LLM (Large Language Model) is a powerful new platform, but they are not always trained on data that is relevant to our tasks or the most recent data.
RAG (Retrieval Augmented Generation) is a general method that connects LLMs with external data sources (such as private data or the latest data). It allows LLMs to use external data to generate their outputs.
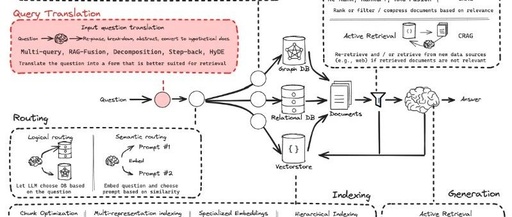
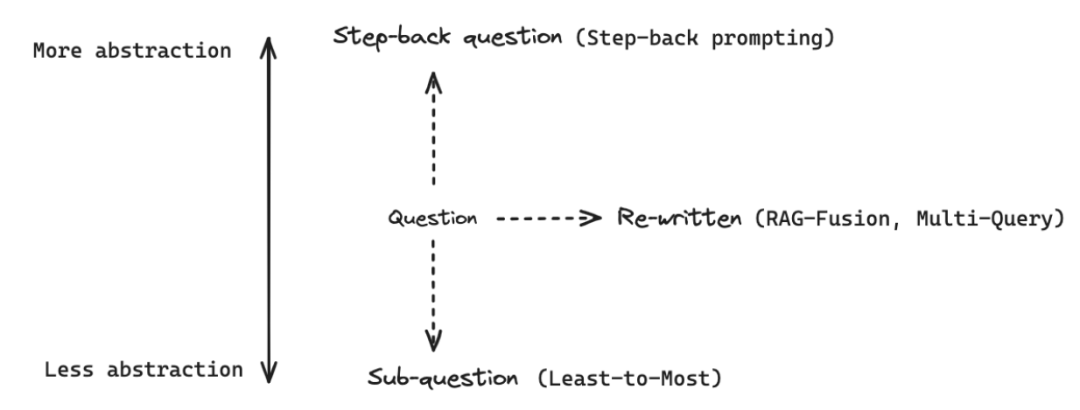
To truly master RAG, we need to learn the techniques shown in the figure below:
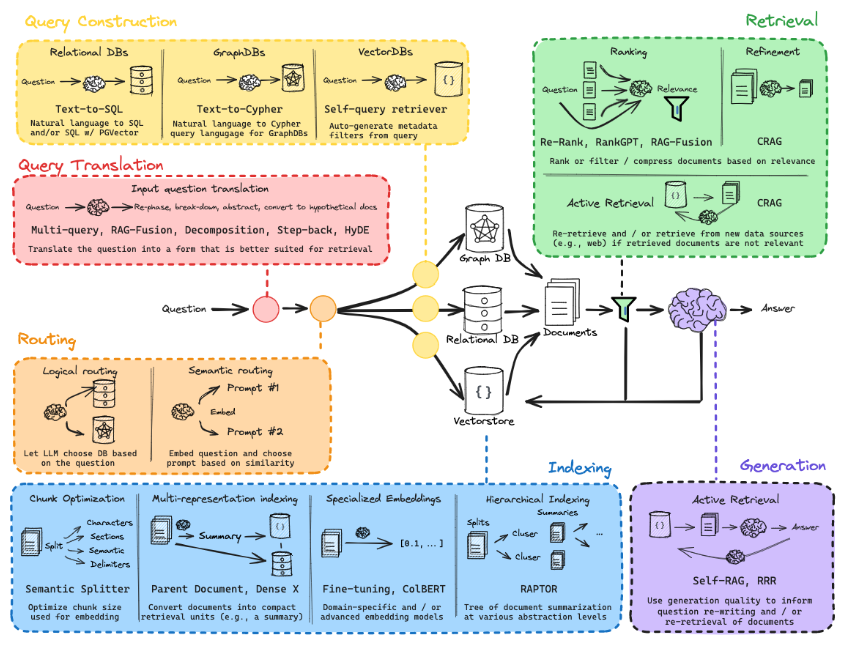
In the article “Mastering RAG Series 1: Basics of RAG”, I have already introduced the basic parts of RAG: Indexing, Retrieval, and Generation.
There is a classic saying in the field of machine learning: Garbage in, Garbage out.
This saying also applies to RAG, as the principle of our retrieval now is to search for relevant documents based on the semantics of the user’s Query (which is the Question).
