
It is recommended to click on the original text at the bottom of the article for a better reading experience, including displaying external links and viewing high-definition illustrations.
In the article that introduces MCP (Model Context Protocol), we quickly covered the basic concepts of MCP and provided an example to give readers an initial feel for the powerful capabilities of MCP. This article will delve deeper, guiding readers step by step on how to develop a complete MCP Server. The complete code for this article can be found here: GitHub Repository.
Core Primitives of MCP Server
The Model Context Protocol (MCP) is a protocol specifically designed for applications of LLM (Large Language Model), allowing you to build servers that securely and standardly expose data and functionalities to LLM applications. The MCP Server provides three core primitives, each with its specific uses and characteristics:
-
Tool allows the server to expose executable functions that can be called by clients and used by LLM to perform operations. Tools not only enable LLM to obtain information from external sources but also allow writing or operations, providing LLM with real actionable capabilities. -
Model Control: Tool directly exposes executable functions to LLM, allowing the model to actively call them.
-
Resource represents any type of read-only data that the server wishes to provide to clients. This may include file content, database records, images, logs, etc. -
Application Control: Resource is managed by clients or applications to provide contextual content for LLM.
-
Prompt is a reusable template defined by the server, which users can select to guide or standardize interactions with LLM. For example, the Git MCP Server can provide a “Generate Commit Message” prompt template that users can use to create standardized commit messages. -
User Control: Prompts are usually selected by users themselves.
Elasticsearch MCP Server Example
Next, we will demonstrate the specific uses of Tool, Prompt, and Resource by building an Elasticsearch MCP Server.
Starting Elasticsearch Cluster with Docker Compose
Execute the <span>docker-compose up -d</span> command to start a 3-node Elasticsearch cluster in the background, providing Kibana for managing and visualizing Elasticsearch.
Access the Kibana interface by entering http://localhost:5601 in your browser, with username <span>elastic</span> and password <span>test123</span>.
Preparing Test Data
Open the <span>Management -> Dev Tools</span> page in Kibana and execute the following code to create two indices <span>student</span> and <span>teacher</span>, inserting several data entries respectively:
POST /student/_doc
{
"name": "Alice",
"age": 20,
"major": "Computer Science"
}
POST /student/_doc
{
"name": "Bob",
"age": 22,
"major": "Mathematics"
}
POST /student/_doc
{
"name": "Carol",
"age": 21,
"major": "Physics"
}
POST /teacher/_doc
{
"name": "Tom",
"subject": "English",
"yearsOfExperience": 10
}
POST /teacher/_doc
{
"name": "John",
"subject": "History",
"yearsOfExperience": 7
}
POST /teacher/_doc
{
"name": "Lily",
"subject": "Mathematics",
"yearsOfExperience": 5
}
Initializing the Project
In this tutorial, we will use the MCP Python SDK to write the project and use uv to manage Python project dependencies.
For installation instructions, please refer to Installing uv. MacOS users can install it using brew:
brew install uv
Execute the following command to initialize the project:
uv init elasticsearch-mcp-server-example
cd elasticsearch-mcp-server-example
Add dependencies:
uv add "mcp[cli]" elasticsearch python-dotenv
Create the <span>server.py</span> file, where we will write the code:
touch server.py
Installing MCP Server on Claude Desktop
Set the connection information for Elasticsearch in the <span>.env</span> file.
ELASTIC_HOST=https://localhost:9200
ELASTIC_USERNAME=elastic
ELASTIC_PASSWORD=test123
You can execute the following command to install the MCP Server on Claude Desktop:
-
<span>--env-file</span>parameter specifies the path of the<span>.env</span>file to load environment variables. -
<span>--with-editable</span>parameter specifies the directory where the uv dependency management file<span>pyproject.toml</span>is located, for installing project dependencies.
mcp install server.py --env-file .env --with-editable ./
This command will automatically help you add the MCP Server configuration to the <span>cluade_desktop_config.json</span> file.
{
"mcpServers": {
"elasticsearch-mcp-server": {
"command": "uv",
"args": [
"run",
"--with",
"mcp[cli]",
"--with-editable",
"/your/project/path/elasticsearch-mcp-server-example",
"mcp",
"run",
"/your/project/path/elasticsearch-mcp-server-example/server.py"
],
"env": {
"ELASTIC_HOST": "https://localhost:9200",
"ELASTIC_USERNAME": "elastic",
"ELASTIC_PASSWORD": "test123"
}
}
}
}
Next, we will start writing the relevant code for the Elasticsearch MCP Server.
Configuring Elasticsearch Client
First, create an Elasticsearch client to interact with the Elasticsearch server.
def create_elasticsearch_client() -> Elasticsearch:
# Load environment variables from .env file
load_dotenv()
url = os.getenv("ELASTIC_HOST")
username = os.getenv("ELASTIC_USERNAME")
password = os.getenv("ELASTIC_PASSWORD")
# Disable SSL warnings
warnings.filterwarnings("ignore", message=".*TLS with verify_certs=False is insecure.*",)
if username and password:
return Elasticsearch(url, basic_auth=(username, password), verify_certs=False)
return Elasticsearch(url)
Initializing FastMCP Server
The MCP Python SDK now provides a new FastMCP class, which leverages Python’s type hints and docstrings features to automatically generate tool definitions. This method allows developers to more conveniently create and manage MCP’s Tool, Resource, and Prompt components.
