LangGraph Persistence allows for easy state persistence between graph execution (thread-level persistence) and threads (cross-thread persistence). This tutorial demonstrates how to add persistence to a graph.
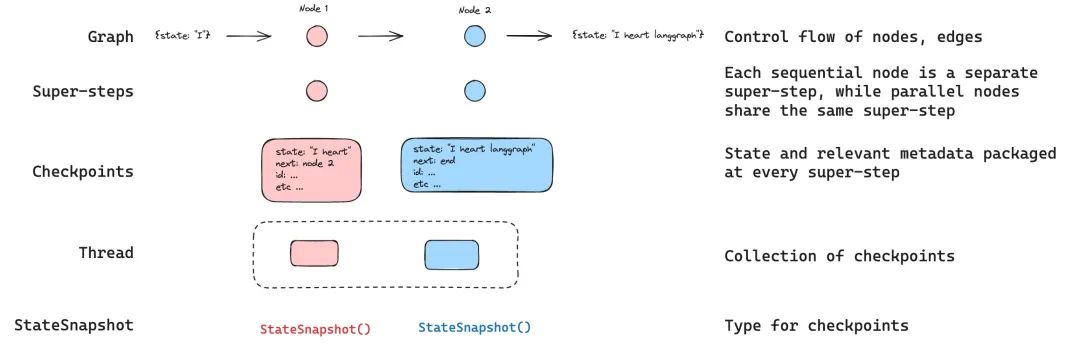
LangGraph has a built-in persistence layer that is implemented through checkpoints. When compiling a graph with a checkpoint, the checkpoint saves a snapshot of the graph’s state at each step. These checkpoints are saved to a thread and can be accessed after the graph execution.
Since threads allow access to the graph’s state after execution, various powerful features can be implemented, including human-computer interaction, memory, historical backtracking, and fault tolerance.
Threads are unique IDs or thread identifiers allocated to each checkpoint saved by the checkpoint program. When calling the graph with the checkpoint program, the thread_id must be specified in the configurable section of the config:
{"configurable": {"thread_id": "1"}}
Checkpoints are snapshots of the graph’s state saved at each super-step, represented by a StateSnapshot object with the following key properties:
-
config: Configuration related to this checkpoint.
-
metadata: Metadata associated with this checkpoint.
-
values: Values of the state channels at this point in time.
-
next: A tuple of the names of the nodes to be executed next in the graph.
-
tasks: A tuple of PregelTask objects that contain information about the tasks to be executed next. If this step has been attempted previously, it will contain error information. If the graph is dynamically interrupted from within a node, the tasks will contain additional data related to the interruption.
Let’s see what checkpoints are saved when calling a simple graph, as shown below:
from langgraph.graph import StateGraph, START, END
from langgraph.checkpoint.memory import MemorySaver
from typing import Annotated
from typing_extensions import TypedDict
from operator import add
class State(TypedDict):
foo: int
bar: Annotated[list[str], add]
def node_a(state: State):
return {"foo": "a", "bar": ["a"]}
def node_b(state: State):
return {"foo": "b", "bar": ["b"]}
workflow = StateGraph(State)