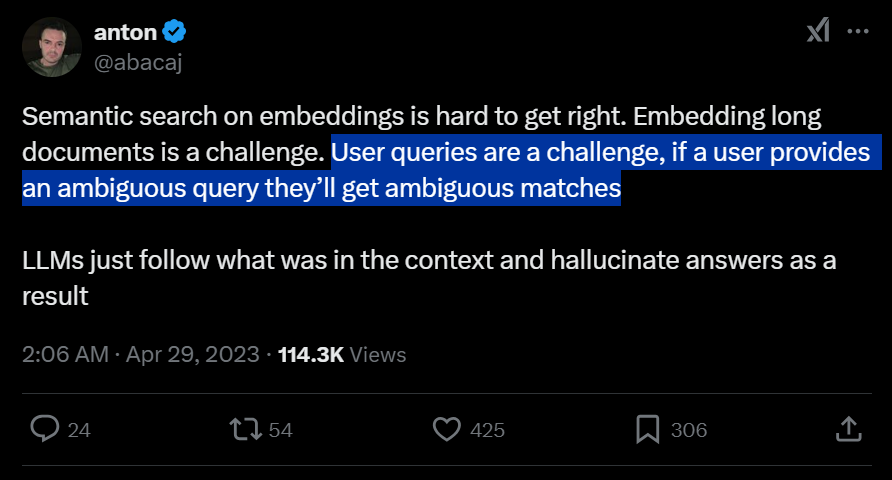
However, we cannot expect all users to clearly describe their Queries. If a user writes an ambiguous Query or a complex Query, the retrieved documents will also be ambiguous or difficult to retrieve accurately, leading to inaccurate answers from the LLM:
In this article, I will introduce the advanced technique of RAG: Query Translation:
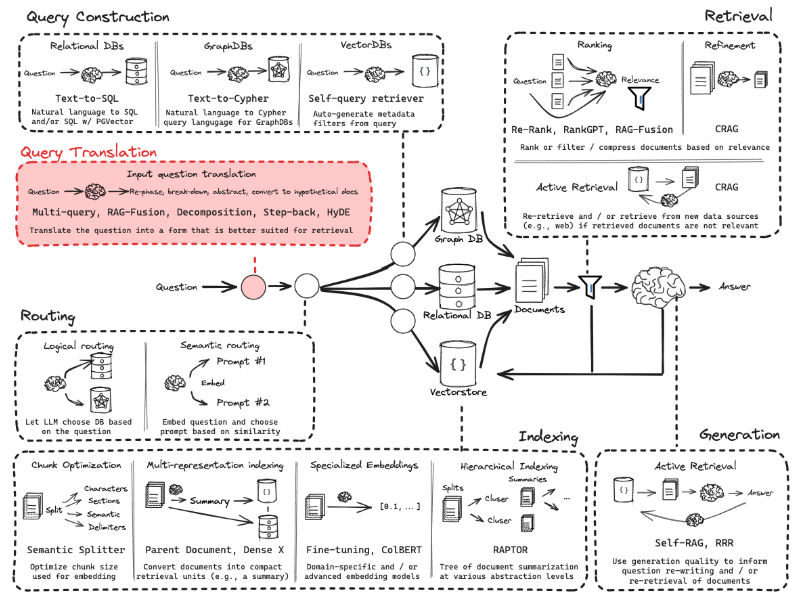
Specifically, we will learn three methods of Query Translation: Re-written, Step-back question, and Sub-question, to enhance the retrieval and generation effectiveness.
Re-written
Re-written refers to semantically rewriting the original query, maintaining the core meaning while adjusting the language expression to make the question easier for the knowledge base or retrieval system to process.
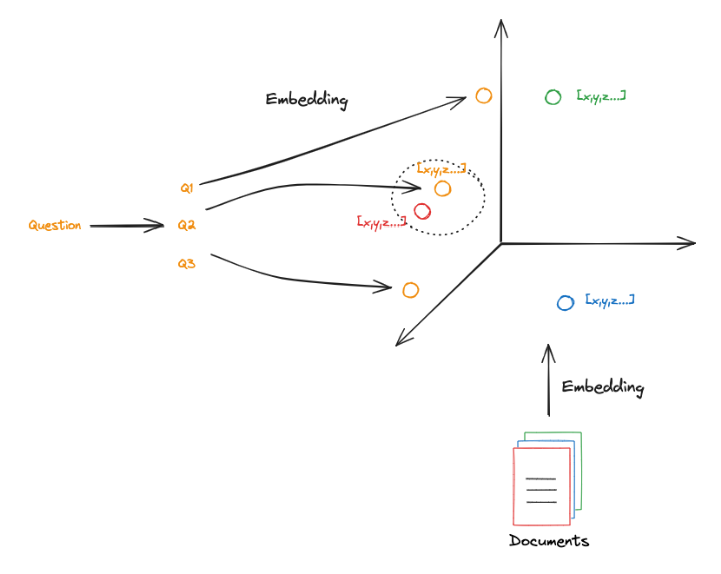
We will rewrite the original Question into three expressions Q1, Q2, and Q3, and then retrieve documents related to these three questions:
Application Scenarios:
-
The original question is vague or unclear.
-
Different expressions are needed to optimize retrieval matching.
Examples:
-
Original question: “What are the uses of Python?”
-
Re-written: “What are the common use cases of the Python programming language?”
-
Effect: The rewritten question is more specific and easier to retrieve high-quality answers.
Common Methods:
-
Multi-Query: Generate multiple different queries for the same question during the retrieval phase to obtain a more comprehensive or relevant set of documents.