The following code creates a FastMCP object named <span>mcp</span>.
from mcp.server.fastmcp import FastMCP
MCP_SERVER_NAME = "elasticsearch-mcp-server"
mcp = FastMCP(MCP_SERVER_NAME)
Adding Tool
Tool defines the operations that LLM can call on the MCP Server; in addition to querying, it can also perform write operations. Next, we define two Tools:
-
<span>list_indices</span>: List all available indices. -
<span>get_index</span>: Get detailed information about a specified index.
Use the <span>@mcp.tool()</span> decorator to mark these two functions as MCP Tools.
@mcp.tool()
def list_indices() -> List[str]:
"""List all Elasticsearch indices"""
return [index["index"] for index in es.cat.indices(format="json")]
@mcp.tool()
def get_index(index: str) -> dict:
"""Get detailed information about a specific Elasticsearch index"""
return es.indices.get(index=index)
Then restart Claude Desktop; if everything is normal, you should see a hammer icon in the bottom right corner of the input box. Click the hammer icon to see the tool information provided by the Elasticsearch MCP Server.
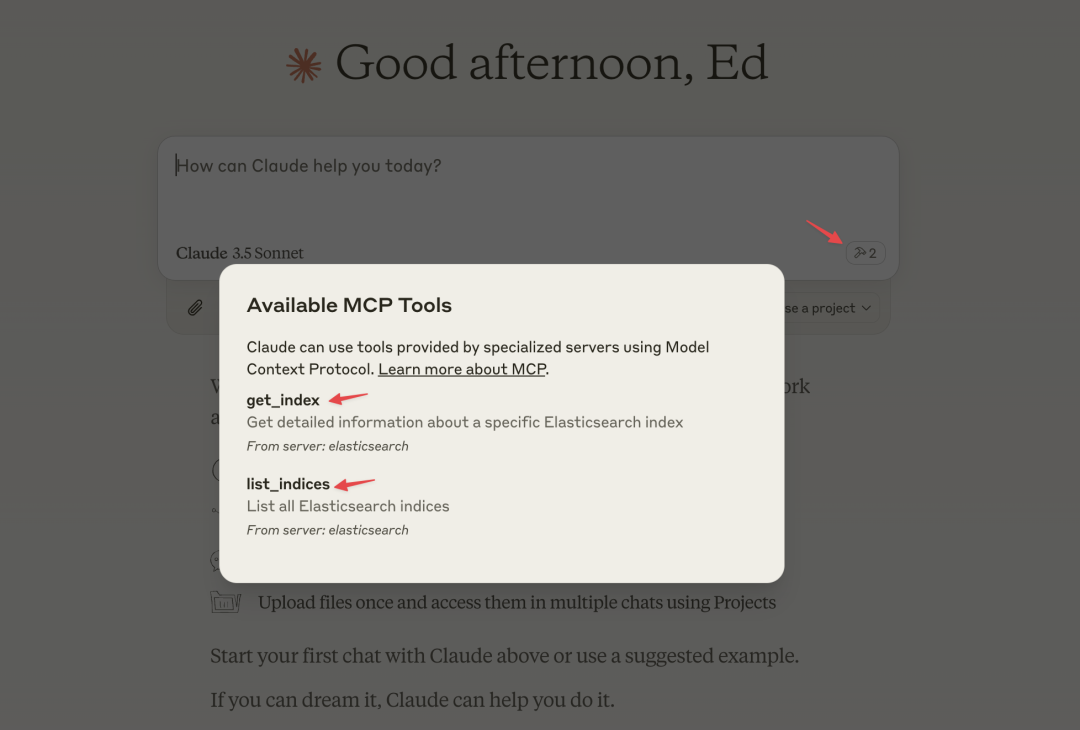
We can ask about the data in Elasticsearch, for example:
What indices are there in Elasticsearch? You can see that Claude called <span>list_indices</span> to list all indices.

What fields are there in the student index? You can see that Claude called <span>get_index</span> to get information about the student index.
