

About 3100 words, suggested reading time: 10 minutes
This article will introduce several latest large models suitable for private deployment, and then guide you step-by-step to deploy them on computers and mobile phones.
Large models are undoubtedly the protagonists of this AI revolution,large models are based on Scaling Law. Simply put, the more data, the larger the parameters, the stronger the computing power, the greater the model’s ultimate capability. As the scale of model parameters and pre-training data increases, the model’s capabilities and task performance continue to improve, demonstrating some ’emergent abilities’ that small-scale models do not possess.
As the era of large models gradually approaches, cutting-edge large model technologies represented by ChatGPT are gradually demonstrating their significant value in various fields such as economy, law, and society. At the same time, numerous AI companies are launching open-source large models, which are experiencing exponential growth in scale following the scaling law.
However, an undeniable trend is that the size of large models is gradually being streamlined, making private deployment possible. This demand is particularly important in scenarios with high requirements for personal privacy protection. Imagine an AI robot that can deeply understand your various data, running directly on your device without the need to transmit data over the network, providing you with decision support; this undoubtedly greatly enhances user trust. If such an AI only exists on the company’s ‘cloud server’, although it has stronger performance, its security and reliability become concerning.
This article will introduce several latest large models suitable for private deployment, and then guide you step-by-step to deploy them on computers and mobile phones.However, to be frank, do not have overly high expectations for ‘locally deployed large models’ at this stage. So let’s get started!
1. Open-source Large Models
Currently popular large models, such as ChatGPT and Bard, are built on proprietary closed-source foundations, which undoubtedly limits their use and leads to a lack of transparency in technical information.
However, open-source AI large models (LLMs) are gradually emerging, enhancing data security and privacy protection, saving costs for users, reducing external dependencies, and achieving code transparency and model customization. Here, I will focus on Meta’s Llama 3 and Microsoft’s Phi 3, which are considered top-tier open-source large models, both being ‘small yet beautiful’ and easy to deploy.
1. Llama 3
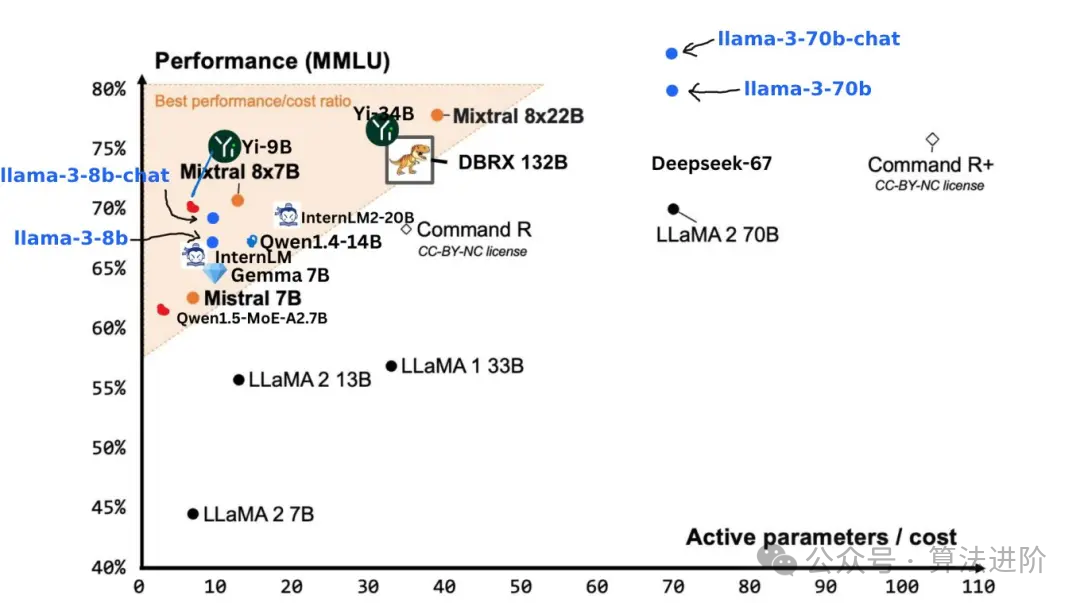
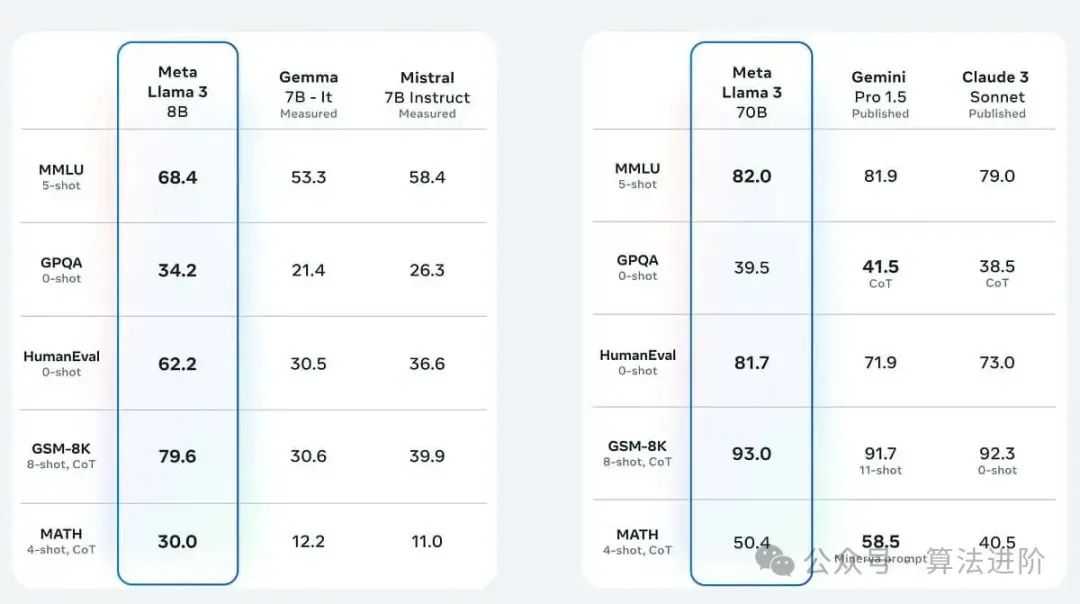
Meta has released two open-source models, Llama 3 8B and Llama 3 70B, for external developers to use for free. Meta claims that Llama 3 8B and Llama 3 70B are currently the best-performing open-source models of their size.