workflow.add_node(node_a)
workflow.add_node(node_b)
workflow.add_edge(START, "node_a")
workflow.add_edge("node_a", "node_b")
workflow.add_edge("node_b", END)
checkpointer = MemorySaver()
graph = workflow.compile(checkpointer=checkpointer)
config = {"configurable": {"thread_id": "1"}}
print(graph.invoke({"foo": ""}, config))
After running the graph, we expect to see 4 checkpoints:
-
Empty checkpoint, with START as the next node to execute
-
Checkpoint where user input {‘foo’: ”, ‘bar’: []} and node_a is the next node to execute
-
Output of checkpoint for node_a {‘foo’: ‘a’, ‘bar’: [‘a’]}, with node_b as the next node to execute
-
Checkpoint where the output of node_b is {‘foo’: ‘b’, ‘bar’: [‘a’, ‘b’]}, with no next node to execute
Getting State
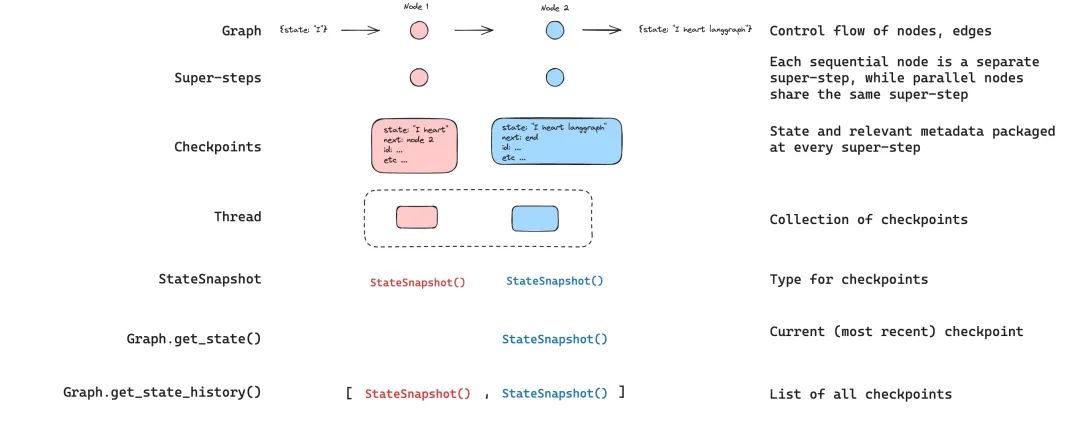
When interacting with saved graph states, the thread identifier must be specified. You can view the latest state of the graph by calling graph.get_state(config).
This will return a StateSnapshot object that corresponds to the latest checkpoint associated with the thread ID provided in the configuration or the checkpoint ID associated with the thread (if provided).
# Get latest state snapshot
config = {"configurable": {"thread_id": "1"}}
graph.get_state(config)
# Get state snapshot for specified checkpoint_id
config = {"configurable": {"thread_id": "1", "checkpoint_id": "1ef663ba-28fe-6528-8002-5a559208592c"}}
graph.get_state(config)
You can retrieve the complete history of the graph execution for a given thread by calling graph.get_state_history(config). This will return a list of StateSnapshot objects associated with the thread ID provided in the configuration.
Importantly, checkpoints will be sorted in chronological order, with the most recent checkpoint/StateSnapshot at the beginning of the list.
config = {"configurable": {"thread_id": "1"}}
list(graph.get_state_history(config))
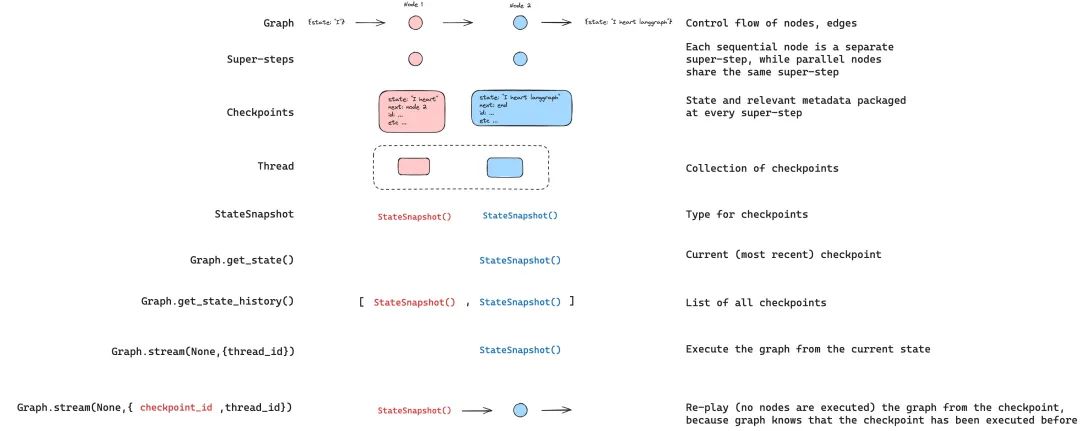
You can also replay a previous graph execution. If we invoke the graph using thread_id and checkpoint_id, we will start re-executing the graph from the checkpoint corresponding to checkpoint_id:
-
thread_id is simply the ID of the thread. This is always required.