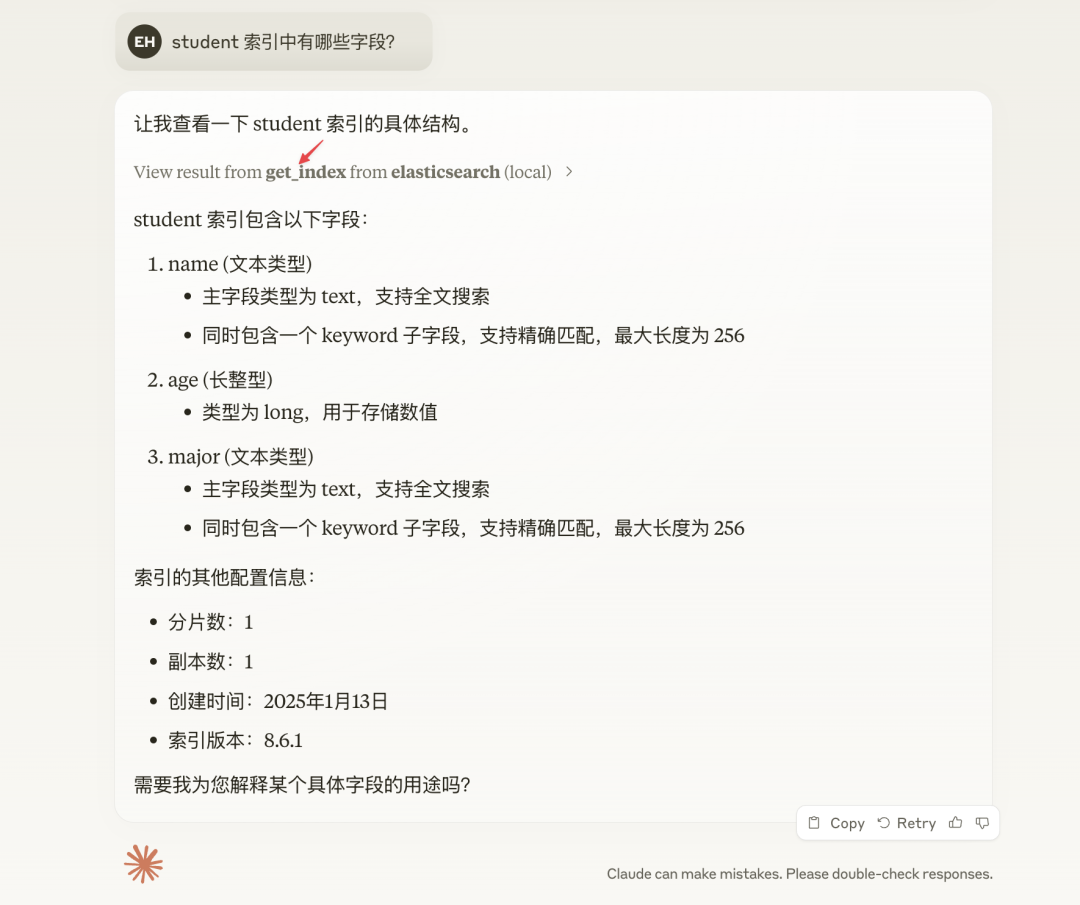
Resource
Resource defines read-only data sources that LLM can access, which can be used to provide contextual content for LLM. In this example, we define two resources:
-
<span>es://logs</span>: Allows LLM to access log information from the Elasticsearch container, retrieving log content through Docker commands. -
<span>file://docker-compose.yaml</span>: Allows LLM to access the content of the project’s<span>docker-compose.yaml</span>file.
@mcp.resource("es://logs")
def get_logs() -> str:
"""Get Elasticsearch container logs"""
result = subprocess.run(["docker", "logs", "elasticsearch-mcp-server-example-es01-1"], capture_output=True, text=True, check=True)
return result.stdout
@mcp.resource("file://docker-compose.yaml")
def get_file() -> str:
"""Return the contents of docker-compose.yaml file"""
with open("docker-compose.yaml", "r") as f:
return f.read()
Use the @mcp.resource() decorator to mark these functions as MCP Resources; the decorator parameters specify the URI of the Resource.
Resources should follow the URI identification format as follows:
[protocol]://[host]/[path]
The protocol and path structure of the URI is defined by the MCP Server implementation.
Restart Claude and click the plug icon to see the Resources provided by the Elasticsearch MCP Server.
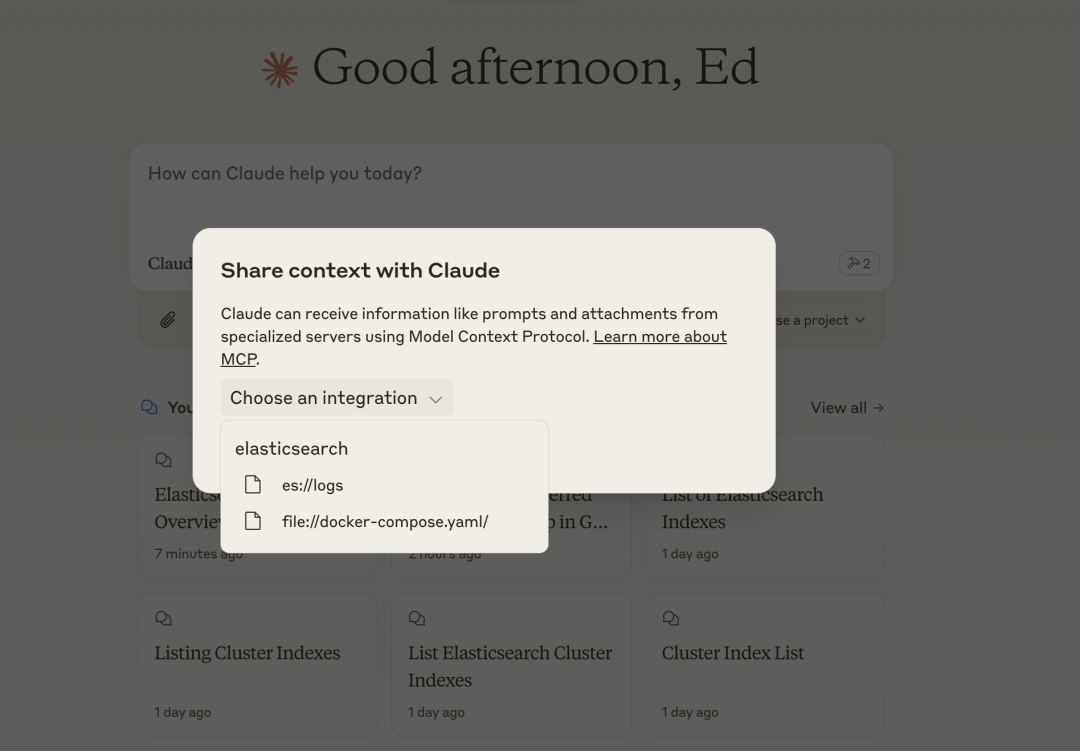
Next, we can choose Resource as the context for questioning, allowing LLM to respond.