-
RAG Fusion: A strategy of integrating retrieval results during the generation phase, focusing on how to synthesize information from multiple retrieved documents to generate high-quality answers.
Advantages:
-
Enhances the retrieval system’s understanding of the question.
-
Improves the relevance of retrieval results.
Challenges:
-
How to maintain semantic consistency between the rewritten question and the original question.
-
Avoid introducing bias or ambiguity.
1. Multi-Query
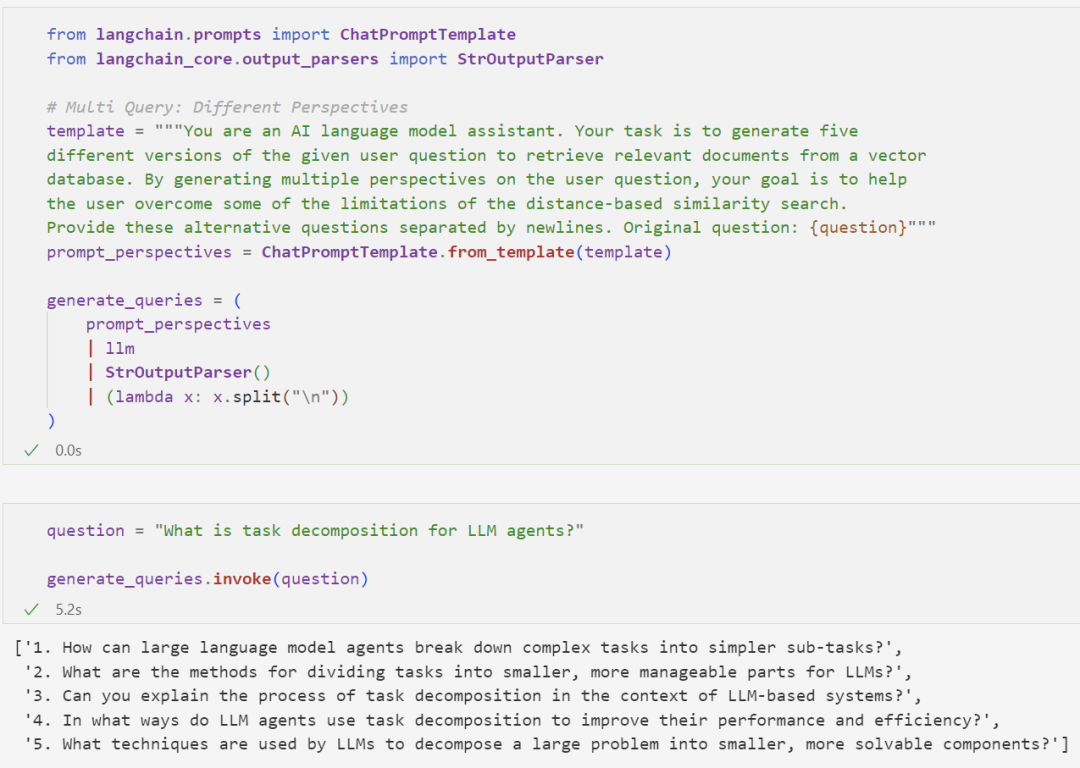