-
checkpoint_id refers to a specific checkpoint within the thread.
# {"configurable": {"thread_id": "1"}} # valid config
# {"configurable": {"thread_id": "1", "checkpoint_id": "0c62ca34-ac19-445d-bbb0-5b4984975b2a"}} # also valid config
config = {"configurable": {"thread_id": "1"}}
graph.invoke(None, config=config)
Importantly, LangGraph knows whether a specific checkpoint has been executed previously.
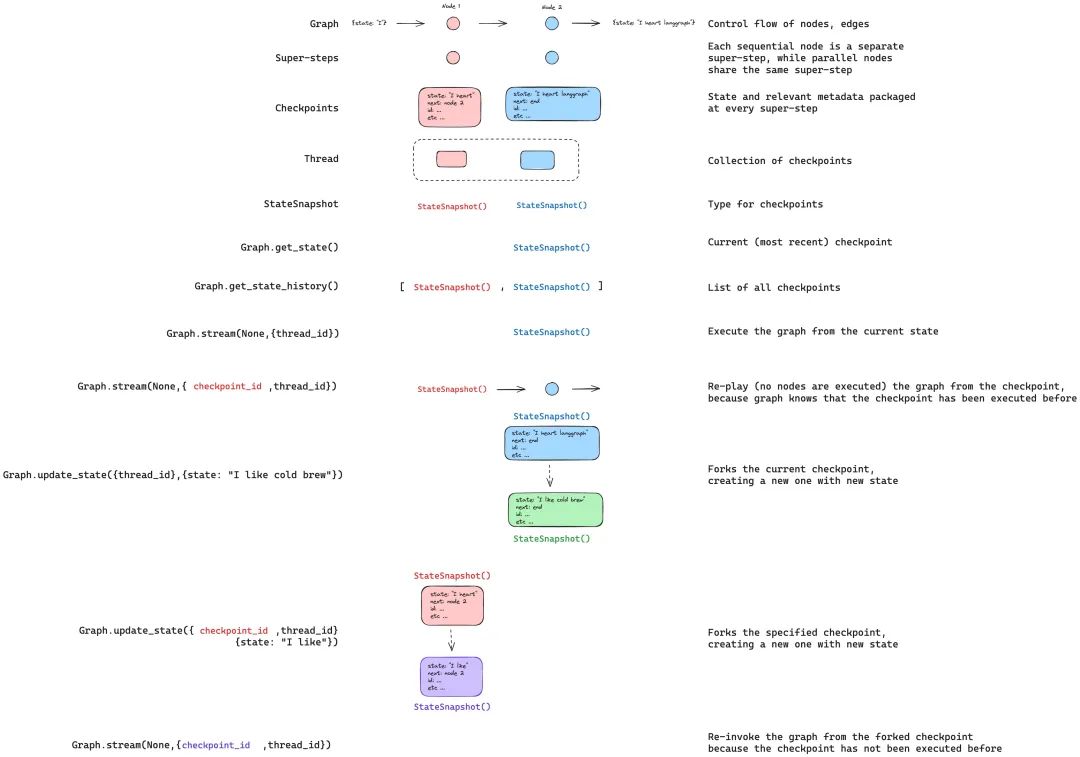
In addition to replaying the graph from a specific checkpoint, we can also modify the state of the graph. We use graph.update_state() to do this. This method accepts three different parameters:
The configuration should include the thread_id to specify which thread to update. When only passing thread_id, we update (or fork) the current state. Alternatively, if we include the checkpoint_id field, we will fork from the selected checkpoint.
These are the values that will be used to update the state. Note that the handling of this update is identical to that of any updates from nodes. This means that if these values are defined for certain channels in the graph state, they will be passed to the reducer function.