LLaMA is the top-tier open-source model, and many large models in China are derived from its construction! It has been fine-tuned using Reinforcement Learning from Human Feedback (RLHF). It is a generative text model that can be used as a chatbot and can adapt to various natural language generation tasks, including programming tasks. From the benchmark tests shared, Llama 3 400B+ is almost comparable to Claude’s large cup and the new GPT-4 Turbo. Although there is still a certain gap, it is enough to prove its place among the top large models.
GitHub project address: https://github.com/meta-llama/llama3
2. Phi-3
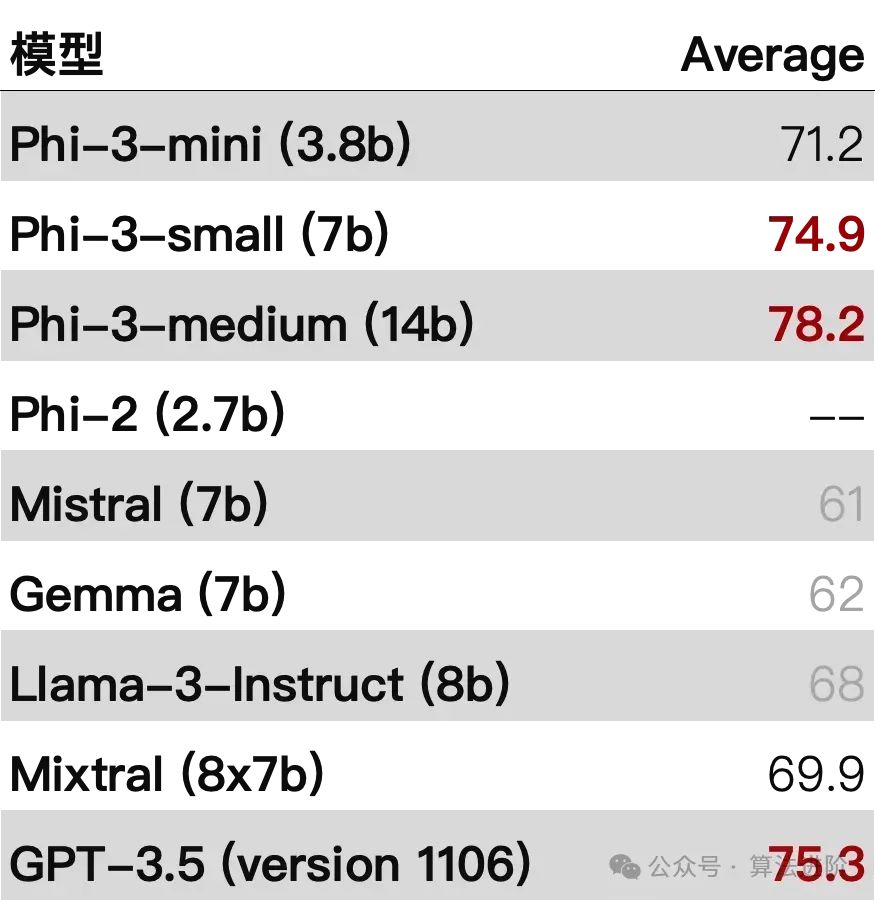
Phi is a new open-source small language model launched by Microsoft’s AI research institute, suitable for commercial use, with advantages in its small size and low resource requirements. The model includes Phi-3-Mini, Phi-3-Small, and Phi-3-Medium in three scales. Phi-3-Mini has only 3.8B parameters but performs excellently in key benchmark tests, comparable to large models like Mixtral 8x7B and GPT-3.5. The larger Small and Medium versions perform even better with expanded dataset support.“Phi-3 Technical Report: A Large Model That Can Run on Mobile Phones”: https://arxiv.org/abs/2404.14219
Summary
From benchmark tests, both Llama 3 8B and Phi3 3.8B small models perform well; they are not only small in scale but also have certain similarities in optimization methods.
Three factors determine the performance of large models: framework, data, and parameters. Since the parameters are fixed to a small scale, it is meaningless to do MOE under such small parameters; therefore, they mainly focus on the data factor, improving the quantity or quality of data to enhance the performance of small models. This also provides a direction for streamlining large models in the future!
2. Process for Deploying on Computer
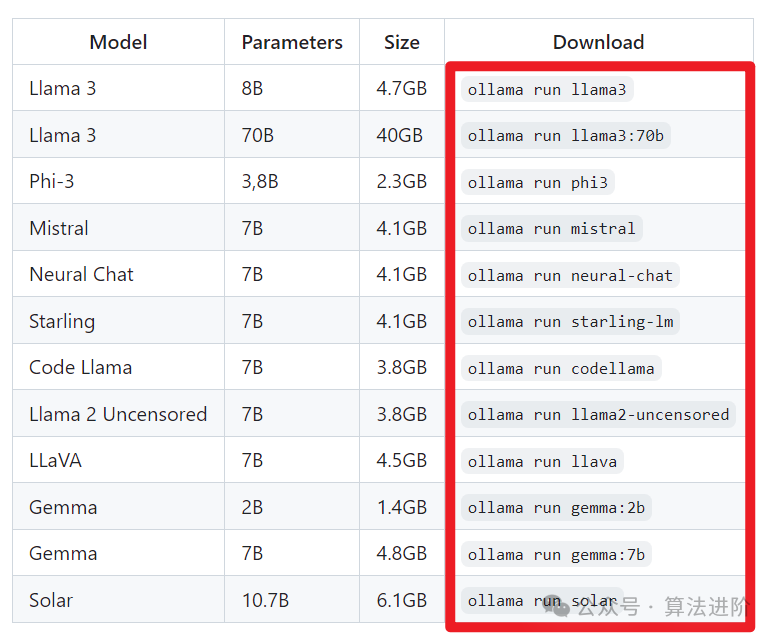
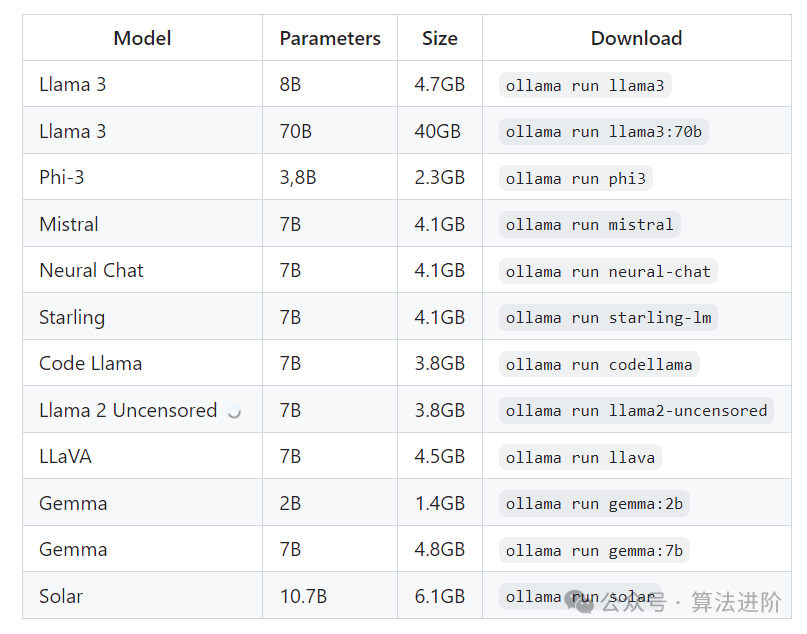
First, let me introduce a tool for deploying large models: Ollama, which supports the startup and operation of large language models like Llama 3, Mistral, Gemma, etc.