-
Select <span>es://logs</span>, then ask:Analyze the logs.
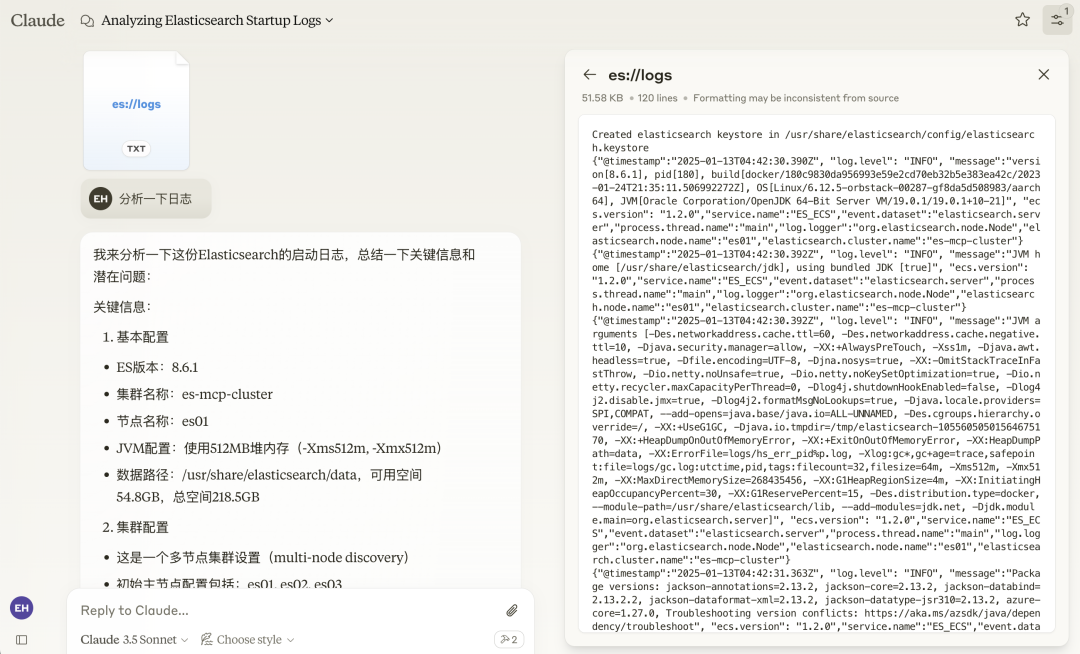
-
Select <span>file://docker-compose.yaml</span>, then ask:What containers are defined in the file?
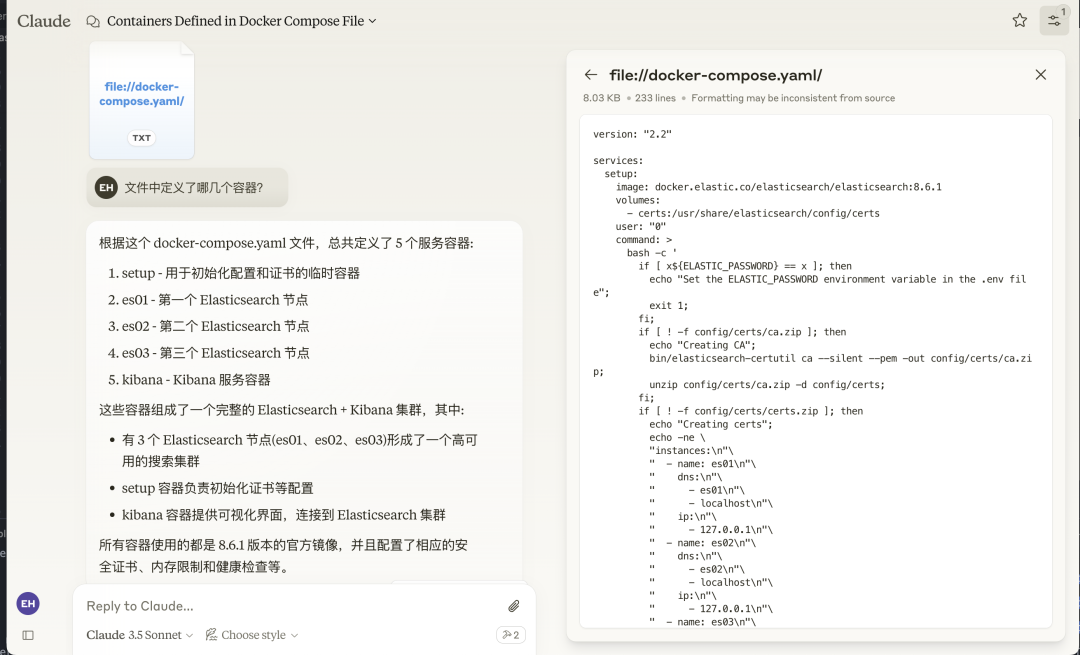
Prompt
Prompt is used to define reusable prompt templates, helping users better guide LLM to complete tasks in a standardized way. In this example, we define a prompt template named <span>es_prompt</span>, which guides LLM to analyze indices from multiple dimensions (such as index settings, search optimization, data modeling, and scalability).