Thus, update_state does not automatically overwrite the values of every channel but will only overwrite channel values that do not have a Reducer. Let’s see an example (Assuming you have defined the state’s graph using the following pattern (see the complete example above):
from typing import Annotated
from typing_extensions import TypedDict
from operator import add
class State(TypedDict):
# No reducer specified
foo: int
# Specified reducer as add
bar: Annotated[list[str], add]
Now let’s assume the current state of the graph is
If we update the state as follows:
graph.update_state(config, {"foo": 2, "bar": ["b"]})
The new state of the graph will be:
{"foo": 2, "bar": ["a", "b"]}
The foo key (channel) has been completely changed (since this channel did not specify any Reducer, update_state will overwrite it). However, the bar key has specified a Reducer, so it will append “b” to the state of bar.
When calling update_state, you can optionally specify the last item as as_node. If provided, the update will be applied as if it came from the as_node. If not provided, it will be set to the last node that updated the state (if not explicitly given).
This is important because the next step to be executed depends on the last node that was updated, and thus can be used to control which node to execute next.
The state schema specifies a set of keys that are populated during the execution of the graph. As mentioned, the state can be written to a thread via checkpoints at each graph step, allowing for state persistence.
However, what if we want to retain some information across different threads? Consider the case of a chatbot where we want to retain specific information about a user across all chat conversations (i.e., threads) with that user!
That is, with checkpoints alone, we cannot share information across threads. Because the granularity of checkpoints is precise to the thread, but the relationship between threads and users is many-to-one, meaning one user can have multiple threads, simply using checkpoints does not allow for information sharing between users.
This sparked the need for a Store interface.
For example, we can define an InMemoryStore to store user information across threads. We just need to compile our graph using checkpoints and the new in_memory_store variable as before.
Let’s take a look at the usage of InMemoryStore separately
from langgraph.store.memory import InMemoryStore
in_memory_store = InMemoryStore()
Memory is named by a tuple, in this specific example (<user_id>, “memories”). The namespace can be of any length and represent anything, not necessarily specific to a user.
user_id = "1"
namespace_for_memory = (user_id, "memories")
memory_id = str(uuid.uuid4())
memory = {"food_preference" : "I like pizza"}
in_memory_store.put(namespace_for_memory, memory_id, memory)
We can read memories in the namespace using the store.search method, which will return all memories for the given user in list form. The most recent memory is at the end of the list.
memories = in_memory_store.search(namespace_for_memory)
print(memories[-1].dict())
{'namespace': ['1', 'memories'], 'key': '7afaa64d-d0cf-44db-bc65-7bfe1bb59025', 'value': {'food_preference': 'I like pizza'}, 'created_at': '2025-01-07T02:28:24.755296+00:00', 'updated_at': '2025-01-07T02:28:24.755301+00:00', 'score': None}
Each memory type is a Python class (Item) with certain properties. We can access it as a dictionary using .dict as shown above. Its properties include:
-
value:The value of this memory (itself a dictionary)
-
key:The unique key of this memory in the namespace
-
namespace: A list of strings representing the namespace of this memory type
-
created_at: The timestamp when this memory was created
-
updated_at: The timestamp when this memory was updated
In addition to simple retrieval, the store also supports semantic search, allowing for finding memories based on meaning rather than exact matches. To implement this, configure the store with an embedding model:
from langchain.embeddings import init_embeddings
from langgraph.store.memory import InMemoryStore,IndexConfig
index = IndexConfig(embed=init_embeddings("openai:text-embedding-3-small"), # Embedding provider
dims=1536, # Embedding dimensions
fields=["food_preference", "$"], # Fields to embed
store = InMemoryStore(index=index)
Now when searching, you can use natural language queries to find relevant memories:
memories = store.search( namespace_for_memory, query="What does the user like to eat?", limit=3 # Return top 3 matching )
You can control which parts of the memory to embed by configuring the fields parameter or the index parameter when storing memories:
# Embed the "food_preference" field
store.put( namespace_for_memory, str(uuid.uuid4()), { "food_preference": "I love Italian cuisine", "context": "Discussing dinner plans" }, index=["food_preference"] # Only embed the "food_preference" field)
# Only store, do not embed
store.put( namespace_for_memory, str(uuid.uuid4()), {"system_info": "Last updated: 2024-01-01"}, index=False)
From a vector storage perspective, note that we generally equate embedding with what is called an index; embedding is a necessary step for indexing a field.