First, we prepare a Prompt for the LLM to rewrite the original question into 5 different expressions:
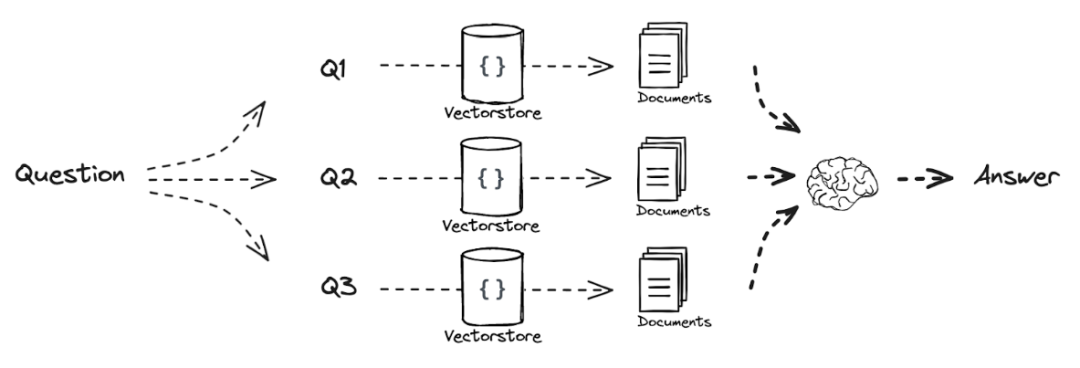
Next, we retrieve documents related to these 5 questions, deduplicate them, and organize them together:
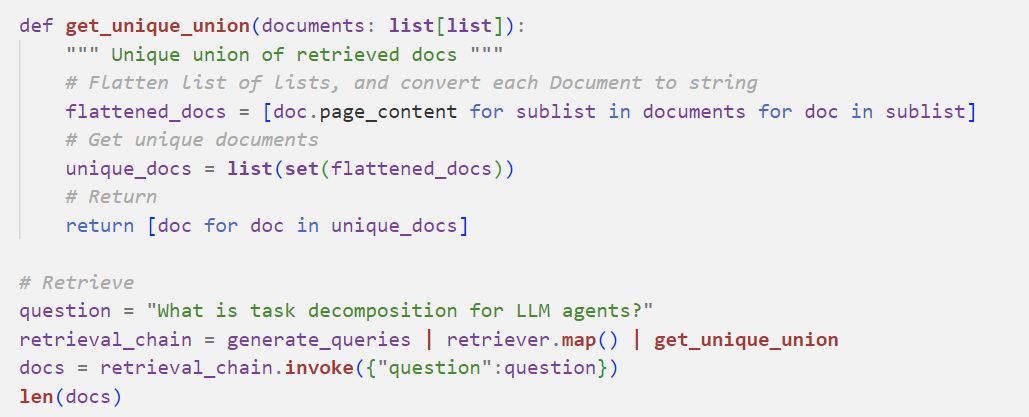
Finally, we connect the chains of split questions and retrieval to form the final RAG pipeline, introducing a new Prompt:

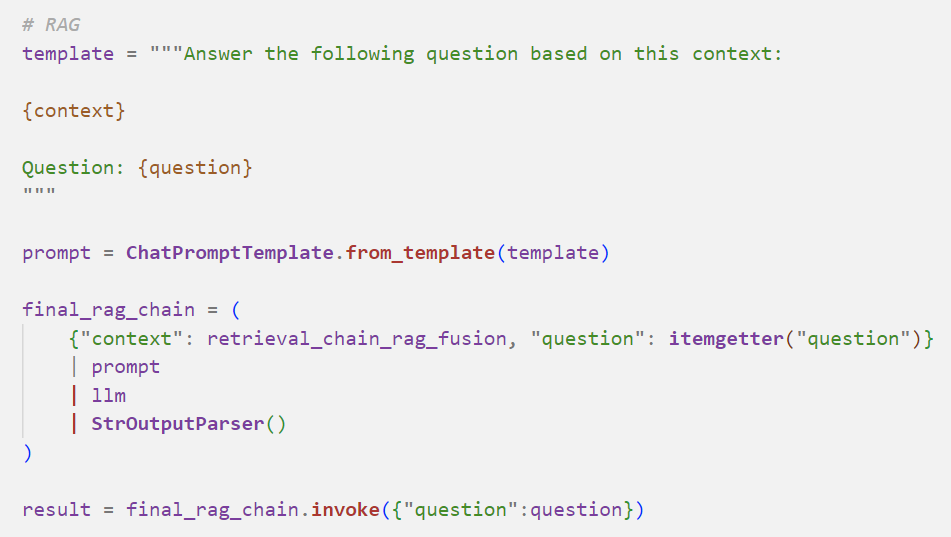
2. RAG Fusion
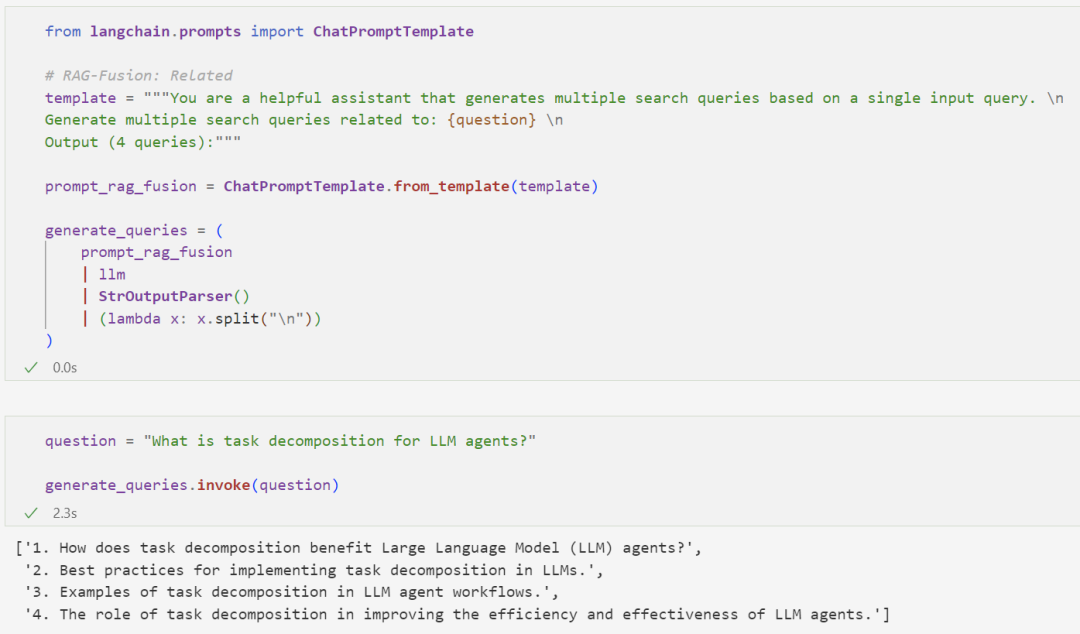
This process is similar to Multi-Query, but filters multiple retrieved documents before inputting them into the LLM:
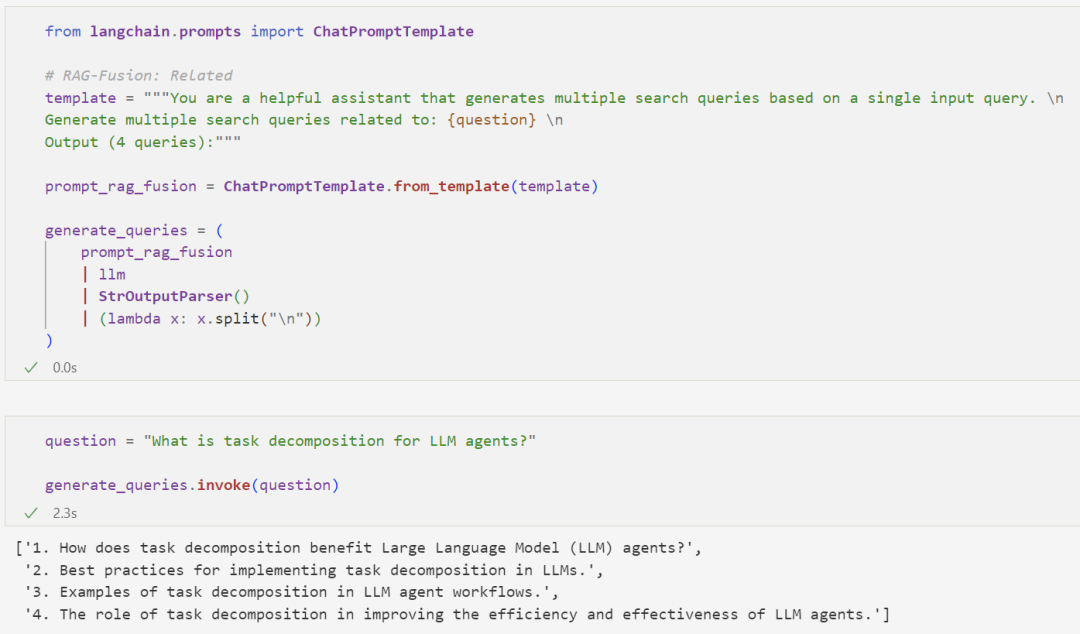
We first write a Prompt: Generate 4 related questions based on the original question:
Here, I will implement a simple Reciprocal Rank Fusion (RRF) retrieval filtering method:
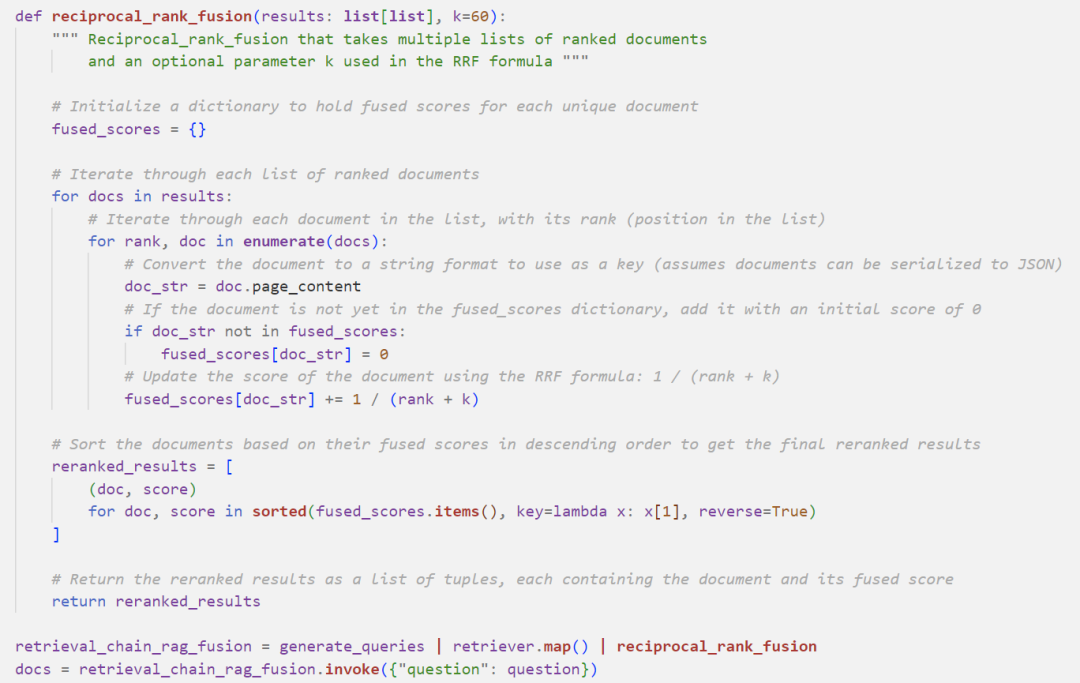
The final RAG pipeline:
Decomposition
Also known as sub-question, it refers to breaking down complex questions into multiple independent sub-questions, each of which can be handled separately. Ultimately, the answers to the sub-questions are aggregated to generate a complete answer.