@mcp.prompt()
def es_prompt(index: str) -> str:
"""Create a prompt for index analysis"""
return f"""You are an elite Elasticsearch expert with deep knowledge of search engine architecture, data indexing strategies, and performance optimization. Please analyze the index '{index}' considering:
- Index settings and mappings
- Search optimization opportunities
- Data modeling improvements
- Potential scaling considerations
"""
Restart Claude Desktop, click the plug icon, select <span>es_prompt</span>, and input the index to be analyzed <span>student</span>.
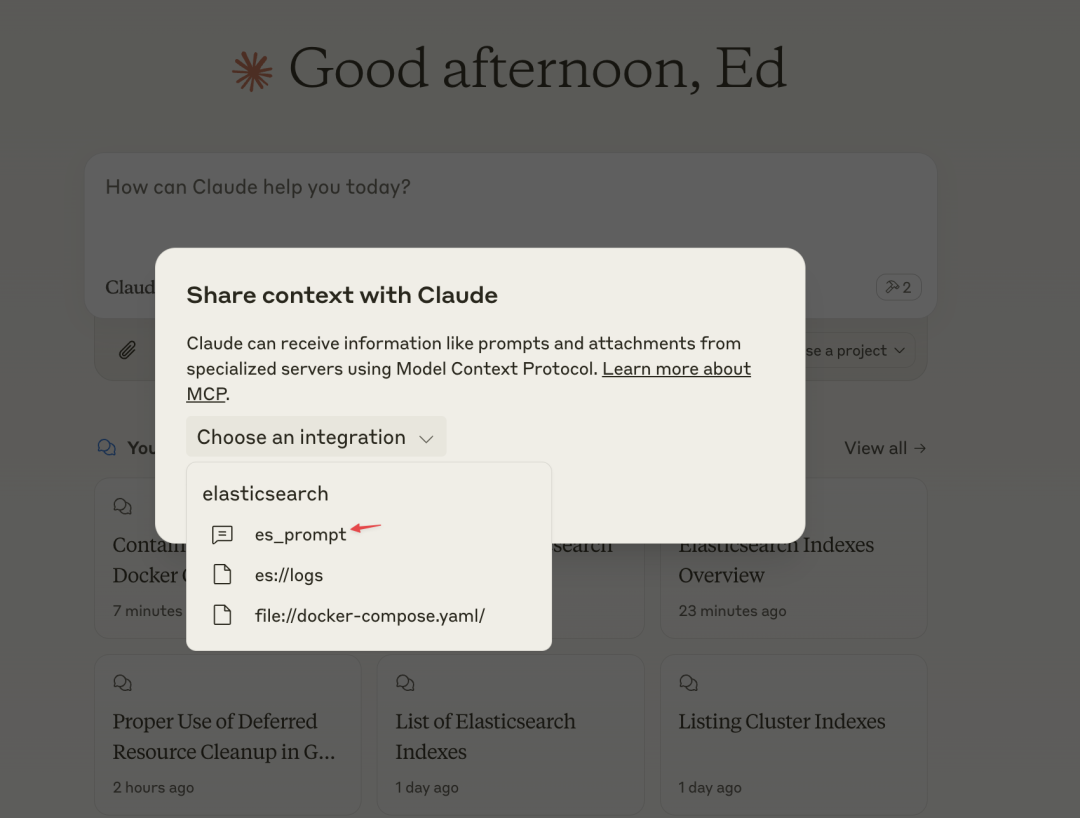
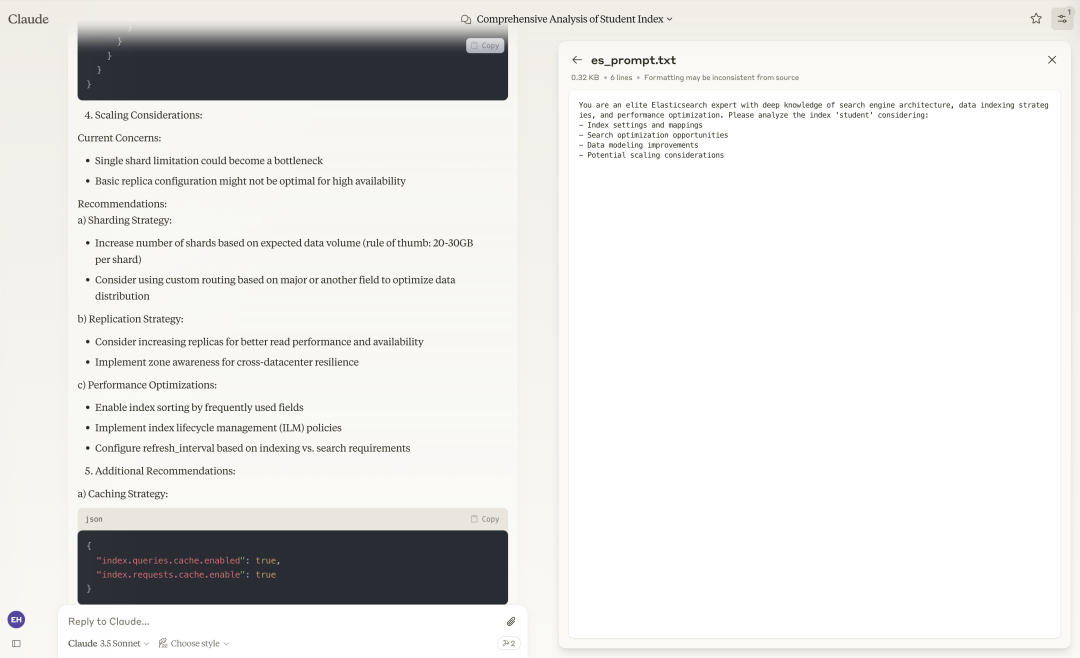
Claude will call the <span>get_index</span> Tool to obtain information about the <span>student</span> index and provide multiple dimension suggestions based on the prompt we provided.