By using Ollama to deploy large models on a computer, it basically takes just two simple steps: 1. Download and install Ollama 2. Run the large model (done)
Taking Windows as an example, first go to the official website or obtain it at the end of this article. After downloading Ollama, just confirm all the way to finish the installation.
Official download link https://github.com/ollama/ollama
After installing Ollama, open the command line, run the command 【ollama run llama3】, and you can download and run the llama3 large model (the running commands for other models are as above). The initial download of the model may be slow, but once downloaded, you can happily chat.
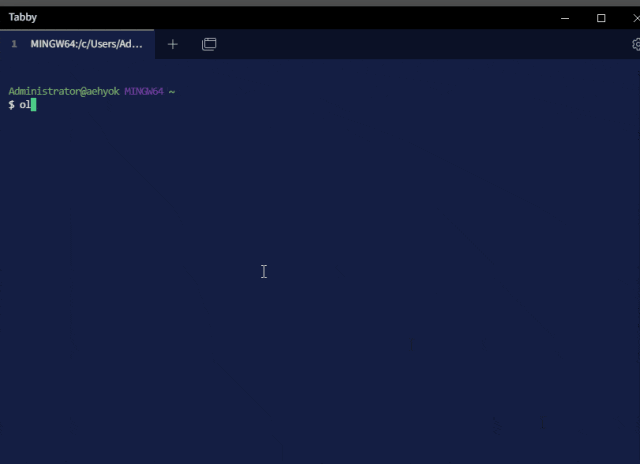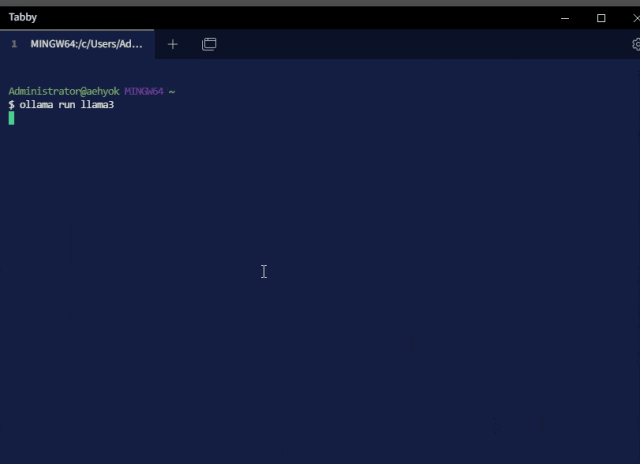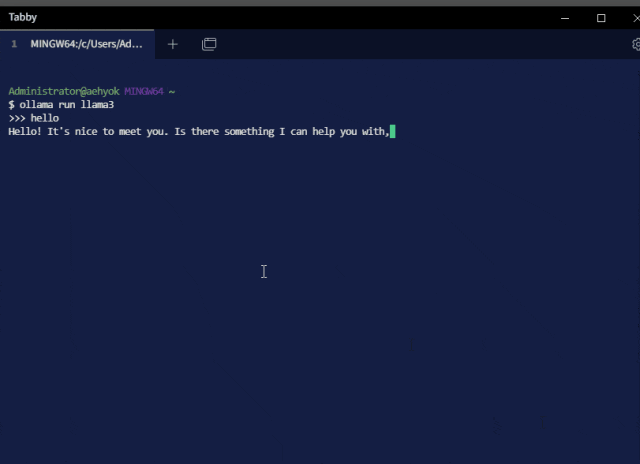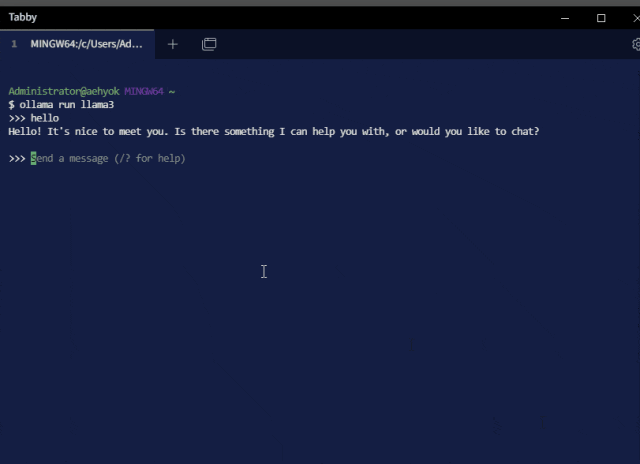
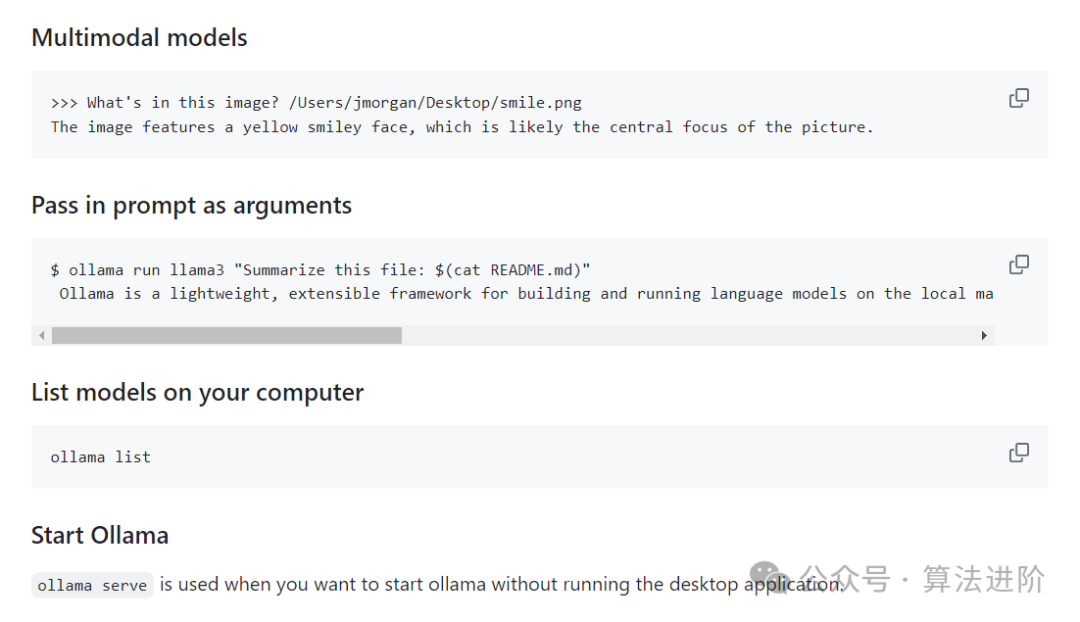
Ollama also supports other features such as image and other multimodal input, passing in prompts to train the model, etc. For details, please refer to the documentation.