Application Scenarios:
-
Multi-hop questions (which require answers across multiple knowledge points).
-
Questions that include logical operations or conditional restrictions.
Examples:
-
Original question: “Among Nobel Prize winners, who is both a scientist and a writer?”
-
Sub-questions:
-
“What scientists have won the Nobel Prize?”
-
“What writers have won the Nobel Prize?”
-
“Who are both scientists and writers?”
Effect: By independently answering each sub-question, we ultimately integrate to obtain an accurate answer.

Methods:
-
Logical Decomposition: Based on the logical relationships in the question (such as “and”, “or”).
-
Multi-hop Decomposition: Gradually deepening based on the knowledge domains the question needs to cross.
Advantages:
-
Reduces the complexity of the question, improving the accuracy of retrieval and generation.
-
Provides a clearer reasoning process, facilitating debugging and analysis.
Challenges:
-
The decomposed sub-questions may have interdependencies, requiring a reasonable order of design.
-
Integrating the answers to sub-questions may lead to conflicts or inconsistencies.
Sub-question Process One
Similar to “recursive solving”: combining the answer to the previous sub-question with the documents retrieved for the next sub-question to generate the answer.
First, set the Prompt:
Then the complete RAG pipeline:

Sub-question Process Two
First obtain the answer to each sub-question, then summarize to get the final answer.
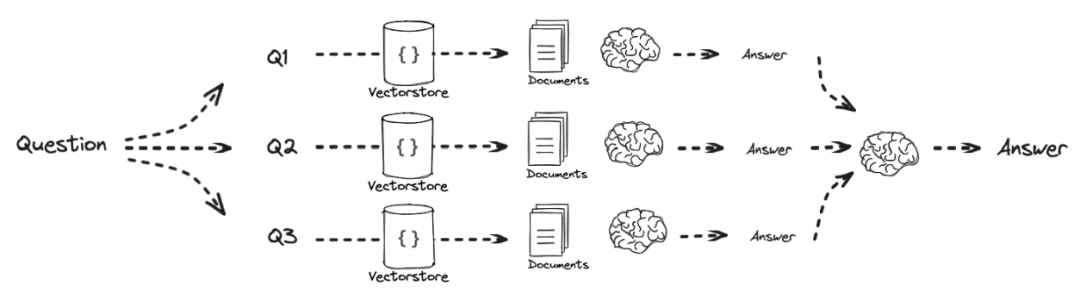
Individually obtain the answers to each sub-question:
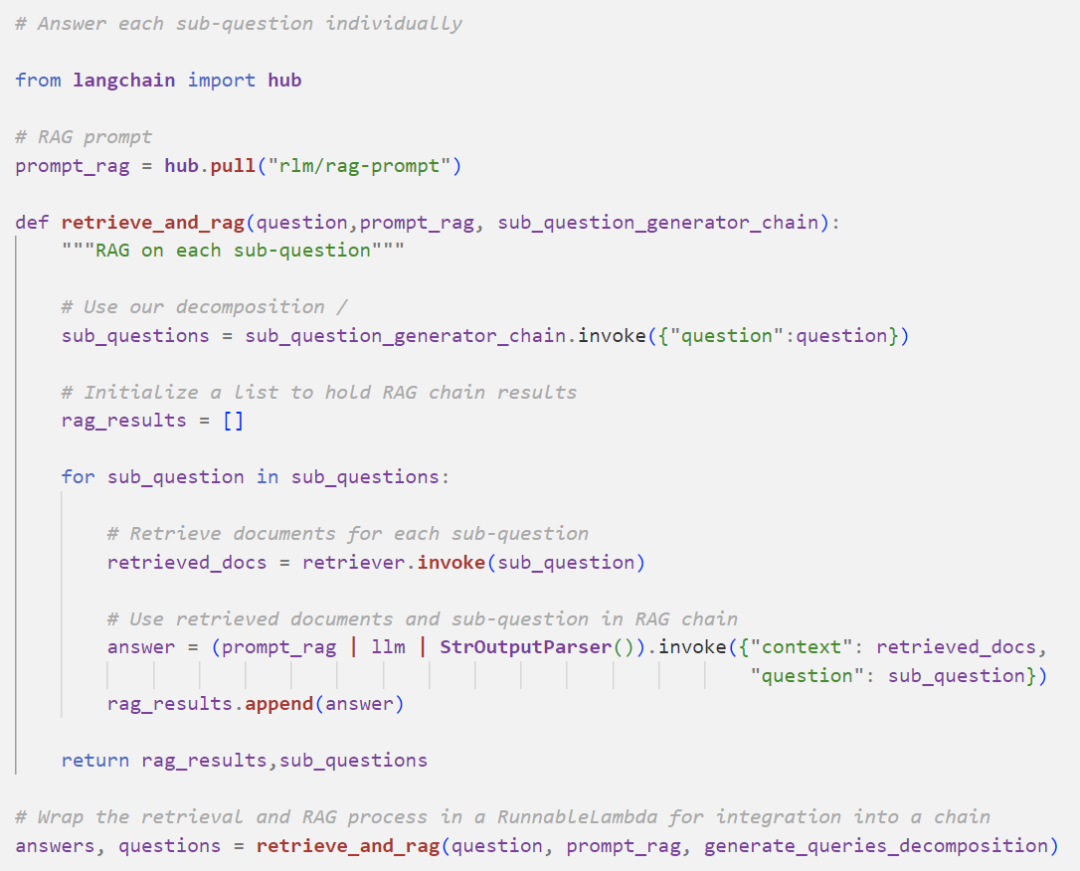
Summarize the answers:

Step-back Question
During the retrieval and answering process, when the system realizes that the current question is too specific or difficult to answer directly, it steps back to ask a broader, more general question to obtain more context information.