Once everything is set up, we use the in_memory_store in LangGraph. The in_memory_store works in conjunction with the checkpointer:
As mentioned, checkpoints save state to threads, and the in_memory_store allows us to store arbitrary information for cross-thread access. We compile the graph using both checkpoints and in_memory_store as follows.
from langgraph.checkpoint.memory import MemorySaver
# Chinese: We need this because we want to enable threads (conversations)
checkpointer = MemorySaver()
# ... Define graph ...
# Compile graph with checkpointer and store
graph = graph.compile(checkpointer=checkpointer, store=in_memory_store)
As before, we call the graph using thread_id while using user_id to name our memory namespace for this specific user, as shown above.
# Invoke graph
user_id = "1"
config = {"configurable": {"thread_id": "1", "user_id": user_id}}
# First, let's greet the AI
for update in graph.stream( {"messages": [{"role": "user", "content": "hi"}]}, config, stream_mode="updates"):
print(update)
We can access the in_memory_store and user_id in any node by passing store: BaseStore and config: RunnableConfig as node parameters.
def update_memory(state: MessagesState, config: RunnableConfig, *, store: BaseStore):
user_id = config["configurable"]["user_id"]
namespace = (user_id, "memories")
# ... Analyze conversation and create new memory
# Create a new ID for the new memory
memory_id = str(uuid.uuid4())
# Create a new memory
store.put(namespace, memory_id, {"memory": memory})
We can access these memories and use them in our model calls.
def call_model(state: MessagesState, config: RunnableConfig, *, store: BaseStore):
user_id = config["configurable"]["user_id"]
memories = store.search( namespace, query=state["messages"][-1].content, limit=3 )
info = "\n".join([d.value["memory"] for d in memories])
# ... Use memories in model calls
If we create a new thread, we can still access the same memory as long as the user_id is the same.
# Invoke graph
config = {"configurable": {"thread_id": "2", "user_id": "1"}}
for update in graph.stream( {"messages": [{"role": "user", "content": "hi, tell me about my memories"}]}, config, stream_mode="updates"):
print(update)
The above only discussed in_memory_store, which has the limitation that once the machine is restarted, the checkpoint is lost. In practice, we rarely use it, or at least need to use it in conjunction with a persistent lib. Below are the abstractions and implementations provided by langgraph:
-
langgraph-checkpoint: Basic interface for checkpoint savers (BaseCheckpointSaver) and serialization/deserialization interfaces (SerializerProtocol). Includes memory checkpoint implementation (MemorySaver) for experimentation. LangGraph comes with langgraph-checkpoint.
-
langgraph-checkpoint-sqlite: LangGraph checkpoint implementation using SQLite database (SqliteSaver / AsyncSqliteSaver). Great for experimentation and local workflows. Requires separate installation.
-
langgraph-checkpoint-postgres: Advanced checkpoint program for LangGraph Cloud using Postgres database (PostgresSaver / AsyncPostgresSaver). Very suitable for production use. Requires separate installation.
Each checkpoint conforms to the BaseCheckpointSaver interface and implements the following methods:
-
.put – Store the checkpoint along with its configuration and metadata.
-
.put_writes – Store intermediate writes associated with the checkpoint (like pending writes).
-
.get_tuple – Retrieve the checkpoint tuple using the given configuration (thread_id and checkpoint_id). This is used to populate StateSnapshot in graph.get_state().
-
.list – List checkpoints that match the given configuration and filtering criteria. This is used to populate the state history in graph.get_state_history().
When checkpoints save graph states, they need to serialize the channel values in the state. This is done using a serializer object.
langgraph_checkpoint defines the protocol for implementing serializers and provides a default implementation (JsonPlusSerializer) that can handle various types, including LangChain and LangGraph primitives, date times, enums, etc.
https://langchain-ai.github.io/langgraph/concepts/persistence/