Using MCP Inspector to Debug MCP Server
The MCP Inspector is an interactive developer tool specifically designed for testing and debugging MCP servers. It provides a graphical interface that allows developers to intuitively inspect and verify the functionalities of the MCP server.
Execute the following command to start the MCP Inspector:
mcp dev server.py
Once started successfully, browse to http://localhost:5173 to open the MCP Inspector interface. Click <span>Connect</span> to connect to the MCP Server.
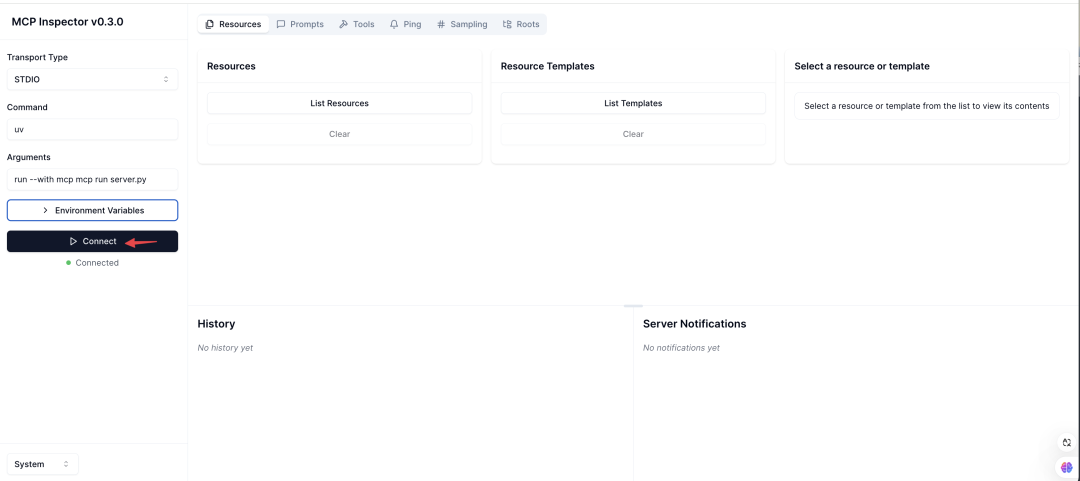
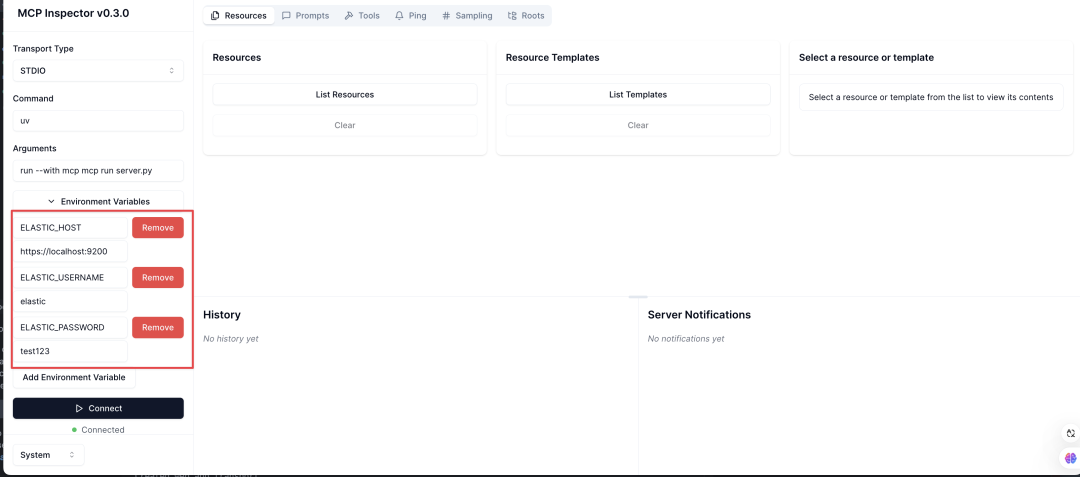
Add the connection information for Elasticsearch to the environment variables.