Application Scenarios:
-
The current query is too specific to directly match the knowledge base content.
-
There is not enough information in the retrieval results to answer the original question.
Examples:
-
Original question: “What was the specific content of Einstein’s speech at the 1921 Nobel Prize ceremony?”
-
Step-back Question: “Why did Einstein win the Nobel Prize in 1921?”
-
Effect: By answering a more general question, we indirectly obtain relevant context information to support answering the specific question.
Advantages:
-
Increases the recall rate and context coverage of retrieval.
-
Suitable for scenarios with sparse data or high difficulty in answering.
Challenges:
-
How to automatically determine when to “step back”?
-
Whether the returned question can still maintain semantic relevance to the original question.
We first need to provide few-shot examples to the LLM to let it know how to modify the original question:

The effect is as follows:

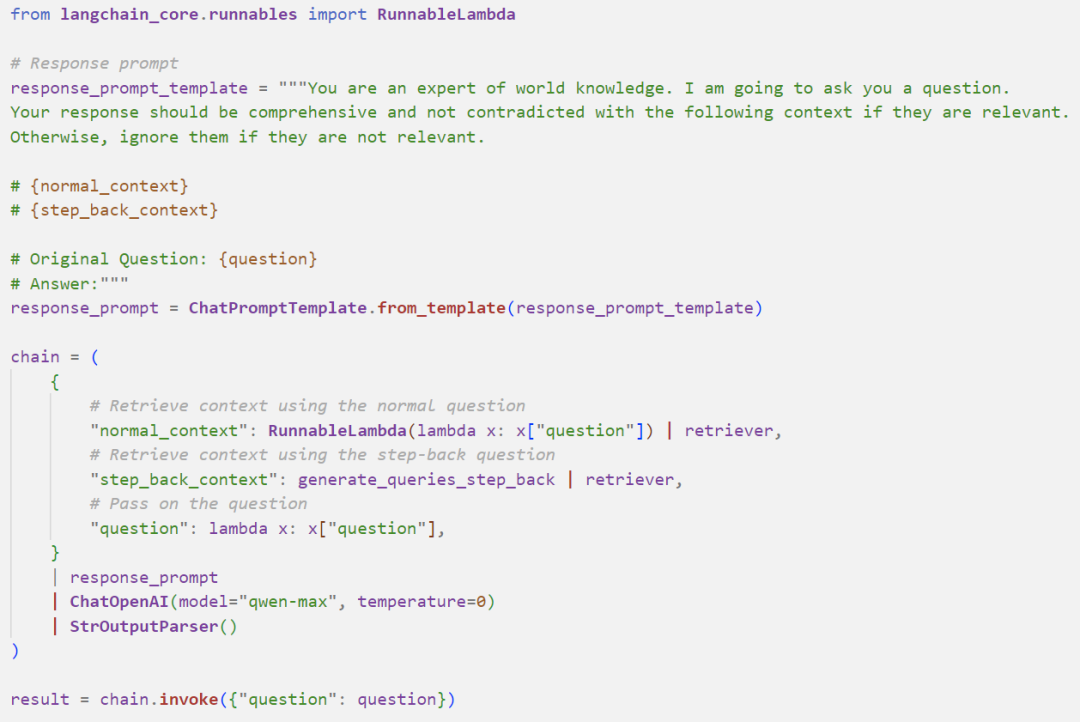
The complete RAG pipeline:
HyDE
HyDE (Hypothetical Document Embedding) is an innovative method for Query Translation, especially suitable for handling complex problems in RAG systems. The core idea of HyDE is to generate “hypothetical documents” to transform queries from abstract natural language questions into representations that can be efficiently processed by retrieval systems.