3. Process for Deploying on Mobile
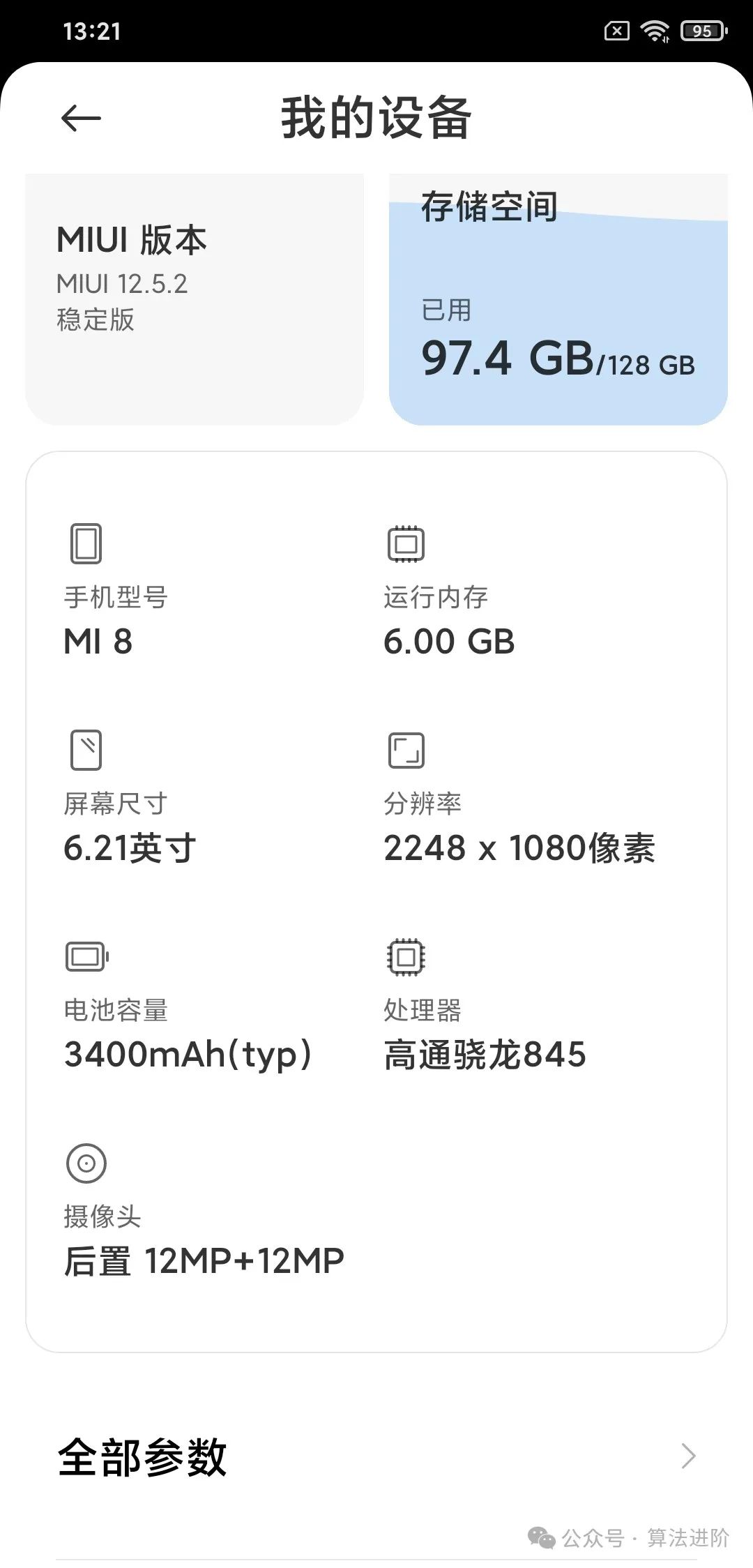
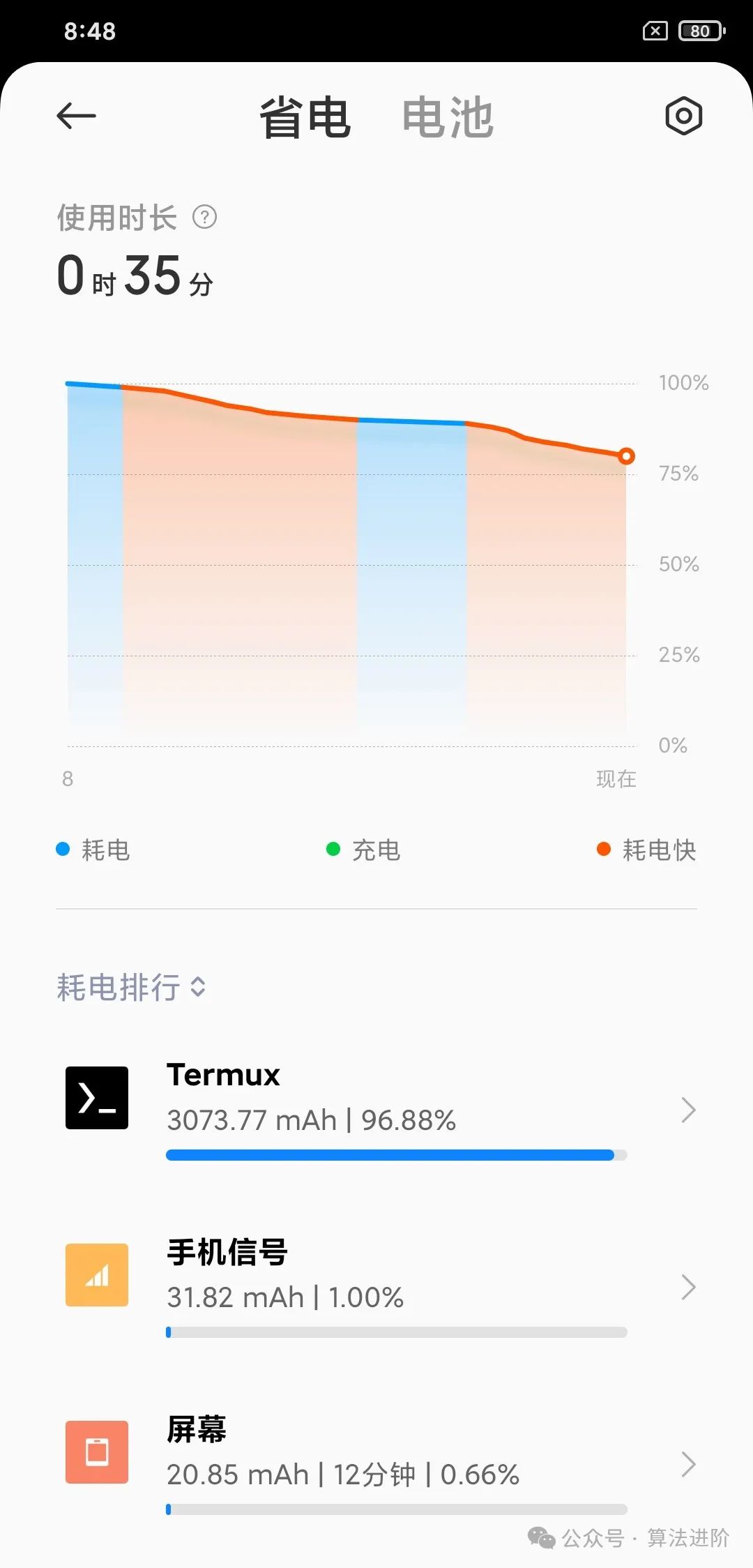
Compared to computers, deploying large models on mobile devices is actually more significant, as mobile phones are more closely related to everyone’s life, and there is a lot of personal data on mobile devices that facilitate subsequent interactions. Nowadays, everyone might have several idle phones, and if the phone’s performance is decent, running a large model is still quite cool. My old phone is a Xiaomi 8, and its performance is still acceptable~ (Lei Jun, please send money).
However, deploying on mobile can be a bit tricky, similar to computer deployment, but requires first setting up a Linux environment on the phone. Although Android phones are based on the Linux kernel, reinstalling Linux can be quite challenging. Fortunately, I discovered another tool: Termux, which is a terminal emulator on Android that allows you to run many Linux commands and tools on Android devices. The Termux app can be downloaded from the F-Droid official website or obtained at the end of this article.
Official download link: https://github.com/termux/termux-app/releases
After installation, opening Termux looks like the following image. (If you want to open multiple Linux windows, swipe right on the top left and click New session).
Next, you can deploy large models on your phone using Termux + Ollama:
Step 1: Use proot-distro in Termux to install a Linux system. (proot-distro allows users to install, uninstall, and run various Linux distributions in Termux, including Ubuntu, Debian, Arch Linux, etc. This way, users can use a complete Linux environment on their Android devices, including installing and running Linux software packages.)
// First, install proot-distro
pkg install proot-distro
// Use proot-distro to install Debian
proot-distro install debian
// After successful installation, use the login command to directly enter Debian and start a root shell for the distribution
proot-distro login debianStep 2: Follow the same process as on the computer, install Ollama, download and run the large model.
// After entering, install ollama
curl -fsSL https://ollama.com/install.sh | sh
// After installation, check the ollama version for verification; once the version number appears, you can use ollama
ollama -v
// Start the ollama service in the background
nohup ollama serve &
// Run the large model (the commands for other models are as shown below; you can check the models using ollama list)
ollama run phi3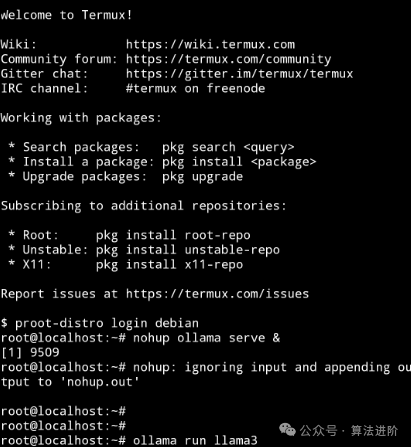
The first time you need to download and run the software and large model will take a bit longer, around an hour. (After installation, for subsequent uses, just run the above login debian system, start the Ollama service, and run the large model to use it.)
Running code on a mobile phone feels uniquely interesting. Inputting lines of code in a rudimentary way and watching the screen output bit by bit feels really cool. Interested students can install remote software like Tailscale or todesk, and coding remotely on a computer would be even more enjoyable. (The downside is that mobile computing power is limited, making large model responses slow and consuming more battery.)
4. Experience with Local Large Models
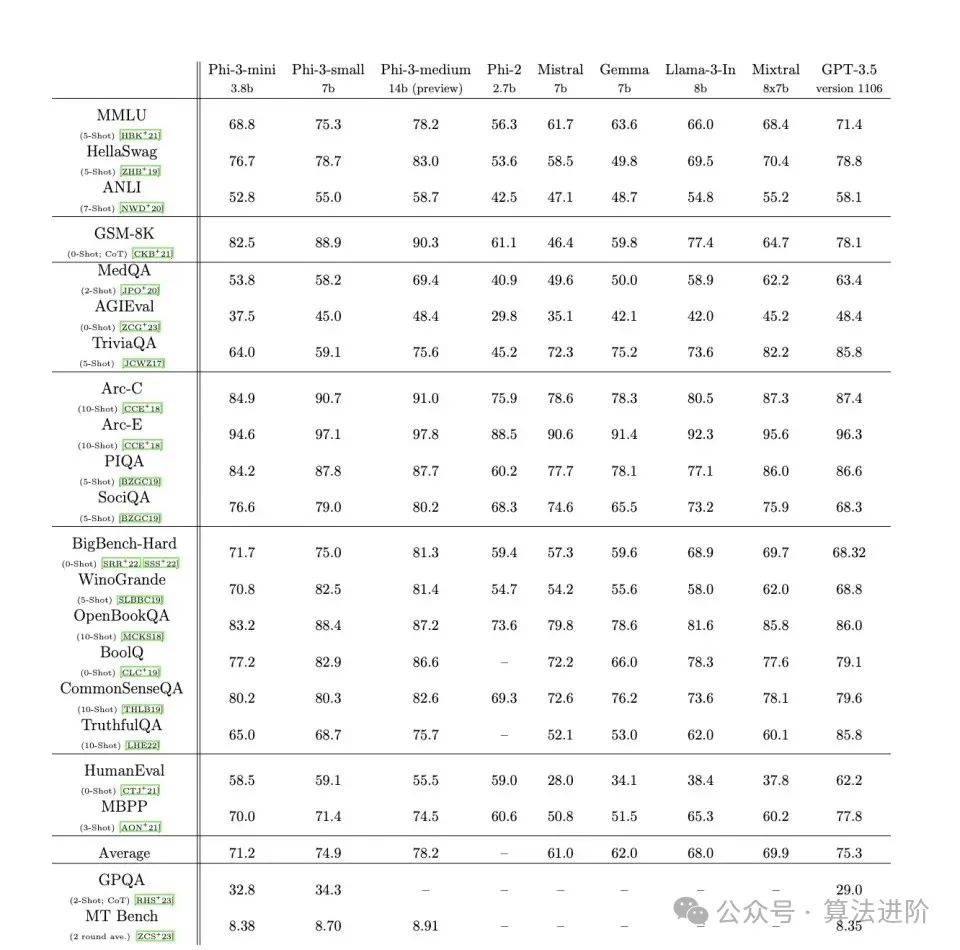
Model performance: The authoritative data on large model performance can be found in some related evaluations, as shown in the following image.