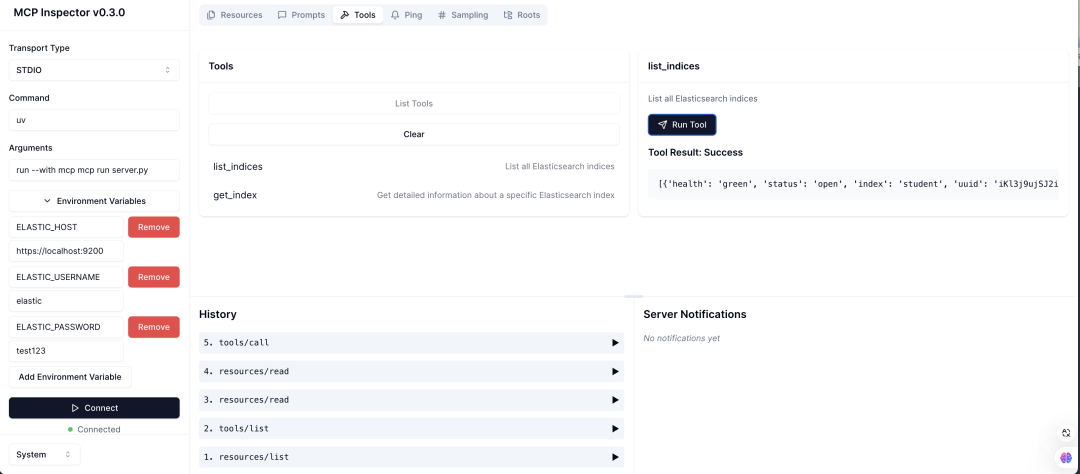
In the MCP Inspector, you can list and execute Resources, Tools, and Prompts.
Combined Example
Now suppose we have a requirement to read the movies.csv file and write documents into the movies index in Elasticsearch; if the movie’s box office exceeds 100 million dollars, set an additional field <span>isPopular: true</span> in the document, otherwise set it to <span>isPopular: false</span>.
In the past, we might have considered using the Elasticsearch Ingest Pipeline‘s Script processor to achieve this requirement.
Now we can provide the movies.csv file to LLM through Resource; LLM will compute the movie’s box office, then set the document’s <span>isPopular</span> field value, and finally call the <span>write_documents</span> Tool to write the document into the movies index in Elasticsearch. The implementation code is as follows:
@mcp.resource("file://movies.csv")
def get_movies() -> str:
"""Return the contents of movies.csv file"""
with open("movies.csv", "r") as f:
return f.read()
@mcp.tool()
def write_documents(index: str, documents: List[Dict]) -> dict:
"""Write multiple documents to an Elasticsearch index using bulk API
Args:
index: Name of the index to write to
documents: List of documents to write
Returns:
Bulk operation response from Elasticsearch
"""
operations = []
for doc in documents:
# Add index operation
operations.append({"index": {"_index": index}})
# Add document
operations.append(doc)
return es.bulk(operations=operations, refresh=True)
Restart Claude, select <span>file://movies.csv/</span> Resource, then send Claude the following instruction:Write the movies from the file into the movies index in Elasticsearch; if the movie’s box office exceeds 100 million dollars, set an additional field isPopular: true, otherwise set it to false.