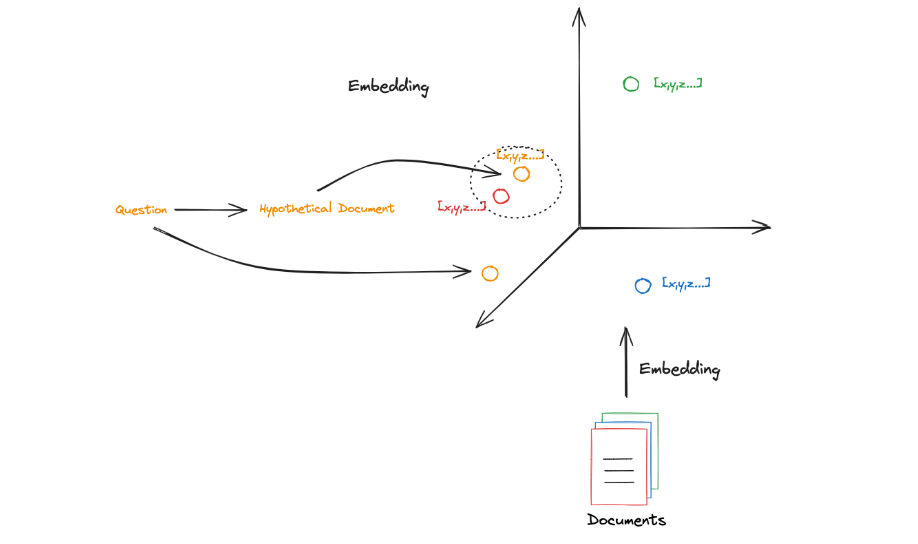
Here is a typical process of HyDE:
-
Input Question: The user inputs a natural language question, such as:
-
“Which country was the first to successfully launch a satellite?”
Generate Hypothetical Document:
-
“The first country to successfully launch a satellite was the Soviet Union, which launched Sputnik 1 in 1957.”
-
Using a language model (such as GPT) to generate a possible answer, the hypothetical content may be:
-
This step provides a strongly semantic context hypothetical answer, even if the generated hypothetical answer may not be completely correct.
Retrieve Relevant Documents:
-
Embedding the generated hypothetical document into vector space or extracting keywords as input for the retrieval system to search for the most relevant documents in the knowledge base.
Generate Final Answer:
-
Combining the retrieved documents and the original question, generating the final answer through a generation model.
HyDE’s approach is:
-
Generate Hypothetical Document: Use a generation model (like GPT) to generate a hypothetical answer to the input question as a possible semantic extension of the question.

-
Retrieve Relevant Documents: Use the generated hypothetical document as input to retrieve relevant documents in the knowledge base through embedding matching or keyword matching.

-
Integrate Retrieval Results: Combine the original query with the retrieved relevant documents to generate the final answer.

The Power of Prompts
Whether it is Re-written, Decomposition, or Step-back Question, all leverage the powerful Prompt.
Perhaps your English is not very good, and our database is all in English, so I can build a translation Chain: first translating the user’s Chinese question into English.
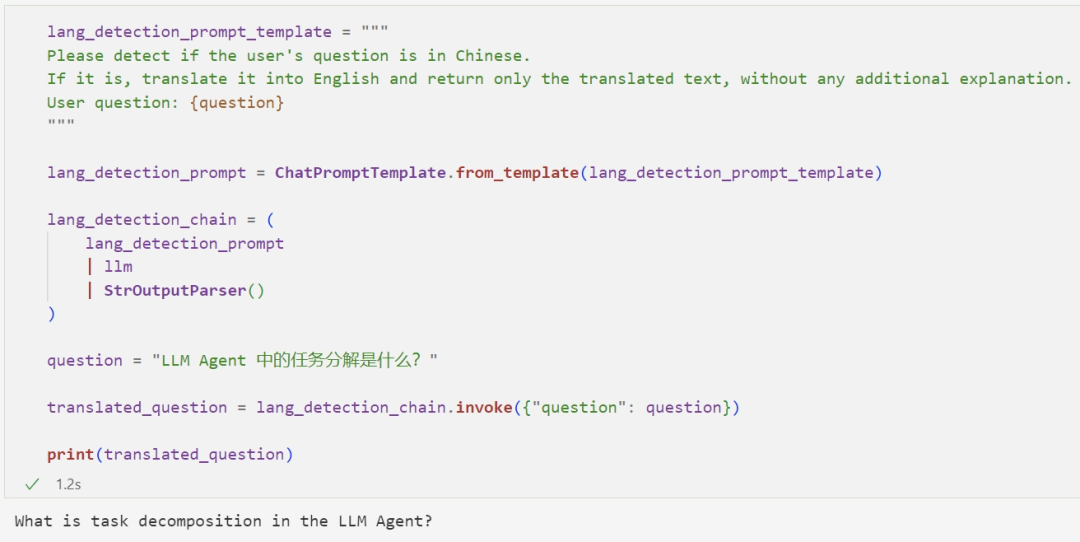
Then ask the LLM to answer the question in Chinese:
GitHub Link:
https://github.com/realyinchen/RAG/blob/main/02_Query_Translation.ipynb
Source: PyTorch Study Group