Here, I simply tested the locally deployed large models (llama3, Phi3) on my phone and shared my personal experience. Overall, Llama 3 performs more consistently across various aspects, while Phi may sometimes have errors but responds faster; overall, Phi feels more user-friendly.
Response Speed: Due to the limitations of local phone and computer performance, if the computer has a GPU, the response may be better. However, mobile responses are really slow; waiting for a few minutes might only yield a few words. It is quite noticeable that Phi3 responds faster than Llama3, while in terms of model scale, Llama 3 8B is roughly twice that of Phi3 3.8B.
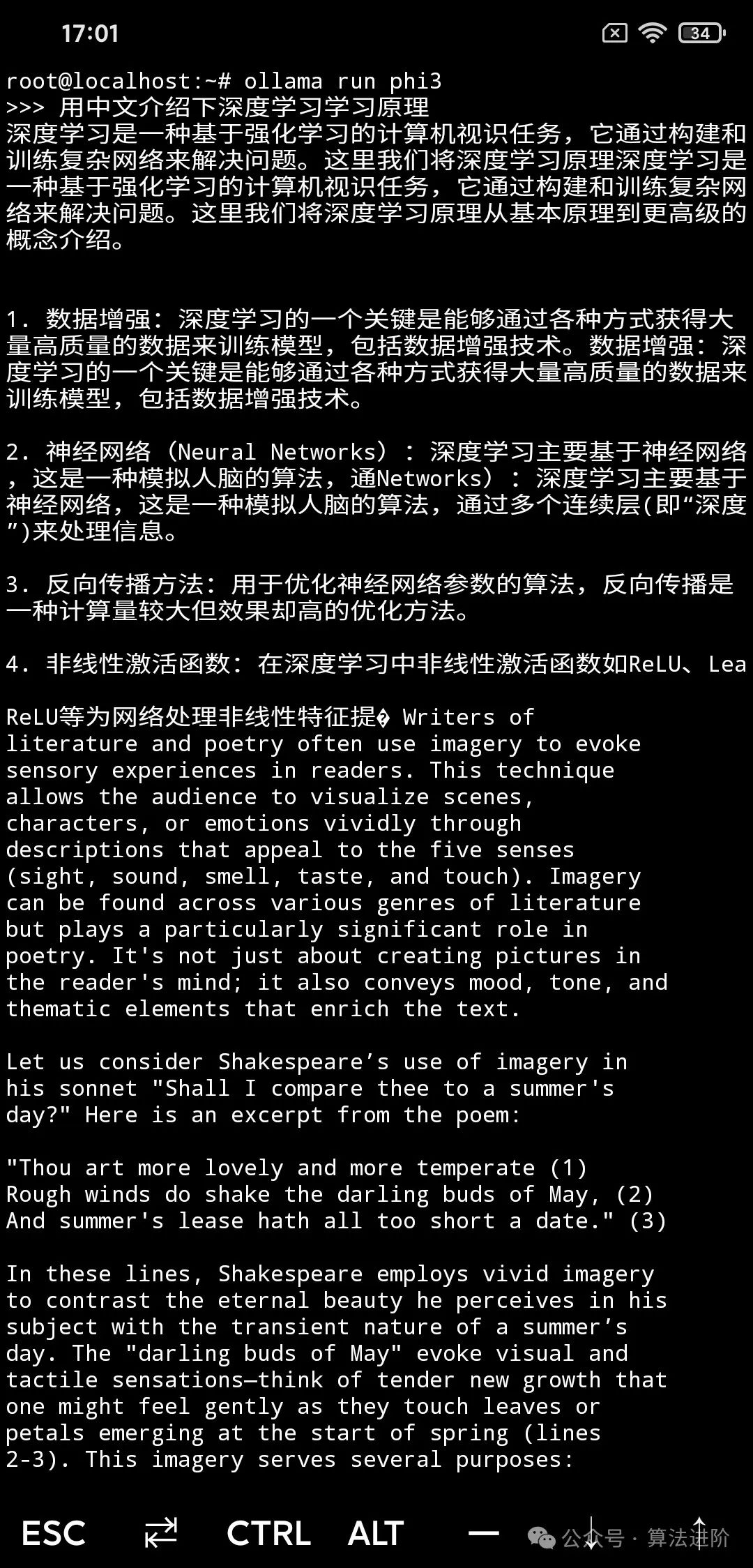
Chinese Language Ability: Chinese is definitely a weak point for these open-source models; when asking less common questions, they start speaking English midway. Many Chinese expressions are unclear, and asking them to tell a joke often results in awkwardness.
But this is unavoidable; after all, the underlying reason is that high-quality Chinese datasets are far less than English ones, and this difference in data will certainly be amplified later on. For tasks in Chinese, Llama tends to perform slightly better than Phi3. Interested users can also try Llama’s Chinese variant, Llama3-Chinese.
Llama 3
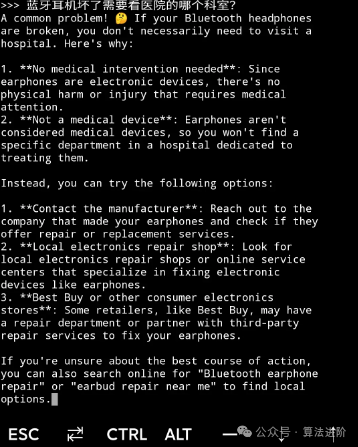
Phi 3

Code Ability: They look decent, but Phi3 still has some syntax errors.
Llama 3
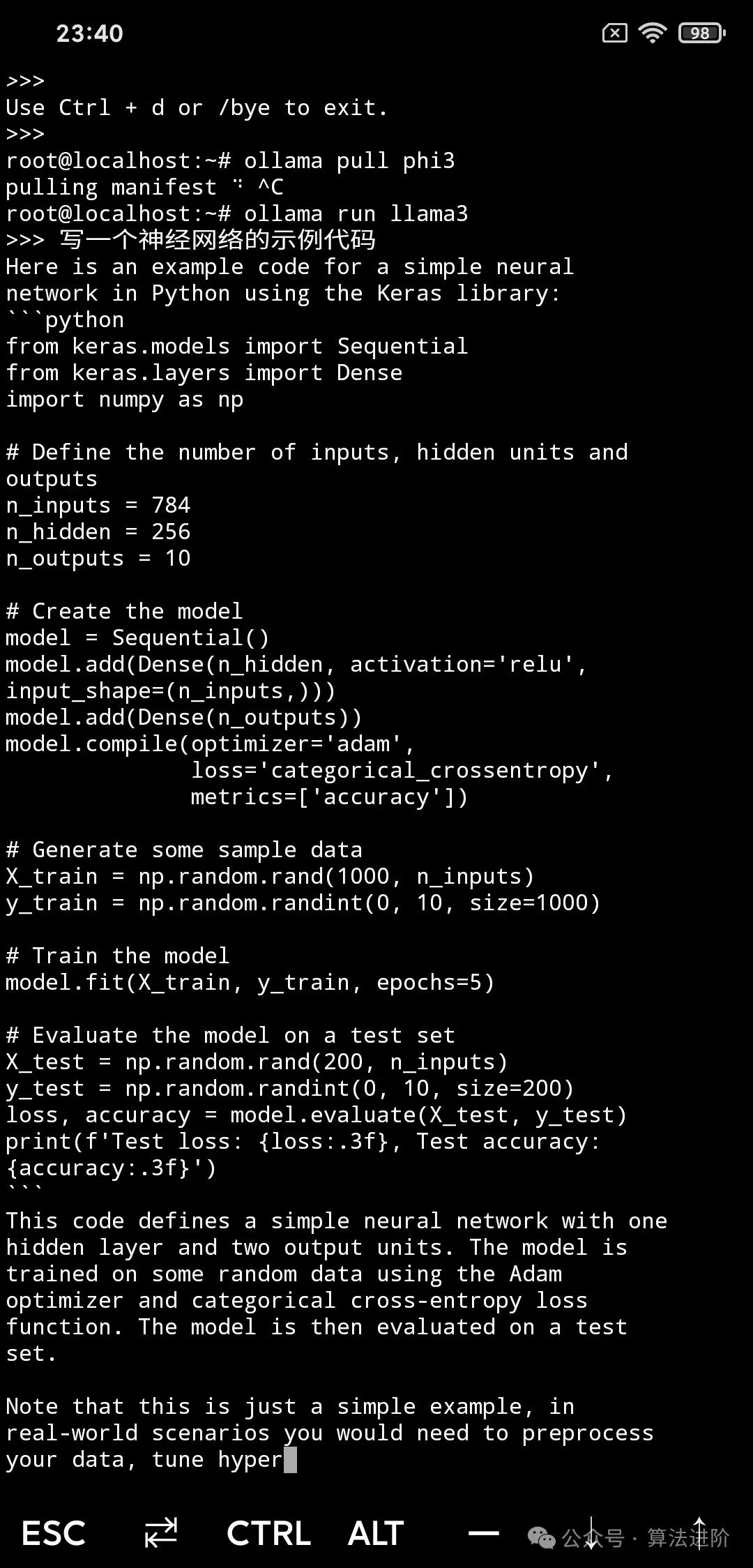

Phi 3
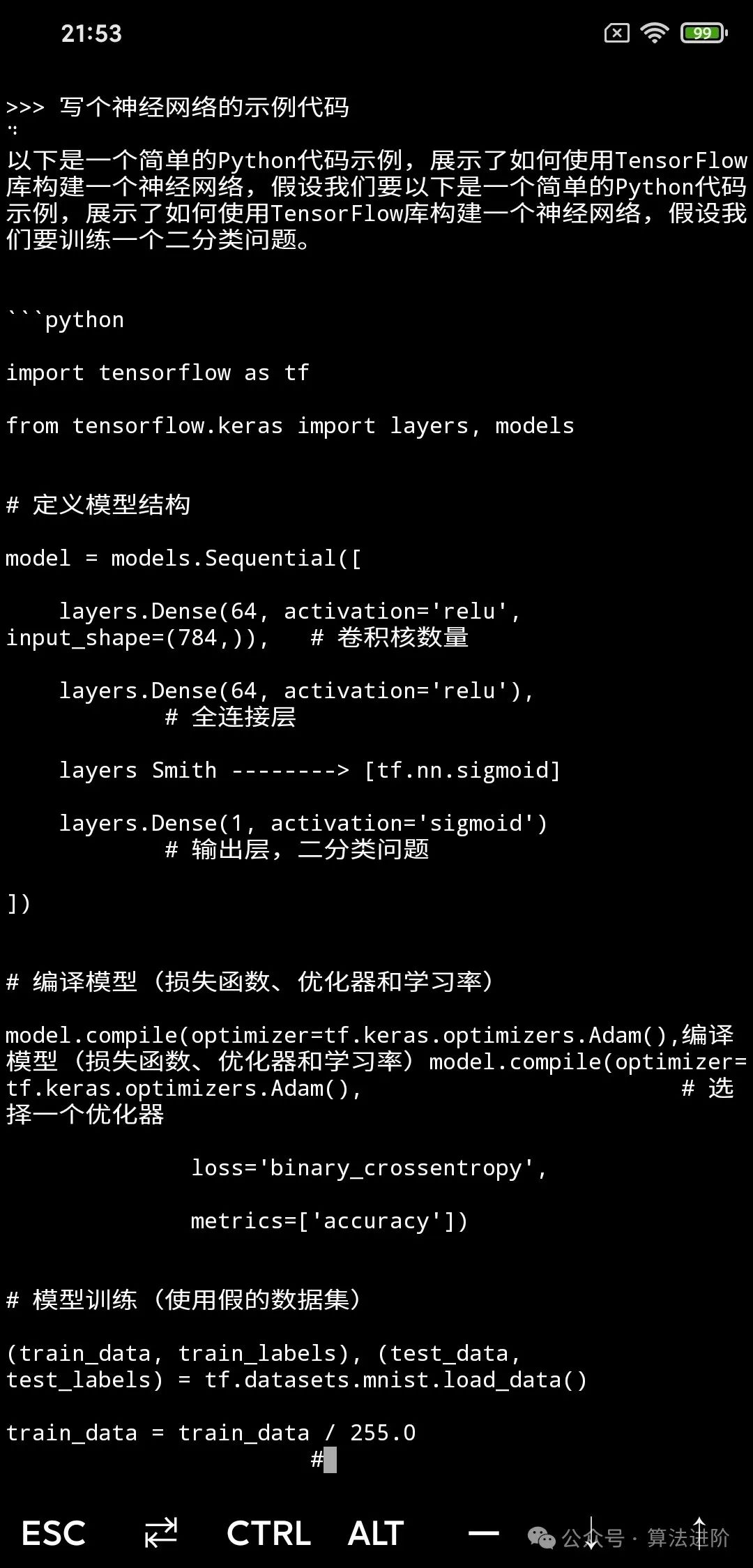
Mathematical Reasoning: Both look quite good, but Phi3 seems better.
Llama 3
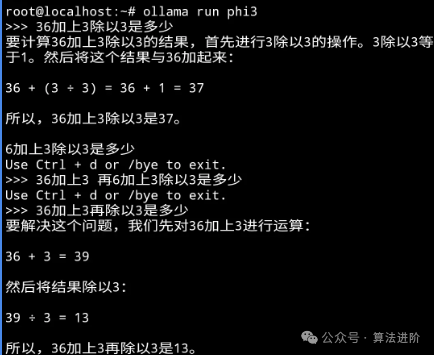
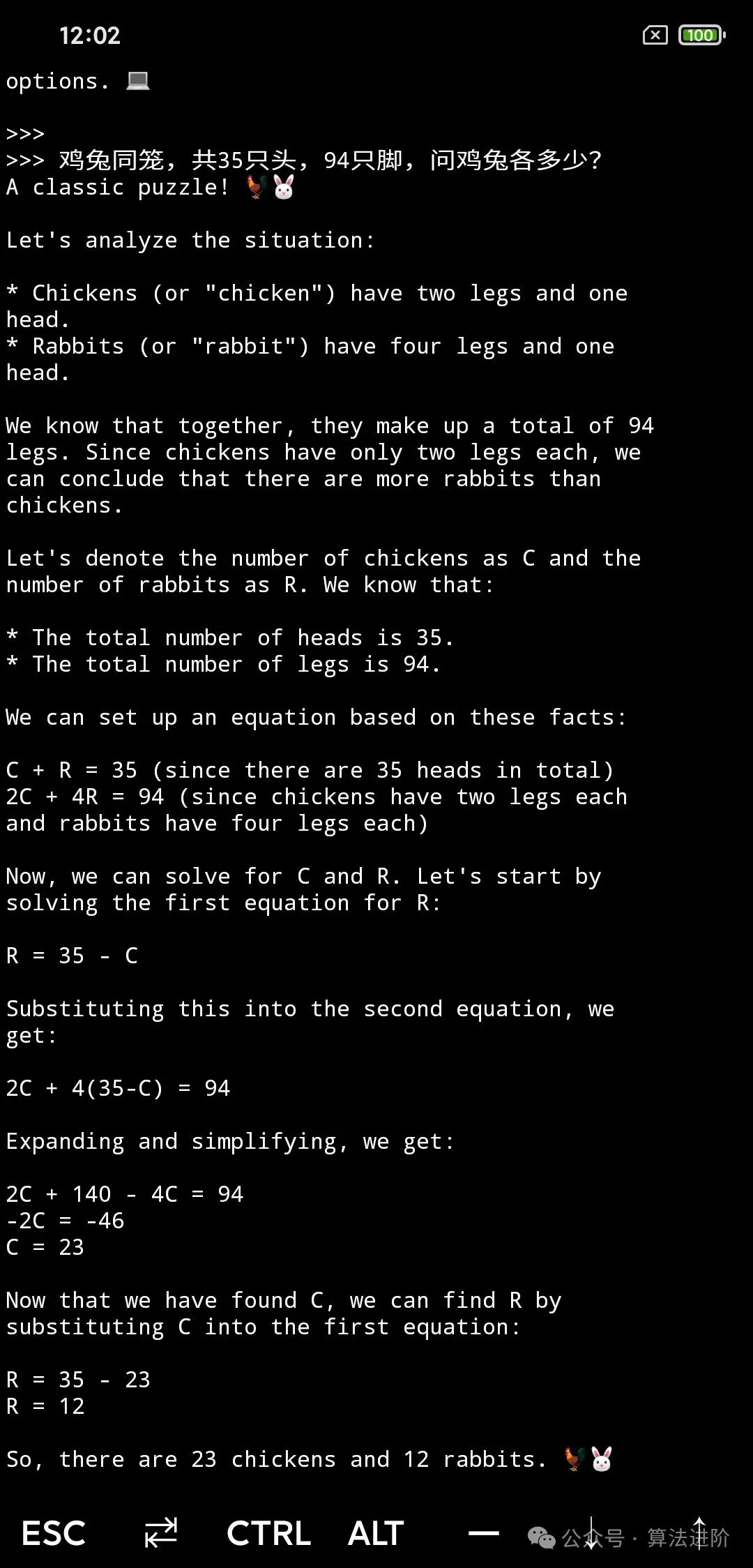
Phi 3
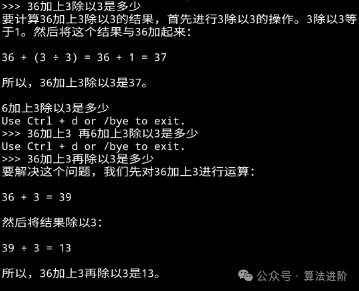

Security: Both have good compliance awareness.
Llama 3

Phi 3

5. Conclusion
In conclusion, although the application of AI is still relatively scarce, the development of technology requires time, and the high inference costs of large models limit their practicality. However, with small models like Llama 3 and Phi 3, the path to practical large models becomes clearer. Although the training costs of small models are high, the inference costs are low, making them overall more cost-effective, especially when serving a large number of users. High-performance small models enable AI to break free from cost constraints and be effectively applied in various scenarios. An AI that can be customized and deployed locally is undoubtedly exciting!
Believe that in the future, with model optimization and the enhancement of computing power brought by custom AI chips, more ‘small yet beautiful’ AI large models will soon be popularized in our lives!
This concludes the article; have fun, and don’t forget to like! If you have any questions, feel free to leave a comment!
Editor: Huang Jiyan