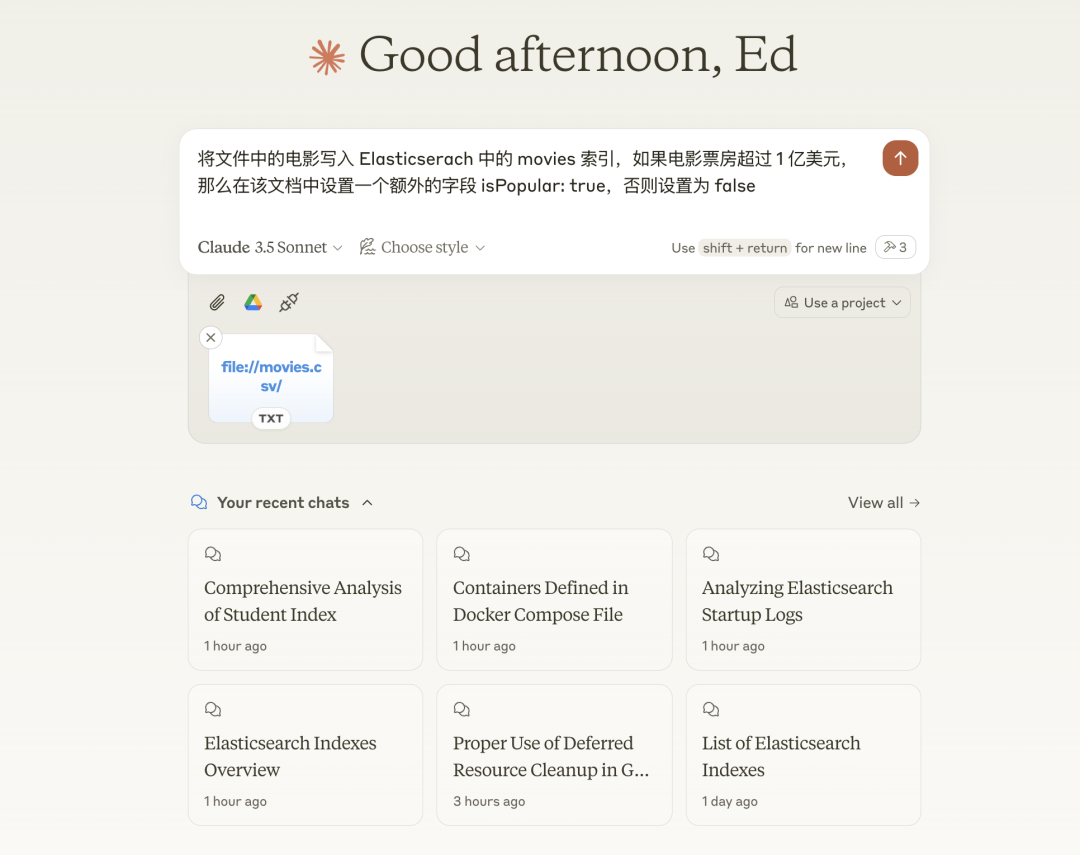
You can see that Claude successfully completed the task we specified.
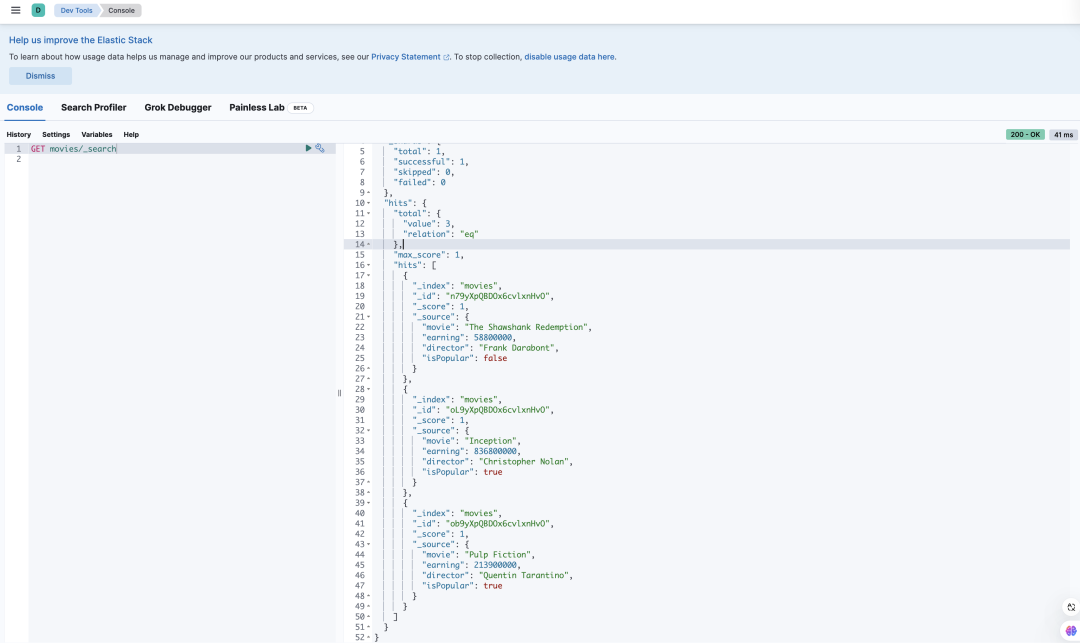
Query the <span>movies</span> index in Kibana, and you can see that our data has been successfully written, and the <span>isPopular</span> field has also been correctly set.
Conclusion
This tutorial demonstrates how to enhance the capabilities of LLM using the three core primitives of the MCP protocol (Tool, Resource, and Prompt) through the construction of an Elasticsearch MCP Server instance. Tool implements index operations and document writing, Resource provides access capabilities to data, while Prompt helps LLM complete tasks in a standardized manner. Finally, a practical combined example demonstrates how to enable LLM to utilize these components to accomplish more complex data processing tasks, fully reflecting the advantages of MCP in improving the efficiency of LLM application development.