the authors fine-tuned on M-Paper to obtain mPLUG-PaperOwl, demonstrating initial capabilities for analyzing paper charts, as shown in Figure 8.
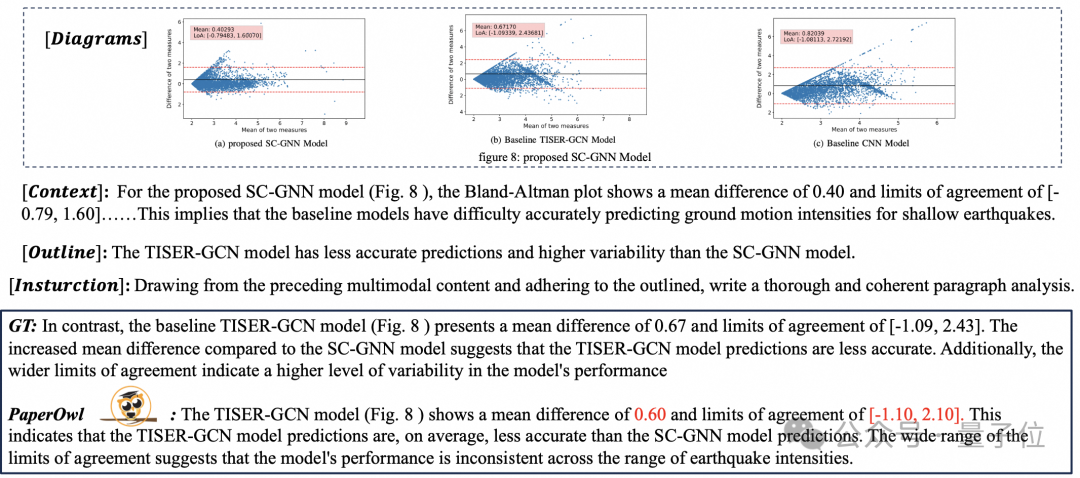
△ Figure 8: Paper Chart Analysis
mPLUG-PaperOwl is currently just an initial attempt to incorporate external knowledge into document understanding, still facing issues such as domain limitations and singular knowledge sources that need further resolution.
In summary, this article summarizes the four key challenges (“high-resolution image text recognition”, “general document structure understanding”, “instruction following”, “external knowledge incorporation”) in multimodal document understanding without relying on OCR, starting from the recently released 7B strongest multimodal document understanding large model mPLUG-DocOwl 1.5, along with the solutions provided by Alibaba’s mPLUG team.
Although mPLUG-DocOwl 1.5 has significantly improved the document understanding performance of open-source models, there remains a substantial gap between it and closed-source large models as well as real-world needs, with room for improvement in areas like text recognition in natural scenes, mathematical calculations, and general types.
The mPLUG team will continue to optimize the performance of DocOwl and open-source it, inviting everyone to keep following and discussing!
GitHub link: https://github.com/X-PLUG/mPLUG-DocOwlPaper link: https://arxiv.org/abs/2403.12895
— End —
【🔥 Hot Registration】 China AIGC Industry Summit
Scheduled for April 17
The summit has invited several representatives from technology, products, investment, and user fields to discuss the latest trends in the generative AI industry.
The first batch of confirmed attendees includes: MicrosoftTao Ran, Kunlun WanweiFang Han, Meitu CompanyWu Xinhong, Lenovo Venture CapitalSong Chunyu, Tongyi QianwenLin Junyang, Zhuji DynamicsZhang Li, Renmin UniversityLu Zhiwu, Peking UniversityYuan Li, Xiaoice CompanyXu Yuanchun, Kingsoft OfficeYao Dong, FusionFundZhang Lu, Tongyi Large ModelXu Dong, DCMZeng Zhenyu, Lanma TechnologyZhou Jian, GetKuai Dao Qing Yi, Experimental FilmmakerHai Xin, etc. Learn more
Welcome to register for the summit ⬇️

Click here👇 to follow me, remember to star it~
One-Click Three Connections: “Share”, “Like”, and “See”
Cutting-edge technological advancements meet daily